Privacy-Preserving Federated Learning via Differential Privacy and Homomorphic Encryption for Cardiovascular Disease Risk Modeling
Pith reviewed 2026-05-07 07:35 UTC · model grok-4.3
The pith
Federated learning with homomorphic encryption matches centralized machine learning accuracy for cardiovascular risk prediction while differential privacy lowers compute costs at the price of greater accuracy loss in logistic regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
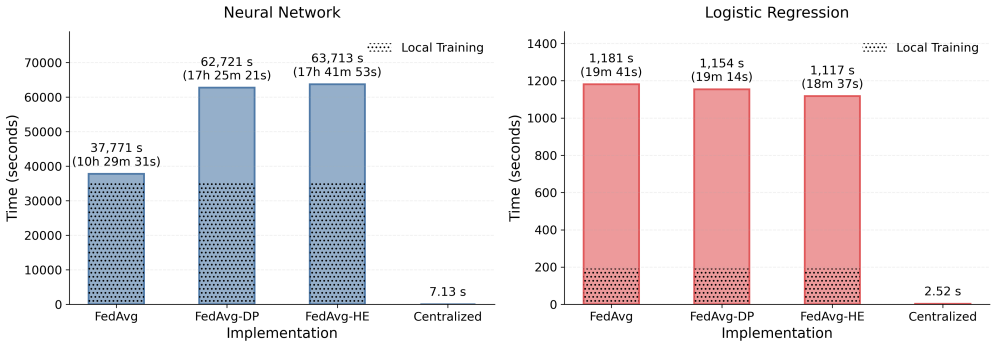
Federated learning combined with homomorphic encryption produces logistic regression and neural network models whose cardiovascular disease risk predictions on Swedish nationwide data reach performance levels comparable to centralized machine learning, at the expense of measurable increases in training time that are larger for neural networks. Federated learning combined with differential privacy incurs lower computational overhead but causes greater performance degradation for logistic regression than for neural networks because the former is more sensitive to the added noise.
What carries the argument
Side-by-side integration of differential privacy (noise addition to gradients or parameters) and homomorphic encryption (encrypted computation on model updates) inside federated learning loops, evaluated on logistic regression and neural network learners for binary cardiovascular risk classification.
If this is right
- Healthcare institutions can adopt homomorphic-encryption federated learning to collaborate on risk models without centralizing raw records and with only modest accuracy cost.
- Differential-privacy federated learning supplies a lower-cost alternative when hardware is limited, provided the model chosen is a neural network rather than logistic regression.
- The performance gap between the best privacy-enhanced federated approach and centralized learning is small enough to be acceptable for routine cardiovascular risk screening across fragmented hospital networks.
- Neural networks tolerate the noise required for differential privacy better than logistic regression does in this data regime.
Where Pith is reading between the lines
- For settings where training time matters more than marginal accuracy, differential privacy may be the practical default despite its larger effect on simpler models.
- The same privacy-compute trade-offs are likely to appear in other multi-site prediction tasks that use similar tabular clinical features.
- Hybrid schemes that apply lighter noise plus partial encryption could be tested to capture the speed of differential privacy and the accuracy retention of homomorphic encryption.
Load-bearing premise
The chosen noise scale for differential privacy and the cryptographic parameters for homomorphic encryption supply meaningful protection against real-world privacy attacks, and the Swedish dataset distribution adequately represents the heterogeneity across typical hospital sites.
What would settle it
Re-running the identical experiments on a second national health registry that exhibits larger demographic or coding differences and finding that both privacy-enhanced federated variants drop well below centralized accuracy.
Figures



read the original abstract
Protecting sensitive health data while enabling collaborative analysis is a central challenge in healthcare. Traditional machine learning (ML) requires institutions to pool anonymized patient records, centralizing analytical development and privacy risks at a single site. Privacy-enhancing technologies (PETs), including Differential Privacy (DP) and Homomorphic Encryption (HE), can mitigate these risks. However, they are mainly studied in conventional data-sharing settings and often introduce trade-offs, including reduced model utility, higher computational cost, and increased implementation complexity. Federated Learning (FL) reduces data centralization by enabling institutions to train models locally and share only model updates. Nevertheless, FL does not eliminate privacy risks, as shared parameters or gradients may still reveal sensitive information. Integrating DP or HE into FL can strengthen privacy guarantees, yet their comparative performance and deployment implications in real-world healthcare settings remain unclear. We systematically evaluated DP and HE integration in FL under real-world conditions, comparing them with standard FL and centralized ML (cML) to quantify privacy-utility trade-offs in multi-institutional settings. Using nationwide Swedish healthcare data, we evaluated cardiovascular disease risk prediction using logistic regression (LR) and neural network (NN) learners. FL with HE achieved performance comparable to cML but introduced measurable cryptographic overhead, particularly in the NN implementation. FL with DP incurred lower computational cost; however, LR was more sensitive to calibrated noise than the NN, resulting in greater performance degradation. Our findings provide practical guidance for deploying privacy-preserving FL in fragmented healthcare systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that integrating differential privacy (DP) and homomorphic encryption (HE) into federated learning (FL) for cardiovascular disease risk prediction on a Swedish nationwide dataset yields practical trade-offs: FL with HE achieves performance comparable to centralized ML (cML) at the cost of cryptographic overhead (especially for neural networks), while FL with DP has lower computational cost but causes greater performance degradation for logistic regression (LR) than for neural networks (NN). The work positions these empirical findings as guidance for deploying privacy-preserving FL in fragmented healthcare systems.
Significance. If the results hold, this systematic empirical comparison is significant for privacy-preserving ML in healthcare. It uses real nationwide data to quantify privacy-utility-compute trade-offs across two model classes and two PETs within FL, highlighting LR's greater sensitivity to DP noise. Such concrete guidance on model-specific behaviors can inform deployment decisions in multi-institutional settings where data centralization is restricted. The study adds to the literature by moving beyond isolated PET evaluations to head-to-head comparisons under the same data regime.
major comments (2)
- [§4 (Experimental Setup)] §4 (Experimental Setup): The partitioning of the Swedish nationwide dataset into simulated institutions is not described in sufficient detail. It is unclear whether the split was random, index-based, or stratified using available covariates (region, age distribution, hospital type) to induce realistic covariate or label shift. No external validation against actual Swedish hospital-level statistics is reported. This directly undermines the central claim of evaluating under 'real-world conditions' and 'multi-institutional heterogeneity,' as random partitioning would make observed utility losses and overheads artifacts of the simulation rather than representative of typical institutional fragmentation.
- [§5 (Results)] §5 (Results): The abstract and results sections state comparative outcomes (FL+HE comparable to cML; LR more sensitive to DP noise than NN) but supply no details on exact privacy budgets (ε or noise scale), HE cryptographic parameters, statistical significance tests, error bars or confidence intervals, data preprocessing steps, or hyperparameter selection. Without these, it is impossible to judge whether reported differences are robust or influenced by post-hoc tuning, weakening the soundness of all empirical claims.
minor comments (2)
- [Abstract] Abstract: The qualitative statements ('measurable cryptographic overhead,' 'greater performance degradation') would be more informative if accompanied by at least one or two key quantitative metrics (e.g., AUC delta or runtime multiplier) to give readers an immediate sense of effect size.
- [Introduction] Notation and terminology: Ensure consistent expansion of acronyms on first use (cML, PETs) and that 'real-world conditions' is explicitly defined in the introduction rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important areas for improving the description of our experimental setup and the transparency of our results. We will revise the manuscript to address these points fully, enhancing the reproducibility and interpretability of our findings on privacy-utility trade-offs in federated learning for cardiovascular disease risk prediction.
read point-by-point responses
-
Referee: §4 (Experimental Setup): The partitioning of the Swedish nationwide dataset into simulated institutions is not described in sufficient detail. It is unclear whether the split was random, index-based, or stratified using available covariates (region, age distribution, hospital type) to induce realistic covariate or label shift. No external validation against actual Swedish hospital-level statistics is reported. This directly undermines the central claim of evaluating under 'real-world conditions' and 'multi-institutional heterogeneity,' as random partitioning would make observed utility losses and overheads artifacts of the simulation rather than representative of typical institutional fragmentation.
Authors: We thank the referee for pointing out the insufficient detail in the description of the dataset partitioning. We agree that this information is crucial for evaluating the realism of the multi-institutional heterogeneity in our simulations. In the revised version of the manuscript, we will substantially expand §4 to include a full description of how the Swedish nationwide dataset was partitioned into simulated institutions, specifying whether the split was random, index-based, or stratified by covariates such as region, age, or hospital type, along with the number of partitions and any measures taken to induce or assess covariate and label shift. Additionally, we will include a limitations subsection discussing the challenges of external validation against actual Swedish hospital-level statistics and the implications for generalizing our findings to real fragmented healthcare systems. This will allow readers to better contextualize the observed privacy-utility-compute trade-offs. revision: yes
-
Referee: §5 (Results): The abstract and results sections state comparative outcomes (FL+HE comparable to cML; LR more sensitive to DP noise than NN) but supply no details on exact privacy budgets (ε or noise scale), HE cryptographic parameters, statistical significance tests, error bars or confidence intervals, data preprocessing steps, or hyperparameter selection. Without these, it is impossible to judge whether reported differences are robust or influenced by post-hoc tuning, weakening the soundness of all empirical claims.
Authors: We acknowledge that the results section and abstract would benefit from greater specificity regarding the experimental parameters and statistical details to allow full assessment of the robustness of our findings. In the revised manuscript, we will add the following information: the precise privacy budgets (ε values) and corresponding noise scales used in the DP-FL experiments; the HE cryptographic parameters such as security level, polynomial modulus degree, and ciphertext modulus for the homomorphic encryption scheme; details on statistical significance testing (e.g., Wilcoxon signed-rank tests or t-tests with reported p-values); error bars representing standard deviations from multiple runs with confidence intervals; a complete description of data preprocessing steps including normalization, imputation for missing values, and feature selection; and the hyperparameter selection methodology (e.g., grid search over learning rates, batch sizes, and network architectures using cross-validation on a held-out portion of the data). These additions will be placed in the methods and results sections, ensuring that the comparative outcomes between FL+HE, FL+DP, and cML can be evaluated for their reliability. revision: yes
Circularity Check
Empirical comparison study with no derivation chain or self-referential reductions
full rationale
The paper is an experimental evaluation of DP and HE integrations into federated learning for CVD risk prediction on partitioned Swedish nationwide data, comparing LR and NN models against centralized baselines. No mathematical derivations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes are present in the abstract or described methodology. All claims rest on measured performance metrics (utility, overhead) from concrete runs rather than any equation or self-citation that reduces to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- DP noise scale or epsilon budget
- HE cryptographic parameters
axioms (2)
- domain assumption Logistic regression and neural networks are appropriate base learners for cardiovascular disease risk modeling on the Swedish data.
- domain assumption The nationwide Swedish dataset exhibits sufficient site-to-site heterogeneity to serve as a realistic test of federated learning.
Reference graph
Works this paper leans on
-
[1]
Khan, F.et al.Privacy enhancing technologies for intelligent healthcare: Research challenges and opportunities.ACM Comput. Surv.58, 1–27 (2026)
work page 2026
-
[2]
Dwork, C., McSherry, F., Nissim, K. & Smith, A. Calibrating noise to sensitivity in private data analysis. InTheory of cryptography conference, 265–284 (Springer, 2006)
work page 2006
-
[3]
Acar, A., Aksu, H., Uluagac, A. S. & Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. (Csur)51, 1–35 (2018)
work page 2018
-
[4]
McMahan, B., Moore, E., Ramage, D., Hampson, S. & y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, 1273–1282 (PMLR, 2017)
work page 2017
- [5]
-
[6]
Ma, X., Wang, J. & Zhang, X. Towards privacy-preserving and communication-efficient federated distillation.Expert. Syst. with Appl.312, 131503, DOI: https://doi.org/10.1016/j.eswa.2026.131503 (2026)
-
[7]
InProceedings of the AAAI conference on artificial intelligence, vol
Cheng, A.et al.Dpnas: Neural architecture search for deep learning with differential privacy. InProceedings of the AAAI conference on artificial intelligence, vol. 36, 6358–6366 (2022)
work page 2022
-
[8]
Pannekoek, M. & Spigler, G. Investigating trade-offs in utility, fairness and differential privacy in neural networks.arXiv preprint arXiv:2102.05975(2021). 9.Negoescu, D. M.et al.Epsilon*: Privacy metric for machine learning models.arXiv preprint arXiv:2307.11280(2023)
-
[9]
Wei, C.et al.Dpmlbench: Holistic evaluation of differentially private machine learning. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2621–2635 (2023)
work page 2023
-
[10]
Matias, C., Ivaki, N. & Moraes, R. Exploring the impact of homomorphic encryption on the performance of machine learning algorithms. InProceedings of the 12th Latin-American Symposium on Dependable and Secure Computing, 120–125 (2023)
work page 2023
-
[11]
Minelli, M.Fully homomorphic encryption for machine learning. Ph.D. thesis, Université Paris sciences et lettres (2018)
work page 2018
- [12]
-
[13]
Saifullah, S., Mercier, D., Agne, S., Dengel, A. & Ahmed, S. Towards privacy preserved document image classification: a comprehensive benchmark.Int. J. on Document Analysis Recognit. (IJDAR)27, 475–499 (2024)
work page 2024
- [14]
-
[15]
Ameur, Y ., Bouzefrane, S. & Banerjee, S. Developing adaptive homomorphic encryption through exploration of differential privacy.J. Cyber Secur. Mobil.13, 863–886, DOI: 10.13052/jcsm2245-1439.1353 (2024)
-
[16]
G., Checri, M., Stan, O., Sirdey, R
Sébert, A. G., Checri, M., Stan, O., Sirdey, R. & Gouy-Pailler, C. Combining homomorphic encryption and differential privacy in federated learning. In2023 20th Annual International Conference on Privacy, Security and Trust (PST), 1–7, DOI: 10.1109/PST58708.2023.10320195 (2023)
-
[17]
U., Shabbir, A., Chen, A., Flynn, D
Manzoor, H. U., Shabbir, A., Chen, A., Flynn, D. & Zoha, A. A survey of security strategies in federated learning: Defending models, data, and privacy.Futur. Internet16, 374 (2024). 19.Zhang, C.et al.A survey on federated learning.Knowledge-Based Syst.216, 106775 (2021)
work page 2024
- [18]
- [19]
-
[20]
arXiv preprint arXiv:2101.05428 , year=
Lv, Z.et al.Awfc: Preventing label flipping attacks towards federated learning for intelligent iot.The Comput. J.65, 2849–2859 (2022). 23.Mammen, P. M. Federated learning: Opportunities and challenges.arXiv preprint arXiv:2101.05428(2021). 12/14
-
[21]
Andreina, S., Marson, G. A., Möllering, H. & Karame, G. Baffle: Backdoor detection via feedback-based federated learning. In2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), 852–863 (IEEE, 2021)
work page 2021
-
[22]
Zhou, X., Xu, M., Wu, Y . & Zheng, N. Deep model poisoning attack on federated learning.Futur. Internet13, 73 (2021)
work page 2021
- [23]
-
[24]
Shokri, R., Stronati, M., Song, C. & Shmatikov, V . Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), 3–18 (IEEE, 2017)
work page 2017
-
[25]
El Ouadrhiri, A. & Abdelhadi, A. Differential privacy for deep and federated learning: A survey.IEEE access10, 22359–22380 (2022)
work page 2022
-
[26]
Adnan, M., Kalra, S., Cresswell, J. C., Taylor, G. W. & Tizhoosh, H. R. Federated learning and differential privacy for medical image analysis.Sci. reports12, 1953 (2022). 30.Dong, J., Roth, A. & Su, W. J. Gaussian differential privacy.J. Royal Stat. Soc. Ser. B: Stat. Methodol.84, 3–37 (2022)
work page 1953
- [27]
-
[28]
Brakerski, Z., Gentry, C. & Vaikuntanathan, V . (leveled) fully homomorphic encryption without bootstrapping.ACM Transactions on Comput. Theory (TOCT)6, 1–36 (2014). 33.Gentry, C.A fully homomorphic encryption scheme(Stanford university, 2009)
work page 2014
-
[29]
Cheon, J. H., Kim, A., Kim, M. & Song, Y . Homomorphic encryption for arithmetic of approximate numbers. In International conference on the theory and application of cryptology and information security, 409–437 (Springer, 2017)
work page 2017
-
[30]
Cheon, J. H., Han, K., Kim, A., Kim, M. & Song, Y . Bootstrapping for approximate homomorphic encryption. InAnnual International Conference on the Theory and Applications of Cryptographic Techniques, 360–384 (Springer, 2018)
work page 2018
-
[31]
Bossuat, J.-P., Troncoso-Pastoriza, J. & Hubaux, J.-P. Bootstrapping for approximate homomorphic encryption with negligible failure-probability by using sparse-secret encapsulation. InInternational Conference on Applied Cryptography and Network Security, 521–541 (Springer, 2022)
work page 2022
- [32]
-
[33]
Cheon, J. H., Han, K. & Hhan, M. Faster homomorphic discrete fourier transforms and improved FHE bootstrapping. Cryptol. ePrint Arch.(2018)
work page 2018
-
[34]
Cheon, J. H., Han, K., Kim, A., Kim, M. & Song, Y . A full rns variant of approximate homomorphic encryption. In International Conference on Selected Areas in Cryptography, 347–368 (Springer, 2018)
work page 2018
-
[35]
Sharma, G., Pajula, J.et al.End-to-End Architecture for Secure Cardiovascular Disease Risk Assessment and Clinical Care.Nord. Conf. on Digit. Heal. Wirel. Solutions 2026(2026). In Press. 41.Pedregosa, F.et al.Scikit-learn: Machine learning in Python.J. Mach. Learn. Res.12, 2825–2830 (2011)
work page 2026
-
[36]
Tenseal: A library for en- crypted tensor operations using homomorphic en- cryption
Benaissa, A., Retiat, B., Cebere, B. & Belfedhal, A. E. Tenseal: A library for encrypted tensor operations using homomorphic encryption.arXiv preprint arXiv:2104.03152(2021)
-
[37]
Nvflare weightedaggregationhelper
NVIDIA Corporation. Nvflare weightedaggregationhelper. https://nvflare.readthedocs.io/en/main/_modules/nvflare/app_ common/aggregators/weighted_aggregation_helper.html (2025). Accessed: 2026-02-06
work page 2025
-
[38]
Jamthikar, A.et al.Cardiovascular/stroke risk predictive calculators: a comparison between statistical and machine learning models.Cardiovasc. Diagn. Ther.10(2020)
work page 2020
-
[39]
Hara, K.et al.Claims-based algorithms for common chronic conditions were efficiently constructed using machine learning methods.Plos one16, e0254394 (2021). 46.Paduraru, L.et al.Integrating renal and metabolic parameters into a derived risk score for hyperuricemia in uncontrolled type 2 diabetes: A retrospective cross-sectional study in northwest romania....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.