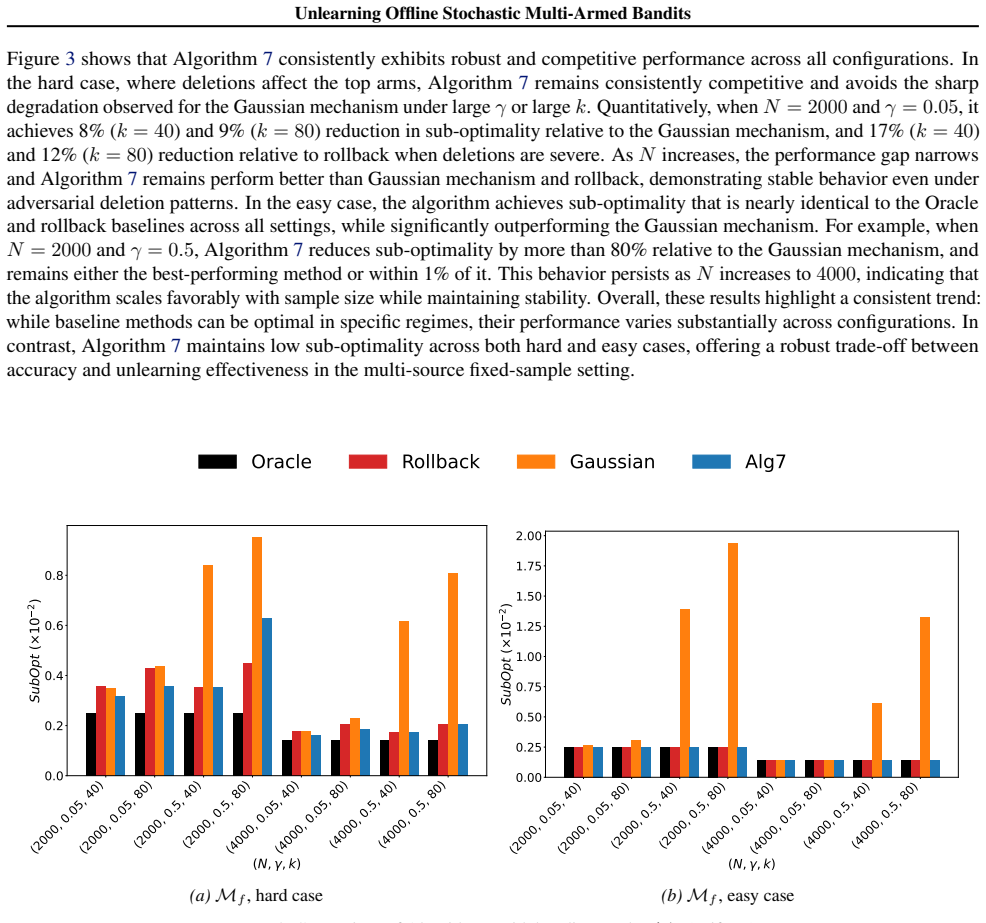
Unlearning Offline Stochastic Multi-Armed Bandits
Pith reviewed 2026-05-09 20:20 UTC · model grok-4.3
The pith
Unlearning in offline stochastic multi-armed bandits can be achieved with performance guarantees using adaptive combinations of Gaussian noise and rollback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We initiate the first study of unlearning for offline stochastic multi-armed bandits by formalizing the privacy constraint and measuring utility via post-unlearning decision quality. We design adaptive algorithms that switch between the Gaussian mechanism and rollback for single- and multi-source settings under fixed-sample and distribution models, supported by performance guarantees and lower bounds under both data models.
What carries the argument
The adaptive switching algorithm between the Gaussian mechanism and rollback procedure, which balances privacy requirements against post-unlearning decision quality depending on the data regime.
If this is right
- Unlearning incurs only bounded additional cost to decision quality in both single- and multi-source scenarios.
- The same algorithmic template yields guarantees under both fixed-sample and distributional data models.
- Lower bounds match the upper bounds, establishing tightness for the two dataset models.
- The mixing procedure explains when to prefer noise addition over rollback.
Where Pith is reading between the lines
- The framework could extend to online bandit problems where new data arrives after initial training.
- Similar adaptive mechanisms might address deletion requests in related sequential problems such as contextual bandits.
- In practice, these methods could reduce the need for full retraining when handling user data erasure requests in recommendation systems.
Load-bearing premise
That utility for unlearning is fully captured by measuring only the quality of decisions made after data deletion.
What would settle it
An experiment or instance in the distribution model where an algorithm satisfying the privacy constraint produces post-unlearning regret that exceeds the stated upper bounds.
Figures


read the original abstract
Machine unlearning aims to unlearn data points from a learned model, offering a principled way to process data-deletion requests and mitigate privacy risks without full retraining. Prior work has mainly studied unsupervised / supervised machine unlearning, leaving unlearning for sequential decision-making systems far less understood. We initiate the first study of a foundational sequential decision-making problem: offline stochastic multi-armed bandits (MAB). We formalize the privacy constraint for offline MAB and measure utility by the post-unlearning decision quality. We conduct a systematic study of both single- and multi-source unlearning scenarios under two data-generation models, the fixed-sample model and the distribution model. For these settings, our algorithmic design is built on two canonical base algorithms: Gaussian mechanism and rollback, and we propose adaptive algorithms that switch between them according to the data regime and privacy constraint. We further introduce a mixing procedure that elucidates the rationale behind these baselines. We provide performance guarantees across the above settings and establish lower bounds under both dataset models. Experiments validate the predicted tradeoffs and demonstrate the effectiveness of the proposed methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper initiates the first study of machine unlearning for offline stochastic multi-armed bandits. It formalizes a privacy constraint for this setting and defines utility solely via post-unlearning decision quality. The work examines single- and multi-source unlearning under fixed-sample and distribution data models, proposes adaptive algorithms that switch between the Gaussian mechanism and rollback, introduces a mixing procedure to explain the baselines, derives performance guarantees and lower bounds for the settings, and validates the tradeoffs via experiments.
Significance. If the formalization and guarantees hold under the stated definitions, the work is significant for opening a new direction in machine unlearning applied to sequential decision-making. It provides both algorithmic constructions with explicit performance bounds and matching lower bounds under two dataset models, plus a mixing procedure that clarifies design choices; these elements together establish a reproducible foundation for privacy-aware unlearning in bandits, which has direct relevance to recommendation and advertising systems that must honor deletion requests.
major comments (2)
- [Abstract and §3] Abstract and §3 (formalization): the decision to measure utility exclusively by post-unlearning decision quality (final arm selection or policy quality) is load-bearing for all claimed guarantees and lower bounds, yet the manuscript provides no argument or robustness check showing that this definition remains sufficient when real deletion requests impose additional constraints such as trajectory-wide indistinguishability or bounds on intermediate regret.
- [§5] §5 (adaptive algorithms and mixing procedure): the adaptive switching rule between Gaussian noise and rollback, together with the mixing procedure, is asserted to satisfy the privacy definition while preserving the stated utility bounds, but no explicit derivation is given that the composition does not introduce unaccounted privacy leakage or extra utility loss; this directly affects whether the performance guarantees transfer to the multi-source and distribution-model cases.
minor comments (2)
- [Experiments] The experimental section should report the number of independent runs, confidence intervals, and the precise data-exclusion rules used when measuring post-unlearning decision quality, so that the claimed validation of tradeoffs can be reproduced.
- [Notation] Notation for the two data-generation models (fixed-sample vs. distribution) and the precise privacy parameter (ε, δ) should be introduced with a single table or definition block before the algorithmic sections to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the positive assessment of the work's significance in opening a new direction for unlearning in sequential decision-making. We address the two major comments below, clarifying our design choices while agreeing to strengthen the manuscript with additional discussion and derivations where needed.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (formalization): the decision to measure utility exclusively by post-unlearning decision quality (final arm selection or policy quality) is load-bearing for all claimed guarantees and lower bounds, yet the manuscript provides no argument or robustness check showing that this definition remains sufficient when real deletion requests impose additional constraints such as trajectory-wide indistinguishability or bounds on intermediate regret.
Authors: Our utility definition centers on post-unlearning decision quality because the offline stochastic MAB setting is fundamentally about identifying the best arm from a fixed dataset, with no ongoing online interactions or regret accumulation during deployment. This choice enables precise performance guarantees and matching lower bounds under the formalized privacy constraint. Real-world deletion requests may indeed involve stronger requirements such as trajectory-wide indistinguishability or intermediate regret bounds; however, these represent distinct privacy models outside the scope of this foundational study. We will add a dedicated discussion paragraph in the revised §3 (and abstract if space permits) explicitly acknowledging this limitation and outlining it as an avenue for future work. revision: yes
-
Referee: [§5] §5 (adaptive algorithms and mixing procedure): the adaptive switching rule between Gaussian noise and rollback, together with the mixing procedure, is asserted to satisfy the privacy definition while preserving the stated utility bounds, but no explicit derivation is given that the composition does not introduce unaccounted privacy leakage or extra utility loss; this directly affects whether the performance guarantees transfer to the multi-source and distribution-model cases.
Authors: The adaptive switching rule selects between mechanisms based on data statistics that are already part of the observable input, and the mixing procedure unifies the baselines to clarify when each is preferable. Privacy holds by construction for each base mechanism, with utility bounds derived separately before combination. To make this fully explicit, we will expand the analysis in the revised §5 and appendix with a dedicated composition argument (including a short theorem) confirming no additional privacy leakage occurs and that the utility bounds carry over unchanged to the multi-source and distribution-model settings. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper initiates a new formalization of privacy constraints and utility (post-unlearning decision quality) for offline stochastic MAB, then builds adaptive algorithms from standard base mechanisms (Gaussian and rollback) plus a mixing procedure. It derives performance guarantees and lower bounds under fixed-sample and distribution models. No equations or steps are shown that reduce claimed results to self-defined quantities, fitted parameters renamed as predictions, or load-bearing self-citation chains. The work is self-contained with independent content; any self-citations are not required for the core claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Privacy constraint for offline MAB can be formalized such that post-unlearning decision quality is a meaningful utility measure.
Reference graph
Works this paper leans on
-
[1]
IEEE Symposium on Security and Privacy (S&P 2021) , pages=
Machine unlearning , author=. IEEE Symposium on Security and Privacy (S&P 2021) , pages=
work page 2021
-
[2]
arXiv preprint arXiv:1905.12298 , year=
Privacy in multi-armed bandits: Fundamental definitions and lower bounds , author=. arXiv preprint arXiv:1905.12298 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Private stochastic convex optimization with optimal rates , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
ACM International Conference on Web Search and Data Mining (WSDM 2019) , pages=
Top-k off-policy correction for a REINFORCE recommender system , author=. ACM International Conference on Web Search and Data Mining (WSDM 2019) , pages=
work page 2019
-
[5]
USENIX Security Symposium (USENIX 2019) , pages=
The secret sharer: Evaluating and testing unintended memorization in neural networks , author=. USENIX Security Symposium (USENIX 2019) , pages=
work page 2019
-
[6]
Journal of Machine Learning Research , volume=
Differentially private empirical risk minimization , author=. Journal of Machine Learning Research , volume=
-
[7]
ACM Transactions on Information and System Security , volume=
Private and continual release of statistics , author=. ACM Transactions on Information and System Security , volume=
-
[8]
IEEE Symposium on Security and Privacy (S&P 2015) , pages=
Towards making systems forget with machine unlearning , author=. IEEE Symposium on Security and Privacy (S&P 2015) , pages=
work page 2015
-
[9]
The International Conference on Learning Representations (ICLR 2023) , year =
Distributed differential privacy in multi-armed bandits , author=. The International Conference on Learning Representations (ICLR 2023) , year =
work page 2023
-
[10]
International Conference on Machine Learning (ICML 2020) , pages=
(Locally) differentially private combinatorial semi-bandits , author=. International Conference on Machine Learning (ICML 2020) , pages=
work page 2020
-
[11]
Foundations and Trends in Theoretical Computer Science , volume=
The algorithmic foundations of differential privacy , author=. Foundations and Trends in Theoretical Computer Science , volume=
-
[12]
International Conference on Machine Learning (ICML 2019) , pages=
Off-policy deep reinforcement learning without exploration , author=. International Conference on Machine Learning (ICML 2019) , pages=
work page 2019
-
[13]
Advances in Neural Information Processing Systems , volume=
Adaptive machine unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
International Conference on Machine Learning (ICML 2021) , pages=
Emaq: Expected-max q-learning operator for simple yet effective offline and online rl , author=. International Conference on Machine Learning (ICML 2021) , pages=
work page 2021
-
[15]
International Conference on Machine Learning (ICML 2020) , pages=
Certified data removal from machine learning models , author=. International Conference on Machine Learning (ICML 2020) , pages=
work page 2020
-
[16]
Advances in Neural Information Processing Systems , volume=
Making ai forget you: Data deletion in machine learning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2505.08557 , year=
Online Learning and Unlearning , author=. arXiv preprint arXiv:2505.08557 , year=
-
[18]
International Conference on Artificial Intelligence and Statistics (AISTATS 2021) , pages=
Approximate data deletion from machine learning models , author=. International Conference on Artificial Intelligence and Statistics (AISTATS 2021) , pages=
work page 2021
-
[19]
Advances in Neural Information Processing Systems , volume=
Morel: Model-based offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
International Conference on Machine Learning (ICML 2021) , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International Conference on Machine Learning (ICML 2021) , pages=
work page 2021
-
[21]
Advances in Neural Information Processing Systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
International Conference on Machine Learning (ICML 2025) , volume=
Offline learning for combinatorial multi-armed bandits , author=. International Conference on Machine Learning (ICML 2025) , volume=
work page 2025
-
[23]
Advances in Neural Information Processing Systems , volume=
Certified minimax unlearning with generalization rates and deletion capacity , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Pessimism for offline linear contextual bandits using _p confidence sets , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
International Conference on Machine Learning (ICML 2022) , pages=
Model selection in batch policy optimization , author=. International Conference on Machine Learning (ICML 2022) , pages=
work page 2022
-
[26]
arXiv preprint arXiv:2208.06875 , year=
Forgetting fast in recommender systems , author=. arXiv preprint arXiv:2208.06875 , year=
-
[27]
Deep unlearning via randomized conditionally independent hessians , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022) , pages=
work page 2022
-
[28]
Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI 2015) , pages=
Nearly optimal differentially private stochastic multi-arm bandits , author=. Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI 2015) , pages=
work page 2015
-
[29]
Algorithmic Learning Theory (ALT 2021) , pages=
Descent-to-delete: Gradient-based methods for machine unlearning , author=. Algorithmic Learning Theory (ALT 2021) , pages=
work page 2021
-
[30]
arXiv preprint arXiv:2007.03121 , year=
Multi-armed bandits with local differential privacy , author=. arXiv preprint arXiv:2007.03121 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Bridging offline reinforcement learning and imitation learning: A tale of pessimism , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Remember what you want to forget: Algorithms for machine unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
IEEE Symposium on Security and Privacy (S&P 2017) , pages=
Membership inference attacks against machine learning models , author=. IEEE Symposium on Security and Privacy (S&P 2017) , pages=
work page 2017
-
[34]
Advances in Neural Information Processing Systems , volume=
Algorithms that approximate data removal: New results and limitations , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
ACM Conference on Recommender Systems (RecSys 2023) , pages=
Reward innovation for long-term member satisfaction , author=. ACM Conference on Recommender Systems (RecSys 2023) , pages=
work page 2023
-
[36]
International Conference on Artificial Intelligence and Statistics (AISTATS 2022) , pages=
Optimal rates of (locally) differentially private heavy-tailed multi-armed bandits , author=. International Conference on Artificial Intelligence and Statistics (AISTATS 2022) , pages=
work page 2022
-
[37]
Conference on Learning Theory (COLT 2021) , pages=
Machine unlearning via algorithmic stability , author=. Conference on Learning Theory (COLT 2021) , pages=
work page 2021
-
[38]
A practical guide, 1st ed., Cham: Springer International Publishing , volume=
The eu general data protection regulation (gdpr) , author=. A practical guide, 1st ed., Cham: Springer International Publishing , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Beyond the best: Estimating distribution functionals in infinite-armed bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
International Conference on Machine Learning (ICML 2021) , pages=
On the optimality of batch policy optimization algorithms , author=. International Conference on Machine Learning (ICML 2021) , pages=
work page 2021
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2025) , volume=
Towards robust knowledge unlearning: An adversarial framework for assessing and improving unlearning robustness in large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2025) , volume=
work page 2025
-
[42]
Advances in Neural Information Processing Systems , volume=
Mopo: Model-based offline policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Reinforcement unlearning , author=
-
[44]
Advances in Neural Information Processing Systems , volume=
Locally differentially private (contextual) bandits learning , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in Neural Information Processing Systems , volume=
Locally private and robust multi-armed bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Prompt certified machine unlearning with randomized gradient smoothing and quantization , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.