Recognition: unknown
Perturb and Correct: Post-Hoc Ensembles using Affine Redundancy
Pith reviewed 2026-05-09 14:24 UTC · model grok-4.3
The pith
Random perturbations to hidden layers plus least-squares affine correction produce multiple predictors from one pretrained model that agree exactly on calibration data but can diverge elsewhere.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Perturb-and-Correct constructs multiple predictors from a single pretrained network by adding random perturbations to hidden layers and then applying a least-squares correction in the subsequent affine layer. The post-correction residual remains controlled near the calibration distribution through a leverage term, while the first-order sensitivity of the corrected outputs increases as inputs move away from the calibration geometry. This produces predictors that agree exactly on calibration data yet remain free to disagree away from it, turning overparameterization into a source of epistemic diversity without additional training.
What carries the argument
The perturb-and-correct procedure, which combines random hidden-layer perturbations with a least-squares correction in the following affine layer to enforce exact agreement on calibration points while permitting divergence outside that set.
Load-bearing premise
Random hidden-layer perturbations followed by least-squares affine correction will preserve in-distribution accuracy while allowing the predictors to disagree usefully on out-of-distribution inputs.
What would settle it
Direct measurement of whether the corrected predictors retain the base model's in-distribution accuracy while showing increased disagreement or improved out-of-distribution detection metrics on shifted test sets.
Figures


read the original abstract
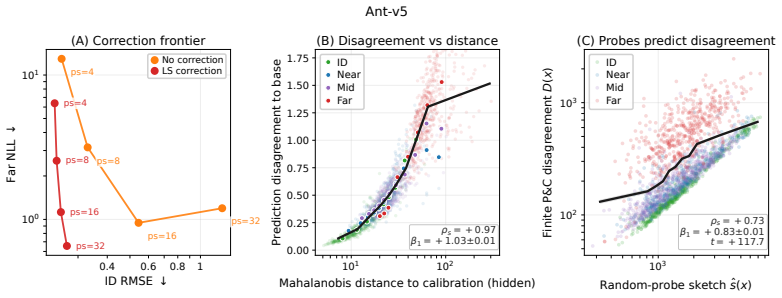
Models that are indistinguishable on in-distribution data can behave very differently under distribution shift. We introduce Perturb-and-Correct (P&C), a post-hoc method for constructing epistemically diverse predictors from a single pretrained network. P&C applies random hidden layer perturbations with a least-squares correction in the subsequent affine layer, producing predictors that agree on calibration data while remaining free to disagree away from it. We analyze this mechanism through the post-correction residual and its first-order sensitivity: the residual is controlled near the calibration distribution by a leverage term, while corrected sensitivity grows as inputs deviate from the calibration geometry. Empirically, P&C achieves a strong ID/OOD tradeoff across MuJoCo dynamics prediction and CIFAR-10 OOD detection, matching or outperforming standard post-hoc baselines while requiring only a single pretrained model. Our findings highlight the potential in further exploiting overparameterization as a strength of deep learning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Perturb-and-Correct (P&C), a post-hoc method to construct ensembles of epistemically diverse predictors from a single pretrained network. Random perturbations are applied to hidden layers, followed by a least-squares affine correction in the subsequent layer to enforce exact agreement on a calibration set while permitting disagreement away from it. The authors analyze the mechanism via the post-correction residual (controlled by a leverage term near calibration) and first-order sensitivity (which grows with deviation from calibration geometry). Empirically, P&C is shown to achieve competitive ID/OOD tradeoffs on MuJoCo dynamics prediction and CIFAR-10 OOD detection, matching or exceeding standard post-hoc baselines.
Significance. If the central empirical claim holds and ID performance is preserved, P&C would provide an efficient way to exploit overparameterization for uncertainty estimation and robustness without training multiple models or incurring high inference cost. The analysis linking residual control to leverage and sensitivity offers a concrete, testable mechanism that could generalize beyond the reported tasks.
major comments (2)
- [§3] §3 (analysis of post-correction residual and sensitivity): The leverage-based bound guarantees agreement only on the calibration points used for the least-squares fit. No empirical verification is provided that ID test points (MuJoCo states or CIFAR-10 images) lie sufficiently close to the calibration geometry for the residual to remain negligible; if leverage is non-negligible on ID test data, the corrected predictors can deviate from the original model and erode the claimed ID/OOD tradeoff.
- [Experiments] Experiments section (MuJoCo and CIFAR-10 results): The manuscript reports that P&C matches or outperforms post-hoc baselines on the ID/OOD tradeoff, yet does not tabulate or plot the in-distribution accuracy (or MSE) of the P&C ensemble versus the original single pretrained model on the held-out ID test sets. This comparison is load-bearing for the central claim that no ID performance is sacrificed.
minor comments (2)
- [Abstract] The abstract refers to 'two tasks' without naming them; explicitly stating MuJoCo dynamics prediction and CIFAR-10 OOD detection would improve clarity.
- Notation for the affine correction matrix and perturbation distribution is introduced without a consolidated table of symbols; adding one would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our analysis and empirical claims. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3] §3 (analysis of post-correction residual and sensitivity): The leverage-based bound guarantees agreement only on the calibration points used for the least-squares fit. No empirical verification is provided that ID test points (MuJoCo states or CIFAR-10 images) lie sufficiently close to the calibration geometry for the residual to remain negligible; if leverage is non-negligible on ID test data, the corrected predictors can deviate from the original model and erode the claimed ID/OOD tradeoff.
Authors: We agree that the leverage bound applies strictly to the calibration points and that explicit verification on ID test points would strengthen the link between theory and the observed ID/OOD tradeoff. The first-order sensitivity analysis already indicates that deviations grow with distance from the calibration geometry, and our empirical results show P&C matching post-hoc baselines that preserve ID performance. In revision we will add a supplementary table or figure reporting average leverage (or post-correction residual norm) on held-out ID test points for both MuJoCo and CIFAR-10, confirming that these quantities remain small and comparable to calibration values. revision: yes
-
Referee: [Experiments] Experiments section (MuJoCo and CIFAR-10 results): The manuscript reports that P&C matches or outperforms post-hoc baselines on the ID/OOD tradeoff, yet does not tabulate or plot the in-distribution accuracy (or MSE) of the P&C ensemble versus the original single pretrained model on the held-out ID test sets. This comparison is load-bearing for the central claim that no ID performance is sacrificed.
Authors: We acknowledge that a direct side-by-side comparison of ID performance between the original single model and the P&C ensemble is necessary to substantiate the claim that ID accuracy is preserved. While the current experiments focus on matching established post-hoc baselines (which themselves are designed to retain ID performance), we omitted explicit ID metrics versus the base network. In the revised manuscript we will include additional rows or columns in the main result tables (and corresponding plots) that report ID MSE/accuracy for the single pretrained model, the P&C ensemble, and all baselines, thereby making the preservation of ID performance explicit. revision: yes
Circularity Check
No significant circularity; analysis uses standard linear-algebra properties of least-squares
full rationale
The derivation defines P&C explicitly as random hidden-layer perturbations plus least-squares affine correction on a calibration set. The post-correction residual bound (via leverage) and first-order sensitivity growth are direct consequences of the normal equations and hat-matrix properties of linear regression, which hold independently of the target ID/OOD tradeoff claim. No load-bearing self-citations, no fitted parameters renamed as predictions, and no ansatz or uniqueness theorem imported from prior author work. The strong ID/OOD tradeoff is asserted via empirical results on MuJoCo and CIFAR-10, not by algebraic reduction to the calibration fit itself. The agreement on calibration points is stated as a design property rather than a derived prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International conference on learning representations , year=
A scalable laplace approximation for neural networks , author=. International conference on learning representations , year=
-
[2]
Advances in neural information processing systems , volume=
A simple baseline for bayesian uncertainty in deep learning , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in Neural Information Processing Systems , volume=
Epistemic neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[5]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[6]
Advances in neural information processing systems , volume=
Deep reinforcement learning in a handful of trials using probabilistic dynamics models , author=. Advances in neural information processing systems , volume=
-
[7]
Uncertainty in Artificial Intelligence , pages=
Subspace inference for Bayesian deep learning , author=. Uncertainty in Artificial Intelligence , pages=. 2020 , organization=
2020
-
[8]
Advances in neural information processing systems , volume=
Identifying and attacking the saddle point problem in high-dimensional non-convex optimization , author=. Advances in neural information processing systems , volume=
-
[9]
Artificial intelligence and statistics , pages=
The loss surfaces of multilayer networks , author=. Artificial intelligence and statistics , pages=. 2015 , organization=
2015
-
[10]
Proceedings of the National Academy of Sciences , volume=
Reconciling modern machine-learning practice and the classical bias--variance trade-off , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[11]
Advances in neural information processing systems , volume=
Adversarial vulnerability for any classifier , author=. Advances in neural information processing systems , volume=
-
[12]
Journal of Machine Learning Research , volume=
Underspecification presents challenges for credibility in modern machine learning , author=. Journal of Machine Learning Research , volume=
-
[13]
International Conference on Learning Representations , year =
Explaining and Harnessing Adversarial Examples , author =. International Conference on Learning Representations , year =
-
[14]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
2016
-
[15]
Advances in neural information processing systems , volume=
Simple and principled uncertainty estimation with deterministic deep learning via distance awareness , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in neural information processing systems , volume=
Approximate inference turns deep networks into Gaussian processes , author=. Advances in neural information processing systems , volume=
-
[17]
International conference on artificial intelligence and statistics , pages=
Improving predictions of Bayesian neural nets via local linearization , author=. International conference on artificial intelligence and statistics , pages=. 2021 , organization=
2021
-
[18]
International Conference on Learning Representations , year =
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations , year =
-
[19]
Advances in neural information processing systems , volume=
Adversarial examples are not bugs, they are features , author=. Advances in neural information processing systems , volume=
-
[20]
Advances in neural information processing systems , volume=
Deep evidential regression , author=. Advances in neural information processing systems , volume=
-
[21]
2013 , address =
Matrix Analysis , author =. 2013 , address =
2013
-
[22]
High-Dimensional Probability: An Introduction with Applications in Data Science , author =. 2018 , address =. doi:10.1017/9781108231596 , isbn =
-
[23]
Advances in neural information processing systems , volume=
Loss surfaces, mode connectivity, and fast ensembling of dnns , author=. Advances in neural information processing systems , volume=
-
[24]
Averaging Weights Leads to Wider Optima and Better Generalization
Averaging weights leads to wider optima and better generalization , author=. arXiv preprint arXiv:1803.05407 , year=
-
[25]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
A baseline for detecting misclassified and out-of-distribution examples in neural networks , author=. arXiv preprint arXiv:1610.02136 , year=
work page internal anchor Pith review arXiv
-
[26]
Advances in neural information processing systems , volume=
Energy-based out-of-distribution detection , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in neural information processing systems , volume=
A simple unified framework for detecting out-of-distribution samples and adversarial attacks , author=. Advances in neural information processing systems , volume=
-
[28]
Advances in neural information processing systems , volume=
React: Out-of-distribution detection with rectified activations , author=. Advances in neural information processing systems , volume=
-
[29]
Advances in Neural Information Processing Systems , volume=
Openood: Benchmarking generalized out-of-distribution detection , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
2009 , type =
Learning Multiple Layers of Features from Tiny Images , author =. 2009 , type =
2009
-
[31]
Zhang, Jingyang and Yang, Jingkang and Wang, Pengyun and Wang, Haoqi and Lin, Yueqian and Zhang, Haoran and Sun, Yiyou and Du, Xuefeng and Li, Yixuan and Liu, Ziwei and others , journal=
-
[32]
2012 IEEE/RSJ international conference on intelligent robots and systems , pages=
MuJoCo: A physics engine for model-based control , author=. 2012 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2012 , organization=
2012
-
[33]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Gymnasium: A standard interface for reinforcement learning environments , author=. arXiv preprint arXiv:2407.17032 , year=
work page internal anchor Pith review arXiv
-
[34]
European conference on computer vision , pages=
Identity mappings in deep residual networks , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[35]
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine
Younis, Omar G. and Perez-Vicente, Rodrigo and Balis, John U. and Dudley, Will and Davey, Alex and Terry, Jordan K. , title =. doi:10.5281/zenodo.13767625 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.