LLMs Capture Emotion Labels, Not Emotion Uncertainty: Distributional Analysis and Calibration of Human-LLM Judgment Gaps
Pith reviewed 2026-05-07 09:19 UTC · model grok-4.3
The pith
Large language models match explicit emotion words but miss the spread of human disagreement on context-dependent emotions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
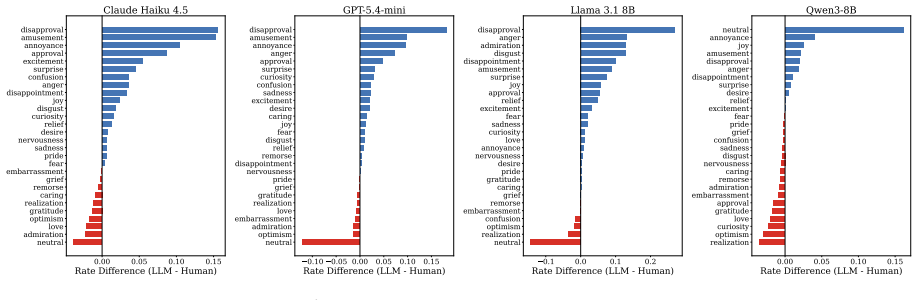
Zero-shot large language models diverge substantially from human emotion judgment distributions on both categorical and dimensional benchmarks, with in-domain fine-tuning rather than model scale required to close the gap; LLMs reliably capture emotions with explicit lexical markers but systematically fail on pragmatically complex emotions requiring contextual inference, as quantified by a proposed transparency score that predicts per-category agreement, while three lightweight post-hoc calibration methods reduce the distributional gap by up to 14 percent.
What carries the argument
The lexical-grounding gradient, quantified by a transparency score that ranks emotion categories according to whether they are signaled by explicit words in the text or require contextual and pragmatic inference to label.
If this is right
- Fine-tuning on in-domain data is required to align LLM emotion distributions with human ones, while scale alone does not suffice.
- LLMs can substitute for human annotators on emotions with clear lexical markers but not on those depending on pragmatic context.
- Three lightweight post-hoc calibration methods reduce the human-LLM distributional gap by up to 14 percent without retraining.
- The lexical versus pragmatic performance split holds across both discrete emotion categories and continuous valence-arousal dimensions.
- Practical guidelines can determine when LLM outputs are safe to use in place of human emotion labels.
Where Pith is reading between the lines
- The transparency score may serve as a quick filter to identify other subjective annotation tasks where LLMs are likely to under-reproduce human variability.
- LLM training objectives that favor surface lexical patterns may inherently limit modeling of human uncertainty on pragmatically complex judgments.
- Combining calibration steps with selective fine-tuning could provide an efficient route to approximating human disagreement distributions in annotation pipelines.
- The results suggest that simply scaling models will leave persistent gaps for emotions that require inference beyond explicit word cues.
Load-bearing premise
Human disagreement distributions on emotion labels encode meaningful uncertainty worth preserving rather than random noise, and the two chosen benchmarks represent general emotion annotation tasks.
What would settle it
A new emotion dataset where the transparency score fails to predict which categories show high human-LLM distributional agreement, or where zero-shot models on larger scales match human distributions as well as fine-tuned models on pragmatically complex emotions.
Figures






read the original abstract
Human annotators frequently disagree on emotion labels, yet most evaluations of Large Language Model (LLM) emotion annotation collapse these judgments into a single gold standard, discarding the distributional information that disagreement encodes. We ask whether LLMs capture the structure of this disagreement, not just majority labels, by comparing emotion judgment distributions between human annotators and four zero-shot LLMs, plus a fine-tuned RoBERTa baseline, across two complementary benchmarks: GoEmotions and EmoBank, totaling 640,000 LLM responses. Zero-shot models diverge substantially from human distributions, and in-domain fine-tuning, not model scale, is required to close the gap. We formalize a lexical-grounding gradient through a quantitative transparency score that predicts per-category human--LLM agreement: LLMs reliably capture emotions with explicit lexical markers but systematically fail on pragmatically complex emotions requiring contextual inference, a pattern that replicates across both categorical and continuous emotion frameworks. We further propose three lightweight post-hoc calibration methods that reduce the distributional gap by up to 14\%, and provide actionable guidelines for when LLM emotion annotations can, and cannot, substitute for human labeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study comparing the distributional emotion judgments of zero-shot LLMs and a fine-tuned RoBERTa baseline to human annotators on the GoEmotions and EmoBank datasets, totaling 640,000 LLM responses. It claims that zero-shot models diverge substantially from human distributions (capturing labels but not uncertainty), that in-domain fine-tuning rather than model scale is required to close the gap, and that a quantitative transparency score based on a lexical-grounding gradient predicts per-category agreement, with LLMs succeeding on explicit lexical emotions but failing on pragmatically complex ones requiring contextual inference. The work replicates across categorical and continuous frameworks, proposes three lightweight post-hoc calibration methods reducing the gap by up to 14%, and provides guidelines for when LLMs can substitute for human labeling.
Significance. If the results hold after addressing the noted concerns, this work would be significant for computational linguistics and affective computing. The large scale (640k responses) and replication across two datasets plus categorical/continuous frameworks provide a robust empirical foundation for the observed patterns. The focus on distributional comparisons rather than majority labels, the lexical transparency score, and the practical calibration proposals offer actionable contributions for practitioners using LLMs in emotion annotation tasks.
major comments (3)
- [Abstract and §3] Abstract and §3 (Human-LLM Distribution Comparison): The central claim that LLMs fail to capture 'emotion uncertainty' (as opposed to producing more consistent labels) rests on the assumption that human disagreement distributions encode intrinsic uncertainty worth preserving. No validation is described (e.g., intra- vs. inter-annotator agreement controls or manipulations of guideline clarity) to rule out alternatives like annotator variability or ambiguous category boundaries; this is load-bearing for the transparency score's predictive validity and the interpretation of divergences as modeling failures rather than strengths.
- [§4.2] §4.2 (Transparency Score): The transparency score is defined to predict human-LLM agreement via lexical features, but the description suggests it is constructed from observable markers rather than fitted independently to the target distributions. This risks making the lexical-grounding gradient claim circular with the empirical results, weakening the conclusion that it explains failures on pragmatically complex emotions.
- [§5] §5 (Calibration Methods): The reported up to 14% reduction in distributional gap via post-hoc calibration requires explicit comparison to fairly tuned baselines (including the in-domain fine-tuned RoBERTa) and details on the metrics used for distributional divergence; without this, the claim that fine-tuning (not scale) is required cannot be fully assessed.
minor comments (2)
- [Abstract] The abstract mentions 640,000 LLM responses but does not break down the exact number of responses per model, per instance, or per dataset; adding this would improve reproducibility.
- [Methods] Clarify in the methods section the exact zero-shot prompting templates used and whether multiple samples per instance were drawn to estimate LLM distributions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key assumptions and strengthen the presentation of our results. We address each major point below with clarifications, additional comparisons where appropriate, and targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim that LLMs fail to capture 'emotion uncertainty' (as opposed to producing more consistent labels) rests on the assumption that human disagreement distributions encode intrinsic uncertainty worth preserving. No validation is described (e.g., intra- vs. inter-annotator agreement controls or manipulations of guideline clarity) to rule out alternatives like annotator variability or ambiguous category boundaries; this is load-bearing for the transparency score's predictive validity and the interpretation of divergences as modeling failures rather than strengths.
Authors: We rely on the established multi-annotator structure of GoEmotions and EmoBank, where per-instance label distributions are standardly interpreted as reflecting annotator uncertainty in the affective computing literature. While we do not introduce new intra-annotator controls or guideline manipulations (which would require fresh annotation campaigns), we will add an explicit limitations paragraph in §3 citing prior validation studies on these datasets and acknowledging that some portion of observed disagreement may stem from category boundary ambiguity. This does not alter our core empirical finding that zero-shot LLMs produce narrower distributions than the human label distributions, but it frames the interpretation more cautiously. revision: partial
-
Referee: [§4.2] The transparency score is defined to predict human-LLM agreement via lexical features, but the description suggests it is constructed from observable markers rather than fitted independently to the target distributions. This risks making the lexical-grounding gradient claim circular with the empirical results, weakening the conclusion that it explains failures on pragmatically complex emotions.
Authors: The transparency score is computed a priori from surface lexical properties (presence of explicit emotion lemmas, valence/arousal lexical norms, and absence of pragmatic cues) without reference to the human-LLM agreement values. It is then used post hoc to predict per-category divergence. We will revise §4.2 to state this independence explicitly, include the precise scoring formula, and report the correlation coefficient between the pre-defined score and observed agreement to demonstrate that the predictive relationship is not tautological. revision: yes
-
Referee: [§5] The reported up to 14% reduction in distributional gap via post-hoc calibration requires explicit comparison to fairly tuned baselines (including the in-domain fine-tuned RoBERTa) and details on the metrics used for distributional divergence; without this, the claim that fine-tuning (not scale) is required cannot be fully assessed.
Authors: We agree that direct head-to-head evaluation is needed. In the revision we will add a table in §5 comparing all three post-hoc calibration methods against both the original zero-shot models and the in-domain fine-tuned RoBERTa baseline, using the same distributional metrics (Jensen-Shannon divergence and Earth Mover’s Distance) already defined in the section. This will allow readers to assess whether calibration approaches the performance of fine-tuning and will clarify the relative contributions of scale versus in-domain adaptation. revision: yes
Circularity Check
No significant circularity: empirical comparison against external benchmarks
full rationale
The paper performs distributional comparisons of LLM emotion judgments against human annotations on two external benchmarks (GoEmotions and EmoBank). The transparency score is defined from observable lexical features and then correlated with agreement rates, without being fitted to the target agreement data or reducing to self-definition. No equations, predictions, or uniqueness claims reduce by construction to the paper's own inputs or self-citations. The central claims rest on independent external human data and are therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotator disagreement distributions encode meaningful emotion uncertainty rather than random noise.
Reference graph
Works this paper leans on
-
[1]
GoEmotions: A dataset of fine-grained emo- tions. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4040–4054. Quanqi Du and Veronique Hoste. 2025. Another ap- proach to agreement measurement and prediction with emotion annotations. InProceedings of the 19th Linguistic Annotation Workshop, pages 87–102. Neele...
work page 2025
-
[2]
ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences of the United States of America, 120:e2305016120. Mitchell L. Gordon, Michelle S. Lam, Joon Sung Park, Kayur Patel, Jeff Hancock, Tatsunori Hashimoto, and Michael S. Bernstein. 2022. Jury learning: Integrat- ing dissenting voices into machine learni...
work page 2022
-
[3]
InProceedings of the 10th IEEE International Conference on Data Science and Systems, pages 58–65
Multi-stage evolutionary model merging with meta data driven curriculum learning for sentiment- specialized large language modeling. InProceedings of the 10th IEEE International Conference on Data Science and Systems, pages 58–65. Joseph James. 2026. Counting on consensus: Selecting the right inter-annotator agreement metric for NLP annotation and evaluat...
work page 2026
-
[4]
Ellie Pavlick and Tom Kwiatkowski
Automated annotation with generative AI re- quires validation.arXiv. Ellie Pavlick and Tom Kwiatkowski. 2019. Inherent disagreements in human textual inferences.Transac- tions of the Association for Computational Linguis- tics, 7:677–694. Barbara Plank. 2022. The “problem” of human label variation: On ground truth in data, modeling and eval- uation. InPro...
work page 2019
-
[5]
Journal of Artificial Intelligence Research, 72:1385– 1470
Learning from disagreement: A survey. Journal of Artificial Intelligence Research, 72:1385– 1470. Shanshan Xu, Santhosh T.Y .S.S, and Barbara Plank
-
[6]
neutral". - Return ONLY a JSON array of selected emotion labels, nothing else. - Example: [
From noise to signal to selbstzweck: Refram- ing human label variation in the era of post-training in NLP.arXiv. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report.arXiv. Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Pan, and Lidong Bing. 2024. Sentim...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.