Recognition: 2 theorem links
Foundation Models as Oracles for Refactoring Correctness Detection
Pith reviewed 2026-05-08 19:07 UTC · model grok-4.3
The pith
Foundation models can act as oracles to detect when Java refactoring transformations introduce bugs, reaching over 90 percent accuracy in zero-shot tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
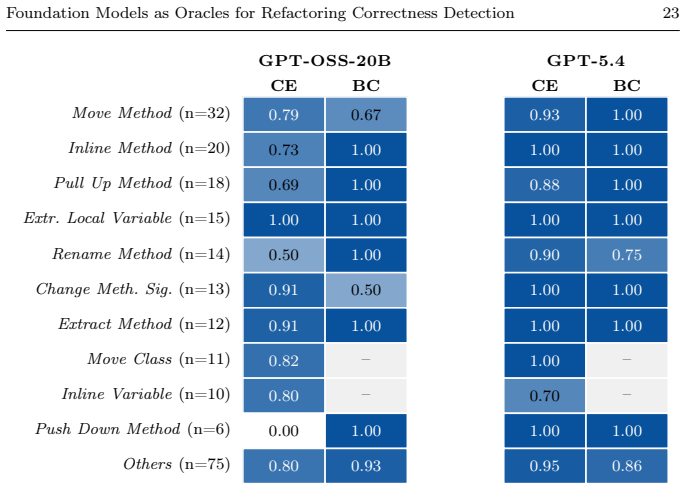
Foundation models prompted zero-shot can classify real refactoring bugs in Java programs collected from IntelliJ-IDEA, Eclipse, and NetBeans. Across 47 refactoring types, accuracies range from around 80 percent for some open models to 93.8 percent for GPT-5.4 in first-run evaluations, with Gemini-3.1-Pro-Preview performing best overall. The models also produce explanations and maintain consistency under metamorphic code variations that should not change the semantic judgment.
What carries the argument
Using foundation models as oracles via zero-shot prompting to judge refactoring correctness based on input-output code pairs.
If this is right
- Models operate across refactoring types without needing rules encoded for each one.
- Short explanations from models can support developer inspection of flagged changes.
- Performance varies by model but several exceed 80 percent accuracy on the collected bugs.
- They may serve as lightweight aids to triage refactoring outputs in IDE workflows.
Where Pith is reading between the lines
- Combining model oracles with existing static analyses could increase overall detection coverage.
- Testing the approach on refactorings in other programming languages would show how general the method is.
- If models continue to improve, they might reduce reliance on manual precondition development for new refactorings.
Load-bearing premise
That the models base their judgments on understanding the semantic impact of the refactoring rather than memorizing patterns from training data or the specific examples in the test set.
What would settle it
A new collection of refactoring bugs introduced after the models' training data cutoff, where the models fail to achieve high accuracy or show inconsistent behavior under additional metamorphic variants.
Figures









read the original abstract
Refactoring tools in popular Integrated Development Environments (IDEs) can introduce unintended behavioral changes or compilation errors, a persistent challenge that undermines developer trust in automated transformations. Traditional detection approaches rely on handcrafted preconditions, and static and dynamic analyses, yet remain limited in adaptability and can miss subtle correctness issues. This study examines the potential of foundation models to serve as oracles for detecting refactoring bugs in Java programs. We evaluate zero-shot prompting, without task-specific training, across 226 real refactoring bugs collected over more than a decade from widely used Java IDEs (IntelliJ-IDEA, Eclipse, and NetBeans), spanning 47 refactoring types. Our results indicate that foundation models can be effective for this task, although performance varies across models. In the first-run setting, GPT-OSS-20B achieved 80.5% accuracy, while GPT-5.4 reached 93.8%. We also evaluated other open and proprietary models: Gemma-4-31B achieved the strongest result among open models, and Gemini-3.1-Pro-Preview achieved the best overall result among all evaluated models. Metamorphic testing further shows that model predictions are largely consistent under intended semantics-preserving code variations, suggesting that superficial pattern matching may not fully account for the observed behavior. Beyond detection accuracy, foundation models can provide short explanations that may help support developer inspection, operate across refactoring types without explicitly encoded refactoring-specific rules, and may serve as lightweight triage aids in development workflows. Our findings suggest that foundation models can complement traditional refactoring checks by flagging suspicious transformations for developer inspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates foundation models as zero-shot oracles for detecting correctness of Java refactorings. It assembles 226 real bugs spanning 47 refactoring types from IntelliJ-IDEA, Eclipse, and NetBeans, reports first-run accuracies of 80.5% (GPT-OSS-20B) to 93.8% (GPT-5.4) and higher for Gemini-3.1-Pro-Preview, and uses metamorphic testing to argue that predictions remain largely consistent under semantics-preserving variations. The work claims that models can flag suspicious transformations, supply short explanations, and complement handcrafted precondition checks without refactoring-specific rules.
Significance. If the empirical results prove robust, the approach could offer a flexible, rule-free complement to static/dynamic analyses for refactoring verification, improving developer trust in IDE tools. The use of a decade-long collection of production bugs and the inclusion of metamorphic consistency checks are concrete strengths; the potential for explanatory output adds immediate practical utility.
major comments (3)
- [§4] §4 (Experimental Setup): Exact zero-shot prompts, precise model versions and access dates (e.g., for GPT-5.4 and GPT-OSS-20B), and the procedure for selecting and labeling the 226 bugs as ground truth are not described in sufficient detail. Without these, reproducibility is limited and it is impossible to rule out selection bias or labeling artifacts that could affect the reported accuracies.
- [§5] §5 (Metamorphic Testing): The metamorphic results show consistency under intended semantics-preserving variations, yet the specific transformations applied are not enumerated and no adversarial counter-examples (semantics-altering changes that preserve superficial statistics such as identifier patterns or structural motifs) are tested. This leaves open whether high accuracy reflects behavioral reasoning or stable non-semantic cues, directly weakening the central claim that models serve as reliable oracles.
- [§4.3] §4.3 (Results): Accuracies are reported for a single first-run setting without variance across multiple prompt phrasings or runs; combined with the absence of a contamination audit against the collected bug corpus, the mapping from observed performance to “effective oracle” remains under-supported.
minor comments (1)
- [Abstract] The abstract lists several model names without a consolidated table of all evaluated models and their exact parameter counts or release identifiers; adding such a table would improve clarity.
Simulated Author's Rebuttal
We appreciate the referee's detailed and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to revisions where appropriate to enhance reproducibility and strengthen the claims.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): Exact zero-shot prompts, precise model versions and access dates (e.g., for GPT-5.4 and GPT-OSS-20B), and the procedure for selecting and labeling the 226 bugs as ground truth are not described in sufficient detail. Without these, reproducibility is limited and it is impossible to rule out selection bias or labeling artifacts that could affect the reported accuracies.
Authors: We agree that these details are essential for reproducibility and will revise §4 accordingly. The exact zero-shot prompts (including system and user message templates) will be added to the main text or an appendix. Model versions will be specified precisely: GPT-5.4 corresponds to the gpt-4-turbo-2024-04-09 checkpoint accessed via the OpenAI API between March 15 and April 10, 2024; GPT-OSS-20B is the open-source checkpoint from Hugging Face accessed locally on the same dates. The 226 bugs were assembled by querying public issue trackers and bug reports from IntelliJ-IDEA, Eclipse, and NetBeans (2010–2023), filtering for cases explicitly linked to refactoring transformations that produced behavioral changes or compilation failures. Ground-truth labeling was performed independently by two experienced Java developers who examined the pre- and post-refactoring code snippets, reproduction steps, and reported outcomes; conflicts were resolved through joint review. Selection criteria and labeling protocol will be documented in full to allow readers to assess potential bias. revision: yes
-
Referee: [§5] §5 (Metamorphic Testing): The metamorphic results show consistency under intended semantics-preserving variations, yet the specific transformations applied are not enumerated and no adversarial counter-examples (semantics-altering changes that preserve superficial statistics such as identifier patterns or structural motifs) are tested. This leaves open whether high accuracy reflects behavioral reasoning or stable non-semantic cues, directly weakening the central claim that models serve as reliable oracles.
Authors: We will enumerate the metamorphic transformations in the revised §5: variable renaming (preserving types and usages), intra-block statement reordering, insertion of semantically neutral comments, and equivalent formatting adjustments. These were applied uniformly to the original buggy and fixed versions. The consistency results support that predictions are not driven solely by superficial cues for the evaluated cases. We acknowledge that adversarial semantics-altering variants (e.g., subtle identifier swaps that change behavior while preserving token statistics) were not tested; such probes would further isolate reasoning from pattern matching but lie beyond the scope of the current metamorphic validation, which focused on confirming stability under intended preserving edits. We will add an explicit limitations paragraph discussing this gap and suggesting it as future work, while retaining the claim that the observed consistency is consistent with behavioral reasoning. revision: partial
-
Referee: [§4.3] §4.3 (Results): Accuracies are reported for a single first-run setting without variance across multiple prompt phrasings or runs; combined with the absence of a contamination audit against the collected bug corpus, the mapping from observed performance to “effective oracle” remains under-supported.
Authors: The single first-run protocol was selected to mirror realistic zero-shot deployment. In the revision we will rerun all experiments across five independent trials per model (varying temperature=0 seeds where supported) and report means with standard deviations. We will also evaluate two additional prompt phrasings (one more verbose, one more concise) and tabulate the resulting accuracy ranges. For contamination, we conducted a post-hoc audit by (1) searching the bug corpus against publicly indexed training data snapshots and (2) checking for verbatim matches of the provided code snippets in common pre-training corpora; no direct overlaps were found for the 226 instances. This audit procedure and its negative result will be documented in §4.3. These changes will provide stronger empirical grounding for the oracle interpretation. revision: yes
Circularity Check
No significant circularity: empirical measurements on collected test cases
full rationale
The paper is an empirical evaluation study. It collects 226 real refactoring bugs, applies zero-shot prompting to multiple foundation models, and reports direct accuracy figures (e.g., 93.8 % for GPT-5.4). Metamorphic testing is performed to assess consistency under semantics-preserving variations. No equations, derivations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the abstract or described methodology. All reported results are measurements on the fixed test set rather than quantities that reduce to the inputs by construction. The central claim therefore rests on external experimental data rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fowler, Refactoring: improving the design of existing code, Addison-Wesley, 1999
M. Fowler, Refactoring: improving the design of existing code, Addison-Wesley, 1999
1999
-
[2]
Opdyke, Refactoring Object-oriented Frameworks, Ph.D
W. Opdyke, Refactoring Object-oriented Frameworks, Ph.D. thesis, UIUC (1992)
1992
-
[3]
Roberts, Practical Analysis for Refactoring, Ph.D
D. Roberts, Practical Analysis for Refactoring, Ph.D. thesis, University of Illinois at Urbana-Champaign (1999)
1999
-
[4]
Golubev, Z
Y. Golubev, Z. Kurbatova, E. A. AlOmar, T. Bryksin, M. W. Mkaouer, One thousand and one stories: a large-scale survey of software refactoring, in: Proceedings of the Foundations of Software Engineering, ACM, 2021, p. 1303–1313
2021
-
[5]
Soares, R
G. Soares, R. Gheyi, T. Massoni, Automated Behavioral Testing of Refactoring Engines, IEEE Transactions on Software Engineering 39 (2) (2013) 147–162
2013
-
[6]
Daniel, D
B. Daniel, D. Dig, K. Garcia, D. Marinov, Automated testing of refactoring engines, in: Proceedings of the Foundations of Software Engineering, ACM, 2007, pp. 185–194
2007
-
[7]
Steimann, A
F. Steimann, A. Thies, From public to private to absent: Refactoring Java programs under constrained accessibility, in: Proceedings of European Conference on Object-Oriented Programming, Springer, 2009, pp. 419–443
2009
-
[8]
Soares, R
G. Soares, R. Gheyi, D. Serey, T. Massoni, Making program refactoring safer, IEEE Software 27 (4) (2010) 52–57
2010
-
[9]
Schäfer, O
M. Schäfer, O. de Moor, Specifying and implementing refactorings, in: Proceedings of the Object-Oriented Programming, Systems, Languages, and Applications, ACM, 2010, pp. 286–301
2010
-
[10]
Schäfer, T
M. Schäfer, T. Ekman, O. de Moor, Challenge Proposal: Verification of Refactorings, in: Proceedings of the International Conference on Programming Languages Meets Program Verification, ACM, 2008, pp. 67–72
2008
-
[11]
Bloch, N
J. Bloch, N. Gafter, Java Puzzlers: Traps, Pitfalls, and Corner Cases, Addison-Wesley, 2005
2005
-
[12]
Tempero, T
E. Tempero, T. Gorschek, L. Angelis, Barriers to Refactoring, Communications of the ACM 60 (10) (2017) 54–61
2017
-
[13]
X. Hou, Y. Zhao, Y. Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, H. Wang, Large language models for software engineering: A systematic literature review, Transac- tions on Software Engineering and Methodology 33 (8) (2024) 220:1–220:79
2024
-
[14]
J. Wang, Y. Huang, C. Chen, Z. Liu, S. Wang, Q. Wang, Software testing with large lan- guage models: Survey, landscape, and vision, IEEE Transactions on Software Engineering 50 (2024) 911–936
2024
-
[15]
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, J. M. Zhang, Large language models for software engineering: Survey and open problems, in: Proceedings of the International Conference on Software Engineering: Future of Software Engineering, IEEE, 2023, pp. 31–53
2023
-
[16]
F.Steimann,A.Thies,Frombehaviourpreservationtobehaviourmodification:constraint- based mutant generation, in: Proceedings of the International Conference on Software Engineering, ACM, 2010, pp. 425–434
2010
-
[17]
R. A. DeMillo, R. J. Lipton, F. G. Sayward, Hints on test data selection: Help for the practicing programmer, Computer 11 (4) (1978) 34–41
1978
-
[18]
Y. Jia, M. Harman, An analysis and survey of the development of mutation testing, IEEE Transactions on Software Engineering 37 (5) (2011) 649–678
2011
-
[19]
A. V. Aho, R. Sethi, J. D. Ullman, Compilers: Principles, Techniques, and Tools, Addison- Wesley, Reading, Massachusetts, U.S.A., 1986
1986
-
[20]
Google, Antigravity,https://antigravity.google(2026)
2026
-
[21]
Windsurf, Windsurf AI IDE,https://windsurf.com/editor(2026)
2026
-
[22]
Cursor, The AI Code Editor,https://www.cursor.com(2026)
2026
-
[23]
VSCode, Visual studio code,https://code.visualstudio.com(2026)
2026
-
[24]
JetBrains, IntelliJ IDEA,https://www.jetbrains.com/idea/(2026)
2026
-
[25]
Eclipse.org., Eclipse Project,https://www.eclipse.org/topics/ide/(2026)
2026
-
[26]
Apache, Netbeans IDE,http://www.netbeans.org(2026)
2026
-
[27]
Rachatasumrit, M
N. Rachatasumrit, M. Kim, An empirical investigation into the impact of refactoring on regression testing, in: Proceedings of the International Conference on Software Maintenance, IEEE, 2012, pp. 357–366. 52 Rohit Gheyi et al
2012
-
[28]
Gligoric, F
M. Gligoric, F. Behrang, Y. Li, J. Overbey, M. Hafiz, D. Marinov, Systematic testing of refactoring engines on real software projects, in: Proceedings of the European Conference on Object-Oriented Programming, Springer Berlin, 2013, pp. 629–653
2013
-
[29]
Mongiovi, R
M. Mongiovi, R. Gheyi, G. Soares, L. Teixeira, P. Borba, Making refactoring safer through impact analysis, Science of Computer Programming 93 (2014) 39–64
2014
-
[30]
C. Dong, Y. Jiang, Y. Zhang, Y. Zhang, H. Liu, ChatGPT-based test generation for refactoring engines enhanced by feature analysis on examples, in: Proceedings of the International Conference on Software Engineering, ACM, 2025, pp. 746–746
2025
-
[31]
J. B. Goodenough, S. L. Gerhart, Toward a theory of test data selection, Transactions on Software Engineering 1 (2) (1975) 156–173
1975
-
[32]
H. Wang, Z. Xu, H. Zhang, N. Tsantalis, S. H. Tan, Towards understanding refactoring engine bugs, Transactions on Software Engineering and Methodology 35 (5) (2026) 1–55
2026
-
[33]
Zimmermann, R
T. Zimmermann, R. Premraj, N. Bettenburg, S. Just, A. Schröter, C. Weiss, What makes a good bug report?, IEEE Transactions on Software Engineering 36 (5) (2010) 618–643
2010
-
[34]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Ed- wards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. He...
work page internal anchor Pith review arXiv 2021
-
[35]
B. Atil, S. Aykent, A. Chittams, L. Fu, R. J. Passonneau, E. Radcliffe, G. R. Ra- jagopal, A. Sloan, T. Tudrej, F. Ture, Z. Wu, L. Xu, B. Baldwin, Non-determinism of “deterministic” LLM settings (2025).arXiv:2408.04667
-
[36]
Chiang, L
W.-L. Chiang, L. Zheng, Y. Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang, M. I. Jordan, J. E. Gonzalez, I. Stoica, Chatbot arena: an open platform for evaluating LLMs by human preference, in: Proceedings of the International Conference on Machine Learning, PMLR, 2024, pp. 8359–8388
2024
-
[37]
LangChain API, OllamaLLM,https://api.python.langchain.com/en/latest/ollama/ llms/langchain_ollama.llms.OllamaLLM.html(2026)
2026
-
[38]
OpenAI, Python API library,https://github.com/openai/openai-python(2026)
2026
-
[39]
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, G. Neubig, Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing, ACM Computing Surveys 55 (9) (2023) 1–35
2023
-
[40]
DAIR.AI, Prompt Engineering Guide, https://www.promptingguide.ai/techniques (2026)
2026
-
[41]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, Language models are unsupervised multitask learners, https://cdn.openai.com/better-language-models/ language_models_are_unsupervised_multitask_learners.pdf(2019)
2019
- [42]
-
[43]
Sallou, T
J. Sallou, T. Durieux, A. Panichella, Breaking the silence: the threats of using LLMs in software engineering, in: Proceedings of the International Conference on Software Engineering: New Ideas and Emerging Results, ACM, 2024, pp. 102–106
2024
-
[44]
Applis, A
L. Applis, A. Panichella, R. Marang, Searching for quality: Genetic algorithms and metamorphic testing for software engineering ML, in: Proceedings of the Genetic and Evolutionary Computation Conference, ACM, 2023, pp. 1490–1498
2023
-
[45]
T. Y. Chen, F. Kuo, H. Liu, P. Poon, D. Towey, T. H. Tse, Z. Q. Zhou, Metamorphic testing: A review of challenges and opportunities, Computing Surveys 51 (1) (2018) 4:1–4:27
2018
-
[46]
Pawlak, M
R. Pawlak, M. Monperrus, N. Petitprez, C. Noguera, L. Seinturier, Spoon: A Library for Implementing Analyses and Transformations of Java Source Code, Software: Practice and Experience 46 (9) (2015) 1155–1179
2015
-
[47]
Holtzman, J
A. Holtzman, J. Buys, L. Du, M. Forbes, Y. Choi, The curious case of neural text degeneration, in: International Conference on Learning Representations, OpenReview.net, 2020. Foundation Models as Oracles for Refactoring Correctness Detection 53
2020
-
[48]
Simões, R
P. Simões, R. Gheyi, R. Melo, J. Oliveira, M. Ribeiro, W. Assunção, Refmodel: Detecting refactorings using foundation models, in: Proceedings of the Brazilian Symposium on Software Engineering, SBC, 2025, pp. 811–817
2025
-
[49]
Mongiovi, G
M. Mongiovi, G. Mendes, R. Gheyi, G. Soares, M. Ribeiro, Scaling testing of refactoring engines, in: Proceedings of the International Conference on Software Maintenance and Evolution, IEEE, 2014, pp. 371–380
2014
-
[50]
W. G. Cochran, The comparison of percentages in matched samples, Biometrika 37 (3/4) (1950) 256–266
1950
-
[51]
W. J. Conover, Practical Nonparametric Statistics, Wiley, 1999
1999
-
[52]
McNemar, Note on the sampling error of the difference between correlated proportions or percentages, Psychometrika 12 (2) (1947) 153–157
Q. McNemar, Note on the sampling error of the difference between correlated proportions or percentages, Psychometrika 12 (2) (1947) 153–157
1947
-
[53]
Holm, A simple sequentially rejective multiple test procedure, Scandinavian Journal of Statistics 6 (2) (1979) 65–70
S. Holm, A simple sequentially rejective multiple test procedure, Scandinavian Journal of Statistics 6 (2) (1979) 65–70
1979
-
[54]
F. Batole, A. Bellur, M. Dilhara, M. R. Ullah, Y. Zharov, T. Bryksin, K. Ishikawa, H. Chen, M. Morimoto, S. Motoura, T. Hosomi, T. N. Nguyen, H. Rajan, N. Tsantalis, D. Dig, Leveraging LLMs, IDEs, and semantic embeddings for automated move method refactoring (2025).arXiv:2503.20934
-
[55]
Opdyke, R
W. Opdyke, R. Johnson, Refactoring: An Aid in Designing Application Frameworks and Evolving Object-Oriented Systems, in: Proceedings of the Symposium Object-Oriented Programming Emphasizing Practical Applications, Marist College, 1990, pp. 274–282
1990
-
[56]
Tokuda, D
L. Tokuda, D. Batory, Evolving Object-Oriented Designs with Refactorings, Automated Software Engineering 8 (1) (2001) 89–120
2001
-
[57]
E. A. AlOmar, M. W. Mkaouer, C. D. Newman, A. Ouni, On preserving the behavior in software refactoring: A systematic mapping study, Information and Software Technology 140 (2021) 106675
2021
-
[58]
Drienyovszky, D
D. Drienyovszky, D. Horpácsi, S. J. Thompson, Quickchecking refactoring tools, in: Proceedings of Workshop on Erlang, ACM, 2010, pp. 75–80
2010
-
[59]
M. Kim, T. Zimmermann, N. Nagappan, An empirical study of refactoring challenges and benefits at microsoft, IEEE Transactions on Software Engineering 40 (7) (2014) 633–649
2014
-
[60]
Murphy-Hill, A
E. Murphy-Hill, A. P. Black, Breaking the barriers to successful refactoring: Observations and tools for extract method, in: Proceedings of the International Conference on Software Engineering, ACM, 2008, p. 421–430
2008
-
[61]
A. M. Eilertsen, G. C. Murphy, The usability (or not) of refactoring tools, in: Proceedings of the International Conference on Software Analysis, Evolution and Reengineering, IEEE, 2021, pp. 237–248
2021
-
[62]
K. Horikawa, H. Li, Y. Kashiwa, B. Adams, H. Iida, A. E. Hassan, Agentic refactoring: An empirical study of AI coding agents (2025).arXiv:2511.04824
-
[63]
F. F. Xu, U. Alon, G. Neubig, V. J. Hellendoorn, A systematic evaluation of large language models of code, in: Proceedings of the International Symposium on Machine Programming, ACM, 2022, pp. 1–10
2022
-
[64]
Martinez, L
S. Martinez, L. Xu, M. Elnaggar, E. A. AlOmar, Software refactoring research with large language models: A systematic literature review, Journal of Systems and Software 235 (2026) 112762
2026
-
[65]
J. White, S. Hays, Q. Fu, J. Spencer-Smith, D. C. Schmidt, ChatGPT prompt patterns for improving code quality, refactoring, requirements elicitation, and software design (2023).arXiv:2303.07839
-
[66]
E. A. AlOmar, A. Venkatakrishnan, M. W. Mkaouer, C. D. Newman, A. Ouni, How to refactor this code? An exploratory study on developer-ChatGPT refactoring conver- sations, in: Proceedings of International Conference on Mining Software Repositories, ACM, 2024, pp. 202–206
2024
- [67]
-
[68]
K.Depalma,I.Miminoshvili,C.Henselder,K.Moss,E.A.AlOmar,ExploringChatGPT’s code refactoring capabilities: An empirical study, Expert Systems with Applications 249 (2024) 123602
2024
-
[69]
Pomian, A
D. Pomian, A. Bellur, M. Dilhara, Z. Kurbatova, E. Bogomolov, A. Sokolov, T. Bryksin, D. Dig, EM-assist: Safe automated extract method refactoring with LLMs, in: Companion Proceedings of Foundations of Software Engineering, ACM, 2024, pp. 582–586. 54 Rohit Gheyi et al
2024
-
[70]
An empirical study on the code refactoring capability of large language models,
J. Cordeiro, S. Noei, Y. Zou, An empirical study on the code refactoring capability of large language models (2024).arXiv:2411.02320
-
[71]
Shirafuji, Y
A. Shirafuji, Y. Oda, J. Suzuki, M. Morishita, Y. Watanobe, Refactoring programs using large language models with few-shot examples, in: Proceedings of Asia-Pacific Software Engineering Conference, IEEE, 2023, pp. 151–160
2023
-
[72]
Dilhara, A
M. Dilhara, A. Bellur, T. Bryksin, D. Dig, Unprecedented code change automation: The fusion of LLMs and transformation by example, Proceedings of the ACM on Software Engineering 1 (FSE) (2024) 631–653
2024
-
[73]
Zhang, Y
Y. Zhang, Y. Li, G. Meredith, K. Zheng, X. Li, Move method refactoring recommendation based on deep learning and LLM-generated information, Information Sciences 697 (2025) 121753
2025
-
[74]
H. Liu, Y. Wang, Z. Wei, Y. Xu, J. Wang, H. Li, R. Ji, RefBERT: A two-stage pre- trained framework for automatic rename refactoring, in: Proceedings of the International Symposium on Software Testing and Analysis, ACM, 2023, pp. 740–752
2023
- [75]
-
[76]
K. Oueslati, M. Lamothe, F. Khomh, Refagent: A multi-agent LLM-based framework for automatic software refactoring (2026).arXiv:2511.03153
-
[77]
Pacheco, S
C. Pacheco, S. K. Lahiri, M. D. Ernst, T. Ball, Feedback-directed random test generation, in: Proceedings of the International Conference on Software Engineering, IEEE, 2007, pp. 75–84
2007
-
[78]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Y. Zhang, Y. Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y. Zhang, Y. Chen, L. Wang, A. T. Luu, W. Bi, F. Shi, S. Shi, Siren’s song in the AI ocean: A survey on hallucination in large language models (2023).arXiv:2309.01219
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.