Quantum Data Loading for Carleman Linearized Systems: Application to the Lattice-Boltzmann Equation
Pith reviewed 2026-05-21 00:27 UTC · model grok-4.3
The pith
A matrix decomposition turns arbitrary operators into linear combinations of unitaries whose term count stays independent of grid size for Carleman-linearized systems like the lattice Boltzmann equation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
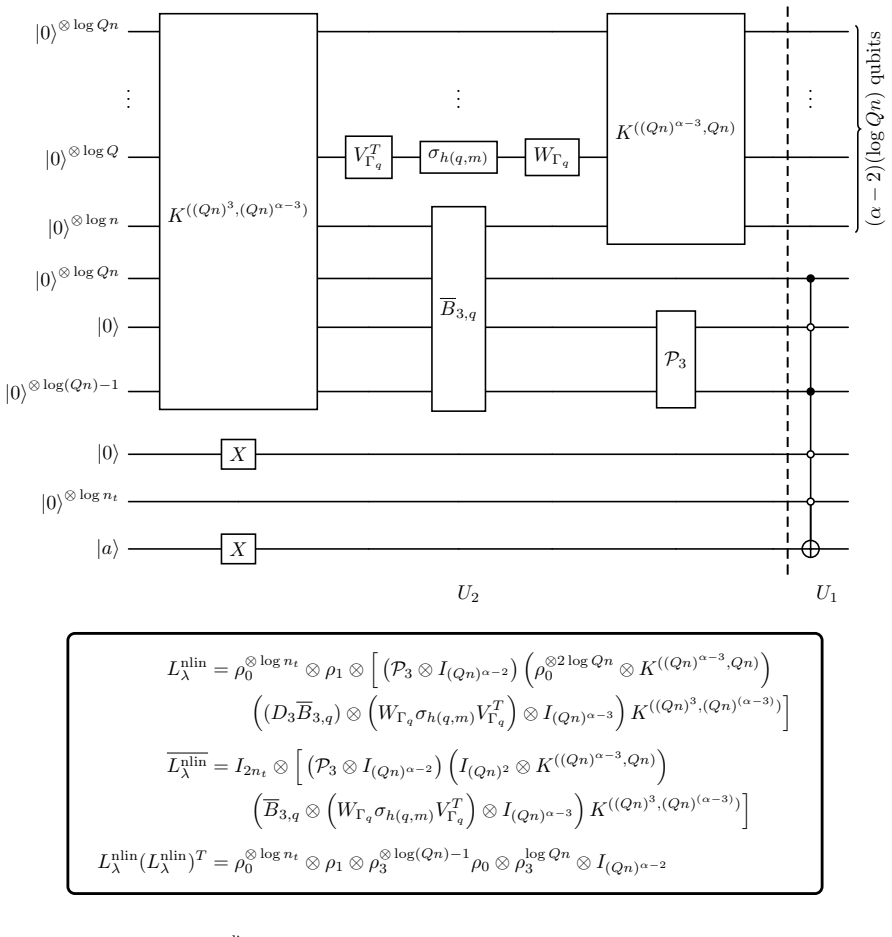
The authors introduce a decomposition that converts an arbitrary square matrix into a linear combination of non-unitaries and then embeds each non-unitary term inside a unitary, yielding a linear combination of unitaries with an equal number of terms. They show that this decomposition produces a generalized linear combination of unitaries framework for any Carleman-linearized autonomous dynamical system possessing a polynomial nonlinearity. For the three-dimensional Carleman-linearized lattice Boltzmann equation the number of terms scales as O(alpha squared Q squared), where alpha is the truncation order and Q is the number of discrete velocities, and this count is completely independent of
What carries the argument
The decomposition of an arbitrary square matrix into a linear combination of non-unitaries that each embed into unitaries to form a linear combination of unitaries with the same term count.
If this is right
- The linear combination of unitaries for the three-dimensional Carleman-linearized lattice Boltzmann equation has a term count that scales as O(alpha squared Q squared).
- The term count remains independent of both the number of temporal and spatial discretization points.
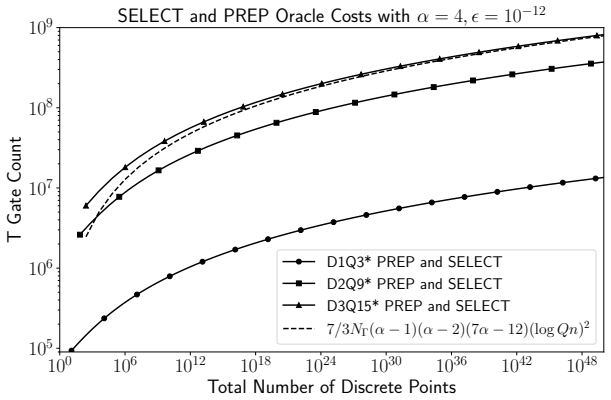
- Combined with preparation and selection oracles the T-gate cost scales as O(alpha cubed Q squared times the square of the log of the number of grid points).
- When paired with the variational quantum linear solver the approach requires a number of circuits per iteration equal to the square of the term count times a logarithmic factor involving time steps and the Carleman order.
Where Pith is reading between the lines
- The same decomposition approach could be applied to other nonlinear partial differential equations that admit Carleman linearization, such as reaction-diffusion or Navier-Stokes systems.
- If the term count truly stays independent of grid size, quantum resource estimates for fluid simulations would improve markedly when moving to finer meshes.
- Small-scale numerical tests of the decomposition on toy matrices drawn from the lattice Boltzmann system could directly verify the claimed independence from discretization.
Load-bearing premise
An arbitrary square matrix can be decomposed into a linear combination of non-unitaries with a term count that does not grow with the number of spatial grid points or time steps.
What would settle it
Apply the decomposition to the system matrix for two different spatial grid resolutions and check whether the number of terms in the resulting linear combination of unitaries remains unchanged.
Figures




read the original abstract
Nonlinear ordinary and partial differential equations are ubiquitous in science and engineering, yet finding their solutions is often computationally intractable for classical hardware. To determine if quantum computers can offer a practical advantage, one critical challenge that must be solved is determining how to efficiently load exponentially sized matrices onto quantum hardware. In this article, we introduce an alternative linear combination of unitaries (LCU) strategy which relies on an intermediate linear combination of non-unitaries (LCNU) and a systematic embedding procedure. One advantage of this LCU strategy is that it maintains the exact number of terms as in the LCNU. Therefore, this approach offers a data loading framework for matrices that lack an efficient decomposition using the standard LCU alone. Using this approach, we construct a generalized LCNU framework for any Carleman linearized autonomous dynamical system having a polynomial nonlinearity. To demonstrate the effectiveness of our approach, we construct an LCNU for the 3D Carleman linearized lattice Boltzmann equation (LBE). Here, we find that the number of terms in the decomposition scales like $N_s\sim\mathcal{O}(\alpha^2Q^2)$, where $\alpha$ is the Carleman truncation order and $Q$ is the number of discrete velocities. Importantly, $N_s$ is independent of the number of spatial and temporal discretization points. We then perform a resource estimation of our LCNU's T gate cost when combined with the (1) PREP and SELECT block encoding oracles, and (2) variational quantum linear solver. In the former, the T cost scales like $\mathcal{O}(\alpha^3Q^2(\log_2n)^2)$, where $n$ is the total number of spatial grid points. The latter requires exactly $N_s^2(\log_2 (2n_tn^\alpha)+1)$ circuits per iteration for $n_t$ time steps, with a worst case T gate cost of $\mathcal{O}(\alpha (\log_2Qn)^2)$ among them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a strategy to decompose an arbitrary square matrix into a linear combination of non-unitaries (LCNU), each embeddable in a unitary, yielding an LCU with equal term count. This is generalized to any Carleman-linearized autonomous dynamical system with polynomial nonlinearity and applied to construct an LCU for the 3D Carleman-linearized lattice Boltzmann equation (LBE), with term count Ns scaling as O(α² Q²) independent of spatial grid points n and time steps nt. T-gate cost estimates are given for PREP/SELECT block encodings and the variational quantum linear solver.
Significance. If the central decomposition holds with the claimed scaling, the work would provide a route to quantum simulation of fluid dynamics via LBE that avoids exponential growth in operator terms with discretization size, a potentially important step toward practical quantum advantage in computational fluid dynamics. The explicit T-cost scaling for both fault-tolerant and variational settings adds concrete utility if the underlying LCNU construction is rigorous.
major comments (2)
- [Abstract] Abstract (paragraph beginning 'Herein, we introduce a strategy...'): The general LCNU decomposition for an arbitrary square matrix is presented as achieving term count equal to the final LCU without additional dimension-dependent factors. For the Carleman-linearized LBE the operator dimension scales as n^α; a generic decomposition into non-unitaries would normally produce term count growing with this dimension unless the construction explicitly cancels the n dependence via the tensor-product structure of the LBE streaming and collision operators. The manuscript must supply the explicit construction and proof that this cancellation occurs for arbitrary matrices before the independence claim can be accepted.
- [LBE application section] Section on application to 3D LBE (following the generalized framework): The reported Ns ∼ O(α² Q²) independent of n and nt is load-bearing for the headline result. Without a concrete decomposition of the Carleman-expanded LBE operator that demonstrates how the general LCNU avoids introducing factors proportional to n^α or nt, the scaling cannot be verified and may rest on an unstated structural cancellation specific to LBE rather than the claimed generality.
minor comments (2)
- [T-gate cost estimates] The T-gate cost expressions (O(α³ Q² (log₂ n)²) for PREP/SELECT and O(α (log₂ Q n)²) worst-case for VQLS) would benefit from an explicit breakdown of the PREP and SELECT oracle implementations and how the LCNU terms enter the circuit depth.
- Notation for the Carleman truncation order α and discrete velocity count Q should be defined at first use with a brief reminder of their relation to the underlying LBE discretization.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each of the major comments below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: The general LCNU decomposition for an arbitrary square matrix is presented as achieving term count equal to the final LCU without additional dimension-dependent factors. For the Carleman-linearized LBE the operator dimension scales as n^α; a generic decomposition into non-unitaries would normally produce term count growing with this dimension unless the construction explicitly cancels the n dependence via the tensor-product structure of the LBE streaming and collision operators. The manuscript must supply the explicit construction and proof that this cancellation occurs for arbitrary matrices before the independence claim can be accepted.
Authors: We agree that an explicit construction is essential to substantiate the scaling claim. Our LCNU approach begins with a decomposition of the original system operators, which for the LBE are highly structured (local collision and streaming terms with tensor-product form across grid points). The Carleman linearization preserves this structure in a block-wise manner, allowing the LCNU to be applied to the base operators and extended via Kronecker products without introducing additional factors of n or nt. The generalized framework in Section 2 details this for any polynomial system, and Section 3 applies it to LBE showing the O(α² Q²) scaling. To address the concern, we will add an appendix with the full proof of the term count independence, including the explicit LCNU terms for the LBE operator. revision: yes
-
Referee: The reported Ns ∼ O(α² Q²) independent of n and nt is load-bearing for the headline result. Without a concrete decomposition of the Carleman-expanded LBE operator that demonstrates how the general LCNU avoids introducing factors proportional to n^α or nt, the scaling cannot be verified and may rest on an unstated structural cancellation specific to LBE rather than the claimed generality.
Authors: The concrete decomposition is provided in the LBE application section, where we expand the Carleman-linearized operator and identify the distinct non-unitary components arising from the velocity discretizations and polynomial terms up to order α. Because the spatial grid enters only through identical local operators tensored across sites, the number of unique terms does not grow with n. Similarly, the time discretization does not affect the operator itself in the linear system formulation. We acknowledge that the presentation could be more explicit, and we will revise the section to include a table or diagram listing the LCNU terms and their embeddings, thereby verifying the claimed scaling directly from the construction rather than relying on the general framework alone. revision: yes
Circularity Check
No circularity: derivation presents explicit algorithmic construction independent of target scaling.
full rationale
The paper introduces a decomposition strategy for arbitrary square matrices into LCNU (with equal-term LCU embedding) as a new contribution, then applies the resulting generalized LCU framework to Carleman-linearized polynomial systems and specifically to the 3D LBE operator. The claimed Ns ~ O(α² Q²) scaling independent of n and nt is stated as following directly from the operator structure under this framework. No equation or section reduces a prediction to a fitted parameter, self-citation chain, or definitional renaming; the central result is an explicit construction rather than a re-expression of inputs. This is the normal case of a self-contained algorithmic paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Carleman linearization of a polynomial nonlinearity yields a finite-dimensional linear system after truncation at order α
- ad hoc to paper Any square matrix admits a decomposition into a linear combination of non-unitaries that can each be embedded in a unitary with equal term count
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a generalized LCU framework for any Carleman linearized autonomous dynamical system with a polynomial nonlinearity... Ns ∼ O(α² Q²) ... completely independent of both the number of temporal and spatial discretization points.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Decomposition of the F1 Matrix ... Decomposition of the F2 and F3 Matrices ... Explicit Circuit Constructions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.