Recognition: unknown
CoAX: Cognitive-Oriented Attribution eXplanation User Model of Human Understanding of AI Explanations
Pith reviewed 2026-05-07 08:20 UTC · model grok-4.3
The pith
Cognitive models based on elicited reasoning strategies fit human decisions using AI explanations better than machine learning baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
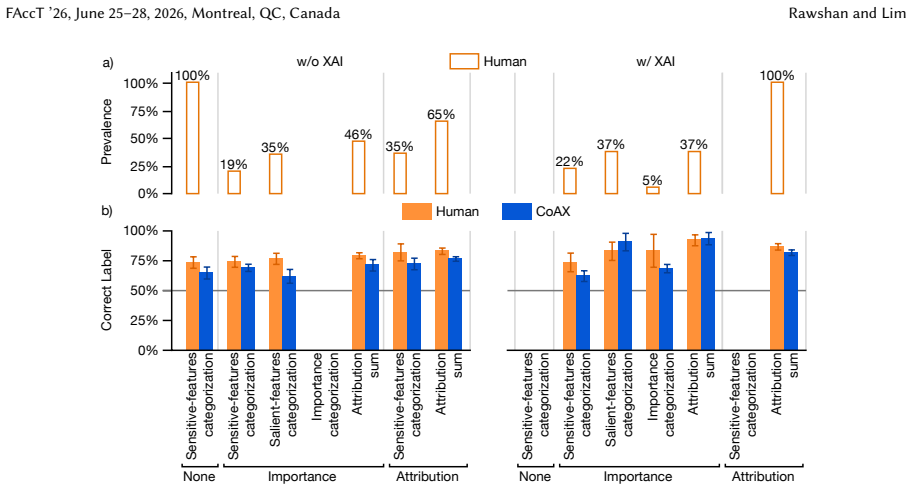
The authors elicit reasoning strategies from a formative user study on anticipating AI decisions with no explanations, feature importance, and feature attribution. They implement these as cognitive models and compare their fit to human decisions collected in a summative study against baseline machine learning proxies. The cognitive models provide a better fit, revealing effective and ineffective reasoning strategies, and serve as a tool for generating and testing hypotheses about human understanding of XAI without additional participant studies.
What carries the argument
The CoAX cognitive user model, which implements the underlying processes of reasoning strategies for forward simulation of AI decisions based on XAI methods.
If this is right
- Certain reasoning strategies are more effective than others for specific XAI methods such as feature importance or attribution.
- The fitted models can be used to form hypotheses and investigate research questions that are costly to study with real human participants.
- Insights from the models can inform the design of more usable and interpretable AI explanations by identifying why users struggle with current methods.
- Cognitive modeling provides a way to debug human understanding of XAI beyond what direct user evaluations reveal.
Where Pith is reading between the lines
- The models could be used to evaluate new explanation designs in simulation before committing to human testing.
- Extending the approach to other tasks or data types might reveal broader patterns in how people interact with AI explanations.
- Personalized explanation systems could adapt based on inferred user reasoning strategies from the fitted models.
Load-bearing premise
The reasoning strategies collected in the formative user study accurately represent the cognitive processes participants used when making decisions in the summative study, and the implemented models faithfully simulate those processes.
What would settle it
Collecting new human decision data on the same forward simulation task and finding that the cognitive models do not fit the data better than the machine learning proxy baselines would falsify the central claim.
Figures
























read the original abstract
Explainable AI (XAI) aims to improve user understanding and decisions when using AI models. However, despite innovations in XAI, recent user evaluations reveal that this goal remains elusive. Understanding human cognition can help explain why users struggle to effectively use AI explanations. Focusing on reasoning on structured (tabular) data, we examined various reasoning strategies for different XAI methods (none, feature importance, feature attribution) in the decision task of anticipating AI decisions (i.e., forward simulation). We i) elicited reasoning strategies from a formative user study, and ii) collected decisions from a summative user study. Using cognitive modeling, we implemented the processes underlying each reasoning strategy and evaluated their alignment with human decision-making. We found that our models better fit human decisions than baseline machine learning proxies, providing insights into which reasoning strategies are (in)effective. We then demonstrate how the fitted model can be used to form hypotheses and investigate research questions that are costly to study with real human participants. This work contributes to debugging human understanding of XAI, informing the future development of more usable and interpretable AI explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoAX, a cognitive model of human understanding of XAI explanations for tabular data forward-simulation tasks. It elicits reasoning strategies via a formative user study for three explanation conditions (none, feature importance, feature attribution), collects human decisions in a summative study, implements process-level cognitive models of the elicited strategies, and reports that these models achieve better fit to the human data than ML baseline proxies. The work claims this yields insights into effective vs. ineffective reasoning strategies and demonstrates using the fitted models to generate and investigate hypotheses that would be costly to test with new human participants.
Significance. If the cognitive models are shown to faithfully instantiate the elicited strategies rather than merely providing flexible functional forms that fit the data, the approach could meaningfully advance XAI by supplying mechanistic, simulatable accounts of user reasoning. This would support both explanation design and the generation of testable predictions without repeated large-scale user studies, addressing a recognized gap between XAI technical advances and demonstrated human benefit.
major comments (3)
- [§5 (Cognitive Modeling)] §5 (Cognitive Modeling): The manuscript claims the implemented models capture the reasoning strategies elicited in the formative study and that superior fit therefore provides insights into which strategies are (in)effective. However, no direct validation is reported (e.g., comparison of model-generated reasoning traces against think-aloud protocols, parameter-recovery simulations, or qualitative alignment between model steps and participant verbal reports). Without such checks, the better fit could arise from statistical regularities captured by the model architecture rather than the intended cognitive processes, weakening both the interpretive claims and the subsequent use of the fitted model for hypothesis generation.
- [§4 (Summative Study) and §6 (Model Evaluation)] §4 (Summative Study) and §6 (Model Evaluation): The cognitive models are fitted to the same human decision data against which they are evaluated. The abstract reports better fit than ML baselines, but the manuscript does not appear to include out-of-sample prediction on held-out tasks or new explanation conditions, nor does it report the number of free parameters in each cognitive model relative to the baselines. This leaves open the possibility that superior fit reflects greater flexibility rather than cognitive fidelity, which is load-bearing for the central claim that the models provide genuine insights into human reasoning strategies.
- [§7 (Hypothesis Generation)] §7 (Hypothesis Generation): The demonstration that the fitted model can be used to investigate research questions costly to study with humans is promising, but it inherits the validation gap identified above. If the models are not independently confirmed to reproduce the elicited strategies, any hypotheses generated from them risk being artifacts of the fitting procedure rather than grounded cognitive predictions.
minor comments (2)
- [Abstract] The abstract refers to 'our models' without enumerating which strategies each model implements or how many free parameters they contain; adding this information would improve clarity for readers.
- [Figures] Figures reporting model fits should include confidence intervals or standard errors on the fit metrics (e.g., log-likelihood or R²) so that visual comparisons to baselines can be assessed for statistical reliability.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our paper. The feedback points to key areas for strengthening the validation of our cognitive models. We address each major comment point-by-point below, providing clarifications based on the manuscript and proposing revisions where appropriate to enhance the rigor of our claims about human reasoning strategies in XAI.
read point-by-point responses
-
Referee: §5 (Cognitive Modeling): The manuscript claims the implemented models capture the reasoning strategies elicited in the formative study and that superior fit therefore provides insights into which strategies are (in)effective. However, no direct validation is reported (e.g., comparison of model-generated reasoning traces against think-aloud protocols, parameter-recovery simulations, or qualitative alignment between model steps and participant verbal reports). Without such checks, the better fit could arise from statistical regularities captured by the model architecture rather than the intended cognitive processes, weakening both the interpretive claims and the subsequent use of the fitted model for hypothesis generation.
Authors: The formative user study elicited reasoning strategies through participant verbal reports during the forward-simulation task. These reports informed the design of the process models in §5, which implement specific steps such as attending to feature attributions and simulating decision thresholds. Although we did not conduct explicit comparisons of model-generated traces to individual think-aloud protocols or parameter-recovery simulations, the models are not flexible black-box forms but are constrained to the strategies described by participants. The better fit to aggregate human decisions supports their cognitive fidelity. We will revise the manuscript to include a detailed table mapping elicited strategies to model processes and add a limitations section discussing the absence of direct trace validation, suggesting it as future work. revision: partial
-
Referee: §4 (Summative Study) and §6 (Model Evaluation): The cognitive models are fitted to the same human decision data against which they are evaluated. The abstract reports better fit than ML baselines, but the manuscript does not appear to include out-of-sample prediction on held-out tasks or new explanation conditions, nor does it report the number of free parameters in each cognitive model relative to the baselines. This leaves open the possibility that superior fit reflects greater flexibility rather than cognitive fidelity, which is load-bearing for the central claim that the models provide genuine insights into human reasoning strategies.
Authors: We confirm that parameter estimation was performed on the summative study data to fit the models to observed decisions, which is common practice in cognitive modeling for process models. To address the concern about flexibility, we will revise §6 to explicitly report the number of free parameters for each cognitive model (e.g., thresholds, weights in the strategies) and compare them to the ML baselines. Regarding out-of-sample evaluation, the current work prioritizes demonstrating in-sample alignment with the elicited strategies; we did not include held-out predictions. We will add a discussion noting this and how the models could be used for out-of-sample testing in future applications, such as predicting behavior on new explanation types. revision: partial
-
Referee: §7 (Hypothesis Generation): The demonstration that the fitted model can be used to investigate research questions costly to study with humans is promising, but it inherits the validation gap identified above. If the models are not independently confirmed to reproduce the elicited strategies, any hypotheses generated from them risk being artifacts of the fitting procedure rather than grounded cognitive predictions.
Authors: We acknowledge that the hypothesis generation builds upon the fitted models and thus shares the validation considerations raised. In the revised manuscript, we will strengthen §7 by more explicitly grounding the generated hypotheses in the specific strategies elicited from the formative study and the process implementations. This includes examples of how varying model parameters (corresponding to strategy components) leads to predictions about user performance. We maintain that this approach allows for efficient exploration of costly-to-test scenarios, with the understanding that model-based predictions should be validated empirically in subsequent studies. revision: partial
Circularity Check
No significant circularity; model comparison is standard and self-contained
full rationale
The paper separates strategy elicitation (formative study) from decision data collection (summative study), implements cognitive models from the elicited strategies, and compares their fit on the summative data against ML baseline proxies. This constitutes ordinary goodness-of-fit model comparison rather than any reduction of a claimed prediction to the fitted inputs by construction. No equations or derivations are shown to be self-definitional, and the subsequent use of the fitted model for hypothesis generation is presented as an independent demonstration. No load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or described chain. The work is therefore self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- cognitive model parameters
axioms (1)
- domain assumption Reasoning strategies elicited from the formative study represent the actual cognitive processes used by participants in the summative study
Reference graph
Works this paper leans on
-
[1]
Ashraf Abdul, Jo Vermeulen, Danding Wang, Brian Y Lim, and Mohan Kankanhalli. 2018. Trends and trajectories for explainable, accountable and intelligible systems: An hci research agenda. InProceedings of the 2018 CHI conference on human factors in computing systems. 1–18
2018
-
[2]
Ashraf Abdul, Christian Von Der Weth, Mohan Kankanhalli, and Brian Y Lim. 2020. COGAM: measuring and moderating cognitive load in machine learning model explanations. InProceedings of the 2020 CHI conference on human factors in computing systems. 1–14
2020
-
[3]
Amina Adadi and Mohammed Berrada. 2018. Peeking inside the black-box: a survey on explainable artificial intelligence (XAI).IEEE access6 (2018), 52138–52160
2018
-
[4]
John R Anderson, Daniel Bothell, Michael D Byrne, Scott Douglass, Christian Lebiere, and Yulin Qin. 2004. An integrated theory of the mind.Psychological review111, 4 (2004), 1036
2004
-
[5]
John R Anderson and Kevin A Gluck. 2013. What role do cognitive architectures play in intelligent tutoring systems? InCognition and instruction. Psychology Press, 227–261
2013
-
[6]
John R Anderson and Lael J Schooler. 1991. Reflections of the environment in memory.Psychological science2, 6 (1991), 396–408
1991
-
[7]
Siddhant Arora, Danish Pruthi, Norman Sadeh, William W Cohen, Zachary C Lipton, and Graham Neubig. 2022. Explain, edit, and understand: Rethinking user study design for evaluating model explanations. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 5277–5285
2022
-
[8]
Saugat Aryal. 2024. Semi-factual explanations in AI. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 23379–23380
2024
-
[9]
Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S Lasecki, Daniel S Weld, and Eric Horvitz. 2019. Beyond accuracy: The role of mental models in human-AI team performance. InProceedings of the AAAI conference on human computation and crowdsourcing, Vol. 7. 2–11
2019
-
[10]
Thierry Baron, Martin D Levine, and Yehezkel Yeshurun. 1994. Exploring with a foveated robot eye system. InProceedings of the 12th IAPR International Conference on Pattern Recognition, Vol. 2-Conference B: Computer Vision & Image Processing.(Cat. No. 94CH3440-5). IEEE, 377–380
1994
-
[11]
Andrew Bell, Ian Solano-Kamaiko, Oded Nov, and Julia Stoyanovich. 2022. It’s just not that simple: an empirical study of the accuracy- explainability trade-off in machine learning for public policy. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency. 248–266
2022
-
[12]
Raunak Bhattacharyya, Blake Wulfe, Derek J Phillips, Alex Kuefler, Jeremy Morton, Ransalu Senanayake, and Mykel J Kochenderfer. 2022. Modeling human driving behavior through generative adversarial imitation learning.IEEE Transactions on Intelligent Transportation Systems24, 3 (2022), 2874–2887
2022
-
[13]
Jock A Blackard and Denis J Dean. 1999. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables.Computers and electronics in agriculture24, 3 (1999), 131–151
1999
-
[14]
Jessica Y Bo, Pan Hao, and Brian Y Lim. 2024. Incremental XAI: Memorable Understanding of AI with Incremental Explanations. In Proceedings of the CHI Conference on Human Factors in Computing Systems. 1–17
2024
-
[15]
Jessica Y Bo, Sophia Wan, and Ashton Anderson. 2025. To rely or not to rely? evaluating interventions for appropriate reliance on large language models. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–23
2025
-
[16]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. 2021. To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-computer Interaction5, CSCW1 (2021), 1–21. CoAX: Cognitive-Oriented Attribution eXplanation User Model of Human Understanding of AI Explanations FAccT...
2021
-
[17]
Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad. 2015. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. InProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 1721–1730
2015
-
[18]
Kathy Charmaz. 2014. Constructing grounded theory (introducing qualitative methods series).Constr. grounded theory(2014)
2014
-
[19]
Chacha Chen, Shi Feng, Amit Sharma, and Chenhao Tan. 2023. Machine Explanations and Human Understanding. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency(Chicago, IL, USA)(FAccT ’23). Association for Computing Machinery, New York, NY, USA, 1. doi:10.1145/3593013.3593970
-
[20]
Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 785–794
2016
-
[21]
Valerie Chen, Nari Johnson, Nicholay Topin, Gregory Plumb, and Ameet Talwalkar. 2022. Use-case-grounded simulations for explanation evaluation.Advances in neural information processing systems35 (2022), 1764–1775
2022
-
[22]
Chiho Choi, Srikanth Malla, Abhishek Patil, and Joon Hee Choi. 2021. DROGON: A trajectory prediction model based on intention- conditioned behavior reasoning. InConference on Robot Learning. PMLR, 49–63
2021
-
[23]
Paulo Cortez, A. Cerdeira, F. Almeida, T. Matos, and J. Reis. 2009. Wine Quality. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C56S3T
-
[24]
Xinyue Dai, Mark T Keane, Laurence Shalloo, Elodie Ruelle, and Ruth MJ Byrne. 2022. Counterfactual explanations for prediction and diagnosis in XAI. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. 215–226
2022
-
[25]
Francesco Bombassei De Bona, Gabriele Dominici, Tim Miller, Marc Langheinrich, and Martin Gjoreski. 2024. Evaluating explanations through llms: Beyond traditional user studies. InProceedings of the GenAI for Health Workshop @ NeurIPS 2024
2024
-
[26]
Andrew DM Dobson, Emiel De Lange, Aidan Keane, Harriet Ibbett, and EJ Milner-Gulland. 2019. Integrating models of human behaviour between the individual and population levels to inform conservation interventions.Philosophical Transactions of the Royal Society B374, 1781 (2019), 20180053
2019
-
[27]
Jonathan Dodge, Q Vera Liao, Yunfeng Zhang, Rachel KE Bellamy, and Casey Dugan. 2019. Explaining models: an empirical study of how explanations impact fairness judgment. InProceedings of the 24th international conference on intelligent user interfaces. 275–285
2019
-
[28]
Finale Doshi-Velez and Been Kim. 2017. Towards a rigorous science of interpretable machine learning.arXiv preprint arXiv:1702.08608 (2017)
work page internal anchor Pith review arXiv 2017
-
[29]
Michael Freedberg, Brian Glass, J Vincent Filoteo, Eliot Hazeltine, and W Todd Maddox. 2017. Comparing the effects of positive and negative feedback in information-integration category learning.Memory & cognition45, 1 (2017), 12–25
2017
-
[30]
Andrew Fuchs, Andrea Passarella, and Marco Conti. 2023. Modeling, replicating, and predicting human behavior: a survey.ACM Transactions on Autonomous and Adaptive Systems18, 2 (2023), 1–47
2023
-
[31]
2017.Discovery of grounded theory: Strategies for qualitative research
Barney Glaser and Anselm Strauss. 2017.Discovery of grounded theory: Strategies for qualitative research. Routledge
2017
-
[32]
Alex Goldstein, Adam Kapelner, Justin Bleich, and Emil Pitkin. 2015. Peeking Inside the Black Box: Visualizing Statistical Learning With Plots of Individual Conditional Expectation.Journal of Computational and Graphical Statistics24, 1 (2015), 44–65. doi:10.1080/ 10618600.2014.907095
-
[33]
Cleotilde Gonzalez and Varun Dutt. 2011. Instance-based learning: integrating sampling and repeated decisions from experience. Psychological review118, 4 (2011), 523
2011
-
[34]
Ziyang Guo, Yifan Wu, Jason D Hartline, and Jessica Hullman. 2024. A decision theoretic framework for measuring AI reliance. In Proceedings of the 2024 ACM conference on fairness, accountability, and transparency. 221–236
2024
-
[35]
Moritz Hardt, Eric Price, and Nathan Srebro. 2016. Equality of opportunity in supervised learning. InAdvances in Neural Information Processing Systems
2016
-
[36]
Peter Hase and Mohit Bansal. 2020. Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior?. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 5540–5552
2020
-
[37]
Gaole He, Lucie Kuiper, and Ujwal Gadiraju. 2023. Knowing about knowing: An illusion of human competence can hinder appropriate reliance on AI systems. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–18
2023
-
[38]
Sophie Hilgard, Nir Rosenfeld, Mahzarin R Banaji, Jack Cao, and David Parkes. 2021. Learning representations by humans, for humans. InInternational conference on machine learning. PMLR, 4227–4238
2021
-
[39]
1983.Mental models: Towards a cognitive science of language, inference, and consciousness
Philip Nicholas Johnson-Laird. 1983.Mental models: Towards a cognitive science of language, inference, and consciousness. Number 6. Harvard University Press
1983
-
[40]
William G Kennedy. 2011. Modelling human behaviour in agent-based models. InAgent-based models of geographical systems. Springer, 167–179
2011
-
[41]
Been Kim, Rajiv Khanna, and Oluwasanmi Koyejo. 2016. Examples Are Not Enough, Learn to Criticize! Criticism for Interpretability. In Advances in Neural Information Processing Systems (NeurIPS)
2016
-
[42]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. 2018. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning. PMLR, 2668– 2677. FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Rawshan and Lim
2018
-
[43]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. 2023. Segment Anything.arXiv:2304.02643(2023)
work page internal anchor Pith review arXiv 2023
-
[44]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. 2020. Concept bottleneck models. InInternational conference on machine learning. PMLR, 5338–5348
2020
-
[45]
Ron Kohavi et al. 1996. Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid.. InKdd, Vol. 96. 202–207
1996
-
[46]
Suresh Kolekar, Shilpa Gite, Biswajeet Pradhan, and Ketan Kotecha. 2021. Behavior prediction of traffic actors for intelligent vehicle using artificial intelligence techniques: A review.IEEE Access9 (2021), 135034–135058
2021
-
[47]
Michał Kuźba, Ewa Baranowska, and Przemysław Biecek. 2019. pyCeterisParibus: explaining machine learning models with ceteris paribus profiles in Python.Journal of Open Source Software4, 37 (2019), 1389
2019
-
[48]
Tobias Labarta, Nhi Hoang, Katharina Weitz, Wojciech Samek, Sebastian Lapuschkin, and Leander Weber. 2025. See What I Mean? CUE: A Cognitive Model of Understanding Explanations. InProceedings of the IJCAI 2025 Workshop on Explainable Artificial Intelligence (XAI). Montreal, Canada. Workshop paper
2025
- [49]
-
[50]
Isaac Lage, Andrew Ross, Samuel J Gershman, Been Kim, and Finale Doshi-Velez. 2018. Human-in-the-loop interpretability prior. Advances in neural information processing systems31 (2018)
2018
-
[51]
Himabindu Lakkaraju, Stephen H Bach, and Jure Leskovec. 2016. Interpretable decision sets: A joint framework for description and prediction. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1675–1684
2016
-
[52]
Luc Le Mero, Dewei Yi, Mehrdad Dianati, and Alexandros Mouzakitis. 2022. A survey on imitation learning techniques for end-to-end autonomous vehicles.IEEE Transactions on Intelligent Transportation Systems23, 9 (2022), 14128–14147
2022
-
[53]
Lewis and Shravan Vasishth
Richard L. Lewis and Shravan Vasishth. 2005. An activation-based model of sentence processing as skilled memory retrieval.Cognitive Science29, 3 (2005), 375–419
2005
-
[54]
Oscar Li, Hao Liu, Chaofan Chen, and Cynthia Rudin. 2018. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
- [55]
-
[56]
Zhuoyan Li and Ming Yin. 2024. Utilizing human behavior modeling to manipulate explanations in AI-assisted decision making: the good, the bad, and the scary.Advances in Neural Information Processing Systems37 (2024), 5025–5047
2024
-
[57]
Q Vera Liao, Yunfeng Zhang, Ronny Luss, Finale Doshi-Velez, and Amit Dhurandhar. 2022. Connecting algorithmic research and usage contexts: a perspective of contextualized evaluation for explainable AI. InProceedings of the AAAI Conference on Human Computation and Crowdsourcing, Vol. 10. 147–159
2022
-
[58]
Brian Y Lim, Anind K Dey, and Daniel Avrahami. 2009. Why and why not explanations improve the intelligibility of context-aware intelligent systems. InProceedings of the SIGCHI conference on human factors in computing systems. 2119–2128
2009
-
[59]
Gordon D Logan. 1988. Toward an instance theory of automatization.Psychological review95, 4 (1988), 492
1988
-
[60]
Gerald L. Lohse. 1997. Models of graphical perception. InHandbook of Human-Computer Interaction(2nd ed.). Elsevier Science, 107–135
1997
-
[61]
Zhuoran Lu, Syed Hasan Amin Mahmoo, Zhuoyan Li, and Ming Yin. 2024. Mix and match: Characterizing heterogeneous human behavior in AI-assisted decision making. InProceedings of the AAAI Conference on Human Computation and Crowdsourcing, Vol. 12. 95–104
2024
-
[62]
Scott Lundberg. 2017. A unified approach to interpreting model predictions.arXiv preprint arXiv:1705.07874(2017)
work page Pith review arXiv 2017
-
[63]
Lu Luo and Bonnie E John. 2005. Predicting task execution time on handheld devices using the keystroke-level model. InCHI’05 extended abstracts on Human factors in computing systems. 1605–1608
2005
-
[64]
Shuai Ma, Ying Lei, Xinru Wang, Chengbo Zheng, Chuhan Shi, Ming Yin, and Xiaojuan Ma. 2023. Who should i trust: Ai or myself? leveraging human and ai correctness likelihood to promote appropriate trust in ai-assisted decision-making. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–19
2023
-
[65]
W Todd Maddox and A David. 2005. Delayed feedback disrupts the procedural-learning system but not the hypothesis-testing system in perceptual category learning.Journal of experimental psychology: learning, memory, and cognition31, 1 (2005), 100
2005
-
[66]
Ramaravind K Mothilal, Amit Sharma, and Chenhao Tan. 2020. Explaining machine learning classifiers through diverse counterfactual explanations. InProceedings of the 2020 conference on fairness, accountability, and transparency. 607–617
2020
-
[67]
Hussein Mozannar, Arvind Satyanarayan, and David Sontag. 2022. Teaching humans when to defer to a classifier via exemplars. In Proceedings of the aaai conference on artificial intelligence, Vol. 36. 5323–5331
2022
-
[68]
Thuy Ngoc Nguyen, Duy Nhat Phan, and Cleotilde Gonzalez. 2023. SpeedyIBL: A comprehensive, precise, and fast implementation of instance-based learning theory.Behavior Research Methods55, 4 (2023), 1734–1757
2023
-
[69]
Howard Kenneth Nixon. 1924. Attention and Interest in Advertising.Archives of Psychology72 (1924)
1924
-
[70]
Eura Nofshin, Esther Brown, Brian Lim, Weiwei Pan, and Finale Doshi-Velez. [n. d.]. A Sim2Real Approach for Identifying Task-Relevant Properties in Interpretable Machine Learning. InICML 2024 Next Generation of AI Safety Workshop. CoAX: Cognitive-Oriented Attribution eXplanation User Model of Human Understanding of AI Explanations FAccT ’26, June 25–28, 2...
2024
-
[71]
Robert M Nosofsky. 1986. Attention, similarity, and the identification–categorization relationship.Journal of experimental psychology: General115, 1 (1986), 39
1986
-
[72]
Payne, James R
John W. Payne, James R. Bettman, and Eric J. Johnson. 1993.The Adaptive Decision Maker. Cambridge University Press, Cambridge, UK
1993
-
[73]
Forough Poursabzi-Sangdeh, Daniel G Goldstein, Jake M Hofman, Jennifer Wortman Wortman Vaughan, and Hanna Wallach. 2021. Manipulating and measuring model interpretability. InProceedings of the 2021 CHI conference on human factors in computing systems. 1–52
2021
-
[74]
Neil Rabinowitz, Frank Perbet, Francis Song, Chiyuan Zhang, SM Ali Eslami, and Matthew Botvinick. 2018. Machine theory of mind. InInternational conference on machine learning. PMLR, 4218–4227
2018
-
[75]
Why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " Why should i trust you?" Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 1135–1144
2016
-
[76]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2018. Anchors: High-precision model-agnostic explanations. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[77]
Yao Rong, Tobias Leemann, Thai-Trang Nguyen, Lisa Fiedler, Peizhu Qian, Vaibhav Unhelkar, Tina Seidel, Gjergji Kasneci, and Enkelejda Kasneci. 2023. Towards human-centered explainable ai: A survey of user studies for model explanations.IEEE transactions on pattern analysis and machine intelligence(2023)
2023
-
[78]
Mirka Saarela and Vili Podgorelec. 2024. Recent Applications of Explainable AI (XAI): A Systematic Literature Review.Applied Sciences 14, 19 (2024), 8884. doi:10.3390/app14198884
-
[79]
Max Schemmer, Patrick Hemmer, Niklas Kühl, Carina Benz, and Gerhard Satzger. 2022. Should I Follow AI-based Advice? Measuring Appropriate Reliance in Human-AI Decision-Making. InACM Conference on Human Factors in Computing Systems (CHI’22), Workshop on Trust and Reliance in AI-Human Teams (trAIt)
2022
-
[80]
Ramprasaath R. et al. Selvaraju. 2017. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. InICCV
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.