Reorganizing Quantum Measurement Records Improves Time-Series Prediction
Pith reviewed 2026-05-07 06:30 UTC · model grok-4.3
The pith
Splitting quantum measurement shots into groups gives the readout more training examples and improves time-series prediction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
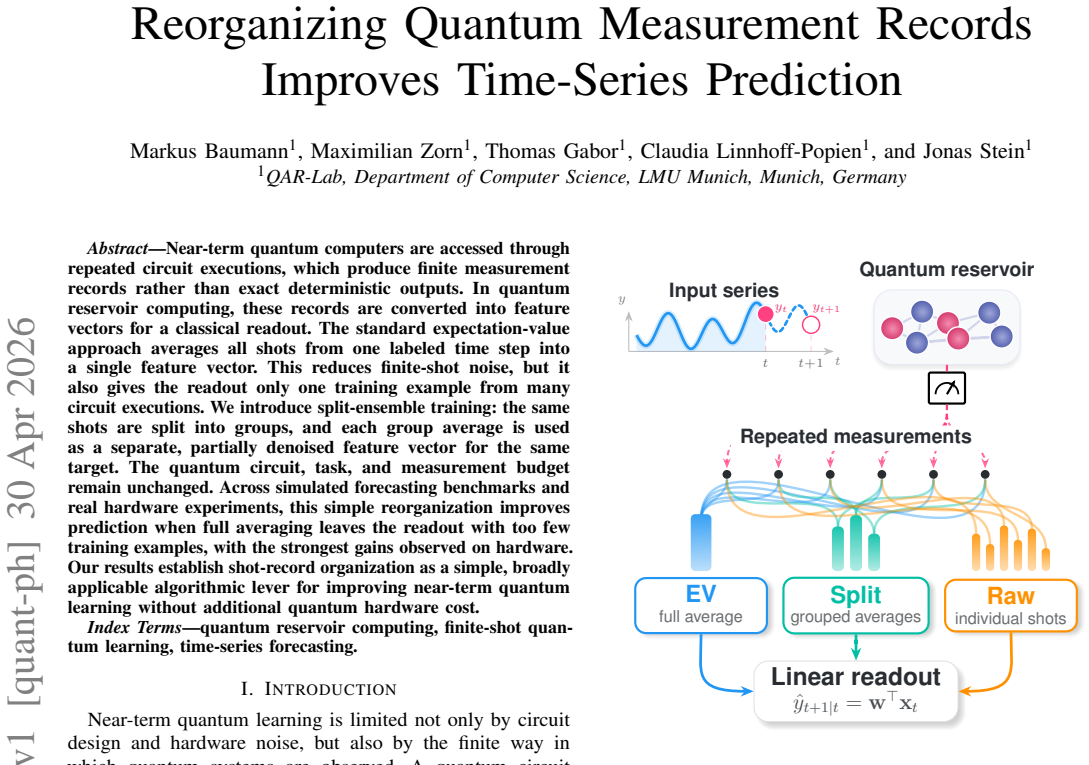
Split-ensemble training partitions the finite shot record collected for each labeled time step into groups, computes an average readout for every group, and feeds each group average to the classical readout as a distinct training vector while keeping the target value unchanged. The quantum circuit, task, and total measurement budget stay identical, yet the effective training set grows and retains partial noise suppression, producing lower prediction error than the single full-average vector when the number of examples is small.
What carries the argument
Split-ensemble training, the division of shots from each execution into groups whose separate averages become distinct feature vectors for the unchanged target.
Load-bearing premise
The averages computed from the split groups stay independent enough and free of new bias that the readout learns more effectively than from the single full average.
What would settle it
On the same hardware and forecasting task, the prediction error with split-group averages equals or exceeds the error obtained from full averaging, especially in regimes where the full-average method already supplies few training examples.
Figures







read the original abstract
Near-term quantum computers are accessed through repeated circuit executions, which produce finite measurement records rather than exact deterministic outputs. In quantum reservoir computing, these records are converted to feature vectors for a classical readout. The standard expectation-value approach averages all shots from one labeled time step into a single feature vector. This reduces finite-shot noise, but it also gives the readout only one training example from many circuit executions. We introduce split-ensemble training: the same shots are split into groups, and each group average is used as a separate, partially denoised feature vector for the same target. The quantum circuit, task, and measurement budget remain unchanged. Across simulated forecasting benchmarks and real hardware experiments, this simple reorganization improves prediction when full averaging leaves the readout with too few training examples, with the strongest gains observed on hardware. Our results establish shot-record organization as a simple, broadly applicable algorithmic lever for improving near-term quantum learning without additional quantum hardware cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces split-ensemble training for quantum reservoir computing on time-series prediction tasks. Instead of averaging all measurement shots from a given circuit execution (labeled by time step) into a single feature vector, the shots are partitioned into multiple groups, with each group average serving as a separate training example for the same target label. The quantum circuit, task, and total shot budget remain fixed. The authors report that this reorganization yields improved prediction accuracy on simulated forecasting benchmarks and real quantum hardware experiments, particularly when the number of distinct time steps is small and full averaging results in too few training examples for the classical readout. The strongest improvements are observed on hardware.
Significance. If the empirical gains are robust, the work identifies a simple, zero-overhead reorganization of existing shot records that can increase the effective training set size for the classical readout without altering the quantum circuit or measurement budget. This is relevant for NISQ-era quantum reservoir computing and related variational algorithms where the number of distinct input circuits (rather than total executions) limits the training data. The hardware results, if confirmed with proper controls, would strengthen the case for practical algorithmic levers in near-term quantum learning.
major comments (3)
- [Abstract and Results section] Abstract and Results section: The central claim of improved prediction is presented without quantitative details on statistical significance, error bars, exact baseline comparisons, data-exclusion rules, or the number of independent runs. This absence prevents assessment of whether the reported gains exceed what could be obtained by adjusting regularization strength on the standard full-average feature vectors.
- [Methods and Results sections] Methods and Results sections: The split-group averages for a fixed time step are formed by partitioning the identical set of circuit executions and therefore share the same underlying quantum state, finite-shot fluctuations, and any hardware-specific temporal correlations. The manuscript provides no covariance analysis of the resulting feature matrix, no comparison against noise-augmented full-average baselines, and no discussion of effective sample size under dependence. These omissions leave open the possibility that observed gains arise from incidental regularization effects rather than genuinely additional informative examples, directly bearing on the validity of the central claim.
- [§3] §3 (or equivalent methods description): The training procedure for the readout on multiple group averages per time step is not specified with respect to the loss function, whether the identical target label is assigned to all groups from the same time step, or how this affects optimization and generalization. Clarification is required to confirm that the reported improvement is not an artifact of the training protocol.
minor comments (1)
- [Abstract] The abstract refers to 'simulated forecasting benchmarks' without naming the specific tasks or metrics; the main text should include these details together with the exact hyper-parameters of the classical readout for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address each major comment below, indicating revisions where appropriate to enhance clarity, rigor, and completeness.
read point-by-point responses
-
Referee: Abstract and Results section: The central claim of improved prediction is presented without quantitative details on statistical significance, error bars, exact baseline comparisons, data-exclusion rules, or the number of independent runs. This absence prevents assessment of whether the reported gains exceed what could be obtained by adjusting regularization strength on the standard full-average feature vectors.
Authors: We agree that the original presentation lacked sufficient quantitative details. In the revised manuscript, we will include error bars (standard deviations over independent runs), specify the exact number of runs, report statistical significance measures such as p-values where applicable, detail baseline comparisons including explicit regularization sweeps on the full-average features, and clarify data handling and exclusion criteria. These additions will enable direct assessment of whether the gains surpass hyperparameter tuning on the standard approach. revision: yes
-
Referee: Methods and Results sections: The split-group averages for a fixed time step are formed by partitioning the identical set of circuit executions and therefore share the same underlying quantum state, finite-shot fluctuations, and any hardware-specific temporal correlations. The manuscript provides no covariance analysis of the resulting feature matrix, no comparison against noise-augmented full-average baselines, and no discussion of effective sample size under dependence. These omissions leave open the possibility that observed gains arise from incidental regularization effects rather than genuinely additional informative examples, directly bearing on the validity of the central claim.
Authors: The referee is correct that the split groups are dependent, sharing the same underlying executions. We will add a covariance analysis of the feature matrix and a discussion of effective sample size under dependence to the Methods section. We will also include explicit comparisons to noise-augmented full-average baselines. However, we maintain that the gains are not merely incidental regularization: partitioning into group averages supplies the linear readout with multiple partially denoised examples per time step, improving matrix conditioning when the number of distinct time steps is limited. This is particularly evident in the hardware experiments, where the improvements are largest and exceed those from regularization adjustments alone. We will revise the text to emphasize this distinction while incorporating the requested analyses. revision: partial
-
Referee: §3 (or equivalent methods description): The training procedure for the readout on multiple group averages per time step is not specified with respect to the loss function, whether the identical target label is assigned to all groups from the same time step, or how this affects optimization and generalization. Clarification is required to confirm that the reported improvement is not an artifact of the training protocol.
Authors: We apologize for the insufficient detail in the original Methods description. The identical target label is assigned to all group averages from the same time step, and the loss function is the standard mean-squared error for the regression task. The readout is trained via ridge regression (or equivalent solver), treating each group average as a distinct training instance. This augments the effective training set size while maintaining label consistency. We will revise §3 to explicitly state the loss function, label assignment rule, optimization method, and implications for generalization, including pseudocode for the procedure. We do not view this as an artifact, as the benefit stems from the increased number of lower-variance examples; the revision will make this fully transparent. revision: yes
Circularity Check
No significant circularity: empirical reorganization of shot records
full rationale
The paper introduces split-ensemble training as a direct reorganization of existing finite-shot measurement records into multiple group averages per time step, each serving as a separate feature vector for the same target label. No equations or derivations are presented that reduce the claimed performance improvement to a fitted parameter, self-referential definition, or self-citation chain. The central claim rests on empirical results from simulated forecasting benchmarks and real hardware experiments, which are external to any internal construction. The method does not invoke uniqueness theorems, ansatzes from prior self-work, or renaming of known results; it remains a straightforward algorithmic lever whose validity is tested against independent benchmarks rather than derived tautologically from its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Finite-shot quantum measurements produce records that can be partitioned and averaged to yield partially denoised feature vectors
- domain assumption A classical readout layer can extract useful signal from multiple partially denoised examples that share the same target label
Reference graph
Works this paper leans on
-
[1]
Harnessing Disordered-Ensemble Quantum Dynamics for Machine Learning,
K. Fujii and K. Nakajima, “Harnessing Disordered-Ensemble Quantum Dynamics for Machine Learning,”Physical Review Applied, vol. 8, no. 2, p. 024030, 2017
work page 2017
-
[2]
Boosting Computational Power through Spatial Multiplexing in Quantum Reservoir Computing,
K. Nakajima, K. Fujii, M. Negoro, K. Mitarai, and M. Kitagawa, “Boosting Computational Power through Spatial Multiplexing in Quantum Reservoir Computing,”Physical Review Applied, vol. 11, no. 3, p. 034021, 2019
work page 2019
-
[3]
Opportunities in Quantum Reservoir Computing and Extreme Learning Machines,
P. Mujal, R. Martínez-Peña, J. Nokkala, J. García-Beni, G. L. Giorgi et al., “Opportunities in Quantum Reservoir Computing and Extreme Learning Machines,”Advanced Quantum Technologies, vol. 4, no. 8, p. 2100027, 2021
work page 2021
-
[4]
Quantum Noise-Induced Reservoir Computing,
T. Kubota, Y . Suzuki, S. Kobayashi, Q. H. Tran, N. Yamamoto, and K. Nakajima, “Quantum Noise-Induced Reservoir Computing,” 2022
work page 2022
-
[5]
Role of Coherence in Many-Body Quantum Reservoir Computing,
A. Palacios de Luis, R. Martínez-Peña, M. C. Soriano, G. L. Giorgi, and R. Zambrini, “Role of Coherence in Many-Body Quantum Reservoir Computing,”Communications Physics, vol. 7, no. 1, p. 369, 2024
work page 2024
-
[6]
W. A. Fuller,Measurement Error Models. New York: Wiley, 1987
work page 1987
-
[7]
R. J. Carroll, D. Ruppert, L. A. Stefanski, and C. M. Crainiceanu, Measurement Error in Nonlinear Models: A Modern Perspective, 2nd ed. Boca Raton: Chapman & Hall/CRC, 2006
work page 2006
-
[8]
O. Ahmed, F. Tennie, and L. Magri, “Optimal Training of Finitely Sampled Quantum Reservoir Computers for Forecasting of Chaotic Dynamics,”Quantum Machine Intelligence, vol. 7, p. 31, 2025
work page 2025
-
[9]
Machine Learning of Quantum Channels on NISQ Devices,
G. Cemin, M. Cech, E. Weiss, S. Soltan, D. Braunet al., “Machine Learning of Quantum Channels on NISQ Devices,” 2024
work page 2024
-
[10]
Random Design Analysis of Ridge Regression,
D. Hsu, S. M. Kakade, and T. Zhang, “Random Design Analysis of Ridge Regression,” inProceedings of the 25th Conference on Learning Theory, ser. Proceedings of Machine Learning Research, vol. 23, 2012, pp. 9.1–9.24
work page 2012
-
[11]
High-Dimensional Asymptotics of Prediction: Ridge Regression and Classification,
E. Dobriban and S. Wager, “High-Dimensional Asymptotics of Prediction: Ridge Regression and Classification,”The Annals of Statistics, vol. 46, no. 1, pp. 247–279, 2018
work page 2018
-
[12]
W. Maass, T. Natschläger, and H. Markram, “Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations,”Neural Computation, vol. 14, no. 11, pp. 2531–2560, 2002
work page 2002
-
[13]
Reservoir Computing Approaches to Recurrent Neural Network Training,
M. Lukoševiˇcius and H. Jaeger, “Reservoir Computing Approaches to Recurrent Neural Network Training,”Computer Science Review, vol. 3, no. 3, pp. 127–149, 2009
work page 2009
-
[14]
Recent Advances in Physical Reservoir Computing: A Review,
G. Tanaka, T. Yamane, J. B. Héroux, R. Nakane, N. Kanazawaet al., “Recent Advances in Physical Reservoir Computing: A Review,”Neural Networks, vol. 115, pp. 100–123, 2019
work page 2019
-
[15]
Temporal Information Processing Induced by Quantum Noise,
T. Kubota, Y . Suzuki, S. Kobayashi, Q. H. Tran, N. Yamamoto, and K. Nakajima, “Temporal Information Processing Induced by Quantum Noise,”Physical Review Research, vol. 5, no. 2, p. 023057, 2023
work page 2023
-
[16]
Information Processing Capacity of Dynamical Systems,
J. Dambre, D. Verstraeten, B. Schrauwen, and S. Massar, “Information Processing Capacity of Dynamical Systems,”Scientific Reports, vol. 2, p. 514, 2012
work page 2012
-
[17]
Quantum Reservoir Computing in Finite Dimensions,
R. Martínez-Peña and J.-P. Ortega, “Quantum Reservoir Computing in Finite Dimensions,”Physical Review E, vol. 107, no. 3, p. 035306, 2023
work page 2023
-
[18]
Time-Series Quantum Reservoir Computing with Weak and Projective Measurements,
P. Mujal, R. Martínez-Peña, G. L. Giorgi, M. C. Soriano, and R. Zambrini, “Time-Series Quantum Reservoir Computing with Weak and Projective Measurements,”npj Quantum Information, vol. 9, p. 16, 2023
work page 2023
-
[19]
Nonlinear Input Transformations Are Ubiquitous in Quantum Reservoir Computing,
L. C. G. Govia, G. J. Ribeill, G. E. Rowlands, and T. A. Ohki, “Nonlinear Input Transformations Are Ubiquitous in Quantum Reservoir Computing,” Neuromorphic Computing and Engineering, vol. 2, no. 1, p. 014008, 2022
work page 2022
-
[20]
Information Processing Capacity of Spin-Based Quantum Reservoir Computing Systems,
R. Martínez-Peña, J. Nokkala, G. L. Giorgi, R. Zambrini, and M. C. Soriano, “Information Processing Capacity of Spin-Based Quantum Reservoir Computing Systems,”Cognitive Computation, vol. 15, no. 5, pp. 1440–1451, 2023
work page 2023
-
[21]
Hilbert Space as a Computational Resource in Reservoir Computing,
W. D. Kalfus, G. J. Ribeill, G. E. Rowlands, H. K. Krovi, T. A. Ohki, and L. C. G. Govia, “Hilbert Space as a Computational Resource in Reservoir Computing,”Physical Review Research, vol. 4, no. 3, p. 033007, 2022
work page 2022
-
[22]
Natural Quantum Reservoir Computing for Temporal Information Processing,
Y . Suzuki, Q. Gao, K. C. Pradel, K. Yasuoka, and N. Yamamoto, “Natural Quantum Reservoir Computing for Temporal Information Processing,” Scientific Reports, vol. 12, p. 1353, 2022
work page 2022
-
[23]
Dissipation as a Resource for Quantum Reservoir Computing,
A. Sannia, R. Martínez-Peña, M. C. Soriano, G. L. Giorgi, and R. Zam- brini, “Dissipation as a Resource for Quantum Reservoir Computing,” Quantum, vol. 8, p. 1291, 2024
work page 2024
-
[24]
D. Fry, A. Deshmukh, S. Y .-C. Chen, V . Rastunkov, and V . Markov, “Optimizing Quantum Noise-Induced Reservoir Computing for Nonlinear and Chaotic Time Series Prediction,”Scientific Reports, vol. 13, p. 19326, 2023
work page 2023
-
[25]
Quantum Reservoir Computing with a Single Nonlinear Oscillator,
L. C. G. Govia, G. J. Ribeill, G. E. Rowlands, H. K. Krovi, and T. A. Ohki, “Quantum Reservoir Computing with a Single Nonlinear Oscillator,” Physical Review Research, vol. 3, no. 1, p. 013077, 2021
work page 2021
-
[26]
F. Hu, G. Angelatos, S. A. Khan, M. Vives, E. Türeciet al., “Tackling Sampling Noise in Physical Systems for Machine Learning Applications: Fundamental Limits and Eigentasks,”Physical Review X, vol. 13, no. 4, p. 041020, 2023
work page 2023
-
[27]
Reduction of Finite Sampling Noise in Quantum Neural Networks,
D. A. Kreplin and M. Roth, “Reduction of Finite Sampling Noise in Quantum Neural Networks,”Quantum, vol. 8, p. 1385, 2024
work page 2024
-
[28]
Resource Frugal Optimizer for Quantum Machine Learning,
C. Moussa, M. H. Gordon, M. Baczyk, M. Cerezo, L. Cincio, and P. J. Coles, “Resource Frugal Optimizer for Quantum Machine Learning,” Quantum Science and Technology, vol. 8, no. 4, p. 045019, 2023
work page 2023
-
[29]
Generalization Error in Quantum Machine Learning in the Presence of Sampling Noise,
F. Hu and X. Gao, “Generalization Error in Quantum Machine Learning in the Presence of Sampling Noise,” 2024
work page 2024
-
[30]
Distribution of Eigenvalues for Some Sets of Random Matrices,
V . A. Marˇcenko and L. A. Pastur, “Distribution of Eigenvalues for Some Sets of Random Matrices,”Mathematics of the USSR-Sbornik, vol. 1, no. 4, pp. 457–483, 1967
work page 1967
- [31]
-
[32]
Oscillation and Chaos in Physiological Control Systems,
M. C. Mackey and L. Glass, “Oscillation and Chaos in Physiological Control Systems,”Science, vol. 197, no. 4300, pp. 287–289, 1977
work page 1977
-
[33]
Deterministic Nonperiodic Flow,
E. N. Lorenz, “Deterministic Nonperiodic Flow,”Journal of the Atmo- spheric Sciences, vol. 20, no. 2, pp. 130–141, 1963
work page 1963
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.