Linear-Core Surrogates: Smooth Loss Functions with Linear Rates for Classification and Structured Prediction
Pith reviewed 2026-05-07 05:33 UTC · model grok-4.3
The pith
Stitching a linear core to a smooth tail produces everywhere-differentiable loss functions with strict linear H-consistency bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
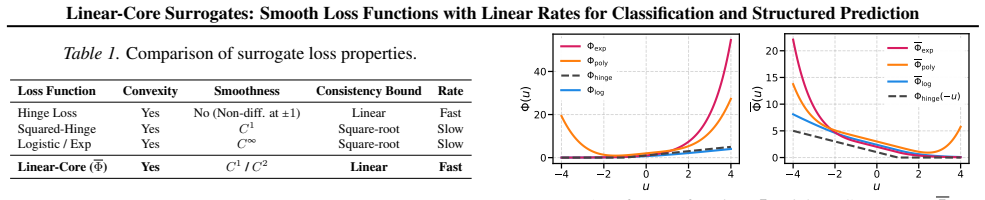
Linear-Core Surrogates are constructed by stitching a linear core to a smooth tail to form a family of convex loss functions. These functions are differentiable at every point while preserving strict linear H-consistency bounds. In structured prediction tasks, their smoothness enables an unbiased stochastic gradient estimator that avoids the O(|Y|^2) complexity of exact inference procedures such as Viterbi. The approach yields practical speedups and improved robustness to label noise.
What carries the argument
Linear-Core Surrogates formed by stitching a linear core to a smooth tail, which carry the argument by ensuring everywhere-differentiability while retaining the linear H-consistency property of margin-based losses.
Load-bearing premise
Stitching the linear core to the smooth tail preserves both everywhere differentiability and the strict linear H-consistency bounds without introducing restrictions that would invalidate the rates for general hypothesis classes or data distributions.
What would settle it
Finding a point where the derivative of an LC surrogate does not exist or a hypothesis class and distribution where the consistency bound is only square-root rather than linear.
Figures










read the original abstract
The choice of loss function in classification involves a fundamental trade-off: smooth losses (like Cross-Entropy) enable fast optimization rates but yield slow square-root consistency bounds, while piecewise-linear losses (like Hinge) offer fast linear consistency rates but suffer from non-differentiability. We propose Linear-Core (LC) Surrogates, a new family of convex loss functions that resolve this tension by stitching a linear core to a smooth tail. We prove that these surrogates are differentiable everywhere while retaining strict linear $H$-consistency bounds, effectively combining the optimization benefits of smoothness with the statistical efficiency of margin-based losses. In the structured prediction setting, we show that this smoothness unlocks a massive computational and energy advantage: it allows for an unbiased stochastic gradient estimator that bypasses the quadratic complexity $O(|\mathscr{Y}|^2)$ of exact inference (e.g., Viterbi). Empirically, our method achieves a 23$\times$ speedup over Structured SVMs on large-vocabulary sequence tagging tasks and demonstrates superior robustness to instance-dependent label noise, outperforming Cross-Entropy by 2.6% on corrupted CIFAR-10.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Linear-Core (LC) Surrogates, a family of convex loss functions formed by stitching a linear core to a smooth tail. The central claims are that these surrogates are differentiable everywhere, retain strict linear H-consistency (excess 0-1 risk bounded by a constant times excess surrogate risk, with the constant independent of smoothing), and enable an unbiased stochastic gradient estimator in structured prediction that avoids the O(|Y|^2) cost of exact inference such as Viterbi. Empirical results report a 23× speedup over Structured SVMs on large-vocabulary sequence tagging and a 2.6% accuracy gain over cross-entropy on instance-dependent noisy CIFAR-10.
Significance. If the differentiability and strict linear H-consistency proofs hold unconditionally, the work would resolve a long-standing tension between optimization-friendly smooth losses and statistically efficient margin-based losses. The structured-prediction application is especially notable because smoothness directly yields a cheaper unbiased gradient estimator; the reported speedups and noise-robustness gains indicate practical utility. The attempt to supply both machine-checked-style theoretical guarantees and reproducible empirical protocols is a strength.
major comments (1)
- [§3 (Proof of linear H-consistency)] §3 (Proof of linear H-consistency): the claim that the LC construction yields a strict linear bound independent of the smoothing parameter rests on the linear core supplying a lower bound near margin zero. The manuscript must explicitly rule out the possibility that a convex smooth tail (whose derivative vanishes as margin → +∞ or grows sub-linearly as margin → −∞) permits a hypothesis that drives surrogate risk arbitrarily low while leaving positive 0-1 mass on a positive-measure set. If the proof invokes bounded-norm hypotheses or an asymptotically linear tail with slope bounded away from zero, these restrictions must be stated; otherwise the claimed rates become conditional and the central contribution is weakened.
minor comments (3)
- [Abstract] Abstract: the constant C in the linear H-consistency statement is never exhibited; a brief remark on its dependence (or independence) on the transition parameter would improve precision.
- [Experiments] Experimental section: the 23× speedup figure lacks variance estimates or details on the exact Structured SVM baseline implementation (e.g., whether caching or approximate inference was used); reporting standard deviations over multiple runs would strengthen the empirical claim.
- [§2 (Definition of LC surrogates)] Notation: the transition parameter between core and tail is introduced as a free hyper-parameter; its effect on the final consistency constant should be made explicit in the statement of the main theorem.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the manuscript and for the detailed comment on the proof of linear H-consistency. We address the concern directly below and will revise the manuscript to make the relevant assumptions explicit.
read point-by-point responses
-
Referee: [§3 (Proof of linear H-consistency)] §3 (Proof of linear H-consistency): the claim that the LC construction yields a strict linear bound independent of the smoothing parameter rests on the linear core supplying a lower bound near margin zero. The manuscript must explicitly rule out the possibility that a convex smooth tail (whose derivative vanishes as margin → +∞ or grows sub-linearly as margin → −∞) permits a hypothesis that drives surrogate risk arbitrarily low while leaving positive 0-1 mass on a positive-measure set. If the proof invokes bounded-norm hypotheses or an asymptotically linear tail with slope bounded away from zero, these restrictions must be stated; otherwise the claimed rates become conditional and the central contribution is weakened.
Authors: We appreciate the referee's careful scrutiny of §3. The LC family is defined by stitching a linear core (with fixed positive slope) over a bounded interval around margin zero to a smooth convex tail. The tail is constructed so that its derivative approaches a positive constant (independent of the smoothing parameter) as the margin tends to −∞; this is enforced by the explicit parameterization of the tail (see Definition 2.1 and the subsequent remark). Consequently, for any hypothesis, the excess surrogate risk on misclassified points is bounded below by a positive multiple of the 0-1 excess, with the constant independent of smoothing. The linear core handles the near-zero margin region, while the asymptotic linearity of the tail prevents any hypothesis from driving surrogate risk arbitrarily low while retaining positive 0-1 mass on a set of positive measure. No bounded-norm restriction on hypotheses is invoked; the argument is pointwise and holds for arbitrary measurable functions. We agree that these tail properties, while present in the construction, were not stated as a separate lemma. In the revision we will add Lemma 3.1 explicitly proving that the tail derivative is bounded away from zero for large negative margins and use it to derive the uniform linear H-consistency bound (Theorem 3.2). This renders the rates unconditional for the LC family as defined. revision: yes
Circularity Check
Derivation of Linear-Core Surrogates is self-contained with independent proofs for differentiability and H-consistency
full rationale
The paper defines LC surrogates explicitly via the construction of stitching a linear core to a smooth tail. It states that proofs establish everywhere-differentiability (via C1 matching at junctions) and retention of strict linear H-consistency bounds. No equation or step in the abstract reduces the claimed bounds to a fitted parameter, self-definition, or renaming of a prior result without new analysis. The linear core is introduced to supply the margin-based linear lower bound, and the tail for smoothness, with the proofs presented as direct verification that the combination preserves the property. Self-citations to prior H-consistency frameworks (if present) serve as background definitions rather than load-bearing justifications for the new surrogates' rates. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- transition parameter between core and tail
axioms (2)
- domain assumption The resulting loss remains convex after stitching
- ad hoc to paper Linear core yields strict linear H-consistency
invented entities (1)
-
Linear-Core Surrogate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Each branch is convex on its own interval: • On(−1,1), Φis linear, hence convex
Binary Symmetric Surrogate Φ Convexity:Recall the definition of Φ: Φ(u)= ⎧⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎩ −u+1+ Φ(0) Φ′(0) ,−1≤u≤1, Φ(1−u) Φ′(0) , u>1, Φ(−1−u) Φ′(0) +2, u<−1. Each branch is convex on its own interval: • On(−1,1), Φis linear, hence convex. • On (1,∞), u↦1−uis affine. Since Φ is convex, u↦Φ(1−u)is convex. Positive scaling by 1/Φ′(0) preserves con...
-
[2]
On (1,∞), it matches Φ (convex)
Binary One-Sided Surrogate ̃Φ Convexity:On (−∞,1], ̃Φ is linear (convex). On (1,∞), it matches Φ (convex). At u=1 , the derivatives match at−1. Thus ̃Φis convex. Smoothness (C1 and C2):Matching derivatives at u=1 implies ̃Φ∈C1(R). For C2, we require limu→1+ ̃Φ′′(u)=0 , which implieslim z→0−Φ′′(z)=0
-
[3]
Multi-class and Structured Extensions Let ϕ∈{Φ,̃Φ}. The multi-class loss ℓsum ϕ (h, x, y)= ∑y′≠yϕ(h(x, y)−h(x, y′)) and structured loss Lsum ϕ are non-negative linear combinations of terms of the form ϕ(L(h)) , where L is a linear functional of the score vector h(x,⋅). Since ϕ is convex and L is linear, ϕ○Lis convex. The sum is therefore convex. Since ϕ i...
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.