Recognition: unknown
Multi-User Dueling Bandits: A Fair Approach using Nash Social Welfare
Pith reviewed 2026-05-10 14:59 UTC · model grok-4.3
The pith
Using Nash Social Welfare to enforce fairness across users with heterogeneous preferences in dueling bandits produces a regret lower bound of order T to the two-thirds power.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
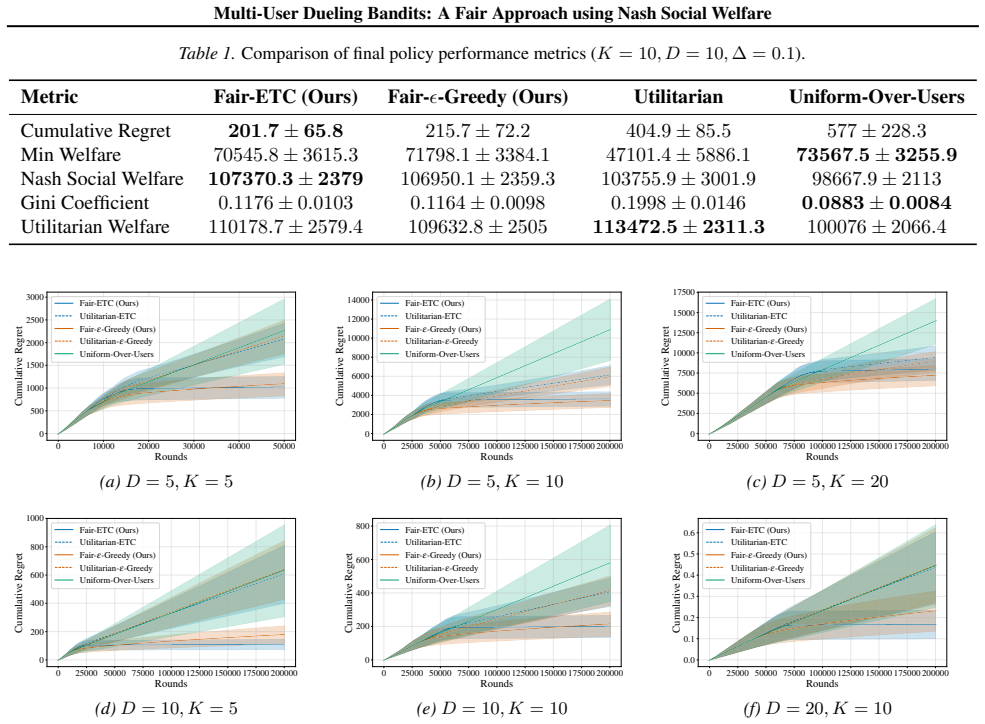
We construct a hard instance to establish a regret lower bound of Ω(T^{2/3} min(K,D)^{1/3}) for a time horizon T, K arms, and D users, which, to the best of our knowledge, is the first result quantifying the cost of fairness in dueling bandits with heterogeneous preferences. We then present the Fair-Explore-Then-Commit and Fair-ε-Greedy algorithms with a Condorcet winner identification phase. We further derive their regret upper bounds that match the lower-bound dependence on T up to logarithmic factors.
What carries the argument
Nash Social Welfare objective applied to per-user utilities, each defined as the probability that a chosen arm beats that user's own Condorcet winner (an arm preferred to every other arm).
If this is right
- The regret of any fair algorithm scales at least with the cube root of min(K, D) in addition to the T^{2/3} term.
- The Fair-Explore-Then-Commit and Fair-ε-Greedy procedures achieve upper bounds whose leading term matches the lower bound in its T dependence.
- A separate identification phase for each user's Condorcet winner is required before fair selection can begin.
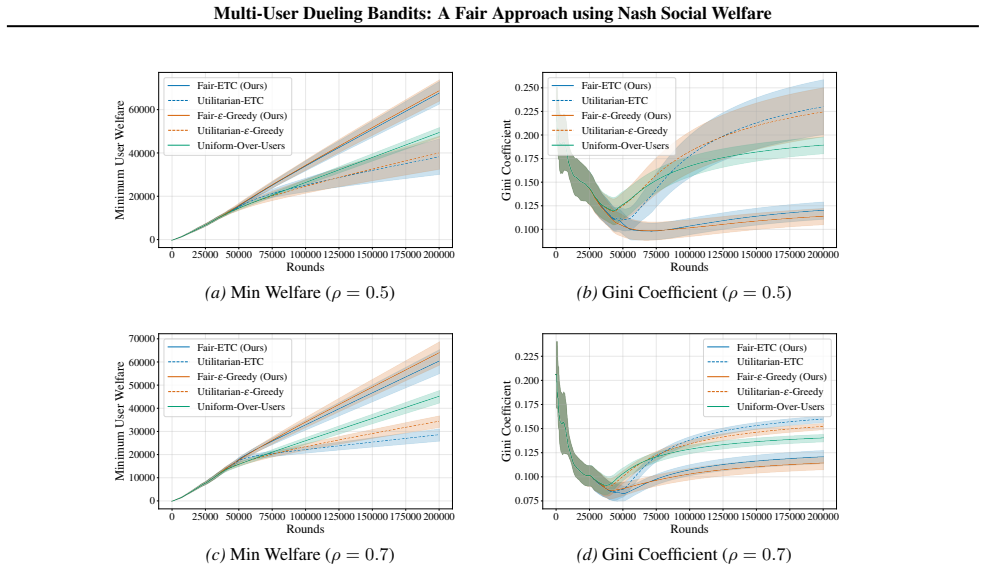
- When the number of users or arms grows, the fairness penalty increases, forcing more exploration overall.
Where Pith is reading between the lines
- In applications such as collecting human feedback for model training, the extra exploration cost suggests allocating additional rounds of pairwise comparisons to protect smaller user groups.
- The same product-based fairness objective could be applied to other sequential decision problems where one wants to avoid any single participant falling too far behind.
- If some users share the same Condorcet winner the effective number of distinct winners drops, which might reduce the observed min(K, D) factor in practice.
Load-bearing premise
Each user has a Condorcet winner, an arm that beats every other arm according to that user's private preference ordering.
What would settle it
An algorithm that achieves regret growing strictly slower than T to the two-thirds power when run on the paper's constructed hard instance with heterogeneous Condorcet winners would contradict the lower bound.
Figures
read the original abstract
Learning from human preference data is becoming a useful tool, from fine-tuning large language models to training reinforcement learning agents. However, in most scenarios, the model is trained on the average preference of all human evaluators, which, under large variations of preferences, can be unfair to minority groups. In this work, we consider fairness in dueling bandits, a standard framework for online learning from preference data. We assume that each user has a (potentially distinct) Condorcet winner, which is an arm preferred to every other arm. Using these user-specific Condorcet winners as reference points, we evaluate and score arms according to their performance relative to the corresponding winner. To promote fairness across heterogeneous users, we adopt the well-established Nash Social Welfare objective, which maximizes the product of user utilities, thereby inherently penalizing inequality and preventing the marginalization of any single user. Within this framework, we construct a hard instance to establish a regret lower bound of $\Omega(T^{2/3}\min(K,D)^\frac{1}{3})$ for a time horizon $T$, $K$ arms, and $D$ users, which, to the best of our knowledge, is the first result quantifying the cost of fairness in dueling bandits with heterogeneous preferences. We then present the Fair-Explore-Then-Commit and Fair-$\epsilon$-Greedy algorithms with a Condorcet winner identification phase. We further derive their regret upper bounds that match the lower-bound dependence on $T$ up to logarithmic factors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies fairness in multi-user dueling bandits under the assumption that each user has a (possibly distinct) Condorcet winner. It adopts the Nash Social Welfare objective to evaluate arms relative to each user's winner, constructs a hard instance yielding a regret lower bound of Ω(T^{2/3} min(K,D)^{1/3}), and presents the Fair-Explore-Then-Commit and Fair-ε-Greedy algorithms (each with an explicit Condorcet-winner identification phase) whose upper bounds match the lower bound's dependence on T up to logarithmic factors.
Significance. If the bounds are correct, the work supplies the first explicit quantification of the price of fairness in heterogeneous-preference dueling bandits. The matching T^{2/3} dependence (up to logs) together with the principled use of Nash Social Welfare and the two concrete algorithms constitute a substantive contribution to online learning from preference data, with direct relevance to applications such as RLHF.
major comments (2)
- [Lower-bound section / abstract] The lower-bound construction (abstract and the dedicated lower-bound section) is load-bearing for the central claim that the result quantifies the cost of fairness. The manuscript must explicitly verify that the constructed hard instance preserves both the per-user Condorcet-winner property and the Nash Social Welfare utility definition; any deviation would invalidate the claimed Ω(min(K,D)^{1/3}) dependence.
- [Algorithm sections and regret analysis] The upper-bound proofs for both algorithms rely on the sample complexity of the Condorcet-winner identification phase. The manuscript should state the precise number of rounds (or pulls) allocated to identification and show how this term is absorbed into the overall O(T^{2/3} polylog) regret without introducing an extra additive factor that would break the claimed matching.
minor comments (2)
- [Abstract and regret theorems] Clarify whether the upper bounds also recover the min(K,D)^{1/3} dependence or only the T^{2/3} term; the abstract mentions only the T dependence.
- [Notation and preliminaries] Ensure uniform notation for the number of users (D) and arms (K) across all theorems, lemmas, and algorithm pseudocode.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The comments highlight important points for rigor in the lower-bound construction and clarity in the algorithmic analysis. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation without altering the core results.
read point-by-point responses
-
Referee: [Lower-bound section / abstract] The lower-bound construction (abstract and the dedicated lower-bound section) is load-bearing for the central claim that the result quantifies the cost of fairness. The manuscript must explicitly verify that the constructed hard instance preserves both the per-user Condorcet-winner property and the Nash Social Welfare utility definition; any deviation would invalidate the claimed Ω(min(K,D)^{1/3}) dependence.
Authors: We agree that explicit verification strengthens the lower-bound argument. The hard instance is constructed by partitioning arms and users such that each user has a unique Condorcet winner (with pairwise preference probabilities strictly greater than 1/2 against all other arms for that user), and the Nash Social Welfare is computed exactly as the product of per-user utilities relative to their respective winners. To address the comment, we will insert a short lemma immediately preceding the regret calculation that formally confirms both properties hold throughout the instance construction, including under the chosen gap parameters that yield the Ω(min(K,D)^{1/3}) factor. This addition is purely expository and does not affect the bound. revision: yes
-
Referee: [Algorithm sections and regret analysis] The upper-bound proofs for both algorithms rely on the sample complexity of the Condorcet-winner identification phase. The manuscript should state the precise number of rounds (or pulls) allocated to identification and show how this term is absorbed into the overall O(T^{2/3} polylog) regret without introducing an extra additive factor that would break the claimed matching.
Authors: We thank the referee for this clarification request. In Fair-Explore-Then-Commit, the identification phase allocates O(K log(KD T)) total pulls (using a tournament-style or pairwise comparison procedure with union bound over D users and failure probability 1/T). In Fair-ε-Greedy the identification is performed in an initial phase of the same order. Because this term is O(log T), it is absorbed into the existing polylogarithmic factors of the O(T^{2/3} polylog T) regret bound; the dominant terms arise from the subsequent exploration and commitment phases, which are calibrated to match the lower-bound exponent. We will add an explicit statement of the identification sample complexity together with a short paragraph in the regret analysis showing the absorption, ensuring no extraneous additive term appears. revision: yes
Circularity Check
No significant circularity identified
full rationale
The derivation begins from the explicit assumption that each user has a distinct Condorcet winner, constructs an independent hard instance to obtain the Ω(T^{2/3} min(K,D)^{1/3}) lower bound, and then applies standard explore-then-commit and ε-greedy analysis to produce matching upper bounds for the two algorithms. The Nash Social Welfare objective is invoked as a pre-existing fairness criterion rather than being derived from the paper's own regret expressions or fitted quantities. No equation reduces a claimed prediction to a parameter fitted from the same data, no self-citation chain bears the central result, and the regret scalings are obtained through separate lower-bound construction and upper-bound analysis rather than by re-labeling inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Each user possesses a Condorcet winner (an arm strictly preferred to all others)
- standard math Standard regret analysis tools (concentration bounds, exploration-exploitation trade-offs) apply to the multi-user setting
Reference graph
Works this paper leans on
-
[1]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review arXiv 1909
-
[2]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[3]
Econometrica: Journal of the Econometric Society , pages=
The Nash social welfare function , author=. Econometrica: Journal of the Econometric Society , pages=. 1979 , publisher=
1979
-
[4]
Journal of Artificial Intelligence Research , volume=
Improving Nash social welfare approximations , author=. Journal of Artificial Intelligence Research , volume=
-
[5]
ACM Transactions on Economics and Computation (TEAC) , volume=
The unreasonable fairness of maximum Nash welfare , author=. ACM Transactions on Economics and Computation (TEAC) , volume=. 2019 , publisher=
2019
-
[6]
Available at SSRN 3536707 , year=
Fairness in the ambulance location problem: maximizing the Bernoulli-Nash social welfare , author=. Available at SSRN 3536707 , year=
-
[7]
Biomimetics , volume=
Maximizing Nash Social Welfare Based on Greedy Algorithm and Estimation of Distribution Algorithm , author=. Biomimetics , volume=. 2024 , publisher=
2024
-
[8]
Proceedings of the 2017 ACM Conference on Economics and Computation , pages=
Nash social welfare approximation for strategic agents , author=. Proceedings of the 2017 ACM Conference on Economics and Computation , pages=
2017
-
[9]
Advances in Neural Information Processing Systems , volume=
Fair algorithms for multi-agent multi-armed bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Journal of Computer and System Sciences , volume=
The k-armed dueling bandits problem , author=. Journal of Computer and System Sciences , volume=. 2012 , publisher=
2012
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
An Efficient Algorithm for Fair Multi-Agent Multi-Armed Bandit with Low Regret , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , month=. doi:10.1609/aaai.v37i7.25985 , abstractNote=
-
[12]
Advances in Neural Information Processing Systems , volume=
No-regret learning for fair multi-agent social welfare optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2208.12584 , year=
Socially fair reinforcement learning , author=. arXiv preprint arXiv:2208.12584 , year=
-
[14]
arXiv preprint arXiv:2212.01382 , year=
Welfare and fairness in multi-objective reinforcement learning , author=. arXiv preprint arXiv:2212.01382 , year=
-
[15]
International Conference on Machine Learning , pages=
Learning fair policies in multi-objective (deep) reinforcement learning with average and discounted rewards , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[16]
Artificial Intelligence and Statistics , pages=
Sparse dueling bandits , author=. Artificial Intelligence and Statistics , pages=. 2015 , organization=
2015
-
[17]
International Conference on Machine Learning , pages=
Adversarial dueling bandits , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[18]
arXiv preprint arXiv:2502.09724 , year=
Navigating the Social Welfare Frontier: Portfolios for Multi-objective Reinforcement Learning , author=. arXiv preprint arXiv:2502.09724 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Identification of the generalized Condorcet winner in multi-dueling bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Econometrica , volume=
The bargaining problem , author=. Econometrica , volume=
-
[21]
2004 , publisher=
Fair division and collective welfare , author=. 2004 , publisher=
2004
-
[22]
International conference on machine learning , pages=
Relative upper confidence bound for the k-armed dueling bandit problem , author=. International conference on machine learning , pages=. 2014 , organization=
2014
-
[23]
Advances in neural information processing systems , volume=
Equality of opportunity in supervised learning , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of the 3rd innovations in theoretical computer science conference , pages=
Fairness through awareness , author=. Proceedings of the 3rd innovations in theoretical computer science conference , pages=
-
[25]
Inherent trade-offs in the fair determination of risk scores.arXiv preprint arXiv:1609.05807, 2016
Inherent trade-offs in the fair determination of risk scores , author=. arXiv preprint arXiv:1609.05807 , year=
-
[26]
Advances in neural information processing systems , volume=
Counterfactual fairness , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in neural information processing systems , volume=
Copeland dueling bandits , author=. Advances in neural information processing systems , volume=
-
[28]
International conference on machine learning , pages=
Generic exploration and k-armed voting bandits , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[29]
Conference on learning theory , pages=
Regret lower bound and optimal algorithm in dueling bandit problem , author=. Conference on learning theory , pages=. 2015 , organization=
2015
-
[30]
International Conference on Machine Learning , pages=
Dueling bandits with weak regret , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dueling bandits with qualitative feedback , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.