Recognition: unknown
To Call or Not to Call: A Framework to Assess and Optimize LLM Tool Calling
Pith reviewed 2026-05-09 19:29 UTC · model grok-4.3
The pith
LLMs often misjudge when calling tools like web search is truly necessary or useful, but estimators built from their internal hidden states can make better calls and raise task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an LLM's self-perceived need and utility for tool calls frequently diverge from the true need and utility that would be obtained by optimally allocating calls; a framework that measures both perspectives reveals this gap, and estimators trained on hidden-state activations can produce controllers that close the gap and improve end-task results.
What carries the argument
A three-factor decision framework (necessity, utility, affordability) that contrasts a normative lens (optimal allocation as ground truth) with a descriptive lens (model's observed behavior), plus lightweight estimators of need and utility extracted from hidden states to drive controllers.
If this is right
- Task performance rises when tool-call decisions are routed through the hidden-state estimators rather than left to the model's own judgment.
- The same lightweight estimators can be attached to multiple base models without retraining the base model itself.
- The framework supplies concrete metrics that let researchers quantify how often a given model over- or under-calls tools.
- Simple rule-based or threshold-based controllers suffice once the estimators are trained.
Where Pith is reading between the lines
- The approach could be tested on tool sets other than web search to check whether hidden-state signals remain informative when the external tool is less noisy.
- If the estimators prove stable across tasks, they might allow a single lightweight controller to serve many different agent workflows without task-specific retraining.
- The misalignment finding raises the possibility that current agent scaffolds over-rely on the LLM's verbal self-assessment of its own knowledge gaps.
Load-bearing premise
True need and utility for tool calls can be inferred reliably enough from an optimal allocation of calls to serve as training labels that generalize across tasks.
What would settle it
On held-out tasks or new models, controllers built from the hidden-state estimators produce no measurable gain in task accuracy or decision quality compared with the model's unaided self-perception.
Figures

























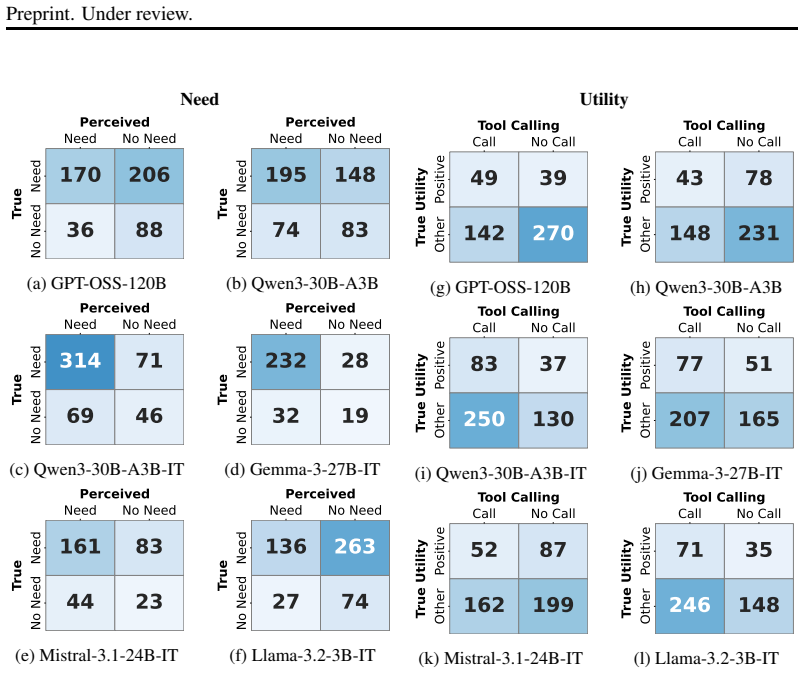























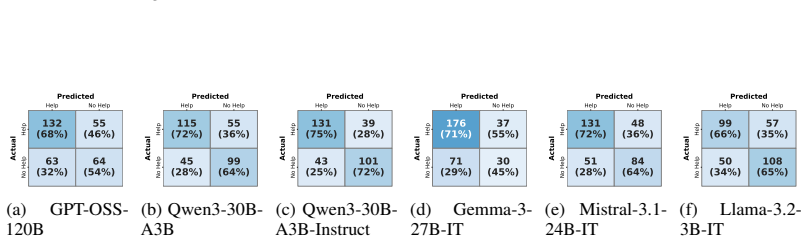







read the original abstract
Agentic AI architectures augment LLMs with external tools, unlocking strong capabilities. However, tool use is not always beneficial; some calls may be redundant or even harmful. Effective tool use, therefore, hinges on a core LLM decision: whether to call or not call a tool, when performing a task. This decision is particularly challenging for web search tools, where the benefits of external information depend on the model's internal knowledge and its ability to integrate potentially noisy tool responses. We introduce a principled framework inspired by decision-making theory to evaluate web search tool-use decisions along three key factors: necessity, utility, and affordability. Our analysis combines two complementary lenses: a normative perspective that infers true need and utility from an optimal allocation of tool calls, and a descriptive perspective that infers the model's self-perceived need and utility from their observed behaviors. We find that models' perceived need and utility of tool calls are often misaligned with their true need and utility. Building on this framework, we train lightweight estimators of need and utility based on models' hidden states. Our estimators enable simple controllers that can improve decision quality and lead to stronger task performance than the self-perceived set up across three tasks and six models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a decision-theoretic framework for evaluating LLM tool-calling decisions (focusing on web search) along necessity, utility, and affordability. It contrasts a normative lens, which infers 'true' need/utility from an optimal allocation of tool calls, with a descriptive lens based on observed model behaviors, revealing frequent misalignments. Lightweight estimators trained on hidden states are then used to build controllers that improve decision quality and task performance over self-perceived baselines across three tasks and six models.
Significance. If the normative labels prove independent of evaluation data and the hidden-state estimators generalize without selection bias, the work offers a practical route to optimize tool use in agentic systems, reducing redundant or harmful calls while boosting accuracy. The empirical demonstration across multiple models and tasks, combined with the use of internal representations rather than external supervision, strengthens its potential impact on reliable LLM agents.
major comments (2)
- [Abstract and normative perspective] Abstract and normative perspective section: The central claim that models' perceived need/utility are misaligned with 'true' values, and that hidden-state estimators outperform self-perception, rests on optimal allocation serving as independent ground truth. However, the manuscript does not detail the exact procedure for computing this allocation (e.g., whether it relies on post-hoc accuracy gains on the same instances, any data exclusion rules, or cross-validation). This risks circularity or selection bias in the labels used both for misalignment analysis and estimator training, as flagged in the stress-test note.
- [Results and experimental setup] Results and experimental setup: Performance improvements from the controllers are reported across tasks and models, but without error bars, number of runs, statistical tests, or explicit confirmation that optimal-allocation labels were derived from held-out data, the robustness of the gains cannot be verified. This directly affects the claim of stronger task performance than the self-perceived setup.
minor comments (3)
- [Framework introduction] The affordability factor is mentioned in the framework but receives less elaboration than necessity and utility; a brief formal definition or example early in the paper would improve clarity.
- [Figures] Ensure all figures comparing normative vs. descriptive decisions include clear legends, axis labels, and sample sizes to aid interpretation of misalignment patterns.
- [Related work] Add a short discussion of related work on LLM calibration, uncertainty estimation, or tool-use optimization to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and rigor of our work. We respond to each major comment below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and normative perspective] Abstract and normative perspective section: The central claim that models' perceived need/utility are misaligned with 'true' values, and that hidden-state estimators outperform self-perception, rests on optimal allocation serving as independent ground truth. However, the manuscript does not detail the exact procedure for computing this allocation (e.g., whether it relies on post-hoc accuracy gains on the same instances, any data exclusion rules, or cross-validation). This risks circularity or selection bias in the labels used both for misalignment analysis and estimator training, as flagged in the stress-test note.
Authors: We agree that a more explicit description of the optimal allocation procedure is necessary to establish its independence as ground truth. In the revised version, we will expand the relevant section to provide a detailed, step-by-step account of how the allocation is computed, including the use of data splits, any exclusion criteria, and cross-validation steps. This will clarify that the normative labels are derived independently of the instances used for misalignment analysis and estimator training, thereby addressing concerns about circularity and selection bias noted in the stress-test. revision: yes
-
Referee: [Results and experimental setup] Results and experimental setup: Performance improvements from the controllers are reported across tasks and models, but without error bars, number of runs, statistical tests, or explicit confirmation that optimal-allocation labels were derived from held-out data, the robustness of the gains cannot be verified. This directly affects the claim of stronger task performance than the self-perceived setup.
Authors: We concur that the experimental results would benefit from enhanced statistical reporting to better substantiate the performance improvements. We will revise the results and experimental setup sections to include error bars, specify the number of experimental runs, incorporate appropriate statistical tests, and provide clear confirmation along with details that the optimal-allocation labels were indeed derived from held-out data. These additions will allow readers to verify the robustness of the gains over the self-perceived baseline. revision: yes
Circularity Check
No circularity: normative optimal allocation is independent external ground truth
full rationale
The paper's core chain defines true need/utility from an optimal allocation benchmark (computed via task outcomes), contrasts it with self-perceived behavior from observed decisions, trains hidden-state estimators to predict the benchmark, and evaluates controllers on downstream task performance. This is standard probe training to an external label with no equations reducing the estimator output to the input by construction, no self-citation load-bearing the uniqueness of the framework, and no renaming or ansatz smuggling. The claimed misalignment and improvement are falsifiable against held-out task metrics and remain independent of the estimators themselves.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tool use is not always beneficial; some calls may be redundant or even harmful.
- ad hoc to paper True need and utility can be inferred from an optimal allocation of tool calls.
invented entities (1)
-
necessity, utility, and affordability factors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adaptive Retrieval Without Self-Knowledge? Bringing Uncertainty Back Home
Moskvoretskii, Viktor and Marina, Maria and Salnikov, Mikhail and Ivanov, Nikolay and Pletenev, Sergey and Galimzianova, Daria and Krayko, Nikita and Konovalov, Vasily and Nikishina, Irina and Panchenko, Alexander. Adaptive Retrieval Without Self-Knowledge? Bringing Uncertainty Back Home. Proceedings of the 63rd Annual Meeting of the Association for Compu...
-
[2]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[3]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[4]
Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
Rowen: Adaptive Retrieval-Augmented Generation for Hallucination Mitigation in LLMs , author=. Proceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region , pages=
2025
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Seakr: Self-aware knowledge retrieval for adaptive retrieval augmented generation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review arXiv
-
[7]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Knowledge of knowledge: Exploring known-unknowns uncertainty with large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[8]
Advances in Neural Information Processing Systems , volume=
Large language models must be taught to know what they don’t know , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Estimating knowledge in large language models without generating a single token , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[10]
Semantic entropy probes: Robust and cheap hallucination detection in llms , author=. arXiv preprint arXiv:2406.15927 , year=
-
[11]
ICLR , year=
Query-level uncertainty in large language models , author=. ICLR , year=
-
[12]
ACM Web Conference , year=
Bowling with ChatGPT: On the Evolving User Interactions with Conversational AI Systems , author=. ACM Web Conference , year=
-
[13]
Forty-second International Conference on Machine Learning , year=
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[14]
2025 , url=
Hadas Orgad and Michael Toker and Zorik Gekhman and Roi Reichart and Idan Szpektor and Hadas Kotek and Yonatan Belinkov , booktitle=. 2025 , url=
2025
-
[15]
doi: 10.18653/v1/2024.findings-emnlp.552
Song, Yixiao and Kim, Yekyung and Iyyer, Mohit. V eri S core: Evaluating the factuality of verifiable claims in long-form text generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.552
-
[16]
2017 , publisher=
An introduction to decision theory , author=. 2017 , publisher=
2017
-
[17]
, author=
Judgment under Uncertainty: Heuristics and Biases: Biases in judgments reveal some heuristics of thinking under uncertainty. , author=. science , volume=. 1974 , publisher=
1974
-
[18]
2023 , html =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , html =
2023
-
[19]
Toolformer: language models can teach themselves to use tools , year =
Schick, Timo and Dwivedi-Yu, Jane and Dess\'. Toolformer: language models can teach themselves to use tools , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[20]
GEAR : Augmenting Language Models with Generalizable and Efficient Tool Resolution
Lu, Yining and Yu, Haoping and Khashabi, Daniel. GEAR : Augmenting Language Models with Generalizable and Efficient Tool Resolution. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.7
-
[21]
Making language models better tool learners with execution feedback , url =
Qiao, Shuofei and Gui, Honghao and Lv, Chengfei and Jia, Qianghuai and Chen, Huajun and Zhang, Ningyu. Making Language Models Better Tool Learners with Execution Feedback. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.1865...
-
[22]
Agentic reasoning and tool integration for llms via reinforcement learning , author=. arXiv preprint arXiv:2505.01441 , year=
-
[23]
ToolRL: Reward is All Tool Learning Needs
Toolrl: Reward is all tool learning needs , author=. arXiv preprint arXiv:2504.13958 , year=
work page internal anchor Pith review arXiv
-
[24]
2025 , eprint=
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs , author=. 2025 , eprint=
2025
-
[25]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review arXiv
-
[26]
Torl: Scaling tool-integrated rl, 2025 b
Torl: Scaling tool-integrated rl , author=. arXiv preprint arXiv:2503.23383 , year=
-
[27]
arXiv e-prints , pages=
Otc: Optimal tool calls via reinforcement learning , author=. arXiv e-prints , pages=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Catp-llm: Empowering large language models for cost-aware tool planning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
Budget-aware tool-use enables effective agent scaling
Budget-aware tool-use enables effective agent scaling , author=. arXiv preprint arXiv:2511.17006 , year=
-
[30]
The Thirteenth International Conference on Learning Representations , year=
Rational decision-making agent with learning internal utility judgment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
Proceedings of the 15th International Conference on Recent Advances in Natural Language Processing-Natural Language Processing in the Generative AI Era , pages=
When to retrieve: Teaching llms to utilize information retrieval effectively , author=. Proceedings of the 15th International Conference on Recent Advances in Natural Language Processing-Natural Language Processing in the Generative AI Era , pages=
-
[32]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Adaptive tool use in large language models with meta-cognition trigger , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:2309.10691 , year=
Mint: Evaluating llms in multi-turn interaction with tools and language feedback , author=. arXiv preprint arXiv:2309.10691 , year=
-
[35]
Frontiers of Computer Science , volume=
Tool learning with large language models: A survey , author=. Frontiers of Computer Science , volume=. 2025 , publisher=
2025
-
[36]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. arXiv preprint arXiv:2307.16789 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[38]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
MetaTool benchmark for large language models: Deciding whether to use tools and which to use, 2024
Metatool benchmark for large language models: Deciding whether to use tools and which to use , author=. arXiv preprint arXiv:2310.03128 , year=
-
[40]
Gummadi, and Muhammad Bilal Zafar
Characterizing Web Search in The Age of Generative AI , author=. arXiv preprint arXiv:2510.11560 , year=
- [41]
-
[42]
34th USENIX Security Symposium (USENIX Security 25) , pages=
When \ LLMs \ go online: The emerging threat of \ Web-Enabled \ \ LLMs \ , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[43]
Don't lie to your friends: Learning what you know from collaborative self-play , author=. arXiv preprint arXiv:2503.14481 , year=
-
[44]
Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
WebGLM: towards an efficient web-enhanced question answering system with human preferences , author=. Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[45]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Search-o1: Agentic Search-Enhanced Large Reasoning Models , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[46]
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , booktitle=. Self-. 2024 , url=
2024
-
[47]
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
-
[48]
ACM Transactions on Information Systems (TOIS) , volume=
Cumulated gain-based evaluation of IR techniques , author=. ACM Transactions on Information Systems (TOIS) , volume=. 2002 , publisher=
2002
-
[49]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[50]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Active retrieval augmented generation , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[51]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Dragin: Dynamic retrieval augmented generation based on the real-time information needs of large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[52]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Critic: Large language models can self-correct with tool-interactive critiquing , author=. arXiv preprint arXiv:2305.11738 , year=
work page internal anchor Pith review arXiv
-
[53]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
On early detection of hallucinations in factual question answering , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[54]
arXiv preprint arXiv:2407.17468 , year=
Wildhallucinations: Evaluating long-form factuality in llms with real-world entity queries , author=. arXiv preprint arXiv:2407.17468 , year=
-
[55]
When2Call: When (not) to call tools , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[56]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.