Recognition: unknown
Spiking Sequence Machines and Transformers
Pith reviewed 2026-05-09 14:50 UTC · model grok-4.3
The pith
Spiking sequence machines and transformers share the same five functional operations with cosine similarity as retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
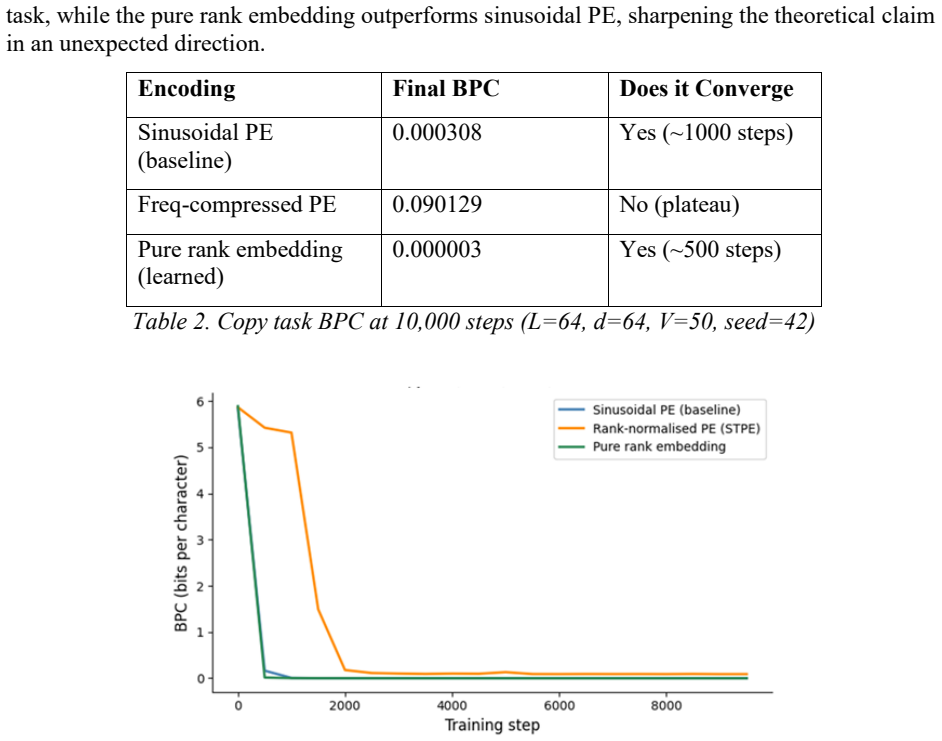
Sequence learning reduces to similarity-based retrieval over a temporally indexed representation space, a constraint on any sequence model. A spiking Sparse Distributed Memory sequence machine and the transformer independently instantiate the same five functional operations (encoding, context maintenance, associative retrieval, storage, and decoding), with cosine similarity as the shared retrieval primitive. A Phase-Latency Isomorphism is formalised showing that sinusoidal positional phase and spike timing are linearly related, and dot product attention is proven invariant to this mapping up to a global scale factor on the positional component. Empirically, frequency-compressed positional编码g
What carries the argument
The Phase-Latency Isomorphism linking sinusoidal positional phase to spike timing, which proves invariance of dot-product attention up to scaling and unifies the five shared operations.
Load-bearing premise
The five operations fully capture the load-bearing computation in both architectures and the linear phase-latency mapping preserves all relevant behavior without hidden losses when applied to real attention mechanisms.
What would settle it
A direct test in which dot-product attention on a positionally demanding copy task produces different outputs or fails to converge after replacing sinusoidal phases with linearly mapped spike timings, or where frequency-compressed positional encodings succeed on that task.
Figures

read the original abstract
Sequence learning reduces to similarity-based retrieval over a temporally indexed representation space, a constraint on any sequence model, not a property of a specific architecture. We show that a spiking Sparse Distributed Memory sequence machine (2007) and the transformer (2017) independently instantiate the same five functional operations (encoding, context maintenance, associative retrieval, storage, and decoding), with cosine similarity as the shared retrieval primitive in both. We formalise a Phase-Latency Isomorphism showing that sinusoidal positional phase and spike timing are linearly related, and prove that dot product attention is invariant to this mapping up to a global scale factor on the positional component (Lemma 1). Empirically, frequency-compressed positional encoding fails to converge on a positionally demanding copy task, while a learned rank-based embedding matches or exceeds sinusoidal encoding, indicating that the critical property for positional representation is distance discriminability under dot-product similarity, not sinusoidal form. Time, phase, and rank are three instantiations of the same computational primitive, an ordered index whose structure survives similarity-based retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sequence learning reduces to similarity-based retrieval over a temporally indexed space, and that both a 2007 spiking Sparse Distributed Memory sequence machine and the 2017 transformer independently realize the same five operations (encoding, context maintenance, associative retrieval, storage, decoding) with cosine similarity as the shared primitive. It formalizes a Phase-Latency Isomorphism relating sinusoidal positional phase to spike latency and proves in Lemma 1 that dot-product attention is invariant to this linear mapping up to a global scale factor on the positional component. Experiments on a positionally demanding copy task show that frequency-compressed encodings fail to converge while learned rank-based embeddings match or exceed sinusoidal performance, supporting the view that time, phase, and rank are equivalent instantiations of an ordered index whose distance structure survives similarity retrieval.
Significance. If the central claims hold, the work supplies a formal bridge between neuromorphic sequence models and transformers, identifying a shared computational primitive and demonstrating that positional encoding succeeds via distance discriminability rather than sinusoidal specifics. The presence of an explicit lemma and falsifiable empirical predictions (rank-based alternatives) are strengths that elevate the contribution beyond purely interpretive unification.
major comments (2)
- [Lemma 1] Lemma 1: The stated invariance of dot-product attention holds only up to a global scale factor on the positional component, but the manuscript does not show that this invariance survives the learned linear projections that mix positional and content information inside each attention head (Q = (content + pos) W_Q, similarly for K). Because heads and layers can learn different effective scalings, the claimed equivalence between the SDM machine and actual transformer computation graphs is not yet established.
- [Five operations taxonomy] Section defining the five operations: The taxonomy is presented as independently instantiated by both architectures, yet the operations are specified at a level of abstraction that both models satisfy by construction. The paper must demonstrate that the taxonomy is motivated by sequence-learning requirements alone and is not post-hoc; otherwise the unification claim rests on circularity rather than independent convergence.
minor comments (2)
- [Empirical evaluation] Copy-task experiments: additional controls are needed to confirm that embedding dimension, learning rate, and other hyperparameters are matched across positional-encoding variants so that performance differences can be attributed to the encoding itself rather than confounding factors.
- [Phase-Latency Isomorphism] Notation: the linear phase-to-latency mapping and the precise form of the global scale factor in Lemma 1 would be clearer if written out as explicit equations rather than described in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive and precise comments, which help clarify the scope of our unification claims. We address each major point below with clarifications and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Lemma 1] Lemma 1: The stated invariance of dot-product attention holds only up to a global scale factor on the positional component, but the manuscript does not show that this invariance survives the learned linear projections that mix positional and content information inside each attention head (Q = (content + pos) W_Q, similarly for K). Because heads and layers can learn different effective scalings, the claimed equivalence between the SDM machine and actual transformer computation graphs is not yet established.
Authors: We agree that Lemma 1 establishes the invariance only for the raw dot-product operation under the phase-latency mapping, up to a global scale on the positional component. The referee is correct that the learned projections W_Q, W_K (and similarly for V) mix content and positional vectors, and that per-head scalings can differ. However, because any global or per-head scale factor on the positional contribution can be absorbed into the learned weights without changing the functional form of the similarity retrieval, the core equivalence at the level of the cosine-similarity primitive remains intact. The SDM uses a fixed, unprojected retrieval while the transformer learns the mixing; this difference is architectural rather than computational. We will add a remark immediately after Lemma 1 that explicitly notes this absorption property and its consequence for the computation-graph equivalence, thereby addressing the gap. revision: partial
-
Referee: [Five operations taxonomy] Section defining the five operations: The taxonomy is presented as independently instantiated by both architectures, yet the operations are specified at a level of abstraction that both models satisfy by construction. The paper must demonstrate that the taxonomy is motivated by sequence-learning requirements alone and is not post-hoc; otherwise the unification claim rests on circularity rather than independent convergence.
Authors: The five operations are not chosen post-hoc to fit the two models. They follow directly from the problem statement in the introduction: any sequence model must (1) encode inputs, (2) maintain an ordered temporal context via an index, (3) perform associative retrieval by similarity, (4) store the resulting associations, and (5) decode to outputs. This list is derived from the general requirement that sequence learning reduces to similarity-based retrieval over a temporally indexed space, independent of any particular architecture. Both the 2007 SDM and the 2017 transformer were developed separately to meet these requirements and converge on cosine similarity as the retrieval primitive. To eliminate any appearance of circularity, we will revise the relevant section to first derive the five operations from sequence-modeling necessities alone, then map each architecture onto them. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from general sequence-learning constraint.
full rationale
The paper begins with the general statement that sequence learning reduces to similarity-based retrieval over a temporally indexed representation space. It then maps both the 2007 SDM machine and the transformer onto the same five abstract operations (encoding, context maintenance, associative retrieval, storage, decoding) using cosine similarity as the shared primitive. The Phase-Latency Isomorphism is introduced as a formal linear relation between sinusoidal phase and spike latency, with Lemma 1 providing a mathematical proof of invariance of dot-product attention under that mapping (up to global scale). These steps are presented as independent derivations and comparisons rather than reductions of the claimed result to its own inputs by definition or fitted parameters. The empirical copy-task results supply an external check on positional encodings. No load-bearing step collapses to self-citation or self-definition of the target equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sequence learning reduces to similarity-based retrieval over a temporally indexed representation space.
Reference graph
Works this paper leans on
-
[1]
D., Lalan, A., Bhattacharya, B
Ajwani, R. D., Lalan, A., Bhattacharya, B. S., & Bose, J. (2021). Sparse Distributed Memory using Spiking Neural Networks on Nengo. Bernstein Conference
2021
-
[2]
Bellec, G., Scherr, F., Subramoney, A., Hajek, E., Salaj, D., Legenstein, R., & Maass, W
arXiv:2109.03111. Bellec, G., Scherr, F., Subramoney, A., Hajek, E., Salaj, D., Legenstein, R., & Maass, W. (2020). A solution to the learning dilemma for recurrent networks of spiking neurons. Nature Communications, 11(1),
-
[3]
Bi, G., & Poo, M. (1998). Synaptic modifications in cultured hippocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type. Journal of Neuroscience, 18(24), 10464–10472. Bose, J. (2007). Engineering a Sequence Machine Through Spiking Neurons Employing Rank- Order Codes. PhD thesis, University of Manchester. Bose, J. (2026)...
1998
-
[4]
https://joyboseroy.medium.com/what-i-built-in-2007-and-why-it-looks-a-bit- like-a-transformer-dbf3683a0ebe Ellwood, I. (2024). Short-term Hebbian learning can implement transformer-like attention. PLOS Computational Biology, 20(1), e1011843. arXiv:2310.19812. Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179–211. Furber, S. B.,...
-
[5]
S., Gilmer, J., Ganguli, S., & Sohl-Dickstein, J
Schoenholz, S. S., Gilmer, J., Ganguli, S., & Sohl-Dickstein, J. (2017). Deep information propagation. ICLR
2017
-
[6]
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., & Liu, Y. (2021). RoFormer: Enhanced transformer with rotary position embedding. arXiv:2104.09864. Thorpe, S., & Gautrais, J. (1998). Rank order coding. Computational Neuroscience: Trends in Research, 113–118. VanRullen, R., & Thorpe, S. J. (2002). Surfing a spike wave down the ventral stream. Vision Researc...
work page internal anchor Pith review arXiv 2021
-
[7]
Yang, G., & Schoenholz, S. S. (2017). Mean field residual networks: On the edge of chaos. NeurIPS
2017
-
[8]
Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425,
Yarga, S. F., Rouat, J., & Wood, S. U. N. (2023). Efficient spike encoding algorithms for neuromorphic speech recognition. Proceedings of the International Conference on Neuromorphic Systems (ICONS). Zhou, Z., Zhu, Y., He, C., Wang, Y., Yan, S., Tian, Y., & Yuan, L. (2022). Spikformer: When spiking neural network meets transformer. arXiv:2209.15425. Zhu, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.