Recognition: unknown
Simulating Infant First-Person Sensorimotor Experience via Motion Retargeting from Babies to Humanoids
Pith reviewed 2026-05-07 09:50 UTC · model grok-4.3
The pith
A framework extracts 3D infant body poses from single videos and retargets the motions onto humanoid embodiments to produce simulated multimodal sensor streams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
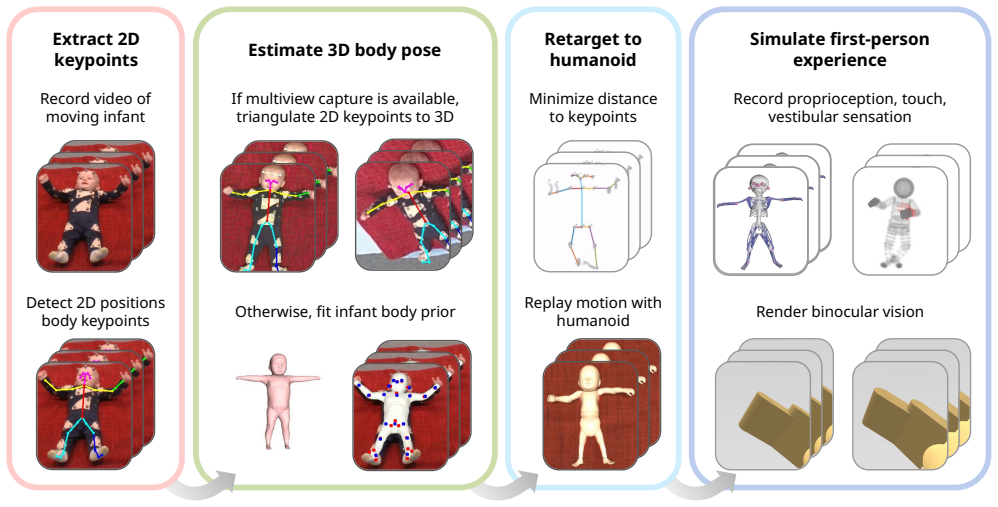
From a single video, the method reconstructs the infant's body configuration by extracting its skeletal structure and estimating the full 3D pose from each frame. Then we map the reconstructed motion onto several developmental platforms. Replaying the retargeted motions on these embodiments produces simulated multisensory streams including proprioception (joints and muscles), touch, and vision. For the best-matching embodiment, the retargeting achieves sub-centimeter accuracy and enables a rich multimodal analysis of infant development as well as enhanced automated annotation of behaviors.
What carries the argument
The motion retargeting pipeline that extracts skeletal structure and 3D poses from infant videos then maps them to humanoid embodiments to generate corresponding proprioceptive, tactile, and visual data streams.
If this is right
- Reconstructs full 3D infant body configurations and poses from single videos via skeletal extraction.
- Maps the motions to produce simulated proprioception, touch, and vision streams on target embodiments.
- Achieves sub-centimeter accuracy when the embodiment matches the infant scale well.
- Enables rich multimodal analysis of infant development from the generated data.
- Supports enhanced automated annotation of infant behaviors in the source videos.
Where Pith is reading between the lines
- The simulated streams could serve as standardized test cases for studying how differences in body size alter the interpretation of the same movement patterns.
- Researchers might extend the pipeline to generate large datasets for training models that detect early deviations in sensorimotor patterns.
- Varying the target embodiment parameters could reveal which aspects of body design most influence the fidelity of the simulated infant experience.
Load-bearing premise
Retargeting motions from infant bodies onto differently proportioned humanoid bodies with different joint limits and sensor placements still produces sensor streams that meaningfully approximate the infant's actual proprioceptive, tactile, and visual experiences.
What would settle it
Direct comparison of the simulated sensor streams against any available ground-truth sensor recordings from infants performing identical movements, or demonstration that retargeting error exceeds sub-centimeter levels across a broad set of infant videos.
Figures






read the original abstract
Motion retargeting from humans to human-like artificial agents is becoming increasingly important as humanoid robots grow more capable. However, most existing approaches focus only on reproducing kinematics and ignore the rich sensorimotor experience associated with human movement. In this work, we present a framework for simulating the multimodal sensorimotor experiences of infants using physical and virtual humanoids. From a single video, our method reconstructs the infant's body configuration by extracting its skeletal structure and estimating the full 3D pose from each frame. Then we map the reconstructed motion onto several developmental platforms: the physical iCub robot and the virtual simulators pyCub, EMFANT and MIMo. Replaying the retargeted motions on these embodiments produces simulated multisensory streams including proprioception (joints and muscles), touch, and vision. For the best-matching embodiment, the retargeting achieves sub-centimeter accuracy and enables a rich multimodal analysis of infant development as well as enhanced automated annotation of behaviors. This framework provides a unique window into the infant's sensorimotor experience, offering new tools for robotics, developmental science, and early detection of neurodevelopmental disorders. The code is available at https://github.com/ctu-vras/motion-retargeting/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a framework that extracts skeletal structure and estimates 3D pose from single videos of infants, then retargets the motion onto physical (iCub) and virtual (pyCub, EMFANT, MIMo) humanoid platforms to generate simulated multisensory streams (proprioception, touch, vision). It claims sub-centimeter kinematic accuracy for the best-matching embodiment and positions the approach as enabling rich multimodal analysis of infant development and early neurodevelopmental disorder detection, with code released publicly.
Significance. If the retargeted streams were shown to preserve functional sensorimotor consequences under the target embodiments' geometry and sensor layouts, the work would supply a reproducible tool for generating otherwise inaccessible first-person infant data, with direct value for developmental robotics and computational modeling of early cognition. The public code release strengthens the potential impact by supporting reproducibility.
major comments (3)
- [Abstract] Abstract: the assertion of 'sub-centimeter accuracy' for the best-matching embodiment supplies no error distributions, measurement protocol, baseline comparisons, or validation against ground-truth infant motion-capture data, leaving the central kinematic claim unsupported.
- [Methods] Methods (retargeting pipeline): body scaling and joint-mapping parameters are treated as free parameters yet no procedure is given for selecting or validating them so that the resulting proprioceptive, tactile, and visual streams remain functionally equivalent to infant experience despite large differences in body proportions and sensor placement.
- [Results] Results: no sensitivity analysis or quantitative comparison of derived quantities (joint-torque distributions, contact-force ranges, visual-field coverage) against published infant literature values is reported, so the claim that the streams 'enable a rich multimodal analysis' rests only on kinematic reproduction.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly distinguish kinematic retargeting accuracy from experiential fidelity.
- [Figures] Figure captions should state the exact embodiment used for each accuracy number and whether the metric is end-effector or joint-space error.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the strengths and limitations of our work. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'sub-centimeter accuracy' for the best-matching embodiment supplies no error distributions, measurement protocol, baseline comparisons, or validation against ground-truth infant motion-capture data, leaving the central kinematic claim unsupported.
Authors: We acknowledge that the abstract's kinematic claim would benefit from additional supporting details to stand alone. The full manuscript reports mean positional errors below 1 cm for the best-matching embodiment (iCub), computed via frame-by-frame comparison of retargeted joint positions to the source video pose estimates. In the revision we will update the abstract to reference these metrics explicitly and point to the Results section for distributions (to be added as box plots) and the measurement protocol (least-squares alignment of 3D keypoints after scaling). Baseline comparisons to naive retargeting without optimization will also be included. Direct validation against ground-truth infant motion-capture data remains unavailable; we instead benchmarked the pose estimator on adult video datasets with known 3D ground truth and on synthetic infant-like renders. This practical limitation will be stated clearly. revision: partial
-
Referee: [Methods] Methods (retargeting pipeline): body scaling and joint-mapping parameters are treated as free parameters yet no procedure is given for selecting or validating them so that the resulting proprioceptive, tactile, and visual streams remain functionally equivalent to infant experience despite large differences in body proportions and sensor placement.
Authors: We agree that the parameter selection process requires explicit description. Scaling factors and joint correspondences were determined by minimizing the sum of squared Euclidean distances between corresponding 3D keypoints after rigid alignment, using a gradient-free optimizer (Nelder-Mead) initialized from anthropometric tables. Validation consisted of both quantitative kinematic error and qualitative visual inspection of retargeted motions. We will insert a dedicated subsection in Methods detailing the objective function, initialization, and convergence criteria. We will also add a limitations paragraph noting that perfect functional equivalence is precluded by embodiment mismatches and that the pipeline prioritizes preservation of relative motion trajectories and resulting sensor activation patterns rather than absolute equivalence. revision: yes
-
Referee: [Results] Results: no sensitivity analysis or quantitative comparison of derived quantities (joint-torque distributions, contact-force ranges, visual-field coverage) against published infant literature values is reported, so the claim that the streams 'enable a rich multimodal analysis' rests only on kinematic reproduction.
Authors: This comment correctly identifies an opportunity to strengthen the multimodal claims. In the revised manuscript we will add a sensitivity analysis subsection that perturbs scaling and mapping parameters within plausible ranges and reports resulting variations in joint-torque histograms, contact-force magnitudes, and visual-field coverage metrics. We will further compare the obtained ranges against values drawn from the infant motor-control literature (e.g., peak forces during reaching and developmental changes in visual field extent). These additions will demonstrate that the generated streams produce sensorimotor statistics consistent with published infant data, thereby supporting the utility claim beyond kinematics alone. revision: yes
- Direct validation of retargeted kinematics against ground-truth 3D motion-capture recordings from infants, which is currently infeasible owing to ethical, safety, and technical constraints on acquiring such data from young infants.
Circularity Check
No circularity: standard pose estimation and retargeting pipeline with no self-referential equations or load-bearing self-citations
full rationale
The paper presents a methodological pipeline: extract skeletal structure and 3D pose from infant video, then retarget the motion to iCub/pyCub/EMFANT/MIMo embodiments to generate proprioceptive, tactile, and visual streams. No equations, fitted parameters, or derivations are described that reduce the output sensor streams to inputs by construction. The abstract and provided text contain no self-citations that justify uniqueness or force the central claim. The reader's assessment of score 2.0 aligns with this; the skeptic concern is about unquantified experiential fidelity (a correctness/validity issue), not circularity in the derivation chain. The work is self-contained against external benchmarks of pose estimation and retargeting accuracy.
Axiom & Free-Parameter Ledger
free parameters (1)
- body scaling and joint mapping parameters
axioms (1)
- domain assumption Infant body configuration can be reliably recovered from monocular video via skeletal extraction and 3D pose estimation
Reference graph
Works this paper leans on
-
[1]
Piaget, M
J. Piaget, M. Cooket al.,The origins of intelligence in children. International universities press New York, 1952, vol. 8, no. 5
1952
-
[2]
Helpless infants are learning a foundation model,
R. Cusack, M. Ranzato, and C. J. Charvet, “Helpless infants are learning a foundation model,”Trends in Cognitive Sciences, vol. 28, no. 8, pp. 726–738, 2024
2024
-
[3]
Lessons from infant learning for unsupervised machine learning,
L. Zaadnoordijk, T. R. Besold, and R. Cusack, “Lessons from infant learning for unsupervised machine learning,”Nature Machine Intelli- gence, vol. 4, no. 6, pp. 510–520, 2022
2022
-
[4]
Bayley scales of infant development: Manual,
N. Bayley, “Bayley scales of infant development: Manual,”New York, 1993
1993
-
[5]
Structuring of early reaching movements: a longitu- dinal study,
C. von Hofsten, “Structuring of early reaching movements: a longitu- dinal study,”Journal of motor behavior, vol. 23, no. 4, pp. 280–292, 1991
1991
-
[6]
Detection of intermodal proprioceptive–visual contingency as a potential basis of self- perception in infancy
L. E. Bahrick and J. S. Watson, “Detection of intermodal proprioceptive–visual contingency as a potential basis of self- perception in infancy.”Developmental psychology, vol. 21, no. 6, p. 963, 1985
1985
-
[7]
Infants tailor their attention to maximize learning,
F. Poli, G. Serino, R. Mars, and S. Hunnius, “Infants tailor their attention to maximize learning,”Science advances, vol. 6, no. 39, p. eabb5053, 2020
2020
-
[8]
A decade of infant neuroimaging research: what have we learned and where are we going?
A. Azhari, A. Truzzi, M. J.-Y . Neoh, J. P. M. Balagtas, H. H. Tan, P. P. Goh, X. A. Ang, P. Setoh, P. Rigo, M. H. Bornsteinet al., “A decade of infant neuroimaging research: what have we learned and where are we going?”Infant Behavior and Development, vol. 58, p. 101389, 2020
2020
-
[9]
Sampling development,
K. E. Adolph and S. R. Robinson, “Sampling development,”Journal of Cognition and Development, vol. 12, no. 4, pp. 411–423, 2011
2011
-
[10]
Video can make behavioural science more reproducible,
R. O. Gilmore and K. E. Adolph, “Video can make behavioural science more reproducible,”Nature human behaviour, vol. 1, no. 7, p. 0128, 2017
2017
-
[11]
A Naturalis- tic Observation of Spontaneous Touches to the Body and Environment in the First 2 Months of Life,
A. DiMercurio, J. P. Connell, M. Clark, and D. Corbetta, “A Naturalis- tic Observation of Spontaneous Touches to the Body and Environment in the First 2 Months of Life,”Frontiers in Psychology, vol. 9, 2018
2018
-
[12]
Automatic infant 2d pose estimation from videos: Comparing seven deep neural network methods,
F. Gama, M. M ´ısaˇr, L. Navara, S. T. Popescu, and M. Hoffmann, “Automatic infant 2d pose estimation from videos: Comparing seven deep neural network methods,”Behavior Research Methods, vol. 57, no. 10, p. 280, 2025
2025
-
[13]
Learning and tracking the 3d body shape of freely moving infants from rgb-d sequences,
N. Hesse, S. Pujades, M. J. Black, M. Arens, U. G. Hofmann, and A. S. Schroeder, “Learning and tracking the 3d body shape of freely moving infants from rgb-d sequences,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2540–2551, 2019
2019
-
[14]
Grounded language acquisition through the eyes and ears of a single child,
W. K. V ong, W. Wang, A. E. Orhan, and B. M. Lake, “Grounded language acquisition through the eyes and ears of a single child,” Science, vol. 383, no. 6682, pp. 504–511, 2024
2024
-
[15]
Simulated cortical magnifi- cation supports self-supervised object learning,
Z. Yu, A. Aubret, C. Yu, and J. Triesch, “Simulated cortical magnifi- cation supports self-supervised object learning,” in2025 IEEE Inter- national Conference on Development and Learning (ICDL). IEEE, 2025, pp. 1–6
2025
-
[16]
Infants’ use of eye movements to explore their natural environment,
T. R. Candy, S. Biehn, S. Freeman, A. Dalessandro, V . Tellez, B. Marella, K. Singh, Z. Petroff, K. Bonnen, and L. Smith, “Infants’ use of eye movements to explore their natural environment,”Journal of Vision, vol. 24, no. 10, pp. 974–974, 2024
2024
-
[17]
The icub humanoid robot: An open-systems platform for research in cognitive development,
G. Metta, L. Natale, F. Nori, G. Sandini, D. Vernon, L. Fadiga, C. V on Hofsten, K. Rosander, M. Lopes, J. Santos-Victoret al., “The icub humanoid robot: An open-systems platform for research in cognitive development,”Neural networks, vol. 23, no. 8-9, pp. 1125– 1134, 2010
2010
-
[18]
Mimo: A multimodal infant model for studying cognitive development,
D. Mattern, P. Schumacher, F. M. L ´opez, M. C. Raabe, M. R. Ernst, A. Aubret, and J. Triesch, “Mimo: A multimodal infant model for studying cognitive development,”IEEE Transactions on Cognitive and Developmental Systems, vol. 16, no. 4, pp. 1291–1301, 2024
2024
-
[19]
Simulating a human fetus in soft uterus,
D. Kim, H. Kanazawa, and Y . Kuniyoshi, “Simulating a human fetus in soft uterus,” in2022 IEEE International Conference on Development and Learning (ICDL). IEEE, 2022, pp. 135–141
2022
-
[20]
Deep learning-based human pose estimation: A survey,
C. Zheng, W. Wu, C. Chen, T. Yang, S. Zhu, J. Shen, N. Kehtarnavaz, and M. Shah, “Deep learning-based human pose estimation: A survey,” ACM Computing Surveys, vol. 56, no. 1, pp. 1–37, 2023
2023
-
[21]
ViTPose: Simple vision transformer baselines for human pose estimation,
Y . Xu, J. Zhang, Q. Zhang, and D. Tao, “ViTPose: Simple vision transformer baselines for human pose estimation,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[22]
Expressive body capture: 3D hands, face, and body from a single image,
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3D hands, face, and body from a single image,” inProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[23]
Methods and technologies for the implementation of large- scale robot tactile sensors,
A. Schmitz, P. Maiolino, M. Maggiali, L. Natale, G. Cannata, and G. Metta, “Methods and technologies for the implementation of large- scale robot tactile sensors,”IEEE Transactions on Robotics, vol. 27, no. 3, pp. 389–400, 2011
2011
-
[24]
Vernon, C
D. Vernon, C. V on Hofsten, and L. Fadiga,A roadmap for cognitive development in humanoid robots. Springer Science & Business Media, 2011, vol. 11
2011
-
[25]
The iCub platform: a tool for studying intrinsically motivated learning,
L. Natale, F. Nori, G. Metta, M. Fumagalli, S. Ivaldi, U. Pattacini, M. Randazzo, A. Schmitz, and G. Sandini, “The iCub platform: a tool for studying intrinsically motivated learning,” inIntrinsically motivated learning in natural and artificial systems. Springer, 2012, pp. 433–458
2012
-
[26]
Robotic homunculus: Learning of artificial skin representation in a humanoid robot motivated by primary somatosensory cortex,
M. Hoffmann, Z. Straka, I. Farkas, M. Vavrecka, and G. Metta, “Robotic homunculus: Learning of artificial skin representation in a humanoid robot motivated by primary somatosensory cortex,”IEEE Transactions on Cognitive and Developmental Systems, vol. 10, no. 2, pp. 163–176, June 2018
2018
-
[27]
Learning with pycub: A new simulation and exercise framework for humanoid robotics,
L. Rustler and M. Hoffmann, “Learning with pycub: A new simulation and exercise framework for humanoid robotics,” 2025. [Online]. Available: https://arxiv.org/abs/2506.01756
-
[28]
Retargeting infant movements to baby humanoid robots,
O. Fiala, “Retargeting infant movements to baby humanoid robots,” Bachelor’s thesis, Czech Technical University in Prague, 2023
2023
-
[29]
An embodied brain model of the human foetus,
Y . Yamada, H. Kanazawa, S. Iwasaki, Y . Tsukahara, O. Iwata, S. Ya- mada, and Y . Kuniyoshi, “An embodied brain model of the human foetus,”Scientific Reports, vol. 6, 2016
2016
-
[30]
Opensim: Simulating musculoskeletal dynamics and neuromuscular control to study human and animal movement,
A. Seth, J. L. Hicks, T. K. Uchida, A. Habib, C. L. Dembia, J. J. Dunne, C. F. Ong, M. S. DeMers, A. Rajagopal, M. Millardet al., “Opensim: Simulating musculoskeletal dynamics and neuromuscular control to study human and animal movement,”PLoS computational biology, vol. 14, no. 7, p. e1006223, 2018
2018
-
[31]
Mimo grows! simulating body and sensory development in a mul- timodal infant model,
F. M. L ´opez, M. Lenz, M. G. Fedozzi, A. Aubret, and J. Triesch, “Mimo grows! simulating body and sensory development in a mul- timodal infant model,” in2025 IEEE International Conference on Development and Learning (ICDL). IEEE, 2025
2025
-
[32]
AnthroKids - Anthropometric data of children,
S. Ressler, “AnthroKids - Anthropometric data of children,”Nat. Inst. Standards and Technol., 1977
1977
-
[33]
Keeping the arm in the limelight: Advanced visual control of arm movements in neonates,
A. L. van der Meer, “Keeping the arm in the limelight: Advanced visual control of arm movements in neonates,”European Journal of Paediatric Neurology, vol. 1, no. 4, pp. 103–108, 1997
1997
-
[34]
Open-ended movements structure sensorimotor information in early human development,
H. Kanazawa, Y . Yamada, K. Tanaka, M. Kawai, F. Niwa, K. Iwanaga, and Y . Kuniyoshi, “Open-ended movements structure sensorimotor information in early human development,”Proceedings of the National Academy of Sciences, vol. 120, no. 1, p. e2209953120, 2023
2023
-
[35]
Independent devel- opment of the reach and the grasp in spontaneous self-touching by human infants in the first 6 months,
B. L. Thomas, J. M. Karl, and I. Q. Whishaw, “Independent devel- opment of the reach and the grasp in spontaneous self-touching by human infants in the first 6 months,”Frontiers in psychology, vol. 5, p. 1526, 2015
2015
-
[36]
Self-touch and other spontaneous behavior patterns in early infancy,
J. Khoury, S. T. Popescu, F. Gama, V . Marcel, and M. Hoffmann, “Self-touch and other spontaneous behavior patterns in early infancy,” in2022 IEEE International Conference on Development and Learning (ICDL). IEEE, 2022, pp. 148–155
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.