The grip of grammar on meaning uncertainty: cross-linguistic evidence, neural correlates, and clinical relevance
Pith reviewed 2026-05-09 14:06 UTC · model grok-4.3
The pith
Grammar reduces uncertainty in word meanings across 20 languages, with corresponding brain activity and selective clinical disruptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
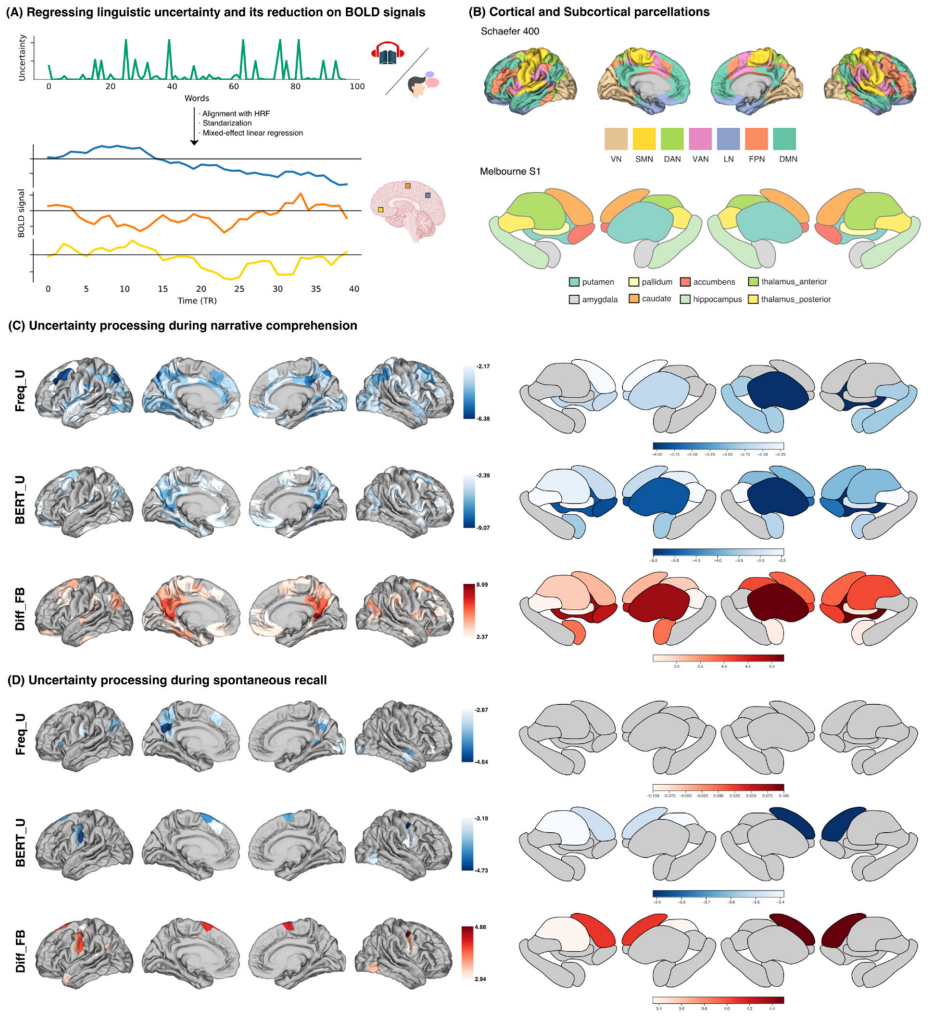
Grammar compresses meaning uncertainty cross-linguistically, reflected in brain activity and selectively disrupted in disorders. This was measured as the relative difference between non-contextual surprisal from lexical frequency and contextual surprisal from grammar-sensitive models. In narratives from 20 languages, the contextual surprisal reduced the frequency-based one, tracking word order reversal costs and scaling with richer lexis and optimal dependency structures. During fMRI, this reduction explained BOLD activity in comprehension and production regions, and it was attenuated in aphasia, dementia, and schizophrenia.
What carries the argument
The relative difference between non-contextual surprisal from lexical frequency and contextual surprisal estimated by grammar-sensitive models, which quantifies grammar's role in reducing meaning uncertainty.
If this is right
- Contextual surprisal reduction closely tracks the cost of reversing word order in sentences.
- This reduction scales with richer, non-redundant vocabulary organized by complex but optimal dependency structures.
- Surprisal and its reduction explain BOLD activity in overlapping but distinct brain regions for comprehension and production.
- Uncertainty reduction via grammar is significantly attenuated in aphasia, dementia, and schizophrenia, but intact in disorders without primary language deficits.
Where Pith is reading between the lines
- If grammar's compression of uncertainty is foundational, it may explain cross-linguistic preferences for certain syntactic patterns.
- This could lead to new ways of modeling language acquisition or evolution based on uncertainty minimization.
- Clinically, it suggests potential for assessing language disorders by measuring uncertainty reduction rather than traditional tests.
- Connections might exist to how other cognitive systems handle uncertainty, like in decision making or perception.
Load-bearing premise
The difference between surprisal based on word frequency alone and surprisal from models using grammar actually captures grammar's unique contribution without being influenced much by meaning or other factors.
What would settle it
Observing no reduction in uncertainty from grammar in a new set of languages or finding that brain activity correlations disappear when controlling for other variables.
Figures



read the original abstract
Isolated word meanings are inherently uncertain. This uncertainty reduces when they are combined and anchored in context. We propose that grammar compresses meaning uncertainty cross-linguistically, which is reflected in brain and selectively disrupted in disorders. Compression was operationalized as the relative difference between non-contextual surprisal estimated from lexical frequency, and contextual surprisal from grammar-sensitive models. In narratives from 20 languages, contextual surprisal reduced frequency-based surprisal. This reduction closely tracked the surprisal cost of reversing word order, and scaled with richer, non-redundant lexis as organized by more complex but optimal dependency structure. During fMRI, surprisal and its reduction explained BOLD activity for comprehension and production in overlapping but distinct regions. Uncertainty reduction was significantly attenuated in aphasia, dementia, and schizophrenia, but remained intact where primary deficit is not language. These findings position uncertainty reduction via grammar as a foundational concept that illuminates principles, brain basis, and disruptions of language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grammar compresses meaning uncertainty cross-linguistically. This is operationalized as the relative reduction from non-contextual surprisal (lexical frequency) to contextual surprisal (grammar-sensitive models). Evidence includes this reduction in narratives from 20 languages, its tracking of word-order reversal costs and scaling with dependency complexity, overlapping fMRI BOLD correlates during comprehension and production, and selective attenuation in aphasia, dementia, and schizophrenia (but not non-language disorders).
Significance. If the attribution to grammar holds after appropriate controls, the work would provide a unifying information-theoretic account linking grammatical structure to uncertainty reduction, with direct neural and clinical implications. The cross-linguistic scope and multi-method approach (behavioral, neuroimaging, patient data) would strengthen its potential impact in computational linguistics and cognitive neuroscience.
major comments (1)
- [Abstract] Abstract and operationalization section: the central metric (lexical-frequency surprisal minus contextual surprisal from grammar-sensitive models) does not isolate grammar's contribution. Models trained on full natural text encode semantic, pragmatic, and lexical co-occurrences in addition to syntax; without explicit baselines (e.g., semantics-only embeddings or purely syntactic parsers) or controls holding semantics constant while varying structure, the reported reductions, correlations with reversal cost and dependency complexity, fMRI overlaps, and clinical selectivity could be driven by non-grammatical factors. This is load-bearing for every downstream claim.
minor comments (2)
- [Results] Results section: directional effects are stated but quantitative statistics, sample sizes per language, model architectures, multiple-comparison corrections, and effect sizes are not reported in the provided abstract or summary; these details are required for reproducibility and evaluation of the strength of the cross-linguistic and clinical findings.
- [Methods] The manuscript should clarify the exact definition and training data of the 'grammar-sensitive models' (e.g., whether they are standard LMs or syntax-augmented) to allow readers to assess the degree of circularity in the surprisal subtraction.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which identify a key methodological issue in attributing our findings specifically to grammar. We address this concern directly below and outline revisions to strengthen the isolation of grammatical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and operationalization section: the central metric (lexical-frequency surprisal minus contextual surprisal from grammar-sensitive models) does not isolate grammar's contribution. Models trained on full natural text encode semantic, pragmatic, and lexical co-occurrences in addition to syntax; without explicit baselines (e.g., semantics-only embeddings or purely syntactic parsers) or controls holding semantics constant while varying structure, the reported reductions, correlations with reversal cost and dependency complexity, fMRI overlaps, and clinical selectivity could be driven by non-grammatical factors. This is load-bearing for every downstream claim.
Authors: We agree that models trained on natural text capture semantic, pragmatic, and lexical co-occurrence information in addition to syntax, so the contextual surprisal estimates reflect multiple levels of structure. Our core operationalization quantifies the reduction from non-contextual (frequency-based) surprisal to contextual surprisal, thereby measuring the benefit provided by context as it occurs in natural language, where grammar organizes that context. The manuscript already includes targeted evidence linking the reduction to grammar: the reduction closely tracks the surprisal cost of word-order reversals (a direct syntactic manipulation) and scales with dependency complexity (a syntactic measure of structure). These correlations would be unexpected if non-grammatical factors were the sole drivers. Nevertheless, to address the referee's concern more explicitly, we will add control analyses in the revised manuscript, including (i) semantics-only baselines using static embeddings without sequential context and (ii) purely syntactic models such as dependency parsers that supply structure while minimizing semantic content. These controls will be applied to the same 20-language narratives and used to re-evaluate the fMRI and clinical results. We view this as a necessary strengthening of the claims rather than a fundamental flaw in the current design. revision: yes
Circularity Check
No significant circularity; empirical measurements remain independent of inputs
full rationale
The paper explicitly operationalizes compression as the difference between unigram frequency surprisal and contextual model surprisal, then reports empirical findings that this difference tracks word-order reversal costs, scales with dependency structure, overlaps with fMRI activity, and attenuates selectively in certain disorders. These downstream correlations and clinical contrasts are not forced by the operationalization itself; they constitute separate measurements on the same narratives, brain data, and patient groups. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core attribution, and the models are treated as standard tools rather than fitted parameters renamed as predictions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lexical-frequency surprisal provides a valid baseline for non-contextual meaning uncertainty.
- domain assumption Grammar-sensitive language models capture syntactic structure without being dominated by semantic or lexical factors.
Reference graph
Works this paper leans on
-
[1]
Olness, G. S. & Ulatowska, H. K. Personal Narratives in Aphasia: Coherence in the Context of Use. Aphasiology 25, 1393–1413 (2011)
work page 2011
-
[2]
Minga, J., Johnson, M., Blake, M. L., Fromm, D. & MacWhinney, B. Making Sense of Right Hemisphere Discourse Using RHDBank. Top Lang Disord 41, 99–122 (2021)
work page 2021
-
[3]
Rezaii, N., Mahowald, K., Ryskin, R., Dickerson, B. & Gibson, E. A syntax –lexicon trade-off in language production. Proceedings of the National Academy of Sciences 119, e2120203119 (2022)
work page 2022
-
[4]
Luz, S., Haider, F., Fuente, S. de la, Fromm, D. & MacWhinney, B. Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge. in Interspeech 2020 2172–2176 (ISCA, 2020). doi:10.21437/Interspeech.2020-2571
-
[5]
Alonso-Sánchez, M. F., Limongi, R., Gati, J. & Palaniyappan, L. Language network self -inhibition and semantic similarity in first -episode schizophrenia: A computational -linguistic and effective connectivity approach. Schizophrenia Research https://doi.org/10.1016/j.schres.2022.04.007 (2022) doi:10.1016/j.schres.2022.04.007
-
[6]
He, R. et al. Navigating the semantic space: Unraveling the structure of meaning in psychosis using different computational language models. Psychiatry Research 333, 115752 (2024)
work page 2024
-
[7]
F., Sholomskas, D., Thompson, D., Belanger, A
Leckman, J. F., Sholomskas, D., Thompson, D., Belanger, A. & Weissman, M. M. Best Estimate of Lifetime Psychiatric Diagnosis: A Methodological Study. Archives of General Psychiatry 39, 879–883 (1982)
work page 1982
-
[8]
Liddle, P. F. et al. Thought and Language Index: an instrument for assessing thought and language in schizophrenia. The British Journal of Psychiatry 181, 326–330 (2002)
work page 2002
-
[9]
Opler, M. G., Yang, L. H., Caleo, S. & Alberti, P. Statistical validation of the criteria for symptom remission in schizophrenia: Preliminary findings. BMC Psychiatry 7, 35 (2007)
work page 2007
-
[10]
Schneider, K. et al. Syntactic complexity and diversity of spontaneous speech production in schizophrenia 40 spectrum and major depressive disorders. Schizophr 9, 1–10 (2023)
work page 2023
-
[11]
Tustison, N. J. et al. N4ITK: Improved N3 Bias Correction. IEEE Transactions on Medical Imaging 29, 1310–1320 (2010)
work page 2010
-
[12]
Avants, B. B., Epstein, C. L., Grossman, M. & Gee, J. C. Symmetric diffeomorphic image registration with cross-correlation: Evaluating automated labeling of elderly and neurodegenerative brain. Medical Image Analysis 12, 26–41 (2008)
work page 2008
-
[13]
Zhang, Y., Brady, M. & Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Transactions on Medical Imaging 20, 45–57 (2001)
work page 2001
-
[14]
Dale, A. M., Fischl, B. & Sereno, M. I. Cortical Surface -Based Analysis: I. Segmentation and Surface Reconstruction. NeuroImage 9, 179–194 (1999)
work page 1999
-
[15]
Klein, A. et al. Mindboggling morphometry of human brains. PLOS Computational Biology 13, e1005350 (2017)
work page 2017
-
[16]
Fonov, V., Evans, A., McKinstry, R., Almli, C. & Collins, D. Unbiased nonlinear average age -appropriate brain templates from birth to adulthood. NeuroImage 47, Supplement 1, S102 (2009)
work page 2009
-
[17]
Jenkinson, M., Bannister, P., Brady, M. & Smith, S. Improved Optimization for the Robust and Accurate Linear Registration and Motion Correction of Brain Images. NeuroImage 17, 825–841 (2002)
work page 2002
-
[18]
Greve, D. N. & Fischl, B. Accurate and robust brain image alignment using boundary -based registration. NeuroImage 48, 63–72 (2009)
work page 2009
-
[19]
Power, J. D. et al. Methods to detect, characterize, and remove motion artifact in resting state fMRI. NeuroImage 84, 320–341 (2014)
work page 2014
- [20]
-
[21]
Satterthwaite, T. D. et al. An improved framework for confound regression and filtering for control of motion artifact in the preprocessing of resting-state functional connectivity data. NeuroImage 64, 240–256 (2013)
work page 2013
-
[22]
Lanczos, C. Evaluation of Noisy Data. Journal of the Society for Industrial and Applied Mathematics Series B Numerical Analysis 1, 76–85 (1964)
work page 1964
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.