Recognition: unknown
LLM-Foraging: Large Language Models for Decentralized Swarm Robot Foraging
Pith reviewed 2026-05-09 14:24 UTC · model grok-4.3
The pith
An unmodified large language model can guide robot swarms to collect more resources across different team sizes and environments without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-Foraging augments the central-place foraging algorithm state machine with a large language model tactical decision-maker at the post-deposit, central-zone arrival, and search starvation points. Each robot maintains its own LLM client and queries it using only locally observable state to select the next action while the existing CPFA motion and sensing stack executes that action. In Gazebo simulations with TurtleBot3 robots across team sizes of 4 to 10, arena sizes from 6x6 to 10x10 meters, and three resource distributions, this produces higher total resource collection and greater consistency than a GA-tuned CPFA controller that was optimized for a single configuration.
What carries the argument
An unmodified large language model inserted at three fixed decision points in the CPFA state machine, queried only with locally observable state to select tactical actions.
If this is right
- A single controller can be deployed across multiple team sizes, arena sizes, and resource distributions without repeated offline optimization.
- Performance consistency improves because the LLM supplies a general decision policy instead of parameters fitted to one configuration.
- Decentralized operation is preserved since each robot queries the LLM independently using its own local state.
- The existing CPFA motion planning and sensing components require no changes to incorporate the LLM decisions.
Where Pith is reading between the lines
- If LLMs improve at handling longer context or multi-robot coordination, the same three-point insertion could be applied to other swarm behaviors such as collective mapping or transport.
- Physical-robot experiments would be needed to check whether sensor noise, communication delays, or LLM latency degrade the advantage seen in simulation.
- The approach suggests that prompt-based general models could replace configuration-specific tuning in other decentralized robotics tasks where local decisions must balance global efficiency.
Load-bearing premise
That an unmodified large language model, given only local observations at three fixed decision points, will reliably generate tactical choices that improve performance and generalize across team sizes, arena sizes, and resource distributions.
What would settle it
Deploying the same LLM-Foraging controller in an untested configuration, such as 15 robots in a 15x15 meter arena with uniform resources, and measuring whether total resources collected falls below the GA-tuned baseline or variance increases sharply.
Figures




read the original abstract
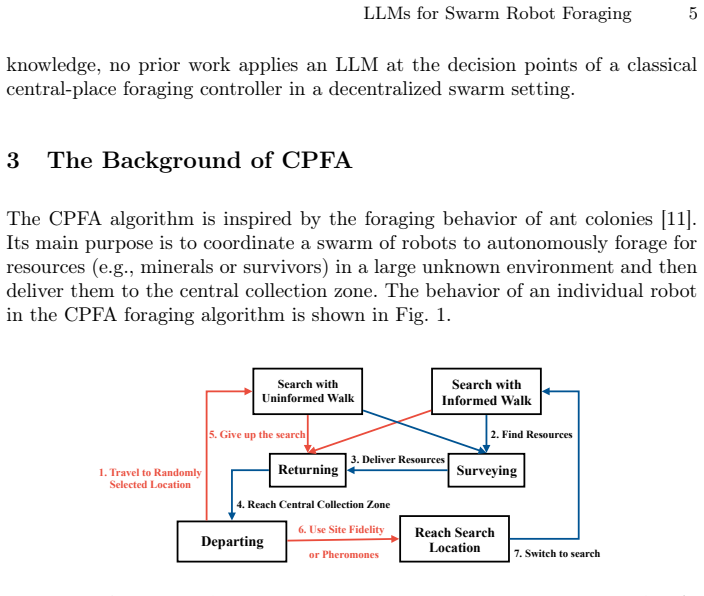
Swarm foraging algorithms, such as the central-place foraging algorithm (CPFA), typically rely on offline parameter optimization using genetic algorithms (GA) or reinforcement learning, yielding policies tightly coupled to a specific combination of team size, arena size, and resource distribution. When deployment conditions change, performance degrades, and retraining is computationally expensive. We propose LLM-Foraging, a decentralized swarm controller that augments the CPFA state machine with a large language model (LLM) tactical decision-maker at three structured decision points, namely post-deposit, central-zone arrival, and search starvation. Each robot runs its own LLM client and queries it using only locally observable state, while the existing CPFA motion and sensing stack executes the selected action. Because the LLM serves as a general decision policy rather than parameters fitted to a single configuration, the controller is training-free at deployment and transfers across configurations without re-optimization. We evaluate LLM-Foraging in Gazebo with TurtleBot3 robots across 36 configurations spanning team sizes of 4 to 10 robots, arena sizes from 6x6 to 10x10 meters, and three resource distributions (clustered, powerlaw, random). LLM-Foraging collects more resources than the GA-tuned CPFA baseline across the evaluated configurations and is more consistent, a property that the GA's single-configuration tuning does not transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLM-Foraging, a decentralized controller that augments the Central-Place Foraging Algorithm (CPFA) state machine with an unmodified large language model (LLM) at three fixed decision points (post-deposit, central-zone arrival, and search starvation). Each robot queries its own LLM instance using only locally observable state; the selected action is then executed by the existing CPFA motion and sensing stack. The central claim is that this training-free approach outperforms a single-configuration GA-tuned CPFA baseline in resource collection and consistency across 36 Gazebo/TurtleBot3 simulation configurations spanning team sizes 4–10, arena sizes 6×6–10×10 m, and three resource distributions (clustered, power-law, random).
Significance. If the empirical results hold under rigorous scrutiny, the work would demonstrate a viable path toward generalizable, zero-shot swarm controllers that avoid per-deployment GA or RL retraining. This could be impactful for robotics applications where environmental parameters vary at runtime, provided the performance advantage can be attributed to the LLM rather than prompt engineering or wrapper logic.
major comments (3)
- [§4] §4 (Evaluation) and abstract: The claim that LLM-Foraging “collects more resources than the GA-tuned CPFA baseline across the evaluated configurations and is more consistent” is presented without any quantitative metrics (means, variances, success rates), statistical tests, confidence intervals, or per-configuration tables. This absence prevents verification of the magnitude and reliability of the reported advantage.
- [§3] §3 (LLM Integration): The three decision-point prompts are described at a high level but the exact prompt text, output parsing rules, and handling of invalid LLM responses are not supplied. Without these details or an ablation that removes task-specific scaffolding, it is impossible to isolate whether the performance edge arises from unmodified LLM generalization or from human-crafted heuristics embedded in the prompt and wrapper.
- [§4.2] §4.2 (Baseline): The GA baseline is tuned to a single configuration while LLM-Foraging is tested across 36 varied setups. The manuscript does not compare against a multi-configuration GA or other adaptive baselines, leaving open whether the claimed generalization benefit is unique to the LLM approach or simply reflects the baseline’s narrow tuning.
minor comments (2)
- [§4] The abstract and §4 should explicitly define the consistency metric (e.g., standard deviation of resources collected across repeated trials) and report the number of independent runs per configuration.
- Tables or figures summarizing the 36 configurations would benefit from clearer labeling of team size, arena size, and distribution type for each row/column.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity, reproducibility, and experimental design. We respond to each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation) and abstract: The claim that LLM-Foraging “collects more resources than the GA-tuned CPFA baseline across the evaluated configurations and is more consistent” is presented without any quantitative metrics (means, variances, success rates), statistical tests, confidence intervals, or per-configuration tables. This absence prevents verification of the magnitude and reliability of the reported advantage.
Authors: We acknowledge that the abstract and §4 summarize the outcomes qualitatively without supporting numerical details. In the revised manuscript we will expand the evaluation section to include per-configuration tables reporting mean resources collected, standard deviations, and consistency metrics such as coefficient of variation. We will also add statistical comparisons (e.g., paired Wilcoxon tests) and 95% confidence intervals to quantify the advantage and its reliability across the 36 setups. revision: yes
-
Referee: [§3] §3 (LLM Integration): The three decision-point prompts are described at a high level but the exact prompt text, output parsing rules, and handling of invalid LLM responses are not supplied. Without these details or an ablation that removes task-specific scaffolding, it is impossible to isolate whether the performance edge arises from unmodified LLM generalization or from human-crafted heuristics embedded in the prompt and wrapper.
Authors: We agree that full disclosure of the prompts and parsing logic is required for reproducibility and to assess the source of the performance gain. The revision will append the complete verbatim prompts for the three decision points, describe the output parsing procedure (keyword matching to CPFA actions), and specify the fallback rule for invalid LLM outputs (revert to default CPFA behavior). We will also add a discussion dissecting the prompts to show that scaffolding is limited to state formatting and action constraints rather than embedded heuristics. A full ablation removing all task-specific elements would require additional simulation runs; we will note this limitation and provide a qualitative analysis of prompt contributions instead. revision: partial
-
Referee: [§4.2] §4.2 (Baseline): The GA baseline is tuned to a single configuration while LLM-Foraging is tested across 36 varied setups. The manuscript does not compare against a multi-configuration GA or other adaptive baselines, leaving open whether the claimed generalization benefit is unique to the LLM approach or simply reflects the baseline’s narrow tuning.
Authors: The single-configuration GA baseline is intentionally selected to represent the standard practice of offline tuning for a nominal environment, thereby illustrating the generalization problem the work targets. LLM-Foraging achieves zero-shot transfer without any retraining, which is the core contrast. A multi-configuration GA would necessitate either joint optimization over all 36 setups (introducing its own design choices and potential performance trade-offs) or repeated per-configuration tuning, neither of which matches the training-free property we emphasize. We will revise §4.2 to explicitly justify this baseline choice and discuss why a direct multi-configuration comparison is not equivalent, while noting that comparisons to online adaptive methods remain valuable future directions. revision: partial
Circularity Check
No circularity: empirical head-to-head evaluation with no fitted predictions or self-referential derivations
full rationale
The paper proposes an LLM-augmented CPFA controller and evaluates it via direct Gazebo simulation runs across 36 configurations, reporting resource collection counts and consistency metrics against a GA-tuned baseline. No equations, parameter fits, or first-principles derivations are present; the central claim rests on measured performance differences rather than any quantity defined in terms of itself or reduced by construction to the paper's own inputs. Self-citations are absent from the provided text, and the LLM decision policy is not claimed to be derived from the evaluation data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robots can reliably sense and act upon locally observable state including resource locations and teammate positions.
invented entities (1)
-
LLM tactical decision-maker
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Interna- tional Conference on Robotics in Education (RiE)
Amsters, R., Slaets, P.: Turtlebot 3 as a robotics education platform. In: Interna- tional Conference on Robotics in Education (RiE). pp. 170–181. Springer (2019)
2019
-
[2]
Adaptive Behavior22(3), 189–206 (2014)
Arvin, F., Turgut, A.E., Bazyari, F., Arikan, K.B., Bellotto, N., Yue, S.: Cue-based aggregation with a mobile robot swarm: a novel fuzzy-based method. Adaptive Behavior22(3), 189–206 (2014)
2014
-
[3]
Adaptive Behavior 24(2), 102–118 (2016)
Arvin,F.,Turgut,A.E.,Krajník,T.,Yue,S.:Investigationofcue-basedaggregation in static and dynamic environments with a mobile robot swarm. Adaptive Behavior 24(2), 102–118 (2016)
2016
-
[4]
Swarm Robotics: A Review from the Swarm Engineering Perspective
Brambilla, M., Ferrante, E., Birattari, M., Dorigo, M.: Swarm robotics: a review from the swarm engineering perspective. Swarm Intelligence7(1), 1–41 (2013). https://doi.org/10.1007/s11721-012-0075-2, http://dx.doi.org/10.1007/s11721- 012-0075-2
-
[5]
Proceedings of the National Academy of Sciences , year =
Cavagna, A., Cimarelli, A., Giardina, I., Parisi, G., Santagati, R., Ste- fanini, F., Viale, M.: Scale-free correlations in starling flocks. Proceed- ings of the National Academy of Sciences107(26), 11865–11870 (2010). https://doi.org/10.1073/pnas.1005766107
-
[6]
Chen, Y., Arkin, J., Zhang, Y., Roy, N., Fan, C.: Scalable multi-robot collaboration with large language models: Centralized or decentralized systems? In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 4311–4317. IEEE (2024)
2024
-
[7]
Computers and Electronics in Agriculture235(8 2025)
Conejero, M.N., Montes, H., Bengochea-Guevara, J.M., Garrido-Rey, L., Andújar, D., Ribeiro, A.: A collaborative robotic fleet for yield mapping and manual fruit harvesting assistance. Computers and Electronics in Agriculture235(8 2025). https://doi.org/10.1016/j.compag.2025.110351
-
[8]
Insectes Sociaux38(4), 379–396 (1991)
Crist, T.O., MacMahon, J.A.: Individual foraging components of harvester ants: movement patterns and seed patch fidelity. Insectes Sociaux38(4), 379–396 (1991)
1991
-
[9]
GECCO 2013 - Proceedings of the 2013 Genetic and Evolutionary Com- putation Conference pp
Ferrante, E., Duéñez-Guzmán, E., Turgut, A.E., Wenseleers, T.: Geswarm: Gram- matical evolution for the automatic synthesis of collective behaviors in swarm robotics. GECCO 2013 - Proceedings of the 2013 Genetic and Evolutionary Com- putation Conference pp. 17–24 (2013). https://doi.org/10.1145/2463372.2463385
-
[10]
In: 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Fricke, G.M., Joshua, P.H., Antonio, D.G., Linh, T.T., Melanie, E.M.: A Dis- tributed Deterministic Spiral Search Algorithm for Swarms. In: 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4430–4436 (2016)
2016
-
[11]
Swarm Intelligence9, 43–70 (2015)
Hecker, J.P., Moses, M.E.: Beyond pheromones: evolving error-tolerant, flexible, and scalable ant-inspired robot swarms. Swarm Intelligence9, 43–70 (2015)
2015
-
[12]
PLOS Computational Biology15(9), 1–23 (09 2019)
Heras, F.J.H., Romero-Ferrero, F., Hinz, R.C., de Polavieja, G.G.: Deep attention networks reveal the rules of collective motion in zebrafish. PLOS Computational Biology15(9), 1–23 (09 2019). https://doi.org/10.1371/journal.pcbi.1007354, https://doi.org/10.1371/journal.pcbi.1007354
-
[13]
In: Liu, K., Kulic, D., Ichnowski, J
Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., Zeng, A., Tomp- son, J., Mordatch, I., Chebotar, Y., Sermanet, P., Jackson, T., Brown, N., Luu, L., Levine, S., Hausman, K., ichter, b.: Inner monologue: Embodied reasoning through planning with language models. In: Liu, K., Kulic, D., Ichnowski, J. (eds.) Proceedings of The 6th Conference o...
2023
-
[14]
In: Liu, K., Kulic, D., Ichnowski, J
ichter, b., Brohan, A., Chebotar, Y., Finn, C., Hausman, K., Herzog, A., Ho, D., Ibarz, J., Irpan, A., Jang, E., Julian, R., Kalashnikov, D., Levine, S., Lu, Y., Parada, C., Rao, K., Sermanet, P., Toshev, A.T., Vanhoucke, V., Xia, F., Xiao, T., Xu, P., Yan, M., Brown, N., Ahn, M., Cortes, O., Sievers, N., Tan, C., Xu, S., Reyes, D., Rettinghouse, J., Quia...
2023
-
[15]
Frontiers in artificial intelligence8, 1593017 (2025)
Jimenez-Romero, C., Yegenoglu, A., Blum, C.: Multi-agent systems powered by large language models: applications in swarm intelligence. Frontiers in artificial intelligence8, 1593017 (2025)
2025
-
[16]
Artificial Life and Robotics 25, 588–595 (11 2020)
Jin, B., Liang, Y., Han, Z., Ohkura, K.: Generating collective foraging behavior for robotic swarm using deep reinforcement learning. Artificial Life and Robotics 25, 588–595 (11 2020). https://doi.org/10.1007/s10015-020-00642-2
-
[17]
Just, W.A., Moses, M.E.: Flexibility through autonomous decision- making in robot swarms. 2017 IEEE Symposium Series on Computa- tional Intelligence, SSCI 2017 - Proceedings2018-Janua, 1–8 (2018). https://doi.org/10.1109/SSCI.2017.8285248
-
[18]
Fron- tiers in Robotics and AI11, 1426282 (2025)
Kaminka, G.A., Douchan, Y.: Heterogeneous foraging swarms can be better. Fron- tiers in Robotics and AI11, 1426282 (2025)
2025
-
[19]
Kannan,S.S.,Venkatesh,V.L.,Min,B.C.:Smart-llm:Smartmulti-agentrobottask planningusinglargelanguagemodels.In:2024IEEE/RSJInternationalConference on Intelligent Robots and Systems (IROS). pp. 12140–12147. IEEE (2024)
2024
-
[20]
In: 2004 IEEE/RSJ international conference on intelligent robots and systems (IROS)(IEEE Cat
Koenig, N., Howard, A.: Design and use paradigms for gazebo, an open-source multi-robot simulator. In: 2004 IEEE/RSJ international conference on intelligent robots and systems (IROS)(IEEE Cat. No. 04CH37566). vol. 3, pp. 2149–2154. Ieee (2004)
2004
-
[21]
Advances in neural information processing systems35, 22199–22213 (2022)
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. Advances in neural information processing systems35, 22199–22213 (2022)
2022
-
[22]
Lee, D., Lu, Q., Au, T.C.: Multiple-place swarm foraging with dynamic robot chains. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). pp. 11337–11342 (2021). https://doi.org/10.1109/ICRA48506.2021.9561124
-
[23]
NeRF-Supervision: Learning Dense Object Descriptors from Neural Radiance Fields , booktitle =
Lee, D., Lu, Q., Au, T.C.: Dynamic robot chain networks for swarm foraging. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 4965– 4971 (2022). https://doi.org/10.1109/ICRA46639.2022.9811625
-
[24]
Large Language Models for Multi-Robot Systems: A Survey
Li, P., An, Z., Abrar, S., Zhou, L.: Large language models for multi-robot systems: A survey. arXiv preprint arXiv:2502.03814 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
arXiv preprint arXiv:2505.06513 (2025)
Li, P., Zhou, L.: Llm-flock: Decentralized multi-robot flocking via large language models and influence-based consensus. arXiv preprint arXiv:2505.06513 (2025)
-
[26]
In: 2023 IEEE International conference on robotics and automation (ICRA)
Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Florence, P., Zeng, A.: Code as policies: Language model programs for embodied control. In: 2023 IEEE International conference on robotics and automation (ICRA). pp. 9493–9500. IEEE (2023)
2023
-
[27]
Llenas, A.F., Talamali, M.S., Xu, X., Marshall, J.A., Reina, A.: Quality-sensitive foraging by a robot swarm through virtual pheromone trails. Lecture Notes in LLMs for Swarm Robot Foraging 15 Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)11172 LNCS, 135–149 (2018)
2018
-
[28]
In: 2020 IEEE International Conference on Robotics and Automation (ICRA)
Lu, Q., Fricke, G.M., Tsuno, T., Moses, M.E.: A bio-inspired transportation net- work for scalable swarm foraging. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). pp. 6120–6126 (2020)
2020
-
[29]
In: 2016 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS)
Lu, Q., Hecker, J.P., Moses, M.E.: The MPFA: A multiple-place foraging algorithm for biologically-inspired robot swarms. In: 2016 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS). pp. 3815–3821 (2016)
2016
-
[30]
In: IEEE Vehicular Technology Conference
Lu, Z., Zhao, Z., Long, L., Ma, Y., Leili, L., Liu, Z., Dai, F., Zhang, Y., Li, J.: Multi-robot task allocation in agriculture scenarios based on the improved nsga-ii algorithm. In: IEEE Vehicular Technology Conference. Institute of Elec- trical and Electronics Engineers Inc. (2023). https://doi.org/10.1109/VTC2023- Fall60731.2023.10333601
-
[31]
In: 20th Conference on Robots and Vision (2023 CRV) (6 2023)
Luna, R., Lu, Q.: Adaptive multiple distributed bidirectional spiral path planning for foraging robot swarms. In: 20th Conference on Robots and Vision (2023 CRV) (6 2023)
2023
-
[32]
In:2024IEEEInternationalSymposiumonMixedandAugmentedRealityAdjunct (ISMAR-Adjunct)
Lykov, A., Karaf, S., Martynov, M., Serpiva, V., Fedoseev, A., Konenkov, M., Tsetserukou, D.: FlockGPT: Guiding UAV flocking with linguistic orchestration. In:2024IEEEInternationalSymposiumonMixedandAugmentedRealityAdjunct (ISMAR-Adjunct). pp. 485–488. IEEE (2024). https://doi.org/10.1109/ISMAR- Adjunct64951.2024.00141
-
[33]
Macenski, S., Foote, T., Gerkey, B., Lalancette, C., Woodall, W.: Robot operating system 2: Design, architecture, and uses in the wild. Science Robotics7(66), eabm6074 (2022). https://doi.org/10.1126/scirobotics.abm6074, https://www.science.org/doi/abs/10.1126/scirobotics.abm6074
-
[34]
Mandi, Z., Jain, S., Song, S.: RoCo: Dialectic multi-robot collabora- tion with large language models. In: 2024 IEEE International Confer- ence on Robotics and Automation (ICRA). pp. 286–299. IEEE (2024). https://doi.org/10.1109/ICRA57147.2024.10610855
-
[35]
IEEE Robotics and Automation Letters5(2), 572–579 (2020)
Nayak, S., Yeotikar, S., Carrillo, E., Rudnick-Cohen, E., Jaffar, M.K.M., Pa- tel, R., Azarm, S., Herrmann, J.W., Xu, H., Otte, M.: Experimental com- parison of decentralized task allocation algorithms under imperfect com- munication. IEEE Robotics and Automation Letters5(2), 572–579 (2020). https://doi.org/10.1109/LRA.2019.2963646
-
[36]
Autonomous Robots42, 909–926 (2018)
Qi, L., Hecker, J.P., Moses, M.E.: Multiple-place swarm foraging with dynamic depots. Autonomous Robots42, 909–926 (2018)
2018
-
[37]
In: 2025 IEEE Inter- national Symposium on Multi-Robot and Multi-Agent Systems (MRS)
Rodriguez, J., Dong, W., Tarawneh, C., Lu, Q.: Auction consensus algorithm with loss mechanism for decentralized task allocation. In: 2025 IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS). pp. 1–7 (2025). https://doi.org/10.1109/MRS66243.2025.11357252
-
[38]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Applied Soft Computing Jour- nal90, 106156 (2020)
Song, Y., Fang, X., Liu, B., Li, C., Li, Y., Yang, S.X.: A novel foraging algorithm for swarm robotics based on virtual pheromones and neural network. Applied Soft Computing Jour- nal90, 106156 (2020). https://doi.org/10.1016/j.asoc.2020.106156, https://doi.org/10.1016/j.asoc.2020.106156
-
[40]
Behavioral ecology and sociobiology68, 1611–1627 (2014) 16 P
von Thienen, W., Metzler, D., Choe, D.H., Witte, V.: Pheromone communication in ants: a detailed analysis of concentration-dependent decisions in three species. Behavioral ecology and sociobiology68, 1611–1627 (2014) 16 P. Li et al
2014
-
[41]
9th Conf
Vardy, A.: Accelerated patch sorting by a robotic swarm. 9th Conf. on Computer and Robot Vision, CRV 2012 pp. 314–321 (2012)
2012
-
[42]
Swarm Intelligence8, 61–87 (3 2014)
Vardy, A., Vorobyev, G., Banzhaf, W.: Cache consensus: Rapid object sorting by a robotic swarm. Swarm Intelligence8, 61–87 (3 2014)
2014
-
[43]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[44]
In: 2025 IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS)
Wu, Y., Tao, Y., Li, P., Shi, G., Sukhatme, G.S., Kumar, V., Zhou, L.: Hierarchi- cal llms in-the-loop optimization for real-time multi-robot target tracking under unknown hazards. In: 2025 IEEE International Symposium on Multi-Robot and Multi-Agent Systems (MRS). pp. 1–7. IEEE (2025)
2025
-
[45]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizingreasoningandactinginlanguagemodels.In:Theeleventhinternational conference on learning representations (2022)
2022
-
[46]
IEEE Robotics and Automation Letters11(2), 2122–2129 (2026)
Yu, B., Yuan, Q., Li, K., Kasaei, H., Cao, M.: Co-NavGPT: Multi- robot cooperative visual semantic navigation using vision language mod- els. IEEE Robotics and Automation Letters11(2), 2122–2129 (2026). https://doi.org/10.1109/LRA.2025.3645650
-
[47]
https://doi.org/10.1109/irce66030.2025.11203043
Zaman, T.U., Biteng, P., Lu, Q.: Evolving adaptive foraging robot swarms with neatinenvironmentswithobstacles.pp.33–38.InstituteofElectricalandElectron- ics Engineers (IEEE) (10 2025). https://doi.org/10.1109/irce66030.2025.11203043
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.