Recognition: unknown
Model Compression with Exact Budget Constraints via Riemannian Manifolds
Pith reviewed 2026-05-09 19:51 UTC · model grok-4.3
The pith
The budget constraint under softmax relaxation forms a Riemannian manifold with simple geometry allowing exact first-order optimization of model loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the softmax relaxation the level set of logit vectors whose expected cost equals the prescribed budget is a smooth Riemannian manifold whose normal vector equals the cost vector. This structure supplies a closed-form orthogonal projection onto the tangent space, a monotonic retraction obtained by binary search along the cost direction, and vector transport that reduces to an inner product, so that any first-order optimizer can be turned into an exact-budget method by three inexpensive augmentations.
What carries the argument
The Riemannian manifold in logit space defined by the linear budget constraint once probabilities are formed by softmax, together with its closed-form normal, tangent projection, and retraction operator.
If this is right
- Non-decomposable objectives that depend on the joint assignment become directly optimizable by gradient methods.
- The budget is satisfied exactly at every iterate without introducing Lagrange multipliers or penalty coefficients.
- No constraint-specific hyperparameters are required beyond the settings of the base optimizer.
- The same manifold construction works for any linear cost constraint once the expectation is taken under softmax.
Where Pith is reading between the lines
- The same manifold view could be applied to other linear resource constraints that arise in routing, scheduling, or hardware allocation.
- Because retraction cost is independent of dimension, the approach should remain practical when the number of groups N grows to tens of thousands.
- Replacing binary-search retraction with a learned or analytic map might further reduce per-iteration overhead in very large models.
Load-bearing premise
The continuous softmax relaxation must remain sufficiently faithful to the underlying discrete one-hot assignments that optimizing on the manifold produces high-quality discrete solutions after the final projection step.
What would settle it
Solve a small instance whose globally optimal discrete assignment is known by exhaustive enumeration; if the final discrete selection recovered by dynamic programming violates the budget or returns strictly higher loss than the enumerated optimum, the claimed geometric properties do not guarantee optimality.
Figures






read the original abstract
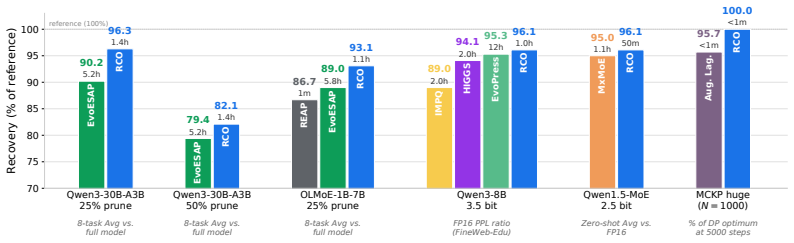
Assigning one of K options to each of N groups under a total cost budget is a recurring problem in efficient AI, including mixed-precision quantization, non-uniform pruning, and expert selection. The objective, typically model loss, depends jointly on all assignments and does not decompose across groups, preventing combinatorial solvers from directly optimizing the true objective and forcing reliance on proxy formulations. Methods such as evolutionary search evaluate the actual loss but lack gradient information, while penalty-based approaches enforce the budget only approximately and often require extensive hyperparameter tuning. We present a new approach by showing that, under softmax relaxation, the budget constraint defines a smooth Riemannian manifold in logit space with unusually simple geometry. The normal vector admits a closed-form expression, shifting logits along the cost vector changes expected cost monotonically, and vector transport reduces to a single inner product. Building on these properties, we propose Riemannian Constrained Optimization (RCO), which augments a standard Adam step with tangent projection, binary-search retraction, and momentum transport. Combined with Gumbel straight-through estimation and budget-constrained dynamic programming for discrete feasibility, RCO enables first-order optimization of the actual loss under exact budget enforcement without introducing constraint-specific hyperparameters. Across both synthetic benchmarks and realistic LLM compression settings, RCO matches or exceeds state-of-the-art methods while often requiring substantially less wall-clock time. Source code is available at https://github.com/IST-DASLab/RCO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under a softmax relaxation of discrete group assignments, the exact total-cost budget constraint defines a smooth embedded hypersurface (Riemannian manifold) in logit space whose Euclidean normal vector has a closed-form expression (per-group p_i ⊙ (c_i − μ_i)), whose level sets are crossed monotonically by shifts along the cost vector (derivative equals sum of per-group cost variances), and on which tangent projection and vector transport reduce to a single inner product. Building on these properties, the authors introduce the Riemannian Constrained Optimization (RCO) algorithm that augments an Adam step with tangent projection, binary-search retraction onto the exact budget level set, and momentum transport; combined with Gumbel straight-through estimation and a final budget-constrained dynamic program, RCO optimizes the true non-decomposable loss while enforcing the budget exactly and without constraint-specific hyperparameters. Experiments on synthetic benchmarks and realistic LLM compression tasks show that RCO matches or exceeds prior art while often using less wall-clock time.
Significance. If the geometric claims and the correctness of the retraction/transport steps hold, the work provides a principled, hyperparameter-free route to exact-budget discrete optimization that directly optimizes the target loss rather than a proxy. This is potentially significant for mixed-precision quantization, non-uniform pruning, and expert routing, where penalty methods require extensive tuning and combinatorial or evolutionary search lacks gradients. The open-source implementation and the reduction of manifold operations to elementary vector operations are additional strengths that support reproducibility and practical adoption.
major comments (1)
- [§3] The central guarantee that binary-search retraction reaches the exact budget level set relies on the monotonicity property (derivative = sum of per-group variances > 0 unless all groups are deterministic). While the skeptic note confirms this follows from standard embedded-hypersurface calculus, the manuscript should include the explicit derivative calculation (likely in §3) rather than stating it only in the abstract, because any hidden approximation here would undermine the “exact budget enforcement” claim.
minor comments (2)
- [Abstract] The abstract asserts that “vector transport reduces to a single inner product”; a one-sentence reminder of the standard formula for the projection onto the tangent space of an embedded hypersurface would improve readability for readers unfamiliar with Riemannian optimization.
- [Experiments] Table captions and axis labels in the experimental section should explicitly state whether the reported cost is the expected cost under the relaxed distribution or the realized cost after the final DP rounding step.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [§3] The central guarantee that binary-search retraction reaches the exact budget level set relies on the monotonicity property (derivative = sum of per-group variances > 0 unless all groups are deterministic). While the skeptic note confirms this follows from standard embedded-hypersurface calculus, the manuscript should include the explicit derivative calculation (likely in §3) rather than stating it only in the abstract, because any hidden approximation here would undermine the “exact budget enforcement” claim.
Authors: We agree that the explicit derivative calculation should appear in the main text. The monotonicity property follows directly from the chain rule applied to the embedded hypersurface defined by the softmax-relaxed budget constraint. In the revised manuscript we will insert a short derivation in §3 (immediately preceding the binary-search retraction paragraph) that computes dE[cost]/dλ = ∑_i Var_i(cost) and shows the sum is strictly positive unless every group is deterministic. This addition will make the exactness of the level-set retraction fully self-contained without reference to the abstract or any external note. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation begins from the explicit definition of expected cost under independent per-group softmax relaxations and computes its Euclidean gradient (the normal) via direct differentiation, yielding the closed-form p ⊙ (c − μ). Monotonicity of cost under shifts along the cost vector follows immediately from the non-negative variance identity, and tangent operations reduce to the standard inner-product projection for any embedded hypersurface. These identities are obtained by elementary calculus on the given manifold definition rather than by fitting, self-referential prediction, or load-bearing self-citation. Standard Riemannian retraction and transport are then applied without additional ansatz or uniqueness theorems imported from prior author work. The overall procedure is therefore self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Softmax relaxation of discrete group assignments is a valid continuous surrogate that preserves the ability to recover feasible discrete solutions via Gumbel straight-through and dynamic programming.
invented entities (1)
-
Riemannian Constrained Optimization (RCO) algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review arXiv
-
[2]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.arXiv preprint arXiv:2101.03961,
work page internal anchor Pith review arXiv
-
[3]
RC-DARTS: Resource constrained differentiable architecture search.arXiv preprint arXiv:1912.12814,
10 Xiaojie Jin, Jiang Wang, Joshua Slocum, Ming-Hsuan Yang, Shengyang Dai, Shuicheng Yan, and Jiashi Feng. RC-DARTS: Resource constrained differentiable architecture search.arXiv preprint arXiv:1912.12814,
-
[4]
REAP the Experts: Why Pruning Prevails for One-Shot MoE compression
Michael Lasby, Reza Bayat, Ivan Googler, Konstantinos N. Plataniotis, and Mahdi S. Hosseini. REAP: Router-weighted expert activation pruning.arXiv preprint arXiv:2510.13999,
work page internal anchor Pith review arXiv
-
[5]
LLM-MQ: Mixed-precision quantization for efficient LLM deployment
Shiyao Li, Xuefei Ning, Ke Hong, Tengxuan Liu, Luning Wang, Xiuhong Li, Kai Zhong, Guohao Dai, Huazhong Yang, and Yu Wang. LLM-MQ: Mixed-precision quantization for efficient LLM deployment. InNeurIPS 2023 Workshop on Efficient Natural Language and Speech Processing, pages 1–5,
2023
-
[6]
EvoESAP: Non-Uniform Expert Pruning for Sparse MoE
Zongfang Liu, Shengkun Tang, Boyang Sun, Ping Wang, Zhiqiang Shen, and Xin Yuan. EvoESAP: Non-uniform expert pruning for sparse MoE.arXiv preprint arXiv:2603.06003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
HIGGS: Pushing the limits of large language model quantization via the linearity theorem
Vladimir Malinovskii, Andrei Panferov, Ivan Ilin, Han Guo, Peter Richtárik, and Dan Alistarh. HIGGS: Pushing the limits of large language model quantization via the linearity theorem. In Proceedings of the 2025 Conference of the North American Chapter of the Association for Compu- tational Linguistics, volume 1, pages 10857–10886. Association for Computat...
2025
-
[8]
Junchen Zhao, Ali Derakhshan, Dushyant Bharadwaj, Jayden Kana Hyman, Junhao Dong, Sangeetha Abdu Jyothi, and Ian Harris. IMPQ: Interaction-aware layerwise mixed precision quantization for LLMs.arXiv preprint arXiv:2509.15455,
-
[9]
By Proposition 2, the (i, k) entry of ∇C(α) isw i pik(ck −E pi[c])
The expected cost C(α) =P i wi⟨softmax(αi),c⟩ is a composition of the smooth softmax with a linear function, hence smooth. By Proposition 2, the (i, k) entry of ∇C(α) isw i pik(ck −E pi[c]). Sincesoftmaxproduces strictly positive probabilities (p ik >0for alli, k), ∥∇C∥ 2 = NX i=1 w2 i KX k=1 p2 ik ck −E pi[c] 2 . If the costs are not all equal, then for ...
2023
-
[10]
All scenarios concentrate near the theoretical bound and stay below45in the worst case. A.3 Verification of retraction axioms A retraction on a manifold M is a smooth map R:TM → M satisfying two axioms [Absil et al., 2008, Definition 4.1]: (i) Rα(0) =α (centering), and (ii) d dt Rα(tξ) t=0 =ξ for all ξ∈T αM (local rigidity). Our retraction takes a tangent...
2008
-
[11]
Therefore d dt t=0Rα(tξ) =ξ
The first term vanishes because ξ∈T αM, and ⟨∇C, ˜c⟩ ̸= 0 by Proposition 3, so dt∗ dt t=0 = 0 . Therefore d dt t=0Rα(tξ) =ξ. A.4 Riemannian gradient The Riemannian gradient of a function f:M →R at α∈ M is the unique tangent vector gradf(α)∈T αM satisfying ⟨gradf,ξ⟩=Df(α)[ξ] for all ξ∈T αM [Boumal, 2023, Proposi- tion 3.61]. We verify that the tangent proj...
2023
-
[12]
When the constraints are separable (each depends on a disjoint subset of groups), independent scalar retraction per constraint suffices
Quadratic convergence typically requires 3–4 iterations for general q. When the constraints are separable (each depends on a disjoint subset of groups), independent scalar retraction per constraint suffices. Figure 5 validates this extension on a synthetic problem withq=16 simultaneous resource constraints, N=500 groups, and K=32 options. The budget manif...
2023
-
[13]
All layers are treated as independent groups (no structural grouping unless stated otherwise)
at a target of 2.5 average bits per parameter. All layers are treated as independent groups (no structural grouping unless stated otherwise). Calibration uses FineWeb-Edu with 256 samples at sequence length 2048 unless noted. Evaluation reports perplexity on two held-out corpora: FineWeb-Edu (FW) and C4, each with 131k tokens at sequence length
2048
-
[14]
Cal Config FW↓C4↓ 256g=8,T=200, lr=0.1 15.78 24.48 512g=8,T=200, lr=0.2 15.65 24.51 256g=4,T=200, lr=0.1 15.81 24.73 512g=4,T=200, lr=0.2 16.23 25.38 No clear benefit from doubling calibration data. The dominant source of variance is the discrete assignment landscape (seed variance, Section E.7), not calibration noise. At 256 samples (524k tokens), the gr...
-
[15]
We run EvoPress for 100 generations, matching the search budget recommended by Sieberling et al
do not include Qwen3-8B in their reported experiments. We run EvoPress for 100 generations, matching the search budget recommended by Sieberling et al. [2025]. RCO and EvoPress are measured in the same compute environment. 1https://github.com/ZongfangLiu/EvoESAP 2https://github.com/IST-DASLab/EvoPress 26 F.3 MxMoE All MxMoE numbers for Qwen1.5-MoE-A2.7B a...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.