Recognition: unknown
Understanding DNNs in Feature Interaction Models: A Dimensional Collapse Perspective
Pith reviewed 2026-05-07 13:30 UTC · model grok-4.3
The pith
DNNs mitigate dimensional collapse of embeddings in feature interaction models rather than capturing high-order interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Both parallel and stacked DNNs effectively mitigate the dimensional collapse of embeddings in feature interaction recommendation models. Gradient-based theoretical analysis, supported by empirical evidence from overall and ablation studies, uncovers the underlying mechanisms of dimensional collapse and its mitigation by DNN structures.
What carries the argument
Dimensional collapse of embeddings, where representations lose effective dimensionality, mitigated by parallel or stacked DNN components through gradient dynamics.
If this is right
- Reconciles prior conflicting claims by showing DNN benefits arise from collapse mitigation instead of high-order interaction capture.
- Model improvements in these systems can target embedding stability directly without assuming interaction-order learning.
- Ablation studies should separate collapse effects from other DNN contributions to isolate performance drivers.
- Design of future feature interaction models can prioritize DNN placements that preserve embedding dimensionality.
Where Pith is reading between the lines
- Simpler techniques like targeted regularization on embedding norms might replicate DNN benefits at lower cost.
- The collapse-mitigation view could apply to embedding-based models outside recommendations, such as in language or graph tasks.
- Direct measurement of embedding rank or effective dimension before and after DNN addition would test the mechanism cleanly.
- Performance attribution studies could quantify the fraction of gains due to collapse reduction versus added parameters.
Load-bearing premise
Observed mitigation stems specifically from improved dimensional robustness of representations rather than general increases in model capacity or unmeasured factors.
What would settle it
An experiment that matches DNN and non-DNN model capacity while measuring embedding dimensionality metrics and finds no reduction in collapse or performance gain from the DNN.
Figures


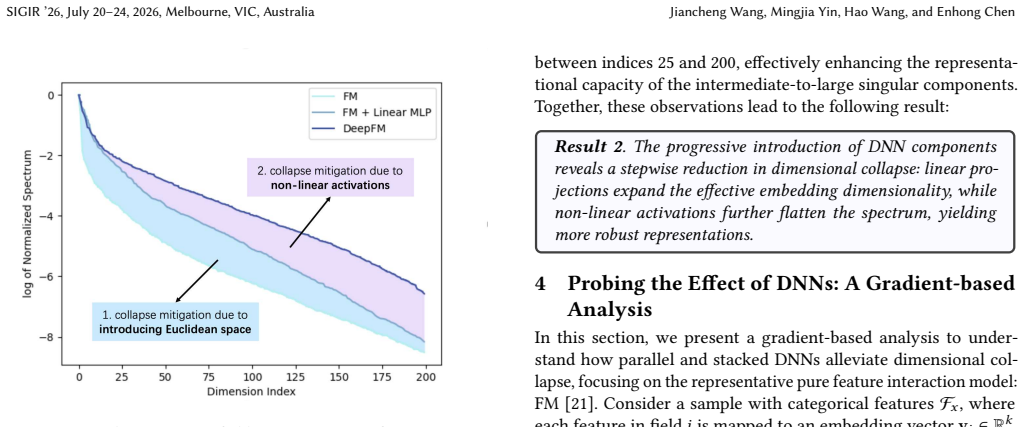

read the original abstract
DNNs have gained widespread adoption in feature interaction recommendation models. However, there has been a longstanding debate on their roles. On one hand, some works claim that DNNs possess the ability to implicitly capture high-order feature interactions. Conversely, recent studies have highlighted the limitations of DNNs in effectively learning dot products, specifically second-order interactions, let alone higher-order interactions. In this paper, we present a novel perspective to understand the effectiveness of DNNs: their impact on the dimensional robustness of the representations. In particular, we conduct extensive experiments involving both parallel DNNs and stacked DNNs. Our evaluation encompasses an overall study of complete DNN on two feature interaction models, alongside a fine-grained ablation analysis of components within DNNs. Experimental results demonstrate that both parallel and stacked DNNs can effectively mitigate the dimensional collapse of embeddings. Furthermore, a gradient-based theoretical analysis, supported by empirical evidence, uncovers the underlying mechanisms of dimensional collapse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that DNNs in feature interaction recommendation models mitigate the dimensional collapse of embeddings by enhancing the dimensional robustness of representations. This is demonstrated through extensive experiments on parallel and stacked DNNs in two feature interaction models, including overall studies and fine-grained ablations, along with a gradient-based theoretical analysis supported by empirical evidence.
Significance. If the central claim holds, this work provides a novel perspective on the longstanding debate regarding the role of DNNs in capturing feature interactions, shifting focus from high-order interaction learning to representation robustness. This could have implications for designing more effective recommendation models and understanding embedding behaviors in deep learning.
major comments (2)
- [Experimental Evaluation] The experimental evaluation (overall study and fine-grained ablations) does not include capacity-matched controls. Adding parallel or stacked DNNs necessarily increases parameter count and introduces non-linear transformations, yet no comparisons are made to equivalent-capacity baselines such as wider linear layers or expanded embedding dimensions. Without these, reductions in dimensional collapse cannot be securely attributed to the claimed dimensional-robustness mechanism rather than generic capacity or optimization effects.
- [Gradient-based Theoretical Analysis] The gradient-based theoretical analysis relies on assumptions about gradient flow through the embeddings and DNN components. The manuscript does not verify that these assumptions remain valid when isolating the DNN contribution from overall model capacity changes, leaving the mechanistic explanation vulnerable to the same confound identified in the experiments.
minor comments (2)
- [Abstract] The abstract refers to 'two feature interaction models' without naming them (e.g., FM, DeepFM, or similar); explicit identification would improve readability and allow immediate contextualization of the results.
- [Notation and Definitions] Notation for the dimensional collapse metric and embedding dimensions should be defined more explicitly at first use to avoid ambiguity in the theoretical and experimental sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important considerations for strengthening the experimental and theoretical claims. We address each major comment below and will revise the manuscript to incorporate capacity-controlled experiments and additional validation of the gradient analysis.
read point-by-point responses
-
Referee: [Experimental Evaluation] The experimental evaluation (overall study and fine-grained ablations) does not include capacity-matched controls. Adding parallel or stacked DNNs necessarily increases parameter count and introduces non-linear transformations, yet no comparisons are made to equivalent-capacity baselines such as wider linear layers or expanded embedding dimensions. Without these, reductions in dimensional collapse cannot be securely attributed to the claimed dimensional-robustness mechanism rather than generic capacity or optimization effects.
Authors: We agree that the absence of capacity-matched controls represents a limitation in the current experimental design. While the fine-grained ablations vary DNN components (e.g., depth, width, and activations) within fixed overall architectures, they do not explicitly match total parameter counts against non-DNN alternatives. To address this, we will add in the revised manuscript new baselines that control for capacity, including (i) linear layers with parameter counts matched to the DNN variants and (ii) models with expanded embedding dimensions that achieve equivalent effective capacity without non-linear transformations. These will be evaluated using the same dimensional collapse metrics on the two feature interaction models, allowing clearer attribution to the robustness mechanism. revision: yes
-
Referee: [Gradient-based Theoretical Analysis] The gradient-based theoretical analysis relies on assumptions about gradient flow through the embeddings and DNN components. The manuscript does not verify that these assumptions remain valid when isolating the DNN contribution from overall model capacity changes, leaving the mechanistic explanation vulnerable to the same confound identified in the experiments.
Authors: The gradient analysis applies the chain rule to the embedding gradients, accounting for the multiplicative effect of the DNN Jacobian. Empirical measurements of gradient norms and directional alignment in our experiments support the derived mechanism. We acknowledge that the assumptions have not been explicitly re-validated under capacity-matched conditions, creating a potential confound. In the revision, we will extend the analysis with additional derivations and simulations that hold total parameter count fixed (comparing DNN paths to linear equivalents) and include corresponding empirical checks on gradient statistics across the same datasets and models. revision: yes
Circularity Check
No significant circularity detected; claims rest on independent experiments and analysis
full rationale
The paper grounds its central claims in extensive empirical evaluations of parallel and stacked DNNs on feature interaction models, plus a separate gradient-based theoretical analysis of mechanisms. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain. The mitigation of dimensional collapse is presented as an observed outcome supported by ablations and theory, not as a tautological renaming or prediction forced by the inputs. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embeddings are updated via gradient descent in feature interaction models
Reference graph
Works this paper leans on
-
[1]
Avazu Dataset
2014. Avazu Dataset. https://www.kaggle.com/competitions/avazu-ctr- prediction/data
2014
-
[2]
Criteo Dataset
2014. Criteo Dataset. https://www.kaggle.com/c/criteo-display-ad-challenge/ data
2014
-
[3]
Adrien Bardes, Jean Ponce, and Yann LeCun. 2021. Vicreg: Variance- invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906(2021)
work page internal anchor Pith review arXiv 2021
-
[4]
Alex Beutel, Paul Covington, Sagar Jain, Can Xu, Jia Li, Vince Gatto, and Ed H Chi. 2018. Latent cross: Making use of context in recurrent recommender systems. InProceedings of the eleventh ACM international conference on web search and data mining. 46–54
2018
-
[5]
Huiyuan Chen, Vivian Lai, Hongye Jin, Zhimeng Jiang, Mahashweta Das, and Xia Hu. 2024. Towards mitigating dimensional collapse of representations in collaborative filtering. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 106–115
2024
-
[6]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[7]
InProceedings of the 1st workshop on deep learning for recommender systems
Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
-
[8]
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann Lecun. 2023. Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank. InInternational conference on machine learning. PMLR, 10929–10974
2023
- [9]
-
[10]
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, and Mingsheng Long. 2024. On the Embedding Collapse when Scaling up Recommendation Models.International Conference on Machine Learning (ICML)(2024)
2024
-
[11]
Junlin He, Jinxiao Du, and Wei Ma. 2024. Preventing dimensional collapse in self-supervised learning via orthogonality regularization.Advances in Neural Information Processing Systems37 (2024), 95579–95606
2024
-
[12]
Xiangnan He and Tat-Seng Chua. 2017. Neural factorization machines for sparse predictive analytics. InProceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. 355–364
2017
-
[13]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: combining fea- ture importance and bilinear feature interaction for click-through rate prediction. InProceedings of the 13th ACM Conference on Recommender Systems. 169–177
2019
-
[14]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. 2021. Understanding Dimensional Collapse in Contrastive Self-supervised Learning. InICLR
2021
-
[15]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature in- teractions for recommender systems. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD). 1754–1763
2018
-
[16]
Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, and Zhenhua Dong
- [17]
-
[18]
Kelong Mao, Jieming Zhu, Jinpeng Wang, Quanyu Dai, Zhenhua Dong, Xi Xiao, and Xiuqiang He. 2021. SimpleX: A simple and strong baseline for collaborative filtering. InProceedings of the 30th ACM International Conference on Information & Knowledge Management. 1243–1252
2021
-
[19]
Junwei Pan, Jian Xu, Alfonso Lobos Ruiz, Wenliang Zhao, Shengjun Pan, Yu Sun, and Quan Lu. 2018. Field-weighted factorization machines for click-through rate prediction in display advertising. InProceedings of the 2018 World Wide Web Conference (WWW). 1349–1357
2018
-
[20]
Junwei Pan, Wei Xue, Ximei Wang, Haibin Yu, Xun Liu, Shijie Quan, Xueming Qiu, Dapeng Liu, Lei Xiao, and Jie Jiang. 2024. Ads recommendation in a collapsed SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Jiancheng Wang, Mingjia Yin, Hao Wang, and Enhong Chen and entangled world. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery...
2024
-
[21]
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive learning for representation degeneration problem in sequential recommendation. InProceedings of the fifteenth ACM international conference on web search and data mining. 813–823
2022
-
[22]
Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, Yong Yu, Ying Wen, and Jun Wang
-
[23]
In2016 IEEE 16th International Conference on Data Mining (ICDM)
Product-based neural networks for user response prediction. In2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 1149–1154
-
[24]
Steffen Rendle. 2010. Factorization machines. In2010 IEEE International Confer- ence on Data Mining (ICDM). IEEE, 995–1000
2010
-
[25]
Steffen Rendle, Walid Krichene, Li Zhang, and John Anderson. 2020. Neural collab- orative filtering vs. matrix factorization revisited. InFourteenth ACM conference on recommender systems. 240–248
2020
-
[26]
Claude E Shannon. 1951. Prediction and entropy of printed English.Bell system technical journal30, 1 (1951), 50–64
1951
-
[27]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self- attentive neural networks. InProceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM). 1161–1170
2019
-
[28]
Yang Sun, Junwei Pan, Alex Zhang, and Aaron Flores. 2021. Fm2: Field-matrixed factorization machines for recommender systems. InProceedings of the Web Conference 2021. 2828–2837
2021
-
[29]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. DCN-V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the Web Conference (WWW). 1785–1797
2021
-
[30]
Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, Jianxun Lian, and Xing Xie. 2021. Self-supervised graph learning for recommendation. InProceed- ings of the 44th international ACM SIGIR conference on research and development in information retrieval. 726–735
2021
- [31]
-
[32]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? simple graph contrastive learning for recommendation. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1294–1303
2022
- [33]
-
[34]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recom- mender system: A survey and new perspectives.ACM computing surveys (CSUR) 52, 1 (2019), 1–38
2019
-
[35]
Weinan Zhang, Tianming Du, and Jun Wang. 2016. Deep learning over multi-field categorical data. InEuropean conference on information retrieval. Springer, 45–57
2016
- [36]
-
[37]
Yifei Zhang, Hao Zhu, Zixing Song, Piotr Koniusz, Irwin King, et al. 2023. Miti- gating the popularity bias of graph collaborative filtering: A dimensional collapse perspective.Advances in Neural Information Processing Systems36 (2023), 67533– 67550
2023
-
[38]
Jieming Zhu, Quanyu Dai, Liangcai Su, Rong Ma, Jinyang Liu, Guohao Cai, Xi Xiao, and Rui Zhang. 2022. Bars: Towards open benchmarking for recommender systems. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2912–2923
2022
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.