A Multi-Dataset Benchmark of Multiple Instance Learning for 3D Neuroimage Classification
Pith reviewed 2026-05-07 10:55 UTC · model grok-4.3
The pith
Simple mean pooling over 2D slice embeddings matches or beats attention-based MIL and 3D CNNs for neuroimage classification while training 25 times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
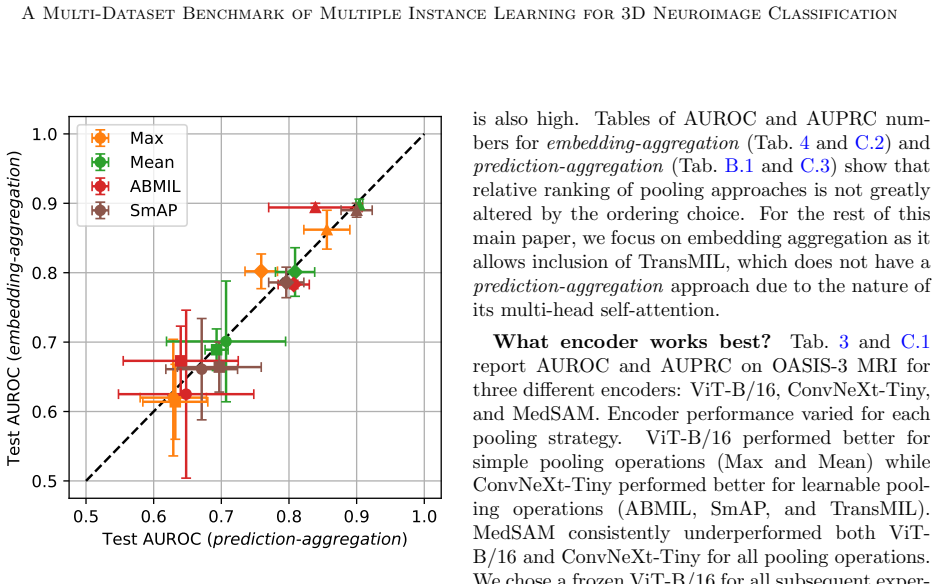
Simple mean pooling MIL, with a frozen pre-trained 2D encoder applied to each slice of a 3D volume followed by averaging and a linear classifier, matches or outperforms recent attention-based MIL and 3D CNN or ViT alternatives on 4 of 6 moderate-sized tasks across three CT and four MRI datasets. The same baseline remains competitive on two large datasets of at least 10,000 scans while training 25 times faster. Systematic comparisons of encoders, pooling operations, and architectural orderings, together with attention-quality analysis and a semi-synthetic dataset allowing exact Bayes-optimal classification, reveal the limits of existing learnable-attention MIL methods.
What carries the argument
Simple mean pooling over per-slice embeddings produced by a frozen 2D pre-trained encoder, which aggregates 2D slice information without any learnable attention weights before final classification.
If this is right
- Mean pooling MIL supplies a fast, strong baseline that practitioners can adopt for many 3D neuroimage tasks without accuracy loss.
- Learnable attention mechanisms do not reliably improve over uniform averaging when slices are processed by a strong frozen 2D encoder.
- The relative advantage of complex models shrinks on larger datasets, making simple pooling more attractive at scale.
- Attention quality checks and semi-synthetic Bayes analysis can diagnose when MIL pooling fails to capture slice-level signal.
- Future MIL designs for neuroimages should target better handling of ambiguous or uninformative slices rather than more elaborate weighting.
Where Pith is reading between the lines
- If mean pooling succeeds because many slices carry redundant diagnostic information, the same pattern may appear in other slice-based or volumetric tasks such as video or 3D microscopy classification.
- The large speed advantage suggests that research effort might be better spent improving slice-level encoders than refining pooling layers for this domain.
- Repeating the benchmark on datasets with different scanners, field strengths, or rarer pathologies would test whether the current ranking is robust.
- The semi-synthetic construction method could be reused to create controlled testbeds for MIL in other medical imaging problems where instance labels are noisy.
Load-bearing premise
The seven tested datasets and chosen pre-trained 2D encoders are representative enough that the observed performance ordering will hold for new clinical neuroimage collections, and the semi-synthetic dataset accurately reflects real slice-labeling challenges.
What would settle it
Finding a new, independent collection of 3D CT or MRI scans where attention-based MIL or 3D CNNs achieve statistically higher accuracy than mean pooling MIL at comparable training cost would falsify the central performance claim.
Figures



read the original abstract
Despite being resource-intensive to train, 3D convolutional neural networks (CNNs) have been the standard approach to classify CT and MRI scans. Recent work suggests that deep multiple instance learning (MIL) may be a more efficient alternative for 3D brain scans, especially when the pre-trained image encoder used to embed each 2D slice is frozen and only the pooling operation and classifier are trained. In this paper, we provide a systematic comparison of simple MIL, attention-based MIL, 3D CNNs, and 3D ViTs across three CT and four MRI datasets, including two large datasets of at least 10,000 scans. Our goal is to help resource-constrained practitioners understand which neural networks work well for 3D neuroimages and why. We further compare design choices for attention-based MIL, including different encoders, pooling operations, and architectural orderings. We find that simple mean pooling MIL, without any learnable attention, matches or outperforms recent MIL or 3D CNN alternatives on 4 of 6 moderate-sized tasks. This baseline remains competitive on two large datasets while being 25x faster to train. To explain mean pooling's success, we examine per-slice attention quality and a semi-synthetic dataset where we can derive the best possible classifier via a Bayes estimator. This analysis reveals the limits of existing MIL approaches and suggests routes for future improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a multi-dataset benchmark comparing simple mean-pooling multiple instance learning (MIL), attention-based MIL variants, 3D CNNs, and 3D ViTs for classifying 3D CT and MRI neuroimages. It reports that mean pooling (with frozen pre-trained 2D slice encoders) matches or outperforms the alternatives on 4 of 6 moderate-sized tasks, remains competitive on two large datasets (≥10k scans each), and trains approximately 25× faster. Explanatory analysis uses per-slice attention quality metrics and a semi-synthetic dataset whose Bayes-optimal classifier is derived to identify limits of existing attention-based MIL.
Significance. If the empirical ordering holds under fully specified protocols, the work offers immediate practical value to resource-constrained medical imaging practitioners by establishing a strong, efficient baseline that questions the necessity of learnable attention or full 3D models. The scale (seven datasets, including large ones) and direct head-to-head comparisons provide a useful reference point for the community; the attention-quality and semi-synthetic analyses, if validated, could guide future MIL design for slice-level label ambiguity.
major comments (3)
- [§4.3] §4.3 (semi-synthetic dataset construction): the sampling process for positive/negative slices, spatial correlations, and label noise is not validated against the empirical marginals or dependencies observed in the real CT/MRI collections. Because the headline explanatory claim—that existing attention MIL cannot reliably identify informative slices—rests on the Bayes estimator derived from this dataset, any mismatch directly weakens the link between the observed performance ordering and the proposed interpretation.
- [§3] §3 (experimental protocol): the manuscript omits exact train/validation/test splits (or cross-validation folds), the statistical testing procedure used to declare that mean pooling “matches or outperforms” on 4/6 tasks, and the hyperparameter search budget for all methods. These omissions are load-bearing for the central empirical claims and for the reported 25× training speedup, as different splits or untuned baselines could alter the ranking.
- [§4.2] §4.2 (per-slice attention quality analysis): the quality metrics and conclusions about attention failure modes are computed exclusively on the semi-synthetic data; without a quantitative check that the synthetic slice-label statistics reproduce those of the real datasets, the analysis cannot reliably diagnose why mean pooling succeeds on the actual clinical collections.
minor comments (2)
- Table captions and axis labels in the main result tables should explicitly state the performance metric (AUC, accuracy, etc.) and whether reported values are means over multiple runs.
- The abstract states “three CT and four MRI datasets” while the experimental section lists seven collections; a brief reconciliation sentence would prevent reader confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. The feedback identifies key areas where additional details and validations will enhance the paper's clarity and impact. We respond to each major comment point-by-point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: §3 (experimental protocol): the manuscript omits exact train/validation/test splits (or cross-validation folds), the statistical testing procedure used to declare that mean pooling “matches or outperforms” on 4/6 tasks, and the hyperparameter search budget for all methods. These omissions are load-bearing for the central empirical claims and for the reported 25× training speedup, as different splits or untuned baselines could alter the ranking.
Authors: We agree that these experimental details are essential for reproducibility and for substantiating our claims. In the revised manuscript, we will provide the exact train/validation/test splits used for each dataset, including any random seeds or standard protocols followed. We will describe the statistical testing procedure, such as the use of paired statistical tests with multiple-comparison corrections to determine when mean pooling matches or outperforms other methods. Additionally, we will report the hyperparameter search spaces, optimization methods, and computational budgets allocated to each approach, including the 3D CNNs and ViTs. These additions will allow readers to better assess the validity of the performance rankings and the training efficiency claims. revision: yes
-
Referee: [§4.3] §4.3 (semi-synthetic dataset construction): the sampling process for positive/negative slices, spatial correlations, and label noise is not validated against the empirical marginals or dependencies observed in the real CT/MRI collections. Because the headline explanatory claim—that existing attention MIL cannot reliably identify informative slices—rests on the Bayes estimator derived from this dataset, any mismatch directly weakens the link between the observed performance ordering and the proposed interpretation.
Authors: The semi-synthetic dataset was designed to capture the inherent slice-level ambiguity in 3D neuroimage classification by sampling slices with varying informativeness and introducing realistic spatial correlations and noise levels based on our observations from the real datasets. While a direct quantitative validation of the marginal distributions was not included in the original submission, the construction parameters were chosen to reflect typical clinical patterns. To strengthen the connection to real data, we will add an analysis comparing key statistics—such as the distribution of positive slice ratios, spatial dependencies, and noise characteristics—between the synthetic and real CT/MRI datasets. This will better support the use of the Bayes-optimal classifier for interpreting the limitations of attention-based MIL. revision: yes
-
Referee: [§4.2] §4.2 (per-slice attention quality analysis): the quality metrics and conclusions about attention failure modes are computed exclusively on the semi-synthetic data; without a quantitative check that the synthetic slice-label statistics reproduce those of the real datasets, the analysis cannot reliably diagnose why mean pooling succeeds on the actual clinical collections.
Authors: We recognize that the per-slice attention quality metrics, which require ground-truth slice labels, are necessarily computed on the semi-synthetic dataset. The purpose was to provide a controlled environment where we can quantify attention's ability to identify informative slices against a known Bayes-optimal baseline. To bridge to the real datasets, we will include a validation of the synthetic data's statistical properties against the real collections, as mentioned in our response to the §4.3 comment. Additionally, we will provide qualitative visualizations of attention maps on real data to illustrate similar failure modes observed in the synthetic setting. This combined approach will help explain the success of mean pooling on clinical data. revision: partial
Circularity Check
No circularity: empirical benchmark with direct comparisons
full rationale
The paper reports empirical results from training and evaluating multiple MIL variants, 3D CNNs, and ViTs on six real neuroimage datasets plus one semi-synthetic dataset. Performance claims rest on measured accuracy, AUC, and training time against held-out test splits; no functional forms are fitted and then re-predicted, no equations are derived from prior self-citations, and the Bayes estimator on the semi-synthetic data is a standard information-theoretic upper bound computed from the known generative process rather than a tautological re-use of the paper's own fitted parameters. All load-bearing steps are external data comparisons, so the derivation chain contains no self-definitional, fitted-input, or self-citation reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained 2D image encoders produce useful embeddings when applied slice-wise to 3D neuroimages
Reference graph
Works this paper leans on
-
[1]
Stefano Cerri, Oula Puonti, Dominik S
Ac- cessed: 2025-12-30. Stefano Cerri, Oula Puonti, Dominik S. Meier, Jens Wuerfel, Mark M¨ uhlau, Hartwig R. Siebner, and Koen Van Leemput. A contrast-adaptive method for simultaneous whole-brain and lesion segmenta- tion in multiple sclerosis.Neuroimage, 225:117471,
2025
-
[2]
Benoit Dufumier, Pietro Gori, Ilaria Battaglia, Julie Victor, Antoine Grigis, and Edouard Duchesnay. Benchmarking CNN on 3D Anatomical Brain MRI: Architectures, Data Augmentation and Deep En- semble Learning.arXiv preprint arXiv:2106.01132,
-
[3]
Flanders, Luciano M
Adam E. Flanders, Luciano M. Prevedello, George Shih, Safwan S. Halabi, Jayashree Kalpathy- Cramer, Robyn Ball, John T. Mongan, Anouk Stein, Felipe C. Kitamura, Matthew P. Lungren, Geetika Choudhary, Luciano Cala, Lu´ ıs Coelho, Mads Mogensen, F´ atima Mor´ on, Eric Miller, Ichiro Ikuta, Vahe Zohrabian, Oran McDonnell, Christoph Lincoln, Luciano Shah, Dev...
2019
-
[4]
URLhttps: //doi.org/10.1101/2019.12.13.19014902. Chenxi Liu, Junhua Mao, Fei Sha, and Alan Yuille. Attention Correctness in Neural Image Captioning. InProceedings of the AAAI Conference on Artifi- cial Intelligence (AAAI),
-
[5]
Clin- ica: An Open-Source Software Platform for Repro- ducible Clinical Neuroscience Studies.Frontiers in Neuroinformatics, Volume 15 - 2021,
Alexandre Routier, Ninon Burgos, Mauricio D´ ıaz, Michael Bacci, Simona Bottani, Omar El-Rifai, Sabrina Fontanella, Pietro Gori, J´ er´ emy Guil- lon, Alexis Guyot, Ravi Hassanaly, Thomas Jacquemont, Pascal Lu, Arnaud Marcoux, Tris- tan Moreau, Jorge Samper-Gonz´ alez, Marc Te- ichmann, Elina Thibeau-Sutre, Ghislain Vaillant, Junhao Wen, Adam Wild, Marie-...
2021
-
[6]
Preprocessing A.1
15 A Multi-Dataset Benchmark of Multiple Instance Learning for 3D Neuroimage Classification Appendix A. Preprocessing A.1. CT For CT images, we convert images into Hounsfield Units (HU) using each image’s rescale slope and intercept; skull strip images (only including -100 to 300 HU) (Muschelli, 2019); resize each 2D slice to 224×224 pixels for VIT-B/16 a...
2019
-
[7]
Appendix B.Prediction-AggregationAUROC Results Table B.1: Test AUROC on moderately-sized datasets
from ANTs (Avants et al., 2014); crop each image to remove background; resize each 2D slice to 224×224 pixels for VIT-B/16 and ConvNeXt-Tiny, and 1024×1024 pixels for MedSAM; and normalize images with the training set mean and standard deviation of each channel. Appendix B.Prediction-AggregationAUROC Results Table B.1: Test AUROC on moderately-sized datas...
2014
-
[8]
bags ofS i instances drawn from our Shifted Mean MIL dataset. We propose a new data-generating process designed to mimic several key challenges in real-world multiple instance medical imaging tasks: •Across the whole dataset, only some features are discriminative (KofM). •For each positively-labeled bag, only a few instances are relevant (RofS i) and they...
1970
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.