Recognition: unknown
Structure-Aware Transformers for Learning Near-Optimal Trotter Orderings with System-Size Generalization in 1D Heisenberg Hamiltonians
Pith reviewed 2026-05-07 09:27 UTC · model grok-4.3
The pith
Transformer model predicts near-optimal Trotter orderings for larger quantum systems from small-system training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
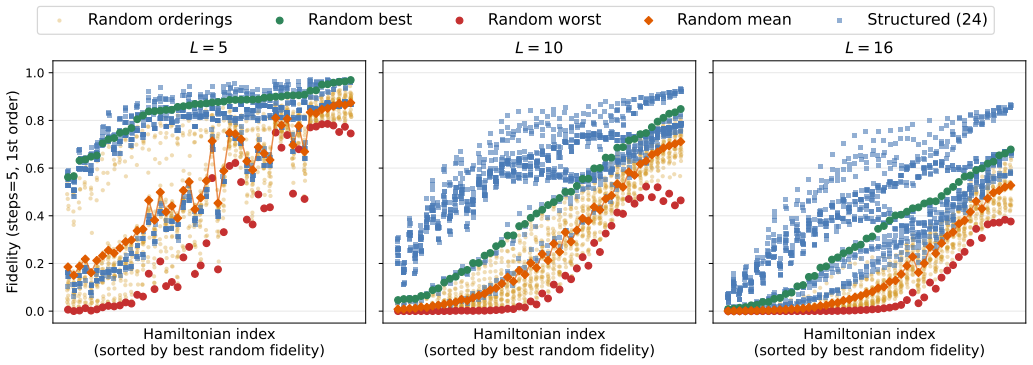
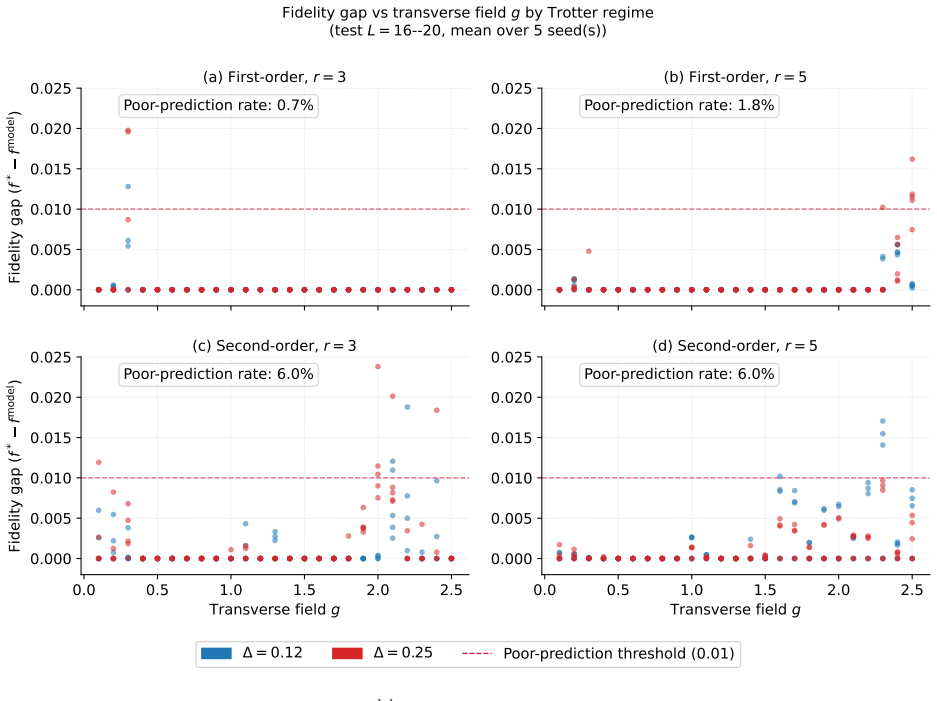
The paper establishes that a transformer encoder, trained solely on smaller systems, can select the ordering among 24 fixed candidates that minimizes the fidelity error for larger 1D XXZ chains without any fidelity computation at inference. On held-out larger sizes the average gap to the best candidate is 0.00115, and a training-size sweep shows the gap shrinks as more system sizes are included in training.
What carries the argument
The transformer encoder that takes Hamiltonian parameters and Trotter configuration features as input and outputs the predicted best ordering from the set of 24 candidates obtained from commutation graph colorings and permutations.
If this is right
- The computational cost of ordering selection stays constant with system size instead of growing with the number of candidates.
- The same trained model applies directly to system sizes outside the training range.
- Increasing the range of training system sizes steadily reduces the fidelity gap on larger test systems.
- This learned selector removes the need to evaluate all 24 orderings on big systems.
Where Pith is reading between the lines
- If the candidate set stays near-optimal for other Hamiltonian families, the approach could extend to different interaction types without new training.
- The feature-based prediction might apply to choosing orderings in other simulation methods like higher-order Trotter expansions.
- One could check whether the model still works when the underlying graph coloring candidates change for different lattice connectivities.
Load-bearing premise
The 24 candidates derived from the commutation graph include a near-optimal ordering for the systems of interest and the selected features are sufficient to learn a mapping that generalizes across system sizes.
What would settle it
Running the full fidelity comparison on systems with 21 or more qubits or on Hamiltonians with different interaction ranges and observing that the predicted ordering's fidelity gap exceeds 0.01 would disprove reliable size generalization.
Figures




read the original abstract
Trotterization is a standard approach for simulating quantum time evolution on quantum computers, where the Hamiltonian is split into local terms and each term is applied in sequence. The order of these terms affects the fidelity of the simulation when they do not commute, so the choice of ordering directly impacts the accuracy of the simulation. We study this problem for one-dimensional XXZ Heisenberg Hamiltonians using a structured set of 24 candidate orderings derived from colorings of the Hamiltonian's commutation graph and their group permutations. Finding the best candidate for large systems becomes prohibitive because fidelity evaluation is computationally expensive. In this work, we train a transformer encoder on smaller systems to predict the best candidate ordering for larger systems directly from Hamiltonian and Trotter-configuration features, without computing candidate fidelities at inference time. The model is trained on in-range systems of 3 to 14 qubits with 15-qubit systems held out for validation. Experimental results show that the model reaches a mean test fidelity gap of 0.00115 relative to the best of the 24 candidates on out-of-range systems of 16 to 20 qubits. A training-size sweep further shows that generalization emerges once training includes systems up to L=8 qubits, with validation at L=9, and the gap continues to decrease as the training range grows. To our knowledge, this is the first application of a learned model to Trotter ordering, and it motivates future work on AI-guided Trotter ordering with generalization across Hamiltonian families and system types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains a transformer encoder to select the best Trotter ordering from a fixed pool of 24 candidates (derived from commutation-graph colorings and group permutations) for 1D XXZ Heisenberg Hamiltonians. The model uses Hamiltonian and configuration features, is trained on systems of 3–14 qubits (with 15-qubit held out for validation), and is evaluated on out-of-range systems of 16–20 qubits. It reports a mean test fidelity gap of 0.00115 relative to the best candidate in the pool, without needing fidelity evaluations at inference time. A training-size sweep shows generalization emerging once training includes up to L=8 qubits.
Significance. If the 24-candidate pool remains representative of near-optimal orderings as L grows, the approach offers a scalable way to avoid expensive fidelity evaluations for large-system Trotter simulations. The work is the first learned-model application to this ordering task and receives credit for its concrete numerical results on held-out larger systems plus the training-size sweep that identifies the emergence of generalization. The significance is tempered by the fact that all claims are relative to the fixed pool rather than to globally optimal orderings.
major comments (2)
- [Abstract] Abstract and experimental results: The title and abstract claim the model learns 'near-optimal' Trotter orderings, yet the only quantitative support is a mean fidelity gap of 0.00115 to the best of the 24 candidates on L=16–20. No evidence is given that the best-of-24 is itself within ~0.001 of the true optimum for these sizes (exhaustive search is intractable, and no comparison to stronger heuristics or exhaustive optima on small L is reported). This assumption is load-bearing for the central claim.
- [Experimental results] Experimental results section: The manuscript provides no details on the exact transformer architecture (number of layers, heads, embedding dimension), the precise feature engineering for Hamiltonian and Trotter-configuration inputs, or statistical error bars on the reported fidelity gaps across multiple random seeds or runs. These omissions hinder assessment of whether the observed size generalization is robust.
minor comments (3)
- The training-size sweep is described qualitatively ('generalization emerges once training includes systems up to L=8'); quantitative details on validation performance at each training cutoff and the exact held-out protocol would strengthen the generalization narrative.
- No baseline comparisons are reported (e.g., random selection from the 24, a simple MLP, or non-learned heuristics). Including at least one such baseline would clarify the added value of the transformer.
- The paper would benefit from a brief discussion of how the 24 candidates were generated (exact coloring algorithm and permutation enumeration) and whether the pool size was chosen by ablation.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment point-by-point below, proposing revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: The title and abstract claim the model learns 'near-optimal' Trotter orderings, yet the only quantitative support is a mean fidelity gap of 0.00115 to the best of the 24 candidates on L=16–20. No evidence is given that the best-of-24 is itself within ~0.001 of the true optimum for these sizes (exhaustive search is intractable, and no comparison to stronger heuristics or exhaustive optima on small L is reported). This assumption is load-bearing for the central claim.
Authors: We appreciate this observation. Our use of 'near-optimal' is intended to refer to orderings that are optimal or near-optimal within the structured pool of 24 candidates, which are systematically generated from commutation-graph colorings and permutations. This pool is motivated by prior work on Trotter ordering and is expected to contain high-fidelity options. While we do not claim or demonstrate that the best-of-24 matches the global optimum for large L (which is computationally infeasible), the model's ability to select from this pool with a small fidelity gap of 0.00115 provides a practical advantage by avoiding expensive evaluations. To address the concern, we will revise the abstract and title to specify 'near-optimal within a fixed pool of candidates' and add a discussion in the introduction clarifying the scope of our optimality claims. revision: yes
-
Referee: [Experimental results] Experimental results section: The manuscript provides no details on the exact transformer architecture (number of layers, heads, embedding dimension), the precise feature engineering for Hamiltonian and Trotter-configuration inputs, or statistical error bars on the reported fidelity gaps across multiple random seeds or runs. These omissions hinder assessment of whether the observed size generalization is robust.
Authors: We agree that these details are essential for full reproducibility and assessment of robustness. In the revised version of the manuscript, we will expand the Experimental results section to include: the precise transformer architecture specifications (number of layers, attention heads, and embedding dimensions), a detailed description of the feature engineering process for both Hamiltonian parameters and Trotter-configuration inputs, and statistical error bars on the fidelity gap metrics computed across multiple independent training runs with different random seeds. revision: yes
Circularity Check
No circularity: empirical ML model trained on independent fidelity computations
full rationale
The paper computes fidelities for the fixed 24 candidate orderings on small systems (L=3-14) to create supervised training labels, then trains a transformer to predict the best label from Hamiltonian/configuration features. On held-out larger systems (L=16-20), the reported gap of 0.00115 is measured against the best of the same 24 candidates after direct fidelity evaluation. No equation, ansatz, or self-citation reduces the central result to a fitted quantity or prior output by construction; the derivation relies on external, independently computed fidelity benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Transformer model hyperparameters
- Candidate ordering count (24)
axioms (2)
- domain assumption The 24 structured candidates include near-optimal orderings for the Hamiltonians studied
- domain assumption Hamiltonian and Trotter-configuration features capture the information needed for size generalization
Reference graph
Works this paper leans on
-
[1]
Shamminuj Aktar, Andreas B¨ artschi, Diane Oyen, Stephan Eidenbenz, and Abdel-Hameed A. Badawy. Graph neu- ral networks for parameterized quantum circuits expressibility estimation. In2024 IEEE International Conference on Quantum Computing and Engineering (QCE), 2024.doi:10.1109/QCE60285.2024.10821280
-
[2]
Springer Science & Business Media, 2012.doi: 10.1007/978-1-4612-0869-3
Assa Auerbach.Interacting Electrons and Quantum Magnetism. Springer Science & Business Media, 2012.doi: 10.1007/978-1-4612-0869-3
-
[3]
Ryan Babbush, Jarrod McClean, Dave Wecker, Al´ an Aspuru-Guzik, and Nathan Wiebe. Chemical basis of Trotter- Suzuki errors in quantum chemistry simulation.Physical Review A, 91(2):022311, 2015.doi:10.1103/PhysRevA. 91.022311
-
[4]
Random compiler for fast hamiltonian simulation,
Earl T. Campbell. Random compiler for fast Hamiltonian simulation.Physical Review Letters, 123:070503, 2019. doi:10.1103/PhysRevLett.123.070503
-
[5]
Theory of Trotter error with commutator scaling,
Andrew M. Childs, Yuan Su, Minh C. Tran, Nathan Wiebe, and Shuchen Zhu. Theory of Trotter error with commutator scaling.Physical Review X, 11(1):011020, 2021.doi:10.1103/PhysRevX.11.011020
-
[6]
Quantum circuit optimization with deep reinforcement learning.arXiv preprint arXiv:2103.07585, 2021
Thomas F¨ osel, Murphy Yuezhen Niu, Florian Marquardt, and Li Li. Quantum circuit optimization with deep reinforcement learning, 2021.arXiv:2103.07585
-
[7]
I. M. Georgescu, S. Ashhab, and Franco Nori. Quantum simulation.Reviews of Modern Physics, 86(1):153–185, 2014.doi:10.1103/RevModPhys.86.153
-
[8]
Pranav Gokhale, Olivia Angiuli, Yongshan Ding, Kaiwen Gui, Teague Tomesh, Martin Suchara, Margaret Martonosi, and Frederic T. Chong.O(N 3) measurement cost for variational quantum eigensolver on molecular Hamiltonians.IEEE Transactions on Quantum Engineering, 1:1–24, 2020.doi:10.1109/TQE.2020.3035814
-
[9]
Hastings, Robin Kothari, and Guang Hao Low
Jeongwan Haah, Matthew B. Hastings, Robin Kothari, and Guang Hao Low. Quantum algorithm for simulating real time evolution of lattice Hamiltonians.SIAM Journal on Computing, 52(6):FOCS18–250–FOCS18–284, 2023. doi:10.1137/18M1231511
-
[10]
Markus Heyl, Philipp Hauke, and Peter Zoller. Quantum localization bounds Trotter errors in digital quantum simulation.Science Advances, 5(4):eaau8342, 2019.doi:10.1126/sciadv.aau8342
-
[11]
Journal of Modern Optics , volume =
Richard Jozsa. Fidelity for mixed quantum states.Journal of Modern Optics, 41(12):2315–2323, 1994.doi: 10.1080/09500349414552171
-
[12]
Universal quantum simulators.Science, 273(5278):1073–1078, 1996.doi:10.1126/science.273.5278
Seth Lloyd. Universal quantum simulators.Science, 273(5278):1073–1078, 1996.doi:10.1126/science.273.5278. 1073
-
[13]
Lorenzo Moro, Matteo G. A. Paris, Marcello Restelli, and Enrico Prati. Quantum compiling by deep reinforcement learning.Communications Physics, 4:178, 2021.doi:10.1038/s42005-021-00684-3
-
[14]
Compiler optimization for quantum computing us- ing reinforcement learning
Nils Quetschlich, Lukas Burgholzer, and Robert Wille. Compiler optimization for quantum computing us- ing reinforcement learning. In2023 60th ACM/IEEE Design Automation Conference (DAC), pages 1–6, 2023. doi:10.1109/DAC56929.2023.10248002
-
[15]
Albert T. Schmitz, Nicolas P. D. Sawaya, Sonika Johri, and A. Y. Matsuura. Graph optimization perspective for low-depth Trotter-Suzuki decomposition.Physical Review A, 109(4):042418, 2024.doi:10.1103/PhysRevA.109. 042418. 14
-
[16]
Masuo Suzuki. General theory of fractal path integrals with applications to many-body theories and statistical physics.Journal of Mathematical Physics, 32(2):400–407, 1991.doi:10.1063/1.529425
-
[17]
An Analysis of Commutation-Based Trotter Ordering Strategies on Heisenberg-Style Hamiltonians
Reuben Tate, Shamminuj Aktar, and Stephan Eidenbenz. An analysis of commutation-based Trotter ordering strategies on Heisenberg-style Hamiltonians, 2026.arXiv:2604.23138
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Chong, Margaret Martonosi, and Martin Suchara
Teague Tomesh, Kaiwen Gui, Pranav Gokhale, Yunong Shi, Frederic T. Chong, Margaret Martonosi, and Martin Suchara. Optimized quantum program execution ordering to mitigate errors in simulations of quantum systems. In2021 International Conference on Rebooting Computing (ICRC), pages 1–13, 2021.doi:10.1109/ICRC53822. 2021.00013
-
[19]
Love, Florian Mintert, Nathan Wiebe, and Peter V
Andrew Tranter, Peter J. Love, Florian Mintert, Nathan Wiebe, and Peter V. Coveney. Ordering of Trotter- ization: Impact on errors in quantum simulation of electronic structure.Entropy, 21(12):1218, 2019.doi: 10.3390/e21121218
-
[20]
Hale F. Trotter. On the product of semi-groups of operators.Proceedings of the American Mathematical Society, 10(4):545–551, 1959.doi:10.2307/2033649
-
[21]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, vol- ume 30. Curran Associates, Inc., 2017. URL:ht...
2017
-
[22]
Hanrui Wang, Zhiding Liang, Jiaqi Gu, Zirui Li, Yongshan Ding, Weiwen Jiang, Yiyu Shi, David Z. Pan, Frederic T. Chong, and Song Han. Torchquantum case study for robust quantum circuits. InProceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design, ICCAD ’22, New York, NY, USA, 2022. Association for Computing Machinery.doi:10.1145/...
-
[23]
Sergiy Zhuk, Niall F. Robertson, and Sergey Bravyi. Trotter error bounds and dynamic multi-product formulas for Hamiltonian simulation.Physical Review Research, 6:033309, 2024.doi:10.1103/PhysRevResearch.6.033309. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.