Recognition: unknown
Differentially Private Contrastive Learning via Bounding Group-level Contribution
Pith reviewed 2026-05-07 13:02 UTC · model grok-4.3
The pith
Bounding group-level contributions in contrastive objectives reduces gradient sensitivity enough for effective differential privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DP-GCL partitions every training batch into small disjoint groups, restricts the negative samples available to each anchor to only the other members of its group, and compensates for the lost diversity by creating additional negative views through intra-group data augmentation; this structural change bounds the contribution of any single group to the overall loss, thereby lowering the sensitivity of the gradient and allowing differential privacy noise to be calibrated more tightly without erasing the contrastive signal.
What carries the argument
Group partitioning that localizes negative sampling and gradient dependence within small disjoint subsets of each batch.
If this is right
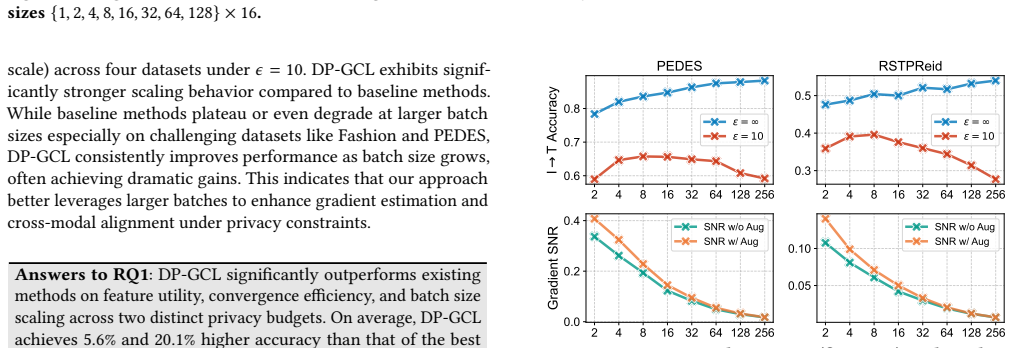
- Image classification accuracy improves by 5.6 percent over existing DP contrastive methods under the same privacy budgets.
- Image-text retrieval accuracy improves by 20.1 percent over existing DP contrastive methods under the same privacy budgets.
- The gains hold across both uni-modal and multi-modal contrastive settings on eight different datasets.
- Practical privacy budgets become usable for representation learning where previous DP contrastive methods produced unusable models.
Where Pith is reading between the lines
- The same grouping idea could be applied to other self-supervised objectives that rely on large negative sets, such as masked language modeling or graph contrastive learning.
- Group size becomes a tunable hyper-parameter that trades privacy benefit against representation quality; systematic sweeps of group size would reveal the operating range.
- In federated or distributed training, the grouping could be aligned with data partitions across clients to further control cross-client gradient leakage.
Load-bearing premise
That the loss of cross-group negative diversity can be offset by intra-group augmentation without damaging the quality of the learned representations.
What would settle it
An experiment in which DP-GCL representations achieve lower accuracy than a standard DP contrastive baseline on the same datasets and privacy budgets, or a direct measurement showing that per-sample gradient norms do not decrease when negatives are restricted to the group.
Figures








read the original abstract
Differentially private (DP) contrastive learning aims to learn general-purpose representations from sensitive data, alleviating the privacy leakage concerns of organizations deploying or sharing embedding models trained on private user content. However, existing approaches suffer from severe utility degradation due to the over-strong inter-sample dependency inherent in standard contrastive objectives, where each sample's gradient depends on all other samples in the batch, amplifying the impact of DP noise. In this work, we argue that effective DP contrastive learning requires explicitly reducing such intrinsic inter-sample reliance. To this end, we propose DP-GCL, a principled DP contrastive learning framework that structurally limits gradient dependency through bounding group-level contribution. DP-GCL partitions each batch into small, disjoint groups and restricts available negative samples to within-group samples, thereby localizing gradient influence and reducing sensitivity. To counteract the resulting loss of negative sample diversity, we further introduce intra-group augmentation, which generates additional negative views without increasing privacy cost. Extensive experiments across eight datasets demonstrate that DP-GCL consistently advances the state of the art in both uni-modal and multi-modal contrastive learning under practical privacy budgets: it improves image classification accuracy by 5.6% and image-text retrieval accuracy by 20.1% over existing DP contrastive methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DP-GCL, a differentially private contrastive learning method that partitions each batch into small disjoint groups, restricts negative samples to within-group instances, and applies intra-group augmentation to offset reduced negative diversity. This structural change is intended to localize gradient contributions, bound per-group sensitivity, and thereby reduce the impact of DP noise while preserving contrastive objective quality. The authors report consistent SOTA improvements across eight datasets: +5.6% image classification accuracy and +20.1% image-text retrieval accuracy over prior DP contrastive baselines under practical privacy budgets.
Significance. If the empirical gains prove robust under full experimental scrutiny, ablations, and theoretical grounding, the work would meaningfully advance privacy-preserving representation learning by offering a practical mechanism to mitigate inter-sample dependency in contrastive objectives. This could enable higher-utility DP embeddings for sensitive domains such as user-generated content or medical data, with the group-bounding idea potentially generalizable beyond contrastive learning.
major comments (2)
- [§3] §3 (Method, group partitioning and intra-group augmentation): The claim that restricting negatives to small disjoint groups plus intra-group augmentation preserves contrastive objective quality (alignment/uniformity) is central to the utility gains. However, if groups contain semantically similar samples, the generated views may produce easy or correlated negatives rather than hard ones, undermining the compensation mechanism. Concrete evidence—such as negative hardness metrics, embedding uniformity scores, or ablation on group size vs. diversity—is required to substantiate that the reported 5.6%/20.1% gains stem from this design rather than dataset artifacts or incomplete baselines.
- [§4] §4 (Experiments): The abstract asserts SOTA advances with specific percentage improvements, yet the provided description supplies no experimental details, full baseline tables, ablation studies on group size/privacy budget, statistical significance tests, or reproducibility information. Without these, the support for the central empirical claim cannot be assessed, and the weakest assumption (that intra-group augmentation fully offsets lost negative diversity) remains untested.
minor comments (1)
- [Abstract] Abstract: The high-level description of the fix is clear, but the lack of any equation or pseudocode for the modified contrastive loss or sensitivity bound makes it difficult to verify the 'bounding group-level contribution' claim at a glance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the presentation of our method and experiments. We have revised the manuscript to incorporate additional evidence and details as outlined below.
read point-by-point responses
-
Referee: [§3] §3 (Method, group partitioning and intra-group augmentation): The claim that restricting negatives to small disjoint groups plus intra-group augmentation preserves contrastive objective quality (alignment/uniformity) is central to the utility gains. However, if groups contain semantically similar samples, the generated views may produce easy or correlated negatives rather than hard ones, undermining the compensation mechanism. Concrete evidence—such as negative hardness metrics, embedding uniformity scores, or ablation on group size vs. diversity—is required to substantiate that the reported 5.6%/20.1% gains stem from this design rather than dataset artifacts or incomplete baselines.
Authors: We agree that direct validation of contrastive objective preservation is essential to rule out easy negatives or dataset-specific effects. Groups are formed via random batch partitioning (as stated in §3.2), which on average preserves semantic diversity across large-scale datasets. In the revised manuscript, we have added to §3 and Appendix C: negative hardness metrics (mean cosine similarity between anchor and in-group negatives), embedding uniformity scores (via the uniformity loss), and group-size ablations (sizes 2–32) showing that intra-group augmentation maintains alignment/uniformity comparable to full-batch baselines while reducing sensitivity. These metrics confirm the compensation mechanism, and performance gains hold under multiple random partitions and seeds, indicating they are not artifacts. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts SOTA advances with specific percentage improvements, yet the provided description supplies no experimental details, full baseline tables, ablation studies on group size/privacy budget, statistical significance tests, or reproducibility information. Without these, the support for the central empirical claim cannot be assessed, and the weakest assumption (that intra-group augmentation fully offsets lost negative diversity) remains untested.
Authors: We acknowledge that the initial experimental section required expansion for full scrutiny. The revised §4 now includes: complete baseline tables across all eight datasets with both DP and non-DP methods; ablations on group size and privacy budgets (ε ∈ {1,2,4,8}); paired t-test statistical significance (p < 0.05 reported for gains); and a reproducibility subsection with hyperparameters, seeds, and anonymized code link. Additional ablation removing intra-group augmentation shows clear degradation, directly testing the offset of negative diversity loss. These changes provide the requested support for the reported improvements. revision: yes
Circularity Check
No significant circularity in algorithmic construction
full rationale
The paper proposes DP-GCL as a new algorithmic framework that partitions batches into disjoint groups, restricts negatives to intra-group samples, and compensates via intra-group augmentation to bound gradient sensitivity for differential privacy. This is presented as a structural design choice motivated by reducing inter-sample dependency in contrastive objectives, supported by empirical results across datasets. No equations, derivations, or first-principles predictions are described that reduce by construction to fitted parameters, self-referential quantities, or self-citation chains. The central claims rest on external empirical validation rather than tautological reductions, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- group size
axioms (1)
- domain assumption Limiting negative samples to within small groups reduces the sensitivity of the contrastive loss to individual data points.
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Andy Chu, Ian J. Goodfellow, and et al. 2016. Deep Learning with Differential Privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. https://doi.org/10.1145/2976749.2978318
-
[2]
Péter Bándi, Oscar Geessink, and et al. 2019. From Detection of Individual Metastases to Classification of Lymph Node Status at the Patient Level: The CAMELYON17 Challenge.IEEE Trans. Medical Imaging(2019). https://doi.org/ 10.1109/TMI.2018.2867350
-
[3]
Zhiqi Bu, Yu-Xiang Wang, Sheng Zha, and George Karypis. 2023. Automatic Clipping: Differentially Private Deep Learning Made Easier and Stronger. In Advances in Neural Information Processing Systems
2023
-
[4]
Krishna Chaitanya, Ertunc Erdil, Neerav Karani, and Ender Konukoglu. 2020. Contrastive learning of global and local features for medical image segmentation with limited annotations. InAdvances in Neural Information Processing Systems
2020
-
[5]
Changyou Chen, Jianyi Zhang, and et al. 2022. Why do We Need Large Batchsizes in Contrastive Learning? A Gradient-Bias Perspective. InAdvances in Neural Information Processing Systems
2022
-
[6]
Ting Chen, Simon Kornblith, and et al. 2020. A Simple Framework for Contrastive Learning of Visual Representations. InProceedings of the 37th International Con- ference on Machine Learning, ICML
2020
-
[7]
Sumit Chopra, Raia Hadsell, and Yann LeCun. 2005. Learning a Similarity Metric Discriminatively, with Application to Face Verification. InIEEE Conference on Computer Vision and Pattern Recognition
2005
-
[8]
Jia Deng, Wei Dong, Richard Socher, and et al. 2009. ImageNet: A large-scale hierarchical image database. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR. 248–255. https://doi.org/10.1109/CVPR. 2009.5206848
-
[9]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam D. Smith. 2006. Cali- brating Noise to Sensitivity in Private Data Analysis. InTCC. 265–284
2006
-
[10]
Junyao Gao, Xinyang Jiang, Huishuai Zhang, Yifan Yang, Shuguang Dou, Dong- sheng Li, Duoqian Miao, Cheng Deng, and Cairong Zhao. 2023. Similarity Dis- tribution Based Membership Inference Attack on Person Re-identification. In Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI
2023
-
[11]
Badih Ghazi, Noah Golowich, Ravi Kumar, Pasin Manurangsi, and Chiyuan Zhang. 2021. Deep Learning with Label Differential Privacy. InAdvances in Neural Information Processing Systems. 27131–27145
2021
-
[12]
Chen Gong, Kecen Li, Zinan Lin, and Tianhao Wang. 2025. Dpimagebench: A unified benchmark for differentially private image synthesis. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. 4139–4153
2025
- [13]
-
[14]
Sivakanth Gopi, Yin Tat Lee, and Lukas Wutschitz. 2021. Numerical Composition of Differential Privacy. InAdvances in Neural Information Processing Systems
2021
-
[15]
Jean-Bastien Grill, Florian Strub, and et al. 2020. Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning. InAdvances in Neural Information Processing Systems
2020
-
[16]
Raia Hadsell, Sumit Chopra, and Yann LeCun. 2006. Dimensionality Reduction by Learning an Invariant Mapping. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)
2006
-
[17]
Girshick
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. 2022. Masked Autoencoders Are Scalable Vision Learners. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR
2022
-
[18]
Kaiming He, Haoqi Fan, and et al. 2020. Momentum Contrast for Unsupervised Visual Representation Learning. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR
2020
-
[19]
Xinlei He and Yang Zhang. 2021. Quantifying and Mitigating Privacy Risks of Contrastive Learning. InCCS ’21: 2021 ACM SIGSAC Conference on Computer and Communications Security
2021
-
[20]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. 2019. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing(2019)
2019
-
[21]
Mengdi Huai, Di Wang, Chenglin Miao, Jinhui Xu, and Aidong Zhang. 2020. Pairwise Learning with Differential Privacy Guarantees. InThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI
2020
-
[22]
Alyssa Huang, Peihan Liu, Ryumei Nakada, Linjun Zhang, and Wanrong Zhang
- [23]
-
[24]
Ding Jiang and Mang Ye. 2023. Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR
2023
-
[25]
Yuming Jiang, Shuai Yang, Haonan Qiu, Wayne Wu, Chen Change Loy, and Ziwei Liu. 2022. Text2Human: Text-Driven Controllable Human Image Generation. ACM Transactions on Graphics (TOG)(2022). https://doi.org/10.1145/3528223. 3530104
-
[26]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. In3rd International Conference on Learning Representations, ICLR
2015
-
[27]
Weiwei Kong, Andrés Muñoz Medina, and Mónica Ribero. 2025. Differentially private optimization for non-decomposable objective functions. InThe Thirteenth International Conference on Learning Representations, ICLR
2025
-
[28]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
- [29]
-
[30]
Kecen Li, Chen Gong, and et al. 2024. PrivImage: Differentially Private Synthetic Image Generation using Diffusion Models with Semantic-Aware Pretraining. In 33rd USENIX Security Symposium, USENIX Security
2024
-
[31]
Kecen Li, Chen Gong, Xiaochen Li, Yuzhong Zhao, Xinwen Hou, and Tianhao Wang. 2025. From Easy to Hard: Building a Shortcut for Differentially Private Image Synthesis. In2025 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 3656–3674
2025
-
[32]
Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang
-
[33]
In2017 IEEE Conference on Computer Vision and Pattern Recognition
Person Search with Natural Language Description. In2017 IEEE Conference on Computer Vision and Pattern Recognition
-
[34]
Wenjun Li, Anli Yan, and et al. 2022. DPCL: Contrastive representation learning with differential privacy.Int. J. Intell. Syst.(2022)
2022
-
[35]
Hongbin Liu, Jinyuan Jia, Wenjie Qu, and Neil Zhenqiang Gong. 2021. EncoderMI: Membership Inference against Pre-trained Encoders in Contrastive Learning. InCCS ’21: 2021 ACM SIGSAC Conference on Computer and Communications Security
2021
-
[36]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regulariza- tion. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net
2019
-
[37]
Yiwei Ma, Guohai Xu, and et al. 2022. X-CLIP: End-to-End Multi-grained Con- trastive Learning for Video-Text Retrieval. InMM ’22: The 30th ACM International Conference on Multimedia
2022
-
[38]
Anqi Mao, Mehryar Mohri, and Yutao Zhong. 2023. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. InInternational Conference on Machine Learning, ICML
2023
-
[39]
Ilya Mironov. 2017. Rényi differential privacy. In2017 IEEE 30th computer security foundations symposium (CSF). IEEE, 263–275
2017
-
[40]
Alec Radford, Jong Wook Kim, and et al. 2021. Learning Transferable Visual Mod- els From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning, ICML
2021
-
[41]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, and et al. 2022. High- Resolution Image Synthesis with Latent Diffusion Models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR
2022
- [42]
-
[43]
Tom Sander, Yaodong Yu, and et al. 2024. Differentially Private Representation Learning via Image Captioning. InForty-first International Conference on Machine Learning, ICML
2024
-
[44]
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. FaceNet: A unified embedding for face recognition and clustering. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR
2015
-
[45]
Zhouxing Shi, Yihan Wang, and et al. 2022. Efficiently Computing Local Lipschitz Constants of Neural Networks via Bound Propagation. InAdvances in Neural Information Processing Systems
2022
-
[46]
Kihyuk Sohn. 2016. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. InAdvances in Neural Information Processing Systems
2016
-
[47]
Congzheng Song and Ananth Raghunathan. 2020. Information Leakage in Em- bedding Models. InCCS ’20: 2020 ACM SIGSAC Conference on Computer and Communications Security
2020
-
[48]
Ruining Sun, Hongsheng Hu, and et al. 2025. When Better Features Mean Greater Risks: The Performance-Privacy Trade-Off in Contrastive Learning. InProceedings of the 20th ACM Asia Conference on Computer and Communications Security, ASIA CCS
2025
-
[49]
Michael Tschannen, Alexey A. Gritsenko, and et al. 2025. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features.CoRRabs/2502.14786 (2025)
work page internal anchor Pith review arXiv 2025
-
[50]
Han Xiao, Kashif Rasul, and Roland Vollgraf. 2017. Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms.CoRR(2017)
2017
-
[51]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive Learning for Sequential Recommendation. In38th IEEE International Conference on Data Engineering, ICDE
2022
-
[52]
Collins, and et al
Zheng Xu, Maxwell D. Collins, and et al. 2023. Learning to Generate Image Embeddings with User-Level Differential Privacy. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR
2023
-
[53]
Zhiyu Xue, Shaoyang Yang, Mengdi Huai, and Di Wang. 2021. Differentially Private Pairwise Learning Revisited. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI. 13
2021
- [54]
-
[55]
Yaodong Yu, Maziar Sanjabi, Yi Ma, Kamalika Chaudhuri, and Chuan Guo. 2024. ViP: A Differentially Private Foundation Model for Computer Vision. InForty-first International Conference on Machine Learning, ICML
2024
-
[56]
Zheng Yuan, Qiao Jin, and et al. 2023. RAMM: Retrieval-augmented Biomedical Visual Question Answering with Multi-modal Pre-training. InACM International Conference on Multimedia, MM
2023
-
[57]
Aichun Zhu, Zijie Wang, and et al. 2021. DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval. InMM ’21: ACM Multimedia Conference
2021
-
[58]
Jie Zhu, Jirong Zha, Ding Li, and Leye Wang. 2024. A Unified Membership Infer- ence Method for Visual Self-supervised Encoder via Part-aware Capability. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communi- cations Security, CCS
2024
-
[59]
Alexander Ziller, Dmitrii Usynin, Rickmer Braren, Marcus Makowski, Daniel Rueckert, and Georgios Kaissis. 2021. Medical imaging deep learning with differential privacy.Scientific Reports11, 1 (2021), 13524. Ethics Considerations We structure the ethical considerations by linking our stakeholder analysis to the impacts during the research process (data han...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.