Recognition: unknown
SiriusHelper: An LLM Agent-Based Operations Assistant for Big Data Platforms
Pith reviewed 2026-05-09 21:03 UTC · model grok-4.3
The pith
SiriusHelper deploys an LLM agent that routes user queries, performs multi-hop retrieval via a hierarchical knowledge base, and distills SOPs from tickets to reduce big data platform support volume by 20.8 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
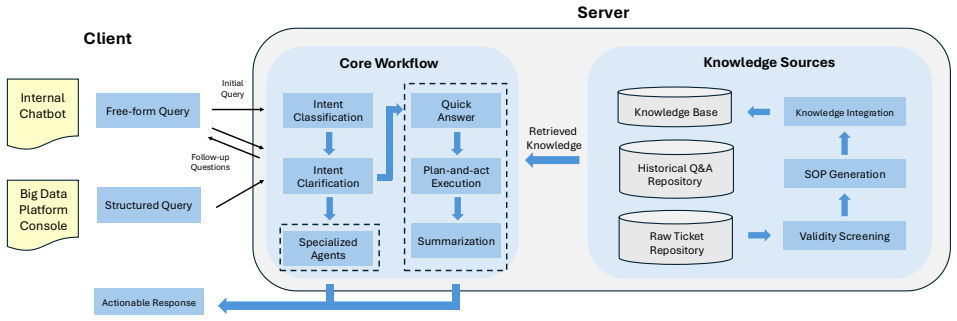
SiriusHelper acts as a unified online assistant that identifies user intent and routes queries to appropriate handling paths, including expert workflows for domain-specific cases like SQL execution diagnosis. It combines a DeepSearch-driven mechanism with a priority-based hierarchical knowledge base to support multi-hop retrieval without context overload. The system also performs automated ticket understanding to diagnose failure reasons and extract domain-specific SOPs that continuously enrich the knowledge base, resulting in better performance than alternatives and a measured 20.8 percent drop in online ticket volume during deployment on the Tencent Big Data platform.
What carries the argument
The DeepSearch-driven mechanism paired with a priority-based hierarchical knowledge base for multi-hop retrieval, together with automated ticket understanding and SOP distillation that diagnoses failures and adds reusable procedures back into the system.
If this is right
- The assistant outperforms representative alternatives in both offline experiments and live use.
- Online ticket volume drops by 20.8 percent once the system is active.
- Both broad consultation and specialized troubleshooting workflows receive dedicated handling paths.
- Escalated tickets are converted into structured SOPs that improve the knowledge base over time.
- Answer reliability rises and response latency falls for complex queries that require several retrieval steps.
Where Pith is reading between the lines
- The same routing-plus-hierarchical-retrieval pattern could transfer to other enterprise platforms that face similar general-versus-specialized query mixes.
- If ticket distillation works reliably, the volume of human expert involvement in support loops should continue to decline as the knowledge base matures.
- Extending the priority hierarchy to include temporal or usage-based weighting might further improve retrieval precision in rapidly changing data environments.
- Teams running large-scale data services could test whether replacing flat RAG indexes with this hierarchical approach yields comparable ticket reductions outside the original deployment setting.
Load-bearing premise
The DeepSearch mechanism with the hierarchical knowledge base will consistently deliver accurate multi-hop results without overwhelming context, and the automated analysis of tickets will correctly identify missing knowledge or routing errors to produce useful SOPs.
What would settle it
A controlled deployment in which multi-hop troubleshooting queries continue to produce incomplete or slow answers or in which ticket analysis yields no new reusable SOPs, so that ticket volume shows no measurable reduction after rollout.
Figures





read the original abstract
Big data platforms are widely used in modern enterprises, and an in-production intelligent assistant is increasingly important to help users quickly find actionable guidance and reduce operational burden. While recent LLM+RAG assistants provide a natural interface, they face practical challenges in real deployments: limited scenario coverage across both general consultation and domain-specific troubleshooting workflows, inefficient knowledge access due to inadequate multi-hop retrieval and flat knowledge organization, and high maintenance cost because escalated tickets are unstructured and hard to convert into assistant improvements and reusable SOPs. In this paper, we present SiriusHelper, a deployed intelligent assistant for big data platforms. SiriusHelper serves as a unified online assistant that automatically identifies user intent and routes queries to the right handling path, including dedicated expert workflows for specialized scenarios (e.g., SQL execution diagnosis). To support complex troubleshooting, SiriusHelper combines a DeepSearch-driven mechanism with a priority-based hierarchical knowledge base to enable multi-hop retrieval without context overload, thus improving answer reliability and latency. To reduce expert overhead, SiriusHelper further introduces automated ticket understanding and SOP distillation: it diagnoses the assistant failure reason (e.g., missing knowledge or wrong routing) and extracts domain-specific SOPs to continuously enrich the knowledge base. Experiments and online deployment on Tencent Big Data platform show that SiriusHelper outperforms representative alternatives and reduces online ticket volume by 20.8\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SiriusHelper, an LLM agent-based operations assistant for big data platforms. It automatically identifies user intent and routes queries to appropriate handling paths including expert workflows, combines a DeepSearch-driven mechanism with a priority-based hierarchical knowledge base for multi-hop retrieval, and introduces automated ticket understanding to diagnose failure reasons and distill SOPs for continuous KB enrichment. Experiments and online deployment on the Tencent Big Data platform are claimed to show outperformance over representative alternatives and a 20.8% reduction in online ticket volume.
Significance. If the empirical deployment outcomes hold under scrutiny, the work could have practical significance for applied LLM systems in enterprise big data operations by addressing scenario coverage, multi-hop knowledge access, and maintenance costs through a self-improving mechanism. The real-world deployment and ticket reduction result, if substantiated with proper controls, would provide valuable evidence of impact beyond synthetic benchmarks.
major comments (2)
- Abstract: The central claims of outperformance over alternatives and a 20.8% reduction in online ticket volume are presented without experimental details, baseline definitions, metric definitions, or statistical tests, preventing verification of the data-to-claim linkage for the headline result.
- Abstract: The automated ticket understanding and SOP distillation mechanism is described as diagnosing failure reasons (e.g., missing knowledge or wrong routing) and enriching the KB, but no quantitative validation of diagnosis precision, error analysis on extracted SOPs, or ablation studies showing the enrichment step improves retrieval quality are supplied; this is load-bearing for the self-improvement loop and the attributed ticket reduction.
minor comments (1)
- The abstract could more explicitly define key terms such as 'DeepSearch-driven mechanism' and 'priority-based hierarchical knowledge base' to improve accessibility for readers unfamiliar with the specific implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where revisions to the manuscript are planned.
read point-by-point responses
-
Referee: Abstract: The central claims of outperformance over alternatives and a 20.8% reduction in online ticket volume are presented without experimental details, baseline definitions, metric definitions, or statistical tests, preventing verification of the data-to-claim linkage for the headline result.
Authors: We agree the abstract is concise by design. The full experimental details—including baseline definitions (vanilla LLM, standard RAG, and other agent baselines), metrics (accuracy, latency, retrieval F1, and ticket volume), and statistical tests (paired t-tests with p-values reported)—appear in Section 5 (Experiments) and the online deployment subsection. The 20.8% reduction comes from a controlled production A/B test on the Tencent platform. To improve standalone readability of the abstract, we will add one sentence summarizing the evaluation methodology and explicitly directing readers to Section 5. revision: yes
-
Referee: Abstract: The automated ticket understanding and SOP distillation mechanism is described as diagnosing failure reasons (e.g., missing knowledge or wrong routing) and enriching the KB, but no quantitative validation of diagnosis precision, error analysis on extracted SOPs, or ablation studies showing the enrichment step improves retrieval quality are supplied; this is load-bearing for the self-improvement loop and the attributed ticket reduction.
Authors: The primary evidence for the self-improvement loop is the measured 20.8% ticket-volume reduction in the live deployment, which occurred after the SOP-distillation component was activated and directly addressed diagnosed gaps (missing knowledge or routing errors). We acknowledge that dedicated quantitative validation—diagnosis precision on annotated tickets, error analysis of extracted SOPs, and an ablation isolating the enrichment step—would strengthen the claim. We will add these analyses (including a new ablation table) to the revised Experiments section. revision: yes
Circularity Check
No derivational circularity; purely empirical system evaluation
full rationale
The paper describes an LLM-based assistant architecture (DeepSearch + hierarchical KB + automated ticket understanding) and supports its claims exclusively via deployment metrics on Tencent's platform, including a reported 20.8% ticket reduction. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. All load-bearing assertions reduce to observed outcomes rather than self-referential definitions or self-citation chains, rendering the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can accurately identify user intent and route queries to the correct expert workflow
- domain assumption A priority-based hierarchical knowledge base supports reliable multi-hop retrieval without context overload
invented entities (2)
-
DeepSearch-driven mechanism
no independent evidence
-
Automated ticket understanding and SOP distillation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sorinel Căpus,neanu, Cristian-Marian Barbu, Alina-Georgiana Solomon, and Ileana-Sorina Rakos. 2025. Reshaping the Digital Economy with Big Data: A Meta-Analysis of Trends and Technological Evolution.Electronics14, 13 (2025), 2709
2025
-
[2]
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. 2025. Towards reason- ing era: A survey of long chain-of-thought for reasoning large language models. arXiv preprint arXiv:2503.09567(2025)
work page internal anchor Pith review arXiv 2025
- [3]
-
[4]
Giuseppe Crupi, Rosalia Tufano, Alejandro Velasco, Antonio Mastropaolo, Denys Poshyvanyk, and Gabriele Bavota. 2025. On the Effectiveness of LLM-as-a- judge for Code Generation and Summarization.IEEE Transactions on Software Engineering(2025)
2025
-
[5]
Tianyu Cui, Ruowei Fu, Changchang Liu, Yuhe Ji, Wenwei Gu, Shenglin Zhang, Yongqian Sun, and Dan Pei. 2025. AetherLog: Log-based Root Cause Analysis by Integrating Large Language Models with Knowledge Graphs. In2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). 49–60. https://doi.org/10.1109/ISSRE66568.2025.00019
-
[6]
Umit Demirbaga and Gagangeet Singh Aujla. 2023. Rootpath: Root cause and critical path analysis to ensure sustainable and resilient consumer-centric big data processing under fault scenarios.IEEE Transactions on Consumer Electronics 70, 1 (2023), 1493–1500
2023
-
[7]
Umit Demirbaga, Zhenyu Wen, Ayman Noor, Karan Mitra, Khaled Alwasel, Saurabh Garg, Albert Y Zomaya, and Rajiv Ranjan. 2021. Autodiagn: An auto- mated real-time diagnosis framework for big data systems.IEEE Trans. Comput. 71, 5 (2021), 1035–1048
2021
-
[8]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 6491–6501
2024
-
[9]
Google. 2024. Try Deep Research and our new experimental model in Gemini, your AI assistant. https://blog.google/products/gemini/google-gemini-deep- research/
2024
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. DeepSeek-R1 incen- tivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
- [11]
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[13]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review arXiv 2025
-
[14]
Xinyuan Liu, Devki Nandan Jha, Yinhao Li, Mutaz Barika, Umit Demirbaga, and Rajiv Ranjan. 2024. AUTOMATE: Automatic anomaly detection and root cause analysis framework for hadoop. In2024 International Conference on Meta Computing (ICMC). IEEE, 213–222
2024
-
[15]
Siyang Lu, Xiang Wei, Bingbing Rao, Byungchul Tak, Long Wang, and Liqiang Wang. 2019. LADRA: Log-based abnormal task detection and root-cause analysis in big data processing with Spark.Future Generation Computer Systems95 (2019), 392–403
2019
-
[16]
OpenAI. 2025. Introducing Deep Research. https://openai.com/zh-Hans- CN/index/introducing-deep-research/
2025
-
[17]
Changhua Pei, Zexin Wang, Fengrui Liu, Zeyan Li, Yang Liu, Xiao He, Rong Kang, Tieying Zhang, Jianjun Chen, Jianhui Li, et al . 2025. Flow-of-Action: SOP Enhanced LLM-Based Multi-Agent System for Root Cause Analysis. In Companion Proceedings of the ACM on Web Conference 2025. 422–431
2025
-
[18]
Ananya Rahaman, Anny Zheng, Mostafa Milani, Fei Chiang, and Rachel Pottinger
- [19]
- [20]
-
[21]
Devjeet Roy, Xuchao Zhang, Rashi Bhave, Chetan Bansal, Pedro Las-Casas, Rodrigo Fonseca, and Saravan Rajmohan. 2024. Exploring llm-based agents for root cause analysis. InCompanion proceedings of the 32nd ACM international conference on the foundations of software engineering. 208–219
2024
-
[22]
Mohammad Shahnawaz and Manish Kumar. 2025. A comprehensive survey on big data analytics: Characteristics, tools and techniques.Comput. Surveys57, 8 (2025), 1–33
2025
-
[23]
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. InFindings of the Association for Computational Linguistics: EMNLP 2023. 9248–9274
2023
-
[24]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agen- tic retrieval-augmented generation: A survey on agentic rag.arXiv preprint arXiv:2501.09136(2025)
work page internal anchor Pith review arXiv 2025
-
[25]
Vikramank Singh, Kapil Eknath Vaidya, Vinayshekhar Bannihatti Kumar, Sopan Khosla, Murali Narayanaswamy, Rashmi Gangadharaiah, and Tim Kraska. 2024. Panda: Performance debugging for databases using LLM agents.(2024). (2024)
2024
-
[26]
Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. 2024. Rcagent: Cloud root cause analysis by autonomous agents with tool-augmented large language models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 4966–4974
2024
-
[27]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
2022
- [28]
- [29]
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Wei Zhang, Hongcheng Guo, Jian Yang, Zhoujin Tian, Yi Zhang, Yan Chaoran, Zhoujun Li, Tongliang Li, Xu Shi, Liangfan Zheng, et al. 2024. mABC: multi-Agent Blockchain-Inspired Collaboration for root cause analysis in micro-services architecture. InFindings of the Association for Computational Linguistics: EMNLP
2024
-
[32]
Xuchao Zhang, Supriyo Ghosh, Chetan Bansal, Rujia Wang, Minghua Ma, Yu Kang, and Saravan Rajmohan. 2024. Automated root causing of cloud incidents using in-context learning with GPT-4. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 266–277
2024
-
[33]
Honggang Zhou, Yunchun Li, Hailong Yang, Jie Jia, and Wei Li. 2018. Bigroots: An effective approach for root-cause analysis of stragglers in big data system. IEEE Access6 (2018), 41966–41977
2018
- [34]
- [35]
- [36]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.