LAPRAS : Learning-Augmented PRivate Answering for linear query Streams
Pith reviewed 2026-05-09 17:19 UTC · model grok-4.3
The pith
LAPRAS uses a prediction set to apply offline-optimal privacy mechanisms to recurring queries while smoothly allocating budget to unpredicted ones under a fixed global budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
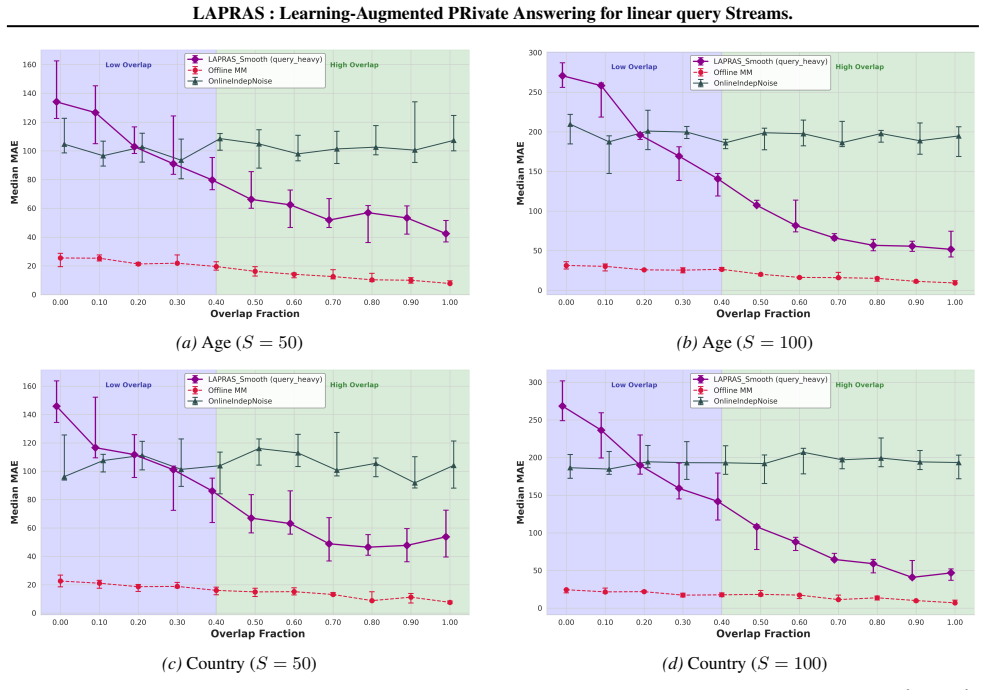
LAPRAS answers predicted queries with the offline-optimal Matrix Mechanism and the remaining queries online from a residual budget, pacing expenditure via Smooth Allocation that forms an unbiased stopping-time estimate from the first Theta(log squared S) unpredicted queries. Under high overlap between the prediction set and the actual stream it achieves near-offline utility; under low overlap it matches baseline online performance.
What carries the argument
LAPRAS's central mechanism is the split between offline Matrix Mechanism treatment for the oracle's predicted queries and Smooth Allocation for unpredicted queries, where the latter builds an unbiased budget estimate from early samples to handle an unknown total count.
If this is right
- High overlap between predictions and the stream produces utility close to the offline optimum under the same privacy budget.
- Low overlap produces performance that matches standard online differentially private methods.
- The unbiased stopping-time estimate allows correct per-query spending without knowing the total number of unpredicted queries in advance.
- The construction applies to any linear queries under (epsilon, delta) differential privacy when arrival order is uniform random.
Where Pith is reading between the lines
- Historical workload logs could train the oracle in practice, turning recurring query templates into reliable predictions.
- The smooth-allocation idea could transfer to other streaming privacy settings where future demand is uncertain.
- Non-random arrival orders would likely require a different estimation step, marking a boundary condition for the current analysis.
- The same prediction-guided split might extend beyond linear queries to other classes of database workloads.
Load-bearing premise
The claim depends on queries arriving in uniformly random order so that the early-sample estimate of remaining budget stays unbiased.
What would settle it
Measuring utility on the two real datasets at varying overlap levels between the oracle prediction set and the stream, and checking whether high overlap yields near-offline performance while low overlap yields baseline performance, would test the claimed tradeoff.
Figures

read the original abstract
Modern database workloads are highly predictable: query streams are dominated by recurring jobs and templates, even when their arrival order is not known in advance. This motivates a learning-augmented view of online differentially private (DP) analytics: can algorithms utilize predictions about which queries will occur to improve utility under a single global privacy budget, while remaining robust when predictions are wrong? We study online DP query answering, where a curator must answer a stream $Q$ of $S$ linear queries arriving in uniformly random order under privacy budget $(\epsilon,\delta)$. We present LAPRAS, which assumes access to an oracle that outputs a prediction set of queries likely to appear in the stream and uses it to guide privacy spending. LAPRAS answers predicted queries using the offline-optimal Matrix Mechanism and answers the remaining queries online from a residual budget. To pace spending across an unknown number of unpredicted queries, we introduce Smooth Allocation, which forms an unbiased stopping-time estimate $\widehat{B}$ from the first $T=\Theta(\log^2 S)$ unpredicted queries and continuously recalibrates per-query expenditure. Empirically, over two real datasets, we validate the intended consistency--robustness trade-off: LAPRAS achieves near-offline utility under high overlap and degrades gracefully to baseline-level performance when overlap is low.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LAPRAS, a learning-augmented framework for differentially private (DP) answering of linear query streams under a global privacy budget. Assuming access to an oracle that predicts a set of likely queries, LAPRAS applies the offline-optimal Matrix Mechanism to the predicted queries and uses a novel Smooth Allocation mechanism for the unpredicted ones. Smooth Allocation uses the arrival time of the T-th unpredicted query, where T = Θ(log² S), to form an unbiased estimate of the total number of unpredicted queries and pace the residual budget expenditure. The paper claims that this achieves near-offline utility when prediction overlap is high and degrades gracefully to baseline performance when overlap is low, under the assumption that queries arrive in uniformly random order. This is supported by empirical results on two real datasets.
Significance. Should the central claims hold, this work would be significant for bridging offline-optimal DP mechanisms with online streaming settings in a robust manner. It explicitly addresses the use of predictions in DP query answering, which is relevant given the predictability of database workloads. The Smooth Allocation technique provides a concrete method for budget pacing with theoretical unbiasedness under the random-order model, and the empirical validation on real datasets lends credibility to the practical utility of the consistency-robustness trade-off.
major comments (2)
- [Smooth Allocation] Smooth Allocation (description of stopping-time estimator): The unbiasedness of the estimate B̂ from the arrival time of the T-th unpredicted query holds only under the uniform random permutation model stated in the abstract. This assumption is load-bearing for the robustness claim, because when overlap is low the residual budget dominates utility and any bias from temporally correlated arrivals would either exhaust the budget early or spend too conservatively, so the 'degrades gracefully to baseline' guarantee no longer follows. The manuscript should either derive the estimator under weaker arrival models or add experiments with correlated streams.
- [Experimental evaluation] Experimental validation (results on two real datasets): The reported near-offline utility under high overlap and graceful degradation are shown, but the experiments appear to enforce the random-order assumption and simulate the prediction oracle without reported controls for temporal correlation or sensitivity to oracle error patterns. This leaves the central consistency-robustness trade-off only partially supported when the weakest assumption (random order) is relaxed.
minor comments (2)
- [Parameter selection] The choice T = Θ(log² S) is listed as a free parameter; a short derivation or ablation showing how the log² factor balances bias and variance in the stopping-time estimate would improve clarity.
- [Introduction] Notation for the prediction set, overlap metric, and residual budget B_res could be introduced with a single table or diagram in the introduction for easier reference.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive major comments. We address each point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Smooth Allocation (description of stopping-time estimator): The unbiasedness of the estimate B̂ from the arrival time of the T-th unpredicted query holds only under the uniform random permutation model stated in the abstract. This assumption is load-bearing for the robustness claim, because when overlap is low the residual budget dominates utility and any bias from temporally correlated arrivals would either exhaust the budget early or spend too conservatively, so the 'degrades gracefully to baseline' guarantee no longer follows. The manuscript should either derive the estimator under weaker arrival models or add experiments with correlated streams.
Authors: We concur that the unbiasedness of the Smooth Allocation estimator is proven under the uniform random permutation model, as stated in the abstract and Section 3. This model is standard for analyzing online algorithms where arrival order is random rather than adversarial. Deriving an unbiased estimator for general arrival processes would require new theoretical techniques beyond the current stopping-time analysis and is not straightforward. Therefore, we will not attempt a full derivation in the revision. Instead, we will add a dedicated paragraph discussing the assumption, its necessity for the unbiasedness, and the potential impact of correlations on the graceful degradation property. We will also include new experiments using temporally correlated query streams (e.g., with Markovian dependencies) to empirically evaluate the robustness of LAPRAS under relaxed assumptions. revision: partial
-
Referee: Experimental validation (results on two real datasets): The reported near-offline utility under high overlap and graceful degradation are shown, but the experiments appear to enforce the random-order assumption and simulate the prediction oracle without reported controls for temporal correlation or sensitivity to oracle error patterns. This leaves the central consistency-robustness trade-off only partially supported when the weakest assumption (random order) is relaxed.
Authors: The experiments in Section 5 are designed to match the theoretical setting by enforcing random query order and controlling the overlap via oracle simulation. This allows direct validation of the consistency-robustness trade-off under the analyzed model. We agree that additional controls would better support the claims. In the revised manuscript, we will add experiments with temporally correlated streams and include an analysis of sensitivity to various oracle error patterns (e.g., false positives/negatives in predictions) to provide a more comprehensive evaluation. revision: partial
Circularity Check
No significant circularity detected in LAPRAS derivation
full rationale
The paper's core construction assumes an external oracle for the prediction set and explicitly invokes the uniform random arrival order to establish that the stopping-time estimate in Smooth Allocation is unbiased. This follows directly from standard probability on permutations and does not reduce the claimed utility or the consistency-robustness trade-off to a fitted parameter or self-referential definition. The offline Matrix Mechanism application and residual-budget routing are standard DP primitives whose properties are independent of the present mechanism. No equation or step equates a derived quantity to its own input by construction, and no load-bearing claim rests on a self-citation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- T = Theta(log^2 S)
axioms (2)
- domain assumption Queries arrive in uniformly random order
- domain assumption Existence of a prediction oracle outputting a set of likely queries
invented entities (1)
-
Smooth Allocation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2014 , series =
Cynthia Dwork and Aaron Roth , title =. 2014 , series =
2014
-
[2]
Journal of Privacy and Confidentiality , year =
Mark Bun and Thomas Steinke and Jonathan Ullman , title =. Journal of Privacy and Confidentiality , year =. doi:10.29012/jpc.655 , note =
-
[3]
Beyond the Worst-Case Analysis of Algorithms , editor =
Michael Mitzenmacher and Sergei Vassilvitskii , title =. Beyond the Worst-Case Analysis of Algorithms , editor =. 2021 , pages =
2021
-
[4]
Communications of the ACM , year =
Michael Mitzenmacher and Sergei Vassilvitskii , title =. Communications of the ACM , year =
-
[5]
Proceedings of the Workshop on Theory and Practice of Differential Privacy , year =
Kareem Amin and Travis Dick and Mikhail Khodak and Sergei Vassilvitskii , title =. Proceedings of the Workshop on Theory and Practice of Differential Privacy , year =
-
[6]
Proceedings of the 40th International Conference on Machine Learning , year =
Mikhail Khodak and Kareem Amin and Travis Dick and Sergei Vassilvitskii , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[7]
Proceedings of the 38th International Conference on Machine Learning , year =
Terrance Liu and Giuseppe Vietri and Thomas Steinke and Jonathan Ullman and Zhiwei Steven Wu , title =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[8]
Combinatorial Correlation Clustering , booktitle =
Vincent Cohen. Combinatorial Correlation Clustering , booktitle =. 2024 , url =. doi:10.1145/3618260.3649712 , timestamp =
-
[9]
Nikhil Bansal and Avrim Blum and Shuchi Chawla , title =. 43rd Symposium on Foundations of Computer Science. 2002 , url =. doi:10.1109/SFCS.2002.1181947 , timestamp =
-
[10]
Journal of Computer and System Sciences , volume=
Clustering with qualitative information , author=. Journal of Computer and System Sciences , volume=. 2005 , publisher=
2005
-
[11]
Journal of the ACM (JACM) , volume=
Aggregating inconsistent information: ranking and clustering , author=. Journal of the ACM (JACM) , volume=. 2008 , publisher=
2008
-
[12]
2023 IEEE 64th Annual Symposium on Foundations of Computer Science (FOCS) , pages=
Handling correlated rounding error via preclustering: A 1.73-approximation for correlation clustering , author=. 2023 IEEE 64th Annual Symposium on Foundations of Computer Science (FOCS) , pages=. 2023 , organization=
2023
-
[13]
International Conference on Machine Learning , pages=
Correlation clustering in constant many parallel rounds , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[14]
Sepehr Assadi and Chen Wang , editor =. Sublinear Time and Space Algorithms for Correlation Clustering via Sparse-Dense Decompositions , booktitle =. 2022 , url =. doi:10.4230/LIPICS.ITCS.2022.10 , timestamp =
-
[15]
Proceedings of the 56th Annual ACM Symposium on Theory of Computing , pages=
Understanding the Cluster Linear Program for Correlation Clustering , author=. Proceedings of the 56th Annual ACM Symposium on Theory of Computing , pages=
-
[16]
Near-Optimal Correlation Clustering with Privacy , booktitle =
Vincent Cohen. Near-Optimal Correlation Clustering with Privacy , booktitle =. 2022 , url =
2022
-
[17]
Single-Pass Pivot Algorithm for Correlation Clustering
Konstantin Makarychev and Sayak Chakrabarty , editor =. Single-Pass Pivot Algorithm for Correlation Clustering. Keep it simple! , booktitle =. 2023 , url =
2023
-
[18]
Forty-first International Conference on Machine Learning,
Mina Dalirrooyfard and Konstantin Makarychev and Slobodan Mitrovic , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[19]
Improving Sparse Vector Technique with Renyi Differential Privacy , booktitle =
Yuqing Zhu and Yu. Improving Sparse Vector Technique with Renyi Differential Privacy , booktitle =. 2020 , url =
2020
-
[20]
Cynthia Dwork and Aaron Roth , title =. Found. Trends Theor. Comput. Sci. , volume =. 2014 , url =. doi:10.1561/0400000042 , timestamp =
-
[21]
Communications of the ACM , volume=
Counting large numbers of events in small registers , author=. Communications of the ACM , volume=. 1978 , publisher=
1978
-
[22]
Algorithms with Predictions , booktitle=
Mitzenmacher, Michael and Vassilvitskii, Sergei , editor=. Algorithms with Predictions , booktitle=. 2021 , pages=
2021
-
[23]
Min Lyu and Dong Su and Ninghui Li , title =. Proc. 2017 , url =. doi:10.14778/3055330.3055331 , timestamp =
-
[24]
A bounded-noise mechanism for differential privacy , booktitle =
Yuval Dagan and Gil Kur , editor =. A bounded-noise mechanism for differential privacy , booktitle =. 2022 , url =
2022
-
[25]
International conference on machine learning , pages=
Improving the gaussian mechanism for differential privacy: Analytical calibration and optimal denoising , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[26]
Miti Mazmudar and Thomas Humphries and Jiaxiang Liu and Matthew Rafuse and Xi He , title =. Proc. 2022 , url =. doi:10.14778/3574245.3574246 , timestamp =
-
[27]
Proceedings of the Second International Conference on Knowledge Discovery and Data Mining , pages =
Kohavi, Ron , title =. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining , pages =. 1996 , publisher =
1996
-
[28]
Optimizing linear counting queries un- der differential privacy
Li, Chao and Hay, Michael and Rastogi, Vibhor and Miklau, Gerome and McGregor, Andrew , title =. 2010 , isbn =. doi:10.1145/1807085.1807104 , booktitle =
-
[29]
Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Friendship and mobility: user movement in location-based social networks , author=. Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[30]
R. J. Serfling , journal =. Probability Inequalities for the Sum in Sampling without Replacement , urldate =
-
[31]
Yamashita, Makoto and Fujisawa, Katsuki and Kojima, Masakazu. Implementation and evaluation of SDPA 6.0 (Semidefinite Programming Algorithm 6.0). Optimization Methods and Software. 2003. doi:10.1080/1055678031000118482. https://doi.org/10.1080/1055678031000118482
-
[32]
Latest Developments in the SDPA Family for Solving Large-Scale SDPs
Yamashita, Makoto and Fujisawa, Katsuki and Fukuda, Mituhiro and Kobayashi, Kazuhiro and Nakata, Kazuhide and Nakata, Maho. Latest Developments in the SDPA Family for Solving Large-Scale SDPs. Handbook on Semidefinite, Conic and Polynomial Optimization. 2012. doi:10.1007/978-1-4614-0769-0_24
-
[33]
Nakata, Maho. A numerical evaluation of highly accurate multiple-precision arithmetic version of semidefinite programming solver: SDPA-GMP, -QD and -DD. 2010 IEEE International Symposium on Computer-Aided Control System Design. 2010. doi:10.1109/CACSD.2010.5612693
-
[34]
Kim, Sunyoung and Kojima, Masakazu and Mevissen, Martin and Yamashita, Makoto. Exploiting sparsity in linear and nonlinear matrix inequalities via positive semidefinite matrix completion. Mathematical Programming. 2011. doi:10.1007/s10107-010-0402-6
-
[35]
Journal of Machine Learning Research , year =
Steven Diamond and Stephen Boyd , title =. Journal of Machine Learning Research , year =
-
[36]
Journal of Control and Decision , year =
Agrawal, Akshay and Verschueren, Robin and Diamond, Steven and Boyd, Stephen , title =. Journal of Control and Decision , year =
-
[37]
and Knuth, Donald E
Graham, Ronald L. and Knuth, Donald E. and Patashnik, Oren , title =. 1994 , isbn =
1994
-
[38]
McKenna, Ryan and Maity, Raj Kumar and Mazumdar, Arya and Miklau, Gerome , title =. 2020 , issue_date =. doi:10.14778/3407790.3407798 , journal =
-
[39]
Hardt, Moritz and Rothblum, Guy N. , title =. 2010 , isbn =. doi:10.1109/FOCS.2010.85 , booktitle =
-
[40]
SageDB: A Learned Database System ,author =
-
[41]
SIGMOD , year =
Huang, Hanxian and Siddiqui, Tarique and Alotaibi, Rana and Curino, Carlo and Leeka, Jyoti and Jindal, Alekh and Zhao, Jishen and Camacho-Rodríguez, Jesús and Tian, Yuanyuan , title =. SIGMOD , year =
-
[42]
Cypher: An evolving query language for property graphs
Jindal, Alekh and Qiao, Shi and Patel, Hiren and Yin, Zhicheng and Di, Jieming and Bag, Malay and Friedman, Marc and Lin, Yifung and Karanasos, Konstantinos and Rao, Sriram , title =. 2018 , isbn =. doi:10.1145/3183713.3190656 , booktitle =
-
[43]
Wu, Ziniu and Marcus, Ryan and Liu, Zhengchun and Negi, Parimarjan and Nathan, Vikram and Pfeil, Pascal and Saxena, Gaurav and Rahman, Mohammad and Narayanaswamy, Balakrishnan and Kraska, Tim , title =. 2024 , isbn =. doi:10.1145/3626246.3653391 , booktitle =
-
[44]
Zhang, Bohan and Van Aken, Dana and Wang, Justin and Dai, Tao and Jiang, Shuli and Lao, Jacky and Sheng, Siyuan and Pavlo, Andrew and Gordon, Geoffrey J. , title =. Proc. VLDB Endow. , month = aug, pages =. 2018 , issue_date =. doi:10.14778/3229863.3236222 , abstract =
-
[45]
Proceedings of the 40th International Conference on Machine Learning , pages =
Fully-Adaptive Composition in Differential Privacy , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[46]
2016 , isbn =
Rogers, Ryan and Roth, Aaron and Ullman, Jonathan and Vadhan, Salil , title =. 2016 , isbn =
2016
-
[47]
Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data , pages =
Eichmann, Philipp and Zgraggen, Emanuel and Binnig, Carsten and Kraska, Tim , title =. Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data , pages =. 2020 , isbn =. doi:10.1145/3318464.3380574 , abstract =
-
[48]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[49]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[50]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.