Recognition: unknown
NLPOpt-Net: A Learning Method for Nonlinear Optimization with Feasibility Guarantees
Pith reviewed 2026-05-09 20:10 UTC · model grok-4.3
The pith
A neural network with quadratic projection layers learns parametric solutions to nonlinear programs while guaranteeing feasibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NLPOpt-Net learns the solution map of an NLP by passing a neural-network prediction through a k-layered projection that exploits local quadratic approximations of the original constraints; the projection is solved by a modified Chambolle-Pock method and back-propagated via the implicit-function theorem, guaranteeing feasibility by construction while the network loss drives the solution toward optimality.
What carries the argument
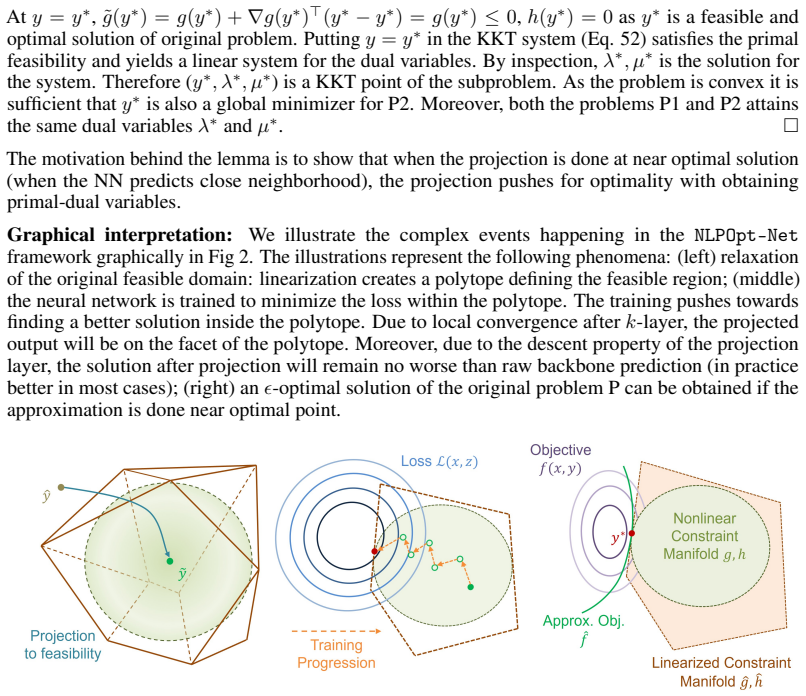
The k-layered projection operator that uses local quadratic approximations of the NLP to map neural-network predictions onto the original constraint manifold.
If this is right
- Large-scale convex QP, QCQP, NLP, and nonconvex problems are solved with near-zero optimality gap.
- Constraint violations are reduced to machine precision.
- Active sets and corresponding dual variables are predicted accurately enough to enable scalable multiparametric programming.
- Compiling the projection in C yields order-of-magnitude faster inference than a JAX implementation.
- The neural network and projection can be decoupled after training for efficient deployment.
Where Pith is reading between the lines
- Real-time control applications in process systems could use the decoupled projection for fast, guaranteed-feasible corrections to neural predictions.
- The quadratic-projection idea may combine with other differentiable optimization layers to create hybrid solvers for problems with mixed continuous-discrete constraints.
- If the descent property of the projection holds more generally, training could become more stable without additional regularization terms.
- The architecture supplies a template for embedding hard feasibility requirements into any learned optimizer that must respect physical or safety limits.
Load-bearing premise
The projection step improves neural-network predictions when the problem satisfies conditions such as convexity.
What would settle it
A benchmark suite of large-scale nonconvex NLPs on which the projected solutions exhibit constraint violations larger than machine epsilon or optimality gaps significantly above zero would disprove the performance guarantees.
Figures

read the original abstract
Nonlinear Parametric Optimization Network (NLPOpt-Net) is an unsupervised learning architecture to solve constrained nonlinear programs (NLP). Given the structure of an NLP, it learns the parametric solution maps with guaranteed constraint satisfaction. The architecture consists of a backbone neural network (NN) followed by a multilayer ($k$-layered) projection. While the NN drives toward optimality through a loss function consisting of a modified Lagrangian augmented with a consistency loss, the projection ensures feasibility by projecting the NN predictions in the original constraint manifold. Instead of typical distance minimization, our projection exploits local quadratic approximations of the original NLP. Under certain conditions (such as convexity), the projection has a descent property, which improves the NN predictions further. NLPOpt-Net deploys an inversion-free, modified Chambolle-Pock algorithm to solve the constrained quadratic projections during the forward pass and uses the implicit function theorem for efficient backpropagation. The fixed structure of the projection further allows decoupling of the NN and the projection once the training is complete. NLPOpt-Net solves large-scale convex QP, QCQP, NLP, and nonconvex problems with near zero optimality gap and constraint violations reduced to machine precision. Additionally, it provides near accurate prediction of the active sets and corresponding dual variables, thereby enabling a scalable approach for multiparametric programming. Compiling the projection in C provides order of magnitude improvement in inference time compared to JAX. We provide the codes and NLPOpt-Net as a ready to use package that includes GPU support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NLPOpt-Net, an unsupervised architecture for parametric nonlinear programs consisting of a backbone neural network followed by a k-layer projection. The NN is trained with a modified Lagrangian plus consistency loss, while the projection uses local quadratic approximations of the NLP solved via an inversion-free modified Chambolle-Pock algorithm to enforce feasibility on the original constraint manifold. The work claims near-zero optimality gaps, machine-precision constraint satisfaction, and accurate active-set/dual predictions for large-scale convex QP, QCQP, NLP, and nonconvex problems, with implicit-function backpropagation and optional C compilation for inference speed.
Significance. If the feasibility and performance claims are rigorously established, the method could meaningfully advance scalable, guaranteed-feasible learning-based solvers for multiparametric programming and real-time optimization. The combination of unsupervised training, projection-based guarantees, and post-training decoupling of the NN from the projection layer addresses practical deployment needs, and the open-source package with GPU/C support is a concrete strength.
major comments (2)
- [Abstract] Abstract: the central claim that NLPOpt-Net achieves 'constraint violations reduced to machine precision' for nonconvex problems is not supported by the stated conditions. The descent property is explicitly qualified as holding 'under certain conditions (such as convexity)', yet the manuscript asserts machine-precision feasibility across nonconvex NLPs without additional analysis showing that local quadratic approximations and the Chambolle-Pock steps still drive violations to machine epsilon when the quadratic model is inaccurate or progress is non-monotonic.
- [Projection layer / forward pass] Projection layer description (and any accompanying theorem): the feasibility guarantee for the k-layer projection rests on the local quadratic approximation plus the modified Chambolle-Pock solver, but no derivation or error bound is provided showing that the forward pass reaches machine precision on nonconvex manifolds. Without this, the implicit-function backpropagation and modified Lagrangian loss cannot compensate for potential failure of the projection to reduce violations monotonically.
minor comments (2)
- [Abstract] The abstract states that the projection 'exploits local quadratic approximations of the original NLP' but does not specify how the quadratic model is constructed or updated across layers; a brief equation or pseudocode would clarify the implementation.
- [Abstract] The claim of 'near accurate prediction of the active sets and corresponding dual variables' would benefit from a quantitative metric (e.g., active-set accuracy percentage or dual error norm) rather than the qualitative phrasing.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We appreciate the positive assessment of the method's potential and will revise the manuscript to better distinguish between the theoretical descent property (under convexity) and the empirical feasibility results observed across problem classes, including nonconvex NLPs.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that NLPOpt-Net achieves 'constraint violations reduced to machine precision' for nonconvex problems is not supported by the stated conditions. The descent property is explicitly qualified as holding 'under certain conditions (such as convexity)', yet the manuscript asserts machine-precision feasibility across nonconvex NLPs without additional analysis showing that local quadratic approximations and the Chambolle-Pock steps still drive violations to machine epsilon when the quadratic model is inaccurate or progress is non-monotonic.
Authors: We agree that the descent property of the projection is qualified under conditions such as convexity. The manuscript's claim of machine-precision constraint violations for nonconvex problems is an empirical observation supported by the numerical results on nonconvex test problems, where the k-layer projection consistently drives violations to machine epsilon despite the local quadratic model. We will revise the abstract to explicitly note that the machine-precision feasibility is observed empirically (while the descent guarantee holds under convexity), and we will add a short clarifying paragraph in Section 3 on the empirical behavior for nonconvex cases. revision: partial
-
Referee: [Projection layer / forward pass] Projection layer description (and any accompanying theorem): the feasibility guarantee for the k-layer projection rests on the local quadratic approximation plus the modified Chambolle-Pock solver, but no derivation or error bound is provided showing that the forward pass reaches machine precision on nonconvex manifolds. Without this, the implicit-function backpropagation and modified Lagrangian loss cannot compensate for potential failure of the projection to reduce violations monotonically.
Authors: The current analysis of the projection layer focuses on the local quadratic approximation and the convergence properties of the modified Chambolle-Pock algorithm under the stated conditions. No general error bound for arbitrary nonconvex manifolds is derived in the manuscript. We will revise the projection-layer section to state the scope of the theoretical results more clearly and to include a remark that, while monotonic reduction is not guaranteed for nonconvex problems, the iterative k-layer procedure empirically achieves machine-precision feasibility on the tested instances. This clarification addresses the concern without requiring a new theorem. revision: partial
Circularity Check
No significant circularity detected; derivation remains self-contained
full rationale
The NLPOpt-Net architecture is presented as a composite forward model: a backbone NN trained with a modified Lagrangian plus consistency loss, followed by a fixed k-layer projection that uses local quadratic approximations of the NLP and an inversion-free modified Chambolle-Pock solver. Feasibility is enforced by the projection step itself rather than being redefined as a prediction; the descent property is explicitly conditioned on convexity and not invoked to justify nonconvex performance. Backpropagation via the implicit function theorem and post-training decoupling of NN and projection are standard architectural choices that do not reduce any claimed optimality gap or machine-precision feasibility to a tautological re-expression of the training inputs. No load-bearing self-citation, fitted-parameter renaming, or ansatz smuggling appears in the provided derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The projection step has a descent property under convexity
Reference graph
Works this paper leans on
-
[1]
Nocedal and S
J. Nocedal and S. J. Wright,Numerical optimization. Springer, 2006
2006
-
[2]
On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming,
A. Wächter and L. T. Biegler, “On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming,”Mathematical programming, vol. 106, no. 1, pp. 25–57, 2006
2006
-
[3]
CONOPT: A grg code for large sparse dynamic nonlinear optimization problems,
A. Drud, “CONOPT: A grg code for large sparse dynamic nonlinear optimization problems,” Mathematical programming, vol. 31, no. 2, pp. 153–191, 1985
1985
-
[4]
Knitro: An integrated package for nonlinear optimization,
R. H. Byrd, J. Nocedal, and R. A. Waltz, “Knitro: An integrated package for nonlinear optimization,” inLarge-scale nonlinear optimization, pp. 35–59, Springer, 2006
2006
-
[5]
SNOPT: An sqp algorithm for large-scale constrained optimization,
P. E. Gill, W. Murray, and M. A. Saunders, “SNOPT: An sqp algorithm for large-scale constrained optimization,”SIAM review, vol. 47, no. 1, pp. 99–131, 2005
2005
-
[6]
B. Bank, J. Guddat, D. Klatte, B. Kummer, and K. Tammer,Nonlinear parametric optimization, vol. 58. Walter de Gruyter GmbH & Co KG, 1982
1982
-
[7]
E. N. Pistikopoulos, N. A. Diangelakis, and R. Oberdieck,Multiparametric optimization and control. John Wiley & Sons, 2020
2020
-
[8]
The explicit linear quadratic regulator for constrained systems,
A. Bemporad, M. Morari, V . Dua, and E. N. Pistikopoulos, “The explicit linear quadratic regulator for constrained systems,”Automatica, vol. 38, no. 1, pp. 3–20, 2002
2002
-
[9]
Multiparametric linear and quadratic programming,
D. Kenefake, I. Pappas, N. A. Diangelakis, S. Avraamidou, R. Oberdieck, and E. N. Pistikopoulos, “Multiparametric linear and quadratic programming,” inEncyclopedia of Optimization, pp. 1–5, Springer, 2023
2023
-
[10]
NeuroMANCER: Neural modules with adaptive nonlinear constraints and efficient regularizations,
J. Drgona, A. Tuor, J. Koch, M. Shapiro, B. Jacob, and D. Vrabie, “NeuroMANCER: Neural modules with adaptive nonlinear constraints and efficient regularizations,”URL https://github. com/pnnl/neuromancer, 2023
2023
-
[11]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,”Journal of Computational physics, vol. 378, pp. 686–707, 2019
2019
-
[12]
Imposing hard constraints on deep networks: Promises and limitations,
P. Márquez-Neila, M. Salzmann, and P. Fua, “Imposing hard constraints on deep networks: Promises and limitations,”arXiv preprint arXiv:1706.02025, 2017
-
[13]
Physics-informed Autoencoders for Lyapunov-stable Fluid Flow Prediction
N. B. Erichson, M. Muehlebach, and M. W. Mahoney, “Physics-informed autoencoders for lyapunov-stable fluid flow prediction,”arXiv preprint arXiv:1905.10866, 2019
work page Pith review arXiv 1905
-
[14]
Physics-informed neural networks for heat transfer problems,
S. Cai, Z. Wang, S. Wang, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks for heat transfer problems,”Journal of Heat Transfer, vol. 143, no. 6, p. 060801, 2021
2021
-
[15]
Operator splitting for convex constrained markov decision processes,
P. D. Grontas, A. Tsiamis, and J. Lygeros, “Operator splitting for convex constrained markov decision processes,”IEEE Transactions on Automatic Control, 2026
2026
-
[16]
When and why pinns fail to train: A neural tangent kernel perspective,
S. Wang, X. Yu, and P. Perdikaris, “When and why pinns fail to train: A neural tangent kernel perspective,”Journal of Computational Physics, vol. 449, p. 110768, 2022
2022
-
[17]
Data-driven strategies for optimization of integrated chemical plants,
K. Ma, N. V . Sahinidis, S. Amaran, R. Bindlish, S. J. Bury, D. Griffith, and S. Rajagopalan, “Data-driven strategies for optimization of integrated chemical plants,”Computers & Chemical Engineering, vol. 166, p. 107961, 2022
2022
-
[18]
Enforcing analytic constraints in neural networks emulating physical systems,
T. Beucler, M. Pritchard, S. Rasp, J. Ott, P. Baldi, and P. Gentine, “Enforcing analytic constraints in neural networks emulating physical systems,”Physical review letters, vol. 126, no. 9, p. 098302, 2021
2021
-
[19]
Learning optimal solutions for extremely fast ac optimal power flow,
A. S. Zamzam and K. Baker, “Learning optimal solutions for extremely fast ac optimal power flow,” in2020 IEEE international conference on communications, control, and computing technologies for smart grids (SmartGridComm), pp. 1–6, IEEE, 2020. 10
2020
-
[20]
DC3: A learning method for optimization with hard constraints,
P. Donti, D. Rolnick, and J. Z. Kolter, “DC3: A learning method for optimization with hard constraints,” inInternational Conference on Learning Representations, 2021
2021
-
[21]
OptNet: Differentiable optimization as a layer in neural networks,
B. Amos and J. Z. Kolter, “OptNet: Differentiable optimization as a layer in neural networks,” inInternational conference on machine learning, pp. 136–145, PMLR, 2017
2017
-
[22]
Differentiable convex optimization layers,
A. Agrawal, B. Amos, S. Barratt, S. Boyd, S. Diamond, and J. Z. Kolter, “Differentiable convex optimization layers,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[23]
Physics-informed neural networks with hard linear equality constraints,
H. Chen, G. E. C. Flores, and C. Li, “Physics-informed neural networks with hard linear equality constraints,”Computers & Chemical Engineering, vol. 189, p. 108764, 2024
2024
-
[24]
Physics-informed neural networks with hard nonlinear equality and inequality constraints,
A. Iftakher, R. Golder, B. N. Roy, and M. M. F. Hasan, “Physics-informed neural networks with hard nonlinear equality and inequality constraints,”Computers & Chemical Engineering, p. 109418, 2025
2025
-
[25]
DAE-HardNet: A physics constrained neural network enforcing differential-algebraic hard constraints,
R. Golder, B. N. Roy, and M. M. F. Hasan, “DAE-HardNet: A physics constrained neural network enforcing differential-algebraic hard constraints,”arXiv preprint arXiv:2512.05881, 2025
-
[26]
P. D. Grontas, A. Terpin, E. C. Balta, R. D’Andrea, and J. Lygeros, “Pinet: Optimizing hard-constrained neural networks with orthogonal projection layers,”arXiv preprint arXiv:2508.10480, 2025
-
[27]
Enforcing hard linear constraints in deep learning models with decision rules,
G. E. Constante-Flores, H. Chen, and C. Li, “Enforcing hard linear constraints in deep learning models with decision rules,”arXiv preprint arXiv:2505.13858, 2025
-
[28]
ENFORCE: Nonlinear Constrained Learning with Adaptive-depth Neural Projection
G. Lastrucci and A. M. Schweidtmann, “ENFORCE: Nonlinear constrained learning with adaptive-depth neural projection,”arXiv preprint arXiv:2502.06774, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
A first-order primal-dual algorithm for convex problems with applications to imaging,
A. Chambolle and T. Pock, “A first-order primal-dual algorithm for convex problems with applications to imaging,”Journal of mathematical imaging and vision, vol. 40, no. 1, pp. 120–145, 2011
2011
-
[30]
Distributed optimization and statistical learning via the alternating direction method of multipliers,
P. Neal, C. Eric, P. Borja, and E. Jonathan, “Distributed optimization and statistical learning via the alternating direction method of multipliers,”Foundations and Trends® in Machine learning, vol. 3, no. 1, pp. 1–122, 2011
2011
-
[31]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
CVXPY: A Python-embedded modeling language for convex optimization,
S. Diamond and S. Boyd, “CVXPY: A Python-embedded modeling language for convex optimization,”Journal of Machine Learning Research, 2016. To appear
2016
-
[33]
OSQP: An operator splitting solver for quadratic programs,
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd, “OSQP: An operator splitting solver for quadratic programs,”Mathematical Programming Computation, vol. 12, no. 4, pp. 637–672, 2020
2020
-
[34]
SCS: Splitting conic solver, version 3.2.11
B. O’Donoghue, E. Chu, N. Parikh, and S. Boyd, “SCS: Splitting conic solver, version 3.2.11.” https://github.com/cvxgrp/scs, Nov. 2023
2023
-
[35]
SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python,
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey, ˙I. Polat, Y . Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen...
2020
-
[36]
Boyd and L
S. Boyd and L. Vandenberghe,Convex optimization. Cambridge university press, 2004
2004
-
[37]
On the ergodic convergence rates of a first-order primal–dual algorithm,
A. Chambolle and T. Pock, “On the ergodic convergence rates of a first-order primal–dual algorithm,”Mathematical Programming, vol. 159, no. 1, pp. 253–287, 2016
2016
-
[38]
A scaling algorithm to equilibrate both rows and columns norms in matrices,
D. Ruiz, “A scaling algorithm to equilibrate both rows and columns norms in matrices,” tech. rep., CM-P00040415, 2001
2001
-
[39]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, Y . Katariya, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” 2018. 11 A Problem instance generation We provide the details of the problem generation for different computational studies here: QP:We ...
2018
-
[40]
Then the quadratic inequality becomes ∥Riy+q i∥2 ≤r i(x), i= 1,
Defining the radius ri(x) :=p ei −E ix+∥q i∥2 2 assumingr i(x)2 ≥0. Then the quadratic inequality becomes ∥Riy+q i∥2 ≤r i(x), i= 1, . . . , m.(41) Lets consider the parametric convex QCQP min y 1 2 y⊤Qy+c ⊤y s.t. Ay=b+Bx, y⊤Ciy+d ⊤ i y≤e i −E ix, i= 1, . . . , m, l+Lx≤y≤u+U x, (42) where Q⪰0 and Ci ⪰0 for all i= 1, . . . , m. With the reformulation the pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.