Judge, Then Drive: A Critic-Centric Vision Language Action Framework for Autonomous Driving
Pith reviewed 2026-05-07 09:48 UTC · model grok-4.3
The pith
A vision-language-action model judges its own rough driving trajectory and refines it before acting, raising closed-loop success on driving benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CriticVLA extends VLAs from pure action generation to a judge-then-drive process: an initial rough trajectory is produced, after which multimodal evaluation by the VLA critic identifies issues and guides single-step refinement, producing higher-quality behaviors than direct-mapping baselines.
What carries the argument
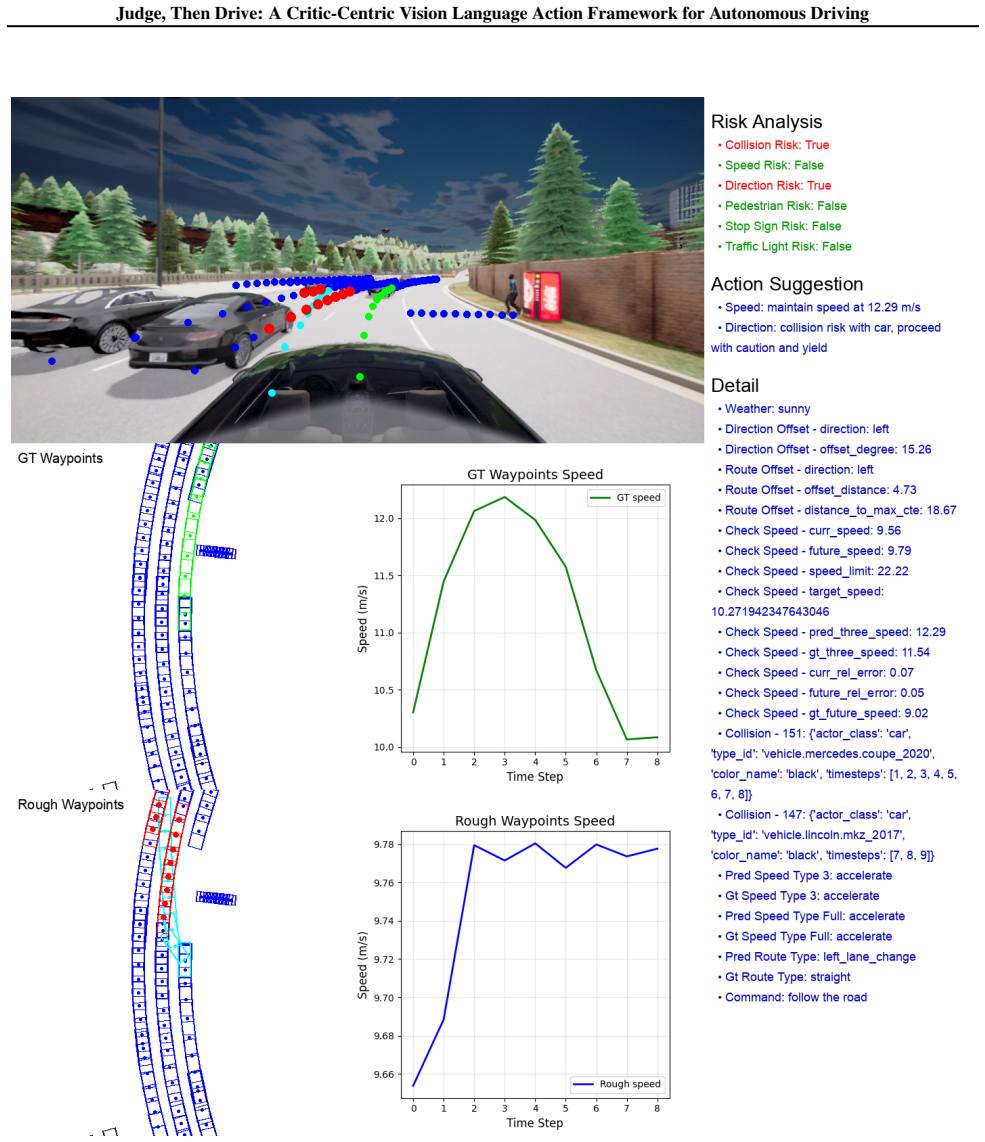
The two-stage CriticVLA pipeline, in which the VLA critic performs multimodal evaluation followed by single-step optimization on an initial trajectory.
If this is right
- Driving systems gain an internal mechanism for catching and correcting trajectory errors before execution.
- VLA models trained on large synthetic trajectory sets can extend their role beyond mapping to include reliable judgment.
- Closed-loop performance improves particularly in scenarios that previously exposed weaknesses in direct VLA control.
- The framework provides a concrete way to leverage existing critic capabilities demonstrated in other LLM domains for vehicle control.
Where Pith is reading between the lines
- Similar judge-then-act loops could apply to other embodied tasks such as robotic manipulation where initial plans benefit from self-evaluation.
- The reliance on synthetic data suggests a path to scale critic training without exhaustive real-world labeling, provided domain gaps remain small.
- If the refinement step generalizes, hybrid systems might combine this critic stage with existing rule-based safety layers for added redundancy.
Load-bearing premise
That a VLA model trained as a critic on synthetic trajectory data can produce evaluations and refinements that improve actual closed-loop driving performance.
What would settle it
Run the full CriticVLA pipeline versus a version without the critic refinement stage on the same Bench2Drive scenarios and measure whether the success rate gap disappears.
Figures












read the original abstract
Recent advances in vision language action (VLA) models have shown remarkable potential for autonomous driving by directly mapping multimodal inputs to control signals. However, previous VLA-based methods have not explicitly exploited the critic capability of VLAs to refine driving decisions, even though such capability has been well demonstrated in other LLM-based domains, thereby limiting their performance in complex closed-loop scenarios. In this work, we present a theoretically inspired two-stage framework, CriticVLA, which extends the role of VLAs from acting to judging. CriticVLA first generates a rough trajectory and then refines it through multimodal evaluation and single-step optimization guided by a VLA-based critic, yielding higher-quality driving behaviors. To support this process, we construct a large-scale synthetic dataset of 12.9 million annotated trajectories covering diverse driving scenarios, which enhances the critic's reasoning and refinement abilities. Extensive closed-loop experiments on the Bench2Drive benchmark show that CriticVLA significantly surpasses state-of-the-art baselines, achieving a 73.33% total success rate and delivering about 30% improvement in challenging scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CriticVLA, a two-stage vision-language-action framework for autonomous driving. In the first stage, a VLA model generates an initial rough trajectory from multimodal inputs. In the second stage, a VLA-based critic evaluates and refines the trajectory through multimodal assessment and single-step optimization. To enable this, the authors build a synthetic dataset comprising 12.9 million annotated trajectories. Closed-loop evaluations on the Bench2Drive benchmark demonstrate that CriticVLA achieves a 73.33% success rate, surpassing state-of-the-art methods with approximately 30% gains in challenging scenarios.
Significance. If the reported performance gains hold under rigorous validation, this work could advance VLA applications in autonomous driving by explicitly leveraging critic capabilities that have succeeded in other LLM domains. The large-scale synthetic dataset is a notable resource contribution. The closed-loop focus directly targets limitations of prior VLA methods, with potential implications for more reliable decision-making in complex scenarios. The theoretically motivated two-stage design is a strength.
major comments (2)
- [§5 (Experimental Results)] §5 (Experimental Results): The headline claims of 73.33% total success rate and ~30% improvement in challenging scenarios are presented without details on the number of evaluation runs, standard deviations, statistical significance tests, or exact baseline implementations and hyperparameter settings. This information is required to assess whether the closed-loop gains on Bench2Drive are robust or potentially confounded by evaluation protocol choices.
- [§3 (Dataset and Critic Training)] §3 (Dataset and Critic Training): The 12.9 million trajectory dataset is central to enabling the critic's refinement capability, yet the manuscript provides insufficient description of how critic annotations (e.g., quality labels or refinement targets) were generated, filtered, or validated for accuracy. Without this, it is difficult to evaluate the reliability of the assumption that the VLA critic can consistently produce better trajectories in closed-loop settings.
minor comments (2)
- [Figure 2] Figure 2: The diagram of the two-stage pipeline would benefit from explicit arrows or labels indicating the flow of multimodal inputs to the critic and the single-step optimization step.
- [§2] Notation in §2: The distinction between the actor VLA and critic VLA could be clarified with consistent variable naming (e.g., distinguishing π_actor from π_critic) to avoid reader confusion when describing the refinement process.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point-by-point below. Where the manuscript is missing required details, we will revise accordingly to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [§5 (Experimental Results)] §5 (Experimental Results): The headline claims of 73.33% total success rate and ~30% improvement in challenging scenarios are presented without details on the number of evaluation runs, standard deviations, statistical significance tests, or exact baseline implementations and hyperparameter settings. This information is required to assess whether the closed-loop gains on Bench2Drive are robust or potentially confounded by evaluation protocol choices.
Authors: We agree that additional statistical details are needed to fully substantiate the reported performance. In the revised manuscript, we will explicitly state the number of independent evaluation runs conducted, report standard deviations alongside the 73.33% success rate and scenario-specific improvements, include statistical significance tests (such as paired t-tests) comparing CriticVLA against baselines, and provide complete hyperparameter settings plus implementation details for all baselines in the main text or supplementary material. These additions will allow readers to rigorously evaluate the robustness of the closed-loop gains. revision: yes
-
Referee: [§3 (Dataset and Critic Training)] §3 (Dataset and Critic Training): The 12.9 million trajectory dataset is central to enabling the critic's refinement capability, yet the manuscript provides insufficient description of how critic annotations (e.g., quality labels or refinement targets) were generated, filtered, or validated for accuracy. Without this, it is difficult to evaluate the reliability of the assumption that the VLA critic can consistently produce better trajectories in closed-loop settings.
Authors: We acknowledge that the current description of the dataset annotation process is insufficient. In the revision, we will expand Section 3 with a detailed account of how critic annotations were produced, including the specific methods for generating quality labels and refinement targets (via a combination of rule-based simulation metrics and VLA-guided assessment), the filtering criteria used to ensure data quality and diversity, and the validation steps such as expert review on sampled subsets to confirm annotation accuracy. This will better justify the reliability of the critic training and its closed-loop benefits. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes a two-stage CriticVLA pipeline that extends existing VLA models by adding an explicit critic stage for trajectory generation followed by multimodal refinement. The central claims rest on a newly constructed 12.9-million-trajectory synthetic dataset and closed-loop evaluation on the external Bench2Drive benchmark. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text. The framework is presented as building on prior VLA capabilities without reducing any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision language action models possess a critic capability that can be leveraged for trajectory refinement in driving tasks
Reference graph
Works this paper leans on
-
[1]
reduce speed from 7.4 m/s to 3.5 m/s
using learnable queries. We utilize two types of learnable queries within the LLM’s structure. First are 512 vision queries, which are used for latent multimodal feature extraction and grounding within the LLM’s attention mechanism. Second are 16 trajectory queries, which interact with the contextualized hidden states and are directly mapped to the output...
2025
-
[2]
Semantic Analysis Phase:The model first performs an autoregressive decoding pass using the Language Critic Head, generating the complete risk assessment and action recommendations
-
[3]
Straight
Refinement Phase:Using the generated analysis as context, the model employs the Query-based Delta Adapters to directly predict refined trajectories. Training data.The CriticVLA refinement stage is trained exclusively on the CriticDrive dataset, which totals 3,081,848 annotated driving frames. This dataset is logically partitioned into three components: Gr...
2024
-
[4]
For dynamic actors, we utilize their future bounding boxes derived from the simulator’s ground truth
Candidate Selection:We identify candidate objects O (vehicles, pedestrians, static meshes) within the ego-vehicle’s future field of view. For dynamic actors, we utilize their future bounding boxes derived from the simulator’s ground truth
-
[5]
Spatiotemporal Matching:For a selected object O at a future timestep tcrash, we calculate the precise position pobj. We then derive a constant collision speedv crash required for the ego-vehicle to reachp obj exactly att crash: vcrash = ∥pego −p obj∥ −δ saf ety ∆tcrash (33) whereδ saf ety accounts for the physical extent of the vehicle and the object
-
[6]
maintain speed
Route Interpolation:We modify the geometric route to intersect with the target. The trajectory is reconstructed by interpolating between the current ego position and the collision point pobj, and then returning to the original route. The ego-vehicle is then simulated along this collision path at speed vcrash, guaranteeing a spatiotemporal overlap with the...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.