Recognition: unknown
Attribution-Guided Multimodal Deepfake Detection via Cross-Modal Forensic Fingerprints
Pith reviewed 2026-05-07 11:35 UTC · model grok-4.3
The pith
Attribution guides deepfake detectors to real forensic traces
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
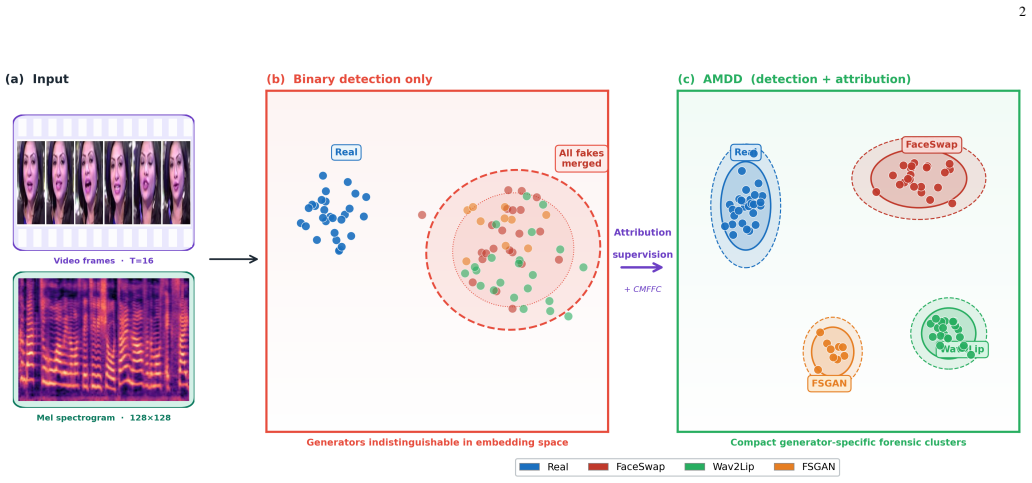
Attribution-guided multimodal deepfake detection via cross-modal forensic fingerprint consistency constrains the embedding space to encode generator-specific artifacts rather than spurious signals, because a model that cannot identify how a video was forged is likely learning the wrong cues.
What carries the argument
Cross-Modal Forensic Fingerprint Consistency (CMFFC) loss, which enforces alignment of generator-induced artifacts between visual and audio modalities based on physical speech-face coupling.
If this is right
- Real-video detection generalizes robustly across different datasets and generators.
- The model gains the ability to attribute fakes to their source as a byproduct of improved detection.
- Fake detection on completely unseen generators remains an open challenge requiring further analysis.
- Architectural pairing of visual and audio encoders closes capacity gaps that limited prior multimodal models.
Where Pith is reading between the lines
- Detectors built this way could output not only a fake flag but also a likely creation method, supporting origin tracing in media verification pipelines.
- The same cross-modal consistency principle might extend to other paired data such as video with overlaid text or synchronized motion and sound in different domains.
- Testing the loss on datasets with deliberately broken or preserved audio-visual synchronization could isolate how much the physical-coupling assumption drives gains.
Load-bearing premise
Coherent manipulations leave correlated traces across audio and visual streams that synthetic generators disrupt in a consistent, exploitable manner.
What would settle it
An experiment in which models trained with the attribution objective show no improvement in separating real from fake samples or fail to maintain cross-modal artifact alignment on held-out manipulations.
Figures











read the original abstract
Audio-visual deepfakes have reached a level of realism that makes perceptual detection unreliable, threatening media integrity and biometric security. While multimodal detection has shown promise, most approaches are binary classification tasks that often latch onto dataset-specific artifacts rather than genuine generative traces. We argue that a detector incapable of identifying how a video was forged is likely learning the wrong signal. Unlike binary detection, attribution-guided learning imposes a stronger geometric constraint on the shared embedding space, forcing the model to encode generator-specific forensic content rather than shortcuts. We propose the Attribution-Guided Multimodal Deepfake Detection (AMDD) framework, which jointly learns to detect and attribute manipulation. AMDD treats generator attribution as a structured regularization that constrains representation geometry toward forensically meaningful features. We introduce a Cross-Modal Forensic Fingerprint Consistency (CMFFC) loss to enforce alignment between generator-induced artifacts in visual and audio streams. This exploits the fact that coherent manipulation leaves correlated traces across modalities, grounded in the physical coupling between speech and facial articulation that synthetic pipelines routinely disrupt. Architecturally, we pair a ResNet50 with temporal attention for visual encoding against a pretrained ResNet18 for mel spectrograms, closing the encoder capacity gap found in prior models. On FakeAVCeleb, AMDD achieves 99.7% balanced accuracy and 99.8% AUC with 95.9% attribution accuracy. Cross-dataset evaluation on DeepfakeTIMIT, DFDM, and LAV-DF confirms that real video detection generalizes robustly, while fake detection on unseen generators remains an open challenge that we analyze in depth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Attribution-Guided Multimodal Deepfake Detection (AMDD) framework, which jointly performs binary deepfake detection and generator attribution for audio-visual content. It proposes the Cross-Modal Forensic Fingerprint Consistency (CMFFC) loss to align generator-induced artifacts between visual and audio streams, exploiting the physical coupling between speech and facial articulation that synthetic manipulations disrupt. The architecture pairs a ResNet50 with temporal attention for video against a pretrained ResNet18 on mel spectrograms to balance encoder capacities. On FakeAVCeleb the model reports 99.7% balanced accuracy, 99.8% AUC and 95.9% attribution accuracy; cross-dataset tests on DeepfakeTIMIT, DFDM and LAV-DF show robust real-video detection while fake detection on unseen generators remains challenging.
Significance. If the reported numbers and the geometric-constraint argument hold, the work offers a concrete way to move multimodal deepfake detection beyond shortcut-prone binary classification toward attribution-regularized representations that encode generator-specific forensic traces. The explicit discussion of the remaining challenge for unseen generators and the architectural choice to close the encoder-capacity gap are positive contributions that could guide subsequent multimodal forensic research.
minor comments (3)
- Abstract: the statement that attribution 'imposes a stronger geometric constraint on the shared embedding space' would be more convincing if the results section included a direct ablation comparing the full CMFFC objective against a binary-detection-only baseline on the same backbone and data splits.
- Abstract: 'closing the encoder capacity gap found in prior models' is mentioned without citation or quantification; adding a brief reference and the specific capacity difference would improve clarity.
- Abstract: cross-dataset results are summarized qualitatively ('robustly' for reals, 'open challenge' for fakes); a compact table with per-dataset balanced accuracy and attribution numbers would make the generalization claim easier to evaluate.
Simulated Author's Rebuttal
We thank the referee for their detailed summary of our AMDD framework and for the positive assessment of its contributions, including the CMFFC loss, architectural choices, and cross-dataset analysis. The recommendation for minor revision is appreciated. As no specific major comments were provided in the report, we have no points to address point-by-point and believe the current manuscript stands as submitted.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines the CMFFC loss and attribution-guided objective independently of the target metrics (balanced accuracy, AUC, attribution accuracy). No equations are present that reduce claimed performance to fitted parameters by construction, nor are there self-citations or uniqueness theorems invoked to justify core choices. The physical-coupling premise is stated as an explicit modeling assumption rather than derived from the results themselves. Cross-dataset evaluations are reported separately and do not collapse into in-sample fits. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coherent manipulation leaves correlated traces across modalities grounded in the physical coupling between speech and facial articulation that synthetic pipelines routinely disrupt.
Reference graph
Works this paper leans on
-
[1]
Faceswap,
deepfakes, “Faceswap,” https://github.com/deepfakes/faceswap, 2017
2017
-
[2]
FSGAN: Subject agnostic face swapping and reenactment,
Y . Nirkin, Y . Keller, and T. Hassner, “FSGAN: Subject agnostic face swapping and reenactment,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 7184– 7193
2019
-
[3]
A lip sync expert is all you need for speech to lip generation in the wild,
K. R. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. V . Jawahar, “A lip sync expert is all you need for speech to lip generation in the wild,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 484–492
2020
-
[4]
Transfer learning from speaker verification to multispeaker text-to-speech synthesis,
Y . Jia, Y . Zhang, R. J. Weiss, Q. Wang, J. Shen, F. Ren, P. Nguyen, R. Pang, I. L. Moreno, Y . Wuet al., “Transfer learning from speaker verification to multispeaker text-to-speech synthesis,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018. 13
2018
-
[5]
FakeA VCeleb: A novel audio-video multimodal deepfake dataset,
H. Khalid, S. Tariq, M. Kim, and S. S. Woo, “FakeA VCeleb: A novel audio-video multimodal deepfake dataset,” inAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
2021
-
[6]
Joint audio-visual deepfake detection,
Y . Zhou and S.-N. Lim, “Joint audio-visual deepfake detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 14 800–14 809
2021
-
[7]
Detecting deep-fake videos from appearance and behavior,
K. Chugh, P. Gupta, A. Dhall, and R. Subramanian, “Detecting deep-fake videos from appearance and behavior,” inIEEE Winter Conference on Applications of Computer Vision (WACV), 2020
2020
-
[8]
Emotions don’t lie: An audio-visual deepfake detection method using affective cues,
T. Mittal, U. Bhattacharya, R. Chandra, A. Bera, and D. Manocha, “Emotions don’t lie: An audio-visual deepfake detection method using affective cues,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 2823–2832
2020
-
[9]
Leveraging large language models for multimodal deepfake detection,
Z. Liu, Z. Wang, and B. Wen, “Leveraging large language models for multimodal deepfake detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[10]
NPVForensics: Jointing non-critical phonemes and visemes for deepfake detection,
H. Feng, J. Zhou, J. Han, R. Ni, Y . Zhao, and C. He, “NPVForensics: Jointing non-critical phonemes and visemes for deepfake detection,” in Proceedings of the ACM International Conference on Multimedia, 2023
2023
-
[11]
GAN fingerprints: Detecting and attributing fake images to their source,
N. Yu, L. Davis, and M. Fritz, “GAN fingerprints: Detecting and attributing fake images to their source,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3512–3524, 2021
2021
-
[12]
FAME: A lightweight spatio- temporal network for model attribution of face-swap deepfakes,
W. Ahmad, Y .-T. Peng, and Y .-H. Chang, “FAME: A lightweight spatio- temporal network for model attribution of face-swap deepfakes,”Expert Systems with Applications, vol. 292, p. 128571, 2025
2025
-
[13]
Capst: Leveraging capsule networks and temporal attention for accurate model attribution in deepfake videos,
W. Ahmad, Y .-T. Peng, Y .-H. Chang, G. O. Ganfure, and S. Khan, “Capst: Leveraging capsule networks and temporal attention for accurate model attribution in deepfake videos,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 21, no. 4, pp. 1–23, 2025
2025
-
[14]
Resvit: A framework for deepfake videos detection,
W. Ahmad, I. Ali, A. Shahzad, A. Hashmi, and F. Ghaffar, “Resvit: A framework for deepfake videos detection,”International Journal of Electrical and Computer Engineering Systems, vol. 13, no. 9, pp. 807– 813, 2022
2022
-
[15]
Multimodal forgery detection using ensemble learning,
A. Hashmi, S. A. Shahzad, W. Ahmad, C.-W. Lin, Y . Tsao, and H.- M. Wang, “Multimodal forgery detection using ensemble learning,” in 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2022, pp. 1524–1532
2022
-
[16]
In ictu oculi: Exposing ai created fake videos by detecting eye blinking,
Y . Li, M.-C. Chang, and S. Lyu, “In ictu oculi: Exposing ai created fake videos by detecting eye blinking,” inIEEE International Workshop on Information Forensics and Security (WIFS), 2018, pp. 1–7
2018
-
[17]
Exposing deepfake videos by detecting face warping artifacts,
Y . Li and S. Lyu, “Exposing deepfake videos by detecting face warping artifacts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019
2019
-
[18]
Xception: Deep learning with depthwise separable convolu- tions,
F. Chollet, “Xception: Deep learning with depthwise separable convolu- tions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1251–1258
2017
-
[19]
Exploiting visual artifacts to expose deepfakes with face warping artifacts,
Y . Li and S. Lyu, “Exploiting visual artifacts to expose deepfakes with face warping artifacts,” inIEEE Winter Applications of Computer Vision Workshops (WACVW), 2019
2019
-
[20]
Detecting deepfake videos using euler video magnification,
H. Qi, S. Guo, F. Torchiani, D. Weuster, and M. Steinebach, “Detecting deepfake videos using euler video magnification,” inMedia Watermarking, Security, and Forensics, 2020
2020
-
[21]
Faceforensics++: Learning to detect manipulated facial images,
A. Rossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner, “Faceforensics++: Learning to detect manipulated facial images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1–11
2019
-
[22]
LipForensics: Breaking temporal-inconsistency based deepfake detection,
A. Haliassos, K. V ougioukas, S. Petridis, and M. Pantic, “LipForensics: Breaking temporal-inconsistency based deepfake detection,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 1795–1805
2021
-
[23]
End-to- end reconstruction-classification learning for face forgery detection,
J. Cao, C. Ma, T. Yao, S. Chen, S. Ding, and X. Yang, “End-to- end reconstruction-classification learning for face forgery detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4523–4533
2022
-
[24]
Leveraging frequency analysis for deep fake image recognition,
J. Frank, T. Eisenhofer, L. Sch¨onherr, A. Fischer, D. Kolossa, and T. Holz, “Leveraging frequency analysis for deep fake image recognition,” in International Conference on Machine Learning (ICML), 2020, pp. 3247– 3258
2020
-
[25]
Self-supervised transformer for deepfake detection,
H. Zhao, W. Zhou, D. Chen, W. Zhang, and N. Yu, “Self-supervised transformer for deepfake detection,” inarXiv preprint arXiv:2203.01265, 2022
-
[26]
ASVspoof 2019: A large- scale public database of synthesized, converted and replayed speech,
X. Wang, J. Yamagishi, M. Todiscoet al., “ASVspoof 2019: A large- scale public database of synthesized, converted and replayed speech,” in Computer Speech & Language, vol. 64, 2020, p. 101114
2019
-
[27]
RawNet2: Towards a more interpretable representation for audio spoofing detection,
H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “RawNet2: Towards a more interpretable representation for audio spoofing detection,” inInterspeech, 2021, pp. 2586–2590
2021
-
[28]
AASIST: Audio anti-spoofing using integrated spectro- temporal graph attention networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “AASIST: Audio anti-spoofing using integrated spectro- temporal graph attention networks,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6367–6371
2022
-
[29]
Enhanced receptive field with boundary- aware temporal forgery detection,
Z. Wang, Z. Cai, and A. Dhall, “Enhanced receptive field with boundary- aware temporal forgery detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2023
2023
-
[30]
Avforensics: Audio-driven deepfake video detection with masking strategy,
Y . Zhu, J. Gao, and X. Zhou, “Avforensics: Audio-driven deepfake video detection with masking strategy,” inProceedings of the 2023 ACM International Conference on Multimedia Retrieval, 2023, pp. 162–171
2023
-
[31]
Video forensics: Identifying video manipulations,
L. Verdoliva, “Video forensics: Identifying video manipulations,”IEEE Signal Processing Magazine, vol. 39, no. 1, pp. 38–49, 2022
2022
-
[32]
Model attribution of face-swap deepfake videos,
S. Jia, X. Li, and S. Lyu, “Model attribution of face-swap deepfake videos,” in2022 IEEE International Conference on Image Processing (ICIP), 2022, pp. 2356–2360
2022
-
[33]
Half-truth: A partially fake audio detection dataset,
J. Yi, R. Fu, J. Tao, S. Nie, H. Ma, C. Wang, T. Wang, and C. Shao, “Half-truth: A partially fake audio detection dataset,” inInterspeech, 2022
2022
-
[34]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[35]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988
2017
-
[36]
Deepfakes and beyond: A survey of face manipulation and fake detection,
R. Tolosana, R. Vera-Rodriguez, J. Fierrez, A. Morales, and J. Ortega- Garcia, “Deepfakes and beyond: A survey of face manipulation and fake detection,” inInformation Fusion, vol. 64, 2020, pp. 131–148
2020
-
[37]
Model attribution of face-swap deepfake videos,
S. Jia, X. Li, and S. Lyu, “Model attribution of face-swap deepfake videos,”arXiv preprint arXiv:2202.12951, 2022
-
[38]
Do you really mean that? content driven audio-visual deepfake dataset and multimodal method for temporal forgery localization,
Z. Cai, K. Stefanov, A. Dhall, and M. Hayat, “Do you really mean that? content driven audio-visual deepfake dataset and multimodal method for temporal forgery localization,” in2023 IEEE International Conference on Digital Image Computing: Techniques and Applications (DICTA), 2022
2022
-
[39]
Celeb-df: A large-scale challenging dataset for deepfake forensics,
Y . Li, X. Yang, P. Sun, H. Qi, and S. Lyu, “Celeb-df: A large-scale challenging dataset for deepfake forensics,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3207–3216
2020
-
[40]
The DeepFake Detection Challenge (DFDC) Dataset
B. Dolhansky, J. Bitton, B. Pflaum, J. Lu, R. Howes, M. Wang, and C. C. Ferrer, “The deepfake detection challenge (dfdc) dataset,”arXiv preprint arXiv:2006.07397, 2020
work page internal anchor Pith review arXiv 2006
-
[41]
Exposing DeepFake Videos By Detecting Face Warping Artifacts
P. Korshunov and S. Marcel, “Deepfakes and face swap: Detection and generation,”arXiv preprint arXiv:1811.00656, 2018
work page Pith review arXiv 2018
-
[42]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” International Conference on Learning Representations (ICLR), 2019
2019
-
[43]
How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks),
A. Bulat and G. Tzimiropoulos, “How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks),” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 1021–1030
2017
-
[44]
A theory of learning from different domains,
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,”Machine Learning, vol. 79, no. 1, pp. 151–175, 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.