Recognition: unknown
Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representation Distillation
Pith reviewed 2026-05-09 19:13 UTC · model grok-4.3
The pith
One-step sampling for text-to-audio generation matches multi-step quality while running up to 8.5 times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
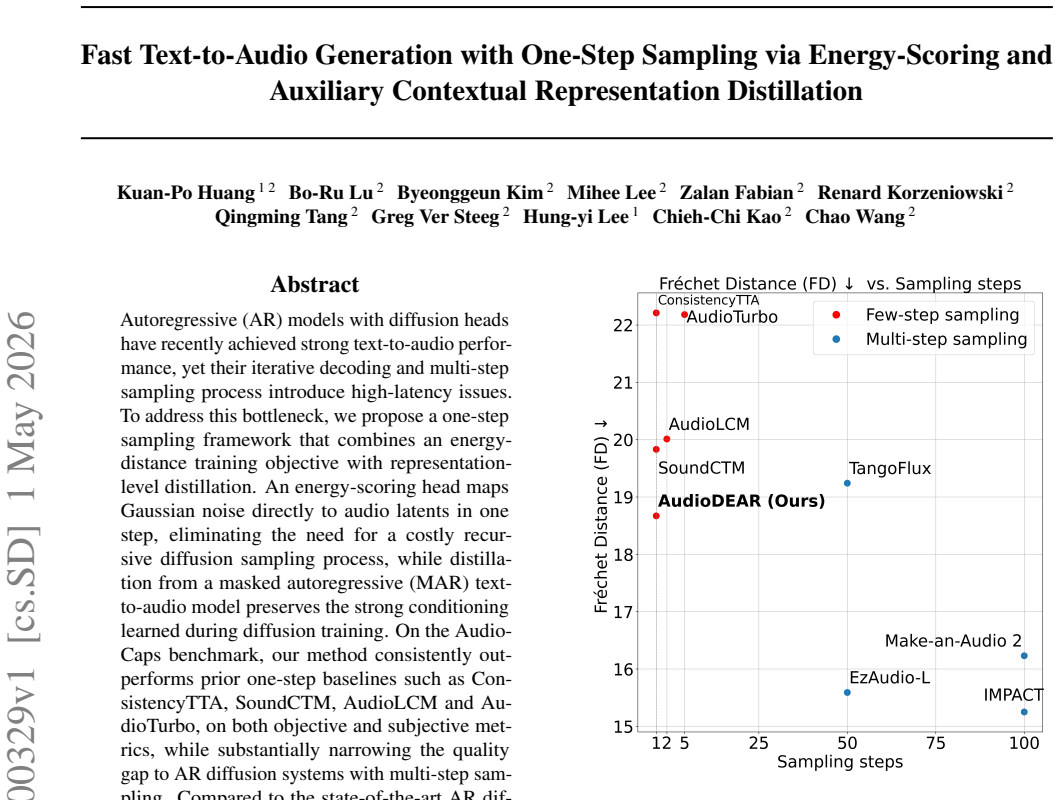
An energy-scoring head maps Gaussian noise directly to audio latents in one step when trained under an energy-distance objective, while auxiliary representation-level distillation from a masked autoregressive text-to-audio model preserves the conditioning that diffusion training normally acquires over many steps, yielding up to 8.5 times faster batch inference than the strongest multi-step baseline with competitive audio quality on AudioCaps.
What carries the argument
Energy-scoring head trained with energy-distance loss, combined with representation-level distillation from a masked autoregressive model.
If this is right
- Outperforms prior one-step baselines (ConsistencyTTA, SoundCTM, AudioLCM, AudioTurbo) on both objective and subjective metrics.
- Substantially narrows the quality gap to multi-step AR diffusion systems.
- Delivers up to 8.5x faster batch inference than the state-of-the-art IMPACT system with highly competitive audio quality.
- Combining energy-distance training with representation-level distillation forms an effective recipe for fast, high-quality text-to-audio synthesis.
Where Pith is reading between the lines
- The method could support real-time applications that require audio to be generated from text descriptions on the fly.
- The distillation step may transfer to other diffusion-based audio tasks such as music or sound-effect generation to reduce sampling steps.
- Scaling the one-step approach to longer audio clips or more complex prompts could be tested by measuring whether quality remains stable without adding extra sampling iterations.
Load-bearing premise
An energy-scoring head can map Gaussian noise to high-quality audio latents in one forward pass while distillation from the masked autoregressive model fully transfers the conditioning learned during diffusion training.
What would settle it
On the AudioCaps test set, objective metrics such as Fréchet Audio Distance for the one-step model fall noticeably short of those reported for the IMPACT multi-step system, or measured wall-clock batch inference speed shows no substantial gain.
Figures






read the original abstract
Autoregressive (AR) models with diffusion heads have recently achieved strong text-to-audio performance, yet their iterative decoding and multi-step sampling process introduce high-latency issues. To address this bottleneck, we propose a one-step sampling framework that combines an energy-distance training objective with representation-level distillation. An energy-scoring head maps Gaussian noise directly to audio latents in one step, eliminating the need for a costly recursive diffusion sampling process, while distillation from a masked autoregressive (MAR) text-to-audio model preserves the strong conditioning learned during diffusion training. On the AudioCaps benchmark, our method consistently outperforms prior one-step baselines such as ConsistencyTTA, SoundCTM, AudioLCM and AudioTurbo, on both objective and subjective metrics, while substantially narrowing the quality gap to AR diffusion systems with multi-step sampling. Compared to the state-of-the-art AR diffusion system, IMPACT, our approach achieves up to $8.5$x faster batch inference with highly competitive audio quality. These results demonstrate that combining energy-distance training with representation-level distillation provides an effective recipe for fast, high-quality text-to-audio synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a one-step sampling framework for text-to-audio generation combining an energy-distance training objective with representation-level distillation from a masked autoregressive (MAR) model. An energy-scoring head maps Gaussian noise directly to audio latents in one step, while the distillation preserves conditioning learned during diffusion training. On the AudioCaps benchmark, the method is claimed to outperform one-step baselines (ConsistencyTTA, SoundCTM, AudioLCM, AudioTurbo) on objective and subjective metrics, narrow the gap to multi-step AR diffusion systems, and achieve up to 8.5x faster batch inference than the state-of-the-art IMPACT system with competitive quality.
Significance. If the empirical results hold with proper validation, the work offers a practical recipe for reducing sampling latency in text-to-audio models without major quality degradation. The explicit combination of energy-distance training and auxiliary distillation from an MAR model could inform efficient inference techniques in related generative audio and speech domains.
major comments (1)
- Abstract: the central performance claims (outperformance on AudioCaps, 8.5x speedup vs. IMPACT) rest on benchmark comparisons, yet the provided text supplies no metrics, error bars, ablation results, training details, or experimental setup; this prevents verification of whether the energy-scoring head and distillation components are load-bearing for the reported gains.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. Below we respond point-by-point to the major comment.
read point-by-point responses
-
Referee: Abstract: the central performance claims (outperformance on AudioCaps, 8.5x speedup vs. IMPACT) rest on benchmark comparisons, yet the provided text supplies no metrics, error bars, ablation results, training details, or experimental setup; this prevents verification of whether the energy-scoring head and distillation components are load-bearing for the reported gains.
Authors: We agree that the abstract is concise and omits specific numerical values, error bars, and experimental details, which is standard practice to keep abstracts brief. The full manuscript supplies all of this information: Section 4 details the experimental setup (datasets, architectures, training procedures, and inference settings); Section 5 reports objective and subjective metrics on AudioCaps with direct comparisons to ConsistencyTTA, SoundCTM, AudioLCM, AudioTurbo, and IMPACT, including the claimed speedups; Section 6 and the appendix contain ablation studies and training details. These ablations isolate the contributions of the energy-scoring head and the auxiliary contextual representation distillation, showing both are necessary for the reported gains over one-step baselines and the competitive quality versus multi-step AR diffusion systems. Error bars are included for key metrics. This structure enables verification that the components are load-bearing. revision: no
Circularity Check
No significant circularity; claims rest on external empirical benchmarks
full rationale
The provided abstract and description contain no equations, derivations, parameter-fitting steps, or self-citations that could reduce any claimed result to its inputs by construction. The method is described at a high level as combining an energy-distance objective with representation distillation from an external MAR model, with performance asserted via direct comparisons to named external baselines (ConsistencyTTA, SoundCTM, AudioLCM, AudioTurbo, IMPACT). No internal prediction is redefined as a fit, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via citation. The derivation chain is therefore self-contained against external benchmarks, consistent with the reader's assessment of score 2.0 and the absence of any load-bearing internal reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, Y ., Dang, T., Tran, D., Koishida, K., and Sojoudi, S. Consistencytta: Accelerating diffusion-based text- to-audio generation with consistency distillation.arXiv preprint arXiv:2309.10740,
-
[2]
Bao, F., Li, C., Zhu, J., and Zhang, B. Analytic-dpm: an ana- lytic estimate of the optimal reverse variance in diffusion probabilistic models.arXiv preprint arXiv:2201.06503,
-
[3]
The Cramer Distance as a Solution to Biased Wasserstein Gradients
Bellemare, M. G., Danihelka, I., Dabney, W., Mohamed, S., Lakshminarayanan, B., Hoyer, S., and Munos, R. The cramer distance as a solution to biased wasserstein gradi- ents.arXiv preprint arXiv:1705.10743,
-
[4]
Soundstorm: Efficient parallel audio generation,
Borsos, Z., Sharifi, M., Vincent, D., Kharitonov, E., Zeghi- dour, N., and Tagliasacchi, M. Soundstorm: Efficient par- allel audio generation.arXiv preprint arXiv:2305.09636,
-
[5]
Chang, H., Zhang, H., Jiang, L., Liu, C., and Freeman, W. T. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11315–11325, 2022a. Chang, H.-J., Yang, S.-w., and Lee, H.-y. Distilhubert: Speech representation learning by layer-wise distillation of hidden-unit bert. InICA...
-
[6]
FMA: A Dataset For Music Analysis
Defferrard, M., Benzi, K., Vandergheynst, P., and Bresson, X. Fma: A dataset for music analysis.arXiv preprint arXiv:1612.01840,
-
[7]
Deshmukh, S., Elizalde, B., and Wang, H. Audio re- trieval with wavtext5k and clap training.arXiv preprint arXiv:2209.14275,
-
[8]
Clotho: An audio captioning dataset
Drossos, K., Lipping, S., and Virtanen, T. Clotho: An audio captioning dataset. InICASSP 2020-2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 736–740. IEEE,
2020
-
[9]
Gao, Z. and Shou, M. Z. D-ar: Diffusion via autoregressive models.arXiv preprint arXiv:2505.23660,
-
[10]
Mean Flows for One-step Generative Modeling
Geng, Z., Deng, M., Bai, X., Kolter, J. Z., and He, K. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
work page internal anchor Pith review arXiv
-
[11]
Hai, J., Xu, Y ., Zhang, H., Li, C., Wang, H., Elhilali, M., and Yu, D. Ezaudio: Enhancing text-to-audio genera- tion with efficient diffusion transformer.arXiv preprint arXiv:2409.10819,
-
[12]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review arXiv
-
[14]
Make-an-audio 2: Temporal-enhanced text-to-audio generation.arXiv preprint arXiv:2305.18474, 2023a
Huang, J., Ren, Y ., Huang, R., Yang, D., Ye, Z., Zhang, C., Liu, J., Yin, X., Ma, Z., and Zhao, Z. Make-an-audio 2: Temporal-enhanced text-to-audio generation.arXiv preprint arXiv:2305.18474, 2023a. 9 Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representation Distillation Huang, K.-P., Feng, T.-H., Fu,...
-
[15]
Hung, C.-Y ., Majumder, N., Kong, Z., Mehrish, A., Bagherzadeh, A. A., Li, C., Valle, R., Catanzaro, B., and Poria, S. Tangoflux: Super fast and faithful text to au- dio generation with flow matching and clap-ranked pref- erence optimization.arXiv preprint arXiv:2412.21037,
-
[16]
Fr\’echet audio distance: A metric for evaluating music enhancement algo- rithms,
Kilgour, K., Zuluaga, M., Roblek, D., and Sharifi, M. Fr \’echet audio distance: A metric for evaluat- ing music enhancement algorithms.arXiv preprint arXiv:1812.08466,
-
[17]
D., Kim, B., Lee, H., and Kim, G
Kim, C. D., Kim, B., Lee, H., and Kim, G. Audiocaps: Gen- erating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, Volume 1 (Long and Short Papers), pp. 119–132,
2019
- [18]
-
[19]
Pseudo numerical methods for diffusion models on manifolds
Liu, H., Huang, R., Liu, Y ., Cao, H., Wang, J., Cheng, X., Zheng, S., and Zhao, Z. Audiolcm: Efficient and high- quality text-to-audio generation with minimal inference steps. InProceedings of the 32nd ACM International Conference on Multimedia, pp. 7008–7017, 2024a. Liu, H., Yuan, Y ., Liu, X., Mei, X., Kong, Q., Tian, Q., Wang, Y ., Wang, W., Wang, Y ....
-
[20]
Ma, Z., Feng, Y ., Shao, C., Meng, F., Zhou, J., and Zhang, M. Efficient speech language modeling via en- ergy distance in continuous latent space.arXiv preprint arXiv:2505.13181,
-
[21]
Pacchiardi, L. and Dutta, R. Likelihood-free inference with generative neural networks via scoring rule minimization. arXiv preprint arXiv:2205.15784,
-
[22]
Passoni, R., Ronchini, F., Comanducci, L., Serizel, R., and Antonacci, F. Diffused responsibility: Analyzing the energy consumption of generative text-to-audio diffusion models.arXiv preprint arXiv:2505.07615,
-
[23]
FitNets: Hints for Thin Deep Nets
URLhttps://arxiv.org/abs/1412.6550. Saito, K., Kim, D., Shibuya, T., Lai, C.-H., Zhong, Z., Takida, Y ., and Mitsufuji, Y . Soundctm: Uniting score- based and consistency models for text-to-sound gener- ation. InAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation,
work page internal anchor Pith review arXiv 2024
-
[24]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review arXiv
-
[25]
Song, Y ., Dhariwal, P., Chen, M., and Sutskever, I. Consis- tency models.arXiv preprint arXiv:2303.01469,
work page internal anchor Pith review arXiv
-
[26]
URL https://www.aclweb.org/anthology/D13-1170
Sun, L., Xu, X., Wu, M., and Xie, W. Auto-acd: A large- scale dataset for audio-language representation learning. InProceedings of the 32nd ACM International Confer- ence on Multimedia, pp. 5025–5034, 2024a. Sun, S., Cheng, Y ., Gan, Z., and Liu, J. Patient knowledge distillation for bert model compression.arXiv preprint arXiv:1908.09355,
-
[27]
Mul- timodal latent language modeling with next-token diffusion
Sun, Y ., Bao, H., Wang, W., Peng, Z., Dong, L., Huang, S., Wang, J., and Wei, F. Multimodal latent language modeling with next-token diffusion.arXiv preprint arXiv:2412.08635, 2024b. Sz´ekely, G. J. E-statistics: The energy of statistical sam- ples.Bowling Green State University, Department of Mathematics and Statistics Technical Report, 3(05):1–18,
-
[28]
Contrastive representation distilla- tion,
Tian, Y ., Krishnan, D., and Isola, P. Contrastive representa- tion distillation.arXiv preprint arXiv:1910.10699,
-
[29]
Audiobox: Unified audio generation with natural language prompts.arXiv preprint arXiv:2312.15821,
Vyas, A., Shi, B., Le, M., Tjandra, A., Wu, Y .-C., Guo, B., Zhang, J., Zhang, X., Adkins, R., Ngan, W., et al. Au- diobox: Unified audio generation with natural language prompts.arXiv preprint arXiv:2312.15821,
-
[30]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Wu, Y ., Chen, K., Zhang, T., Hui, Y ., Berg-Kirkpatrick, T., and Dubnov, S. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[31]
Comparing discrete and continuous space llms for speech recognition
Xu, Y ., Zhang, S.-X., Yu, J., Wu, Z., and Yu, D. Comparing discrete and continuous space llms for speech recognition. InProc. Interspeech 2024, pp. 2509–2513,
2024
-
[32]
Continuous speech tokens makes llms robust multi-modality learners.arXiv preprint arXiv:2412.04917,
11 Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representation Distillation Yuan, Z., Liu, Y ., Liu, S., and Zhao, S. Continuous speech tokens makes llms robust multi-modality learners.arXiv preprint arXiv:2412.04917,
-
[33]
Zeng, A., Du, Z., Liu, M., Wang, K., Jiang, S., Zhao, L., Dong, Y ., and Tang, J. Glm-4-voice: Towards intelli- gent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612,
-
[34]
and Chen, Y
Zhang, Q. and Chen, Y . Fast sampling of diffusion models with exponential integrator. InNeurIPS 2022 Workshop on Score-Based Methods,
2022
-
[35]
Generative pre-trained autoregressive diffusion transformer.arXiv preprint arXiv:2505.07344,
Zhang, Y ., Jiang, J., Ma, G., Lu, Z., Huang, H., Yuan, J., and Duan, N. Generative pre-trained autoregressive diffusion transformer.arXiv preprint arXiv:2505.07344,
-
[36]
Audioturbo: Fast text-to- audio generation with rectified diffusion.arXiv preprint arXiv:2505.22106,
Zhao, J., Zhao, J., Liu, H., Chen, Y ., Han, L., Liu, X., Plumbley, M., and Wang, W. Audioturbo: Fast text-to- audio generation with rectified diffusion.arXiv preprint arXiv:2505.22106,
-
[37]
Energy-distance The following content lists out the definitions and theorems required to prove Corollary 1, stated as follows
12 Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representation Distillation A. Energy-distance The following content lists out the definitions and theorems required to prove Corollary 1, stated as follows. Corollary A.1.LetXandYbe independent random vectors inR d with distributionsPandQ, respectively. Th...
2005
-
[38]
The equality holds if and only ifP=Q
Theorem A.5.For any two independent random variablesX∼PandY∼Q, we have 2E[g(X, Y)]−E[g(X, X ′)]−E[g(Y, Y ′)]≥0, where g is the Euclidean distance, X ′ and Y ′ are independent copies of X and Y , respectively. The equality holds if and only ifP=Q. 13 Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representa...
2005
-
[39]
Text Embeddings Table 6 examines how different text embedding choices affect the performance of our one-step energy-scoring model with representation distillation
C. Text Embeddings Table 6 examines how different text embedding choices affect the performance of our one-step energy-scoring model with representation distillation. The best overall results are achieved when using a combination of CLAP and Flan-T5 embeddings. The model’s performance remains strong even when the CLAP embeddings are removed, with only a n...
2022
-
[40]
stdev” stands for standard deviation. “stderr
Table 8.Ablation study on IMPACT with CFG applied at different levels of output. Setting CFG FD↓FAD↓KL↓IS↑CLAP↑ (a) Noise-prediction-level 5.0 15.25 1.26 1.06 10.57 0.372 (b) No CFG 1.0 22.42 2.96 1.42 6.84 0.269 (c) Representation-level 1.1 21.00 2.55 1.34 7.07 0.282 (d) Representation-level 1.5 17.12 1.93 1.20 8.37 0.313 (e) Representation-level 2.0 16....
2020
-
[41]
9https://freesound.org/ 10https://zenodo.org/records/4060432 11https://keithito.com/LJ-Speech-Dataset/ 22 Fast Text-to-Audio Generation with One-Step Sampling via Energy-Scoring and Auxiliary Contextual Representation Distillation Figure 6.Illustration of the training framework with masked generative modeling by energy-scoring. J. Overall Structure As sho...
-
[42]
This 1024-dimensional vector is duplicated 78 times to form the conditioning sequence
In this case, a single 512-dimensional CLAP audio embedding is extracted for each audio clip and expanded to 1024 dimensions by repeating it once along the sequence length dimension. This 1024-dimensional vector is duplicated 78 times to form the conditioning sequence. J.2. Training - Masked Generative Modeling As shown in Figure 6, during masked generati...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.