LLM Output Detectability and Task Performance Can be Jointly Optimized
Pith reviewed 2026-05-09 15:09 UTC · model grok-4.3
The pith
Reinforcement learning can jointly optimize LLMs for high machine-text detectability and strong performance on downstream tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
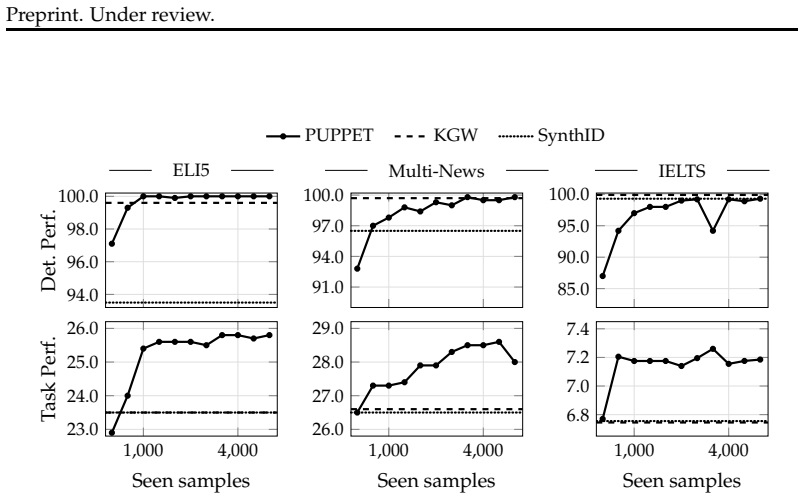
Training LLMs via reinforcement learning with dual rewards—a detector likelihood that the output is machine-generated and an evaluator for the target task metric—yields models whose generations are competitive in detectability with watermarking methods yet outperform them on downstream task scores; the process uses only a few thousand samples, completes in 1-2 GPU hours, and remains effective across out-of-domain tasks, model families, sizes, and paraphrasing attacks.
What carries the argument
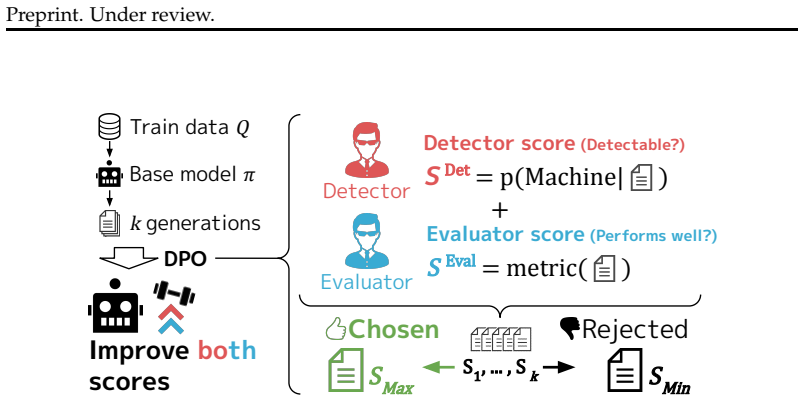
PUPPET, the reinforcement learning procedure that combines a detector's machine-class likelihood reward with a task-specific performance reward to fine-tune the LLM's token generation.
If this is right
- The resulting LLMs achieve detectability rates competitive with watermarking methods.
- They deliver higher scores than watermarked models on long-form QA, summarization, and essay writing.
- Training requires only a few thousand samples and 1-2 GPU hours.
- The improvements persist on out-of-domain tasks and across different LLM families and sizes.
- The generated text remains detectable even after paraphrasing attacks.
Where Pith is reading between the lines
- Detection might be achievable through learned generation habits rather than fixed token biases, allowing more flexible text styles.
- The approach could be paired with other detectors to increase robustness without additional watermarking overhead.
- If the learned patterns generalize broadly, deployment of LLMs could include built-in detectability at lower performance cost than current methods.
- A direct test would apply the same dual-reward training to newer model architectures or generation tasks beyond text.
Load-bearing premise
The two reward signals for detectability and task performance can be balanced in reinforcement learning without one reward dominating or the model learning shortcuts that fail outside the training tasks and detectors.
What would settle it
Train a model with the dual-reward method, then test it on an entirely new task type with a detector never seen during training; if detectability falls below watermark levels or task scores drop relative to the non-optimized baseline, the joint optimization claim does not hold.
Figures




read the original abstract
Detecting machine-generated text is essential for transparency and accountability when deploying large language models (LLMs). Among detection approaches, watermarking is a statistically reliable method by design -- it embeds detectable signals into LLM outputs by biasing their token distributions. However, it has been reported that watermarked LLMs often perform worse on downstream tasks. We propose PUPPET, a framework that fine-tunes an LLM via reinforcement learning to generate text that is both more detectable and better performing on downstream tasks. We use two reward functions: a detector that outputs a machine-class likelihood and an evaluator that measures a task-specific metric. Experiments on long-form QA, summarization, and essay writing show that LLMs trained with PUPPET achieve high detectability competitive with watermarking methods while outperforming them on downstream tasks. The analysis shows that this optimization can be performed efficiently with only a few thousand samples in 1--2 GPU hours. Moreover, these gains are consistent across out-of-domain tasks, different LLM families, and model sizes, and are even robust to paraphrasing attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PUPPET, a reinforcement learning framework for fine-tuning LLMs that combines a detector-based reward (machine-class likelihood) with a task-specific evaluator reward. Experiments on long-form QA, summarization, and essay writing claim that the resulting models achieve detectability competitive with watermarking while outperforming watermarking on downstream task metrics, with reported efficiency (few thousand samples, 1-2 GPU hours) and robustness to out-of-domain tasks, model families/sizes, and paraphrasing.
Significance. If the empirical claims hold under detailed scrutiny, the work would provide a practical method to reduce the apparent trade-off between LLM output detectability and task utility, with direct implications for transparent AI deployment. The efficiency of the RL procedure and the reported cross-model/out-of-domain consistency would be notable strengths if supported by quantitative evidence and proper controls.
major comments (3)
- [Abstract and Experimental Results] The abstract reports positive experimental outcomes across three tasks and robustness checks but provides no quantitative results, specific baselines, effect sizes, or statistical tests. This absence makes it impossible to assess whether the claimed joint optimization actually outperforms watermarking by a meaningful margin or whether the detector reward simply dominates.
- [Method (Reward Functions) and Robustness Analysis] The central claim requires that the RL policy increases general statistical detectability rather than exploiting patterns specific to the detector used in the reward. The manuscript does not indicate whether the reward detector was held fixed across all reported evaluations or whether an ablation with an unseen detector (or paraphraser not seen during training) was performed; without this, the robustness claims cannot be distinguished from reward hacking.
- [Method (RL Objective)] No details are provided on how the two reward signals are combined (weighting, scaling, or normalization). Because the detector reward is itself a learned scalar, the absence of an ablation on reward combination leaves open the possibility that one signal dominates or that the policy learns narrow, non-generalizable patterns.
minor comments (1)
- [Abstract] The efficiency claim ('1--2 GPU hours') would benefit from specifying the exact hardware configuration and providing a breakdown of wall-clock time versus number of samples for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, providing clarifications from the manuscript and indicating revisions made to improve the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The abstract reports positive experimental outcomes across three tasks and robustness checks but provides no quantitative results, specific baselines, effect sizes, or statistical tests. This absence makes it impossible to assess whether the claimed joint optimization actually outperforms watermarking by a meaningful margin or whether the detector reward simply dominates.
Authors: We agree that the abstract would benefit from quantitative details to allow readers to immediately gauge the effect sizes. The revised manuscript updates the abstract to include key metrics from the experiments, such as detectability scores competitive with watermarking (within 1-3 percentage points) and task performance gains (e.g., improvements on ROUGE and accuracy metrics), along with references to the statistical tests and baselines reported in Section 4. revision: yes
-
Referee: [Method (Reward Functions) and Robustness Analysis] The central claim requires that the RL policy increases general statistical detectability rather than exploiting patterns specific to the detector used in the reward. The manuscript does not indicate whether the reward detector was held fixed across all reported evaluations or whether an ablation with an unseen detector (or paraphraser not seen during training) was performed; without this, the robustness claims cannot be distinguished from reward hacking.
Authors: The reward detector is held fixed across all evaluations, as stated in Section 3.2. Robustness experiments explicitly use paraphrasers not seen during training, and out-of-domain and cross-model results further support generality. To directly address the possibility of reward hacking, the revised manuscript adds a new ablation evaluating the trained policy with an independent detector model not used in the reward. revision: yes
-
Referee: [Method (RL Objective)] No details are provided on how the two reward signals are combined (weighting, scaling, or normalization). Because the detector reward is itself a learned scalar, the absence of an ablation on reward combination leaves open the possibility that one signal dominates or that the policy learns narrow, non-generalizable patterns.
Authors: We have expanded the Method section to explicitly describe the reward combination: both signals are scaled to [0,1] and combined via a weighted sum (default equal weights of 0.5). The revised manuscript also includes an ablation varying the weights across a range of values, demonstrating that task performance and detectability remain balanced and that results do not depend on one signal dominating. revision: yes
Circularity Check
No circularity: empirical RL framework with external rewards
full rationale
The paper describes an empirical training procedure (PUPPET) that fine-tunes LLMs via RL using two independent external reward signals: a separate detector model outputting machine-class likelihood and a task-specific evaluator metric. No equations, derivations, or self-referential definitions appear in the abstract or described method; the central claims rest on reported experimental outcomes across tasks, models, and attacks rather than any reduction of predictions to fitted inputs or self-citations by construction. The framework is self-contained against external benchmarks (watermarking baselines and downstream metrics), with no load-bearing uniqueness theorems or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward combination weights
axioms (1)
- domain assumption Reinforcement learning with multiple scalar rewards can produce models that improve on both objectives simultaneously
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 40th International Conference on Machine Learning , year =
John Kirchenbauer and Jonas Geiping and Yuxin Wen and Jonathan Katz and Ian Miers and Tom Goldstein , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[2]
Nature , year=
Sumanth Dathathri and Abigail See and Sumedh Ghaisas and Po-Sen Huang and Rob McAdam and Johannes Welbl and Vandana Bachani and Alex Kaskasoli and Robert Stanforth and Tatiana Matejovicova and others , title=. Nature , year=
-
[3]
Provable Robust Watermarking for
Xuandong Zhao and Prabhanjan Vijendra Ananth and Lei Li and Yu-Xiang Wang , booktitle=. Provable Robust Watermarking for. 2024 , url=
2024
-
[4]
Simons institute talk on watermarking of large language models, 2023 , author=
2023
-
[5]
k- S em S tamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text
Hou, Abe and Zhang, Jingyu and Wang, Yichen and Khashabi, Daniel and He, Tianxing. k- S em S tamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[6]
Spotting
Abhimanyu Hans and Avi Schwarzschild and Valeriia Cherepanova and Hamid Kazemi and Aniruddha Saha and Micah Goldblum and Jonas Geiping and Tom Goldstein , booktitle=. Spotting. 2024 , url=
2024
-
[7]
2019 , eprint=
Release strategies and the social impacts of language models , author=. 2019 , eprint=
2019
-
[8]
Fast-Detect
Guangsheng Bao and Yanbin Zhao and Zhiyang Teng and Linyi Yang and Yue Zhang , booktitle=. Fast-Detect. 2024 , url=
2024
-
[9]
2023 , url =
Mitchell, Eric and Lee, Yoonho and Khazatsky, Alexander and Manning, Christopher D and Finn, Chelsea , booktitle =. 2023 , url =
2023
-
[10]
S em S tamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation
Hou, Abe and Zhang, Jingyu and He, Tianxing and Wang, Yichen and Chuang, Yung-Sung and Wang, Hongwei and Shen, Lingfeng and Van Durme, Benjamin and Khashabi, Daniel and Tsvetkov, Yulia. S em S tamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation. Proceedings of the 2024 Conference of the North American Chapter of the Association for...
2024
-
[11]
From Trade-off to Synergy: A Versatile Symbiotic Watermarking Framework for Large Language Models
Wang, Yidan and Ren, Yubing and Cao, Yanan and Fang, Binxing. From Trade-off to Synergy: A Versatile Symbiotic Watermarking Framework for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[12]
Downstream Trade-offs of a Family of Text Watermarks
Ajith, Anirudh and Singh, Sameer and Pruthi, Danish. Downstream Trade-offs of a Family of Text Watermarks. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024
2024
-
[13]
Watermarking Conditional Text Generation for AI Detection: Unveiling Challenges and a Semantic-Aware Watermark Remedy
Yu Fu and Deyi Xiong and Yue Dong. Watermarking Conditional Text Generation for AI Detection: Unveiling Challenges and a Semantic-Aware Watermark Remedy. Proceedings of the AAAI Conference on Artificial Intelligence
-
[14]
Three Bricks to Consolidate Watermarks for Large Language Models , year=
Fernandez, Pierre and Chaffin, Antoine and Tit, Karim and Chappelier, Vivien and Furon, Teddy , booktitle=. Three Bricks to Consolidate Watermarks for Large Language Models , year=
-
[15]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and others , year =. The. 2407.21783 , primaryClass=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[18]
2023 , url=
Xiaomeng Hu and Pin-Yu Chen and Tsung-Yi Ho , booktitle=. 2023 , url=
2023
-
[19]
ELI 5: Long Form Question Answering
Fan, Angela and Jernite, Yacine and Perez, Ethan and Grangier, David and Weston, Jason and Auli, Michael. ELI 5: Long Form Question Answering. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019
2019
-
[20]
How close is ChatGPT to human experts? Comparison corpus, evaluation, and detection
Biyang Guo and Xin Zhang and Ziyuan Wang and Minqi Jiang and Jinran Nie and Yuxuan Ding and Jianwei Yue and Yupeng Wu. How Close is C hat GPT to Human Experts? Comparison Corpus, Evaluation, and Detection. 2023. 2301.07597 , howpublished =
-
[21]
Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model
Fabbri, Alexander and Li, Irene and She, Tianwei and Li, Suyi and Radev, Dragomir. Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019
2019
-
[22]
Proceedings of the 38th AAAI Conference on Artificial Intelligence , year =
Ryuto Koike and Masahiro Kaneko and Naoaki Okazaki , title =. Proceedings of the 38th AAAI Conference on Artificial Intelligence , year =
-
[23]
Jifan Yu and Xiaozhi Wang and Shangqing Tu and Shulin Cao and Daniel Zhang-Li and Xin Lv and Hao Peng and Zijun Yao and Xiaohan Zhang and Hanming Li and others , booktitle=. Ko. 2024 , url=
2024
-
[24]
COPEN : Probing Conceptual Knowledge in Pre-trained Language Models
Peng, Hao and Wang, Xiaozhi and Hu, Shengding and Jin, Hailong and Hou, Lei and Li, Juanzi and Liu, Zhiyuan and Liu, Qun. COPEN : Probing Conceptual Knowledge in Pre-trained Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022
2022
-
[25]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018
2018
-
[26]
2021 , howpublished =
Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan and Henrique Ponde de Oliveira Pinto and Jared Kaplan and Harri Edwards and Yuri Burda and Nicholas Joseph and Greg Brockman and others , title =. 2021 , howpublished =
2021
-
[27]
Yann Dubois and Xuechen Li and Rohan Taori and Tianyi Zhang and Ishaan Gulrajani and Jimmy Ba and Carlos Guestrin and Percy Liang and Tatsunori Hashimoto , booktitle=. Alpaca. 2023 , url=
2023
-
[28]
Companion Proceedings of the The Web Conference 2018 , pages =
Maia, Macedo and Handschuh, Siegfried and Freitas, Andr\'. Companion Proceedings of the The Web Conference 2018 , pages =. 2018 , url =
2018
-
[29]
QMS um: A New Benchmark for Query-based Multi-domain Meeting Summarization
Zhong, Ming and Yin, Da and Yu, Tao and Zaidi, Ahmad and Mutuma, Mutethia and Jha, Rahul and Awadallah, Ahmed Hassan and Celikyilmaz, Asli and Liu, Yang and Qiu, Xipeng and others. QMS um: A New Benchmark for Query-based Multi-domain Meeting Summarization. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computationa...
2021
-
[30]
W ater B ench: Towards Holistic Evaluation of Watermarks for Large Language Models
Tu, Shangqing and Sun, Yuliang and Bai, Yushi and Yu, Jifan and Hou, Lei and Li, Juanzi. W ater B ench: Towards Holistic Evaluation of Watermarks for Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[31]
M ark LLM : An Open-Source Toolkit for LLM Watermarking
Pan, Leyi and Liu, Aiwei and He, Zhiwei and Gao, Zitian and Zhao, Xuandong and Lu, Yijian and Zhou, Binglin and Liu, Shuliang and Hu, Xuming and Wen, Lijie and others. M ark LLM : An Open-Source Toolkit for LLM Watermarking. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2024
2024
-
[32]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[33]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[34]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[35]
Yu Meng and Mengzhou Xia and Danqi Chen , booktitle=. Sim. 2024 , url=
2024
-
[36]
The Twelfth International Conference on Learning Representations , year=
Language Model Detectors Are Easily Optimized Against , author=. The Twelfth International Conference on Learning Representations , year=
-
[37]
Beyond Agreement: Diagnosing the Rationale Alignment of Automated Essay Scoring Methods based on Linguistically-informed Counterfactuals
Wang, Yupei and Hu, Renfen and Zhao, Zhe. Beyond Agreement: Diagnosing the Rationale Alignment of Automated Essay Scoring Methods based on Linguistically-informed Counterfactuals. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024
2024
-
[38]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and el al. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[39]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[40]
Fine-tuning Language Models for AI vs Human Generated Text detection
Bahad, Sankalp and Bhaskar, Yash and Krishnamurthy, Parameswari. Fine-tuning Language Models for AI vs Human Generated Text detection. Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024). 2024
2024
-
[41]
MAGE : Machine-generated Text Detection in the Wild
Li, Yafu and Li, Qintong and Cui, Leyang and Bi, Wei and Wang, Zhilin and Wang, Longyue and Yang, Linyi and Shi, Shuming and Zhang, Yue. MAGE : Machine-generated Text Detection in the Wild. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[42]
Intrinsic Dimension Estimation for Robust Detection of
Eduard Tulchinskii and Kristian Kuznetsov and Kushnareva Laida and Daniil Cherniavskii and Sergey Nikolenko and Evgeny Burnaev and Serguei Barannikov and Irina Piontkovskaya , booktitle=. Intrinsic Dimension Estimation for Robust Detection of. 2023 , url=
2023
-
[43]
S em E val-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Wang, Yuxia and Mansurov, Jonibek and Ivanov, Petar and Su, Jinyan and Shelmanov, Artem and Tsvigun, Akim and Mohammed Afzal, Osama and Mahmoud, Tarek and Puccetti, Giovanni and Arnold, Thomas. S em E val-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection. Proceedings of the 18th International Workshop on Semantic Evalu...
2024
-
[44]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. 2019 , howpublished =. 1907.11692 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. 2019 , primaryClass =
2019
-
[46]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[47]
2025 , eprint=
Machine Text Detectors are Membership Inference Attacks , author=. 2025 , eprint=
2025
-
[48]
Boundary detection in mixed
Laida Kushnareva and Tatiana Gaintseva and Dmitry Abulkhanov and Kristian Kuznetsov and German Magai and Eduard Tulchinskii and Serguei Barannikov and Sergey Nikolenko and Irina Piontkovskaya , booktitle=. Boundary detection in mixed. 2024 , url=
2024
-
[49]
Paraphrasing evades detectors of
Kalpesh Krishna and Yixiao Song and Marzena Karpinska and John Frederick Wieting and Mohit Iyyer , booktitle=. Paraphrasing evades detectors of. 2023 , url=
2023
-
[50]
Revisiting the Robustness of Watermarking to Paraphrasing Attacks
Rastogi, Saksham and Pruthi, Danish. Revisiting the Robustness of Watermarking to Paraphrasing Attacks. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024
2024
-
[51]
The Twelfth International Conference on Learning Representations , year=
A Semantic Invariant Robust Watermark for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[52]
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Yuxia Wang and Rui Xing and Jonibek Mansurov and Giovanni Puccetti and Zhuohan Xie and Minh Ngoc Ta and Jiahui Geng and Jinyan Su and Mervat Abassy and Saad El Dine Ahmed and others , year=. Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against. 2502.11614 , primaryClass=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
All That ' s `Human' Is Not Gold: Evaluating Human Evaluation of Generated Text
Clark, Elizabeth and August, Tal and Serrano, Sofia and Haduong, Nikita and Gururangan, Suchin and Smith, Noah A. All That ' s `Human' Is Not Gold: Evaluating Human Evaluation of Generated Text. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing...
2021
-
[54]
Hancock and Mor Naaman , title =
Maurice Jakesch and Jeffrey T. Hancock and Mor Naaman , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , URL =
2023
-
[55]
Chen, Canyu and Shu, Kai , booktitle=. Can. 2024 , url=
2024
-
[56]
2023 , eprint=
Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations , author=. 2023 , eprint=
2023
-
[57]
Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul and Benjamin Bossan and Marian Tietz , howpublished =
-
[58]
2023 , eprint=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
2023
-
[59]
A Unified Approach to Interpreting Model Predictions , url =
Lundberg, Scott M and Lee, Su-In , booktitle =. A Unified Approach to Interpreting Model Predictions , url =
-
[60]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[61]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.