Recognition: unknown
Context-Aware Wireless Token Communication via Joint Token Masking and Detection
Pith reviewed 2026-05-09 16:50 UTC · model grok-4.3
The pith
A shared masked language model lets wireless transmitters omit some tokens and lets receivers recover them from context and noisy channel data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
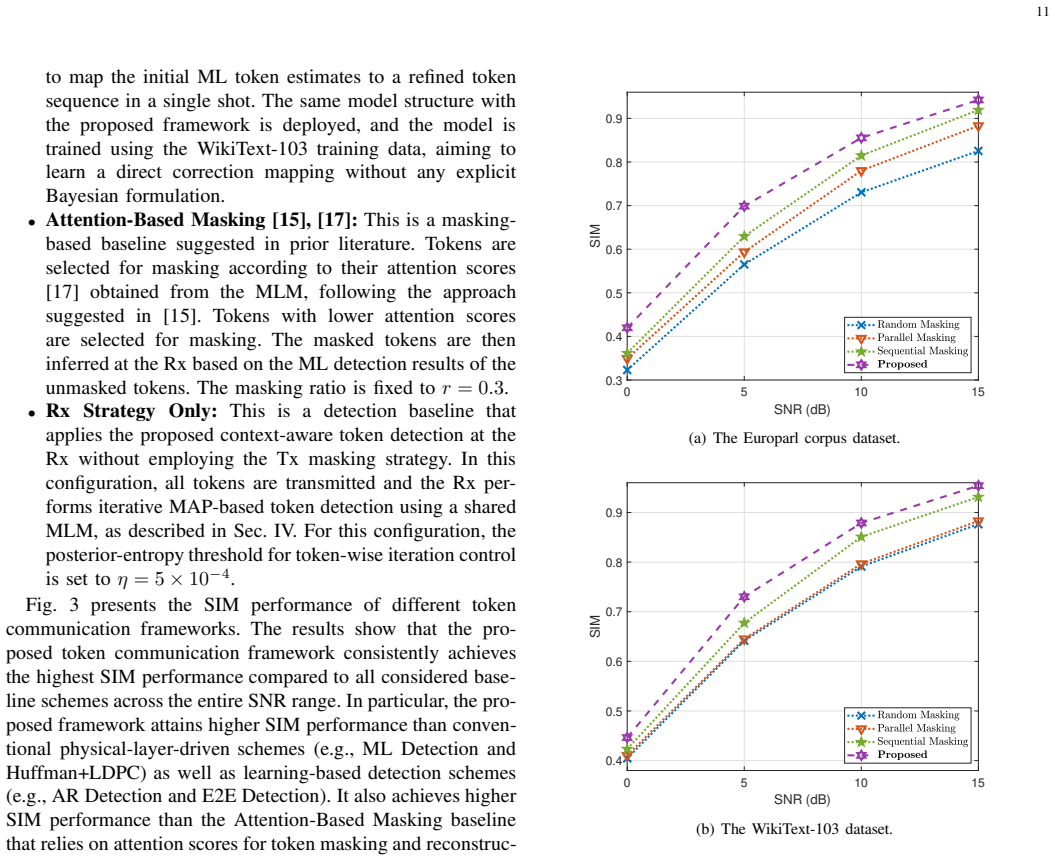
The proposed context-aware token communication framework leverages a masked language model shared between transmitter and receiver. At the transmitter a context-aware masking strategy selectively omits tokens that can be reliably inferred at the receiver, allowing the available power budget to be concentrated on more informative tokens. At the receiver a context-aware token detection method integrates channel likelihoods with MLM-based contextual priors under a Bayesian formulation, enabling robust token inference over noisy channels. These components are jointly designed through the shared MLM, establishing a unified Tx-Rx framework for efficient token transmission and detection.
What carries the argument
Joint token masking at the transmitter and Bayesian detection at the receiver, both driven by the same masked language model that supplies contextual priors.
If this is right
- Transmitters can transmit fewer tokens while maintaining reconstruction quality by relying on receiver-side inference from context.
- Power is allocated non-uniformly, favoring tokens whose omission would most damage contextual recovery.
- Token reconstruction error decreases measurably under the same total power and channel conditions compared with conventional uniform schemes.
- The joint masking-plus-detection design works on large language corpora such as Europarl and WikiText-103.
Where Pith is reading between the lines
- The same principle of semantic skipping could be tested on non-text sequences if a suitable predictive model is substituted for the masked language model.
- Resource allocation in wireless systems may shift from bit-level or symbol-level decisions toward decisions that incorporate semantic recoverability.
- The magnitude of the gains will depend on how well the language model matches the actual token distribution seen at deployment.
Load-bearing premise
The masked language model supplies reliable predictions for omitted tokens even when the wireless channel is noisy and some tokens are missing.
What would settle it
Run the same reconstruction experiment on the Europarl corpus but replace the shared model with a weaker or domain-mismatched language model and measure whether the reported accuracy gains over uniform allocation disappear.
Figures





read the original abstract
The increasing use of token-based representations in language-driven applications has motivated wireless token communication, where tokens are treated as fundamental units for transmission. However, conventional communication systems overlook dependencies among tokens and allocate transmission resources uniformly, leading to inefficient use of limited wireless resources under channel impairments. In this paper, we propose a context-aware token communication framework that leverages a masked language model (MLM) as a shared contextual model between the transmitter (Tx) and receiver (Rx). At the Rx, we develop a context-aware token detection method that integrates channel likelihoods with MLM-based contextual priors under a Bayesian formulation, enabling robust token inference over noisy channels. At the Tx, we propose a context-aware token masking strategy that selectively omits tokens that can be reliably inferred at the Rx, allowing the available power budget to be concentrated on more informative tokens. These components are jointly designed through a shared MLM, establishing a unified Tx-Rx framework for efficient token transmission and detection. Simulation results demonstrate that the proposed framework significantly improves reconstruction performance compared to conventional and existing token communication schemes, achieving up to 1.77X and 1.63X performance gains on the Europarl corpus and WikiText-103 datasets, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a context-aware wireless token communication framework that uses a shared masked language model (MLM) between transmitter and receiver. At the transmitter, a context-aware masking strategy selectively omits tokens that can be reliably inferred from context to concentrate power on informative tokens. At the receiver, a Bayesian token detection method combines channel likelihoods with MLM-based contextual priors for robust inference under noise. Simulations on the Europarl corpus and WikiText-103 dataset report reconstruction performance gains of up to 1.77X and 1.63X, respectively, over conventional and existing token communication schemes.
Significance. If the central claims hold after addressing the gaps, the work would demonstrate a practical way to integrate linguistic priors into physical-layer token transmission, potentially improving spectral efficiency for language-driven wireless applications. The joint Tx-Rx design via a shared MLM is a conceptually clean contribution, and the reported gains on standard corpora provide a starting point for further validation in semantic communications.
major comments (3)
- [Abstract] Abstract: The performance claims of 1.77X and 1.63X gains are presented without any description of the channel models (AWGN, Rayleigh fading, etc.), SNR operating points, baseline schemes (e.g., uniform power allocation or non-contextual masking), error bars, or number of Monte Carlo trials. This information is load-bearing for evaluating whether the gains are statistically significant and attributable to the joint MLM mechanism rather than generic power concentration.
- [Proposed framework (detection component)] The context-aware token detection method: The Bayesian formulation that integrates channel likelihoods with MLM priors p(token | context) is described only at a high level; no explicit expression for the posterior p(token | y, context) or the handling of omitted tokens is provided. Without these details it is impossible to verify that the MLM prior remains reliable after token omission and channel impairment, which is the weakest assumption identified in the stress test.
- [Simulation results] Simulation results: No ablation experiments isolate the contribution of the shared MLM prior (used for both masking and detection) from simpler alternatives such as random masking or non-Bayesian detection. In the absence of such controls, the attribution of the reported gains specifically to the joint Tx-Rx MLM design cannot be confirmed.
minor comments (2)
- [Abstract] The abstract introduces 'token communication' without a brief definition or reference to prior work on token-based semantic communication; a short clarifying sentence would help readers outside the immediate subfield.
- [Token masking strategy] Notation for the masking threshold or rate is listed as a free parameter in the axiom ledger but is never explicitly tied to an equation or algorithm step in the provided description; adding this link would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have revised the manuscript to address each major concern by adding the requested details, explicit formulations, and ablation studies. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims of 1.77X and 1.63X gains are presented without any description of the channel models (AWGN, Rayleigh fading, etc.), SNR operating points, baseline schemes (e.g., uniform power allocation or non-contextual masking), error bars, or number of Monte Carlo trials. This information is load-bearing for evaluating whether the gains are statistically significant and attributable to the joint MLM mechanism rather than generic power concentration.
Authors: We agree that the abstract requires these details to properly contextualize the gains. In the revised version, the abstract now specifies an AWGN channel model, SNR range of 0-20 dB, baselines of uniform power allocation and non-contextual masking, and that results are averaged over 1000 Monte Carlo trials with error bars representing one standard deviation. Corresponding details and figures have also been expanded in Section IV. revision: yes
-
Referee: [Proposed framework (detection component)] The context-aware token detection method: The Bayesian formulation that integrates channel likelihoods with MLM priors p(token | context) is described only at a high level; no explicit expression for the posterior p(token | y, context) or the handling of omitted tokens is provided. Without these details it is impossible to verify that the MLM prior remains reliable after token omission and channel impairment, which is the weakest assumption identified in the stress test.
Authors: The referee is correct that the abstract is high-level. We have added the explicit posterior in the revised Section III-B: p(token_i | y, context) ∝ p(y | token_i) · p(token_i | context), normalized by the evidence. For omitted tokens (zero power), the channel likelihood is replaced by a uniform distribution, so inference relies entirely on the MLM prior. This formulation is now stated clearly to allow verification. revision: yes
-
Referee: [Simulation results] Simulation results: No ablation experiments isolate the contribution of the shared MLM prior (used for both masking and detection) from simpler alternatives such as random masking or non-Bayesian detection. In the absence of such controls, the attribution of the reported gains specifically to the joint Tx-Rx MLM design cannot be confirmed.
Authors: We agree that ablations are needed to attribute gains specifically to the joint design. The revised manuscript includes new ablation results in Section IV: (i) context-aware masking replaced by random masking, and (ii) Bayesian detection replaced by non-Bayesian ML detection using only channel likelihoods. These confirm that both the shared MLM masking and detection components are necessary for the reported improvements. revision: yes
Circularity Check
No significant circularity: novel framework with independent simulation validation
full rationale
The paper proposes a new context-aware token communication framework that jointly designs transmitter masking and receiver Bayesian detection around a shared masked language model. This construction is presented as an original design choice rather than derived from prior equations or self-citations by the same authors. Performance claims rest on simulation results comparing reconstruction on Europarl and WikiText-103 corpora against conventional and existing schemes, which constitute external empirical benchmarks. No load-bearing step reduces by construction to fitted inputs, self-definitional loops, or renamed known results; the MLM is treated as an external contextual prior whose utility is tested rather than assumed tautologically. The derivation chain is therefore self-contained against independent data.
Axiom & Free-Parameter Ledger
free parameters (1)
- masking selection threshold or rate
axioms (1)
- domain assumption Masked language models provide accurate contextual priors for token dependencies even under partial omission and channel noise.
Reference graph
Works this paper leans on
-
[1]
FLS#2 on evaluation assumptions for 6 GR air interface,
3GPP TSG RAN1 WG1, “FLS#2 on evaluation assumptions for 6 GR air interface,” Meeting Rep. #122, Bengaluru, India, Doc. R1-2 506548, 2025
2025
-
[2]
Token communications: A large model-driven framework for cross-modal context-aware semantic communications,
L. Qiao, M. B. Mashhadi, Z. Gao, R. Tafazolli, M. Bennis, a nd D. Niyato, “Token communications: A large model-driven framework for cross-modal context-aware semantic communications,” IEEE Wireless Commun. , vol. 32, no. 5, pp. 80–88, Oct. 2025
2025
-
[3]
Low-complexity sem antic packet aggregation for token communication via lookahead search,
S. Lee, J. Park, J. Choi, and H. Park, “Low-complexity sem antic packet aggregation for token communication via lookahead search, ” 2025, arXiv preprint arXiv:2506.19451
-
[4]
S. Oh, J. Kim, J. Park, S.-W. Ko, J. Choi, T. Q. S. Quek, and S .-L. Kim, “Communication-efficient hybrid language model via un certainty- aware opportunistic and compressed transmission,” 2025, arXiv preprint arXiv:2505.11788
-
[5]
MIMO detection under hardware impairments: Data augmentation with boosti ng,
Y . Kang, S. Jeon, J. Shin, Y .-S. Jeon, and H. V . Poor, “MIMO detection under hardware impairments: Data augmentation with boosti ng,” IEEE Trans. Commun., vol. 73, no. 12, pp. 13549–13562, Dec. 2025
2025
-
[6]
Leveraging large language models for wireless symbol detection via in-context learning,
M. Abbas, K. Kar, and T. Chen, “Leveraging large language models for wireless symbol detection via in-context learning,” in Proc. IEEE Global Commun. Conf. (GLOBECOM) , 2024, pp. 5217–5222
2024
-
[7]
BERT: P re-training of deep bidirectional transformers for language understan ding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: P re-training of deep bidirectional transformers for language understan ding,” in Proc. 2019 Conf. North Amer . Chapter Assoc. Comput. Linguistics: Hum. Lang. Technol., 2019, pp. 4171–4186
2019
-
[8]
Mas ked language model scoring,
J. Salazar, D. Liang, T. Q. Nguyen, and K. Kirchhoff, “Mas ked language model scoring,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguistics (ACL), 2020, pp. 2699–2712
2020
-
[9]
Deep joi nt source channel coding for wireless image transmission,
E. Bourtsoulatze, D. B. Kurka, and D. G¨ und¨ uz, “Deep joi nt source channel coding for wireless image transmission,” IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567–579, Sep. 2019
2019
-
[10]
Deep learning e nabled semantic communication systems,
H. Xie, Z. Qin, G. Y . Li, and B.-H. Juang, “Deep learning e nabled semantic communication systems,” IEEE Trans. Signal Process. , vol. 69, pp. 2663–2675, Apr. 2021
2021
-
[11]
Lightweight joint s ource-channel coding for semantic communications,
Y . Jia, Z. Huang, K. Luo, and W. Wen, “Lightweight joint s ource-channel coding for semantic communications,” IEEE Commun. Lett. , vol. 27, no. 12, pp. 3161–3165, Dec. 2023
2023
-
[12]
Blind Tr aining for Channel-Adaptive Digital Semantic Communications,
Y . Oh, J. Park, J. Choi, J. Park, and Y .-S. Jeon, “Blind Tr aining for Channel-Adaptive Digital Semantic Communications,” IEEE Trans. Commun., vol. 73, no. 11, pp. 11274–11290, Nov. 2025
2025
-
[13]
ESC-MVQ : End-to-end semantic communication with multi-codebook vector quanti zation,
J. Shin, Y . Oh, J. Park, J. Park, and Y .-S. Jeon, “ESC-MVQ : End-to-end semantic communication with multi-codebook vector quanti zation,” IEEE Trans. Wireless Commun., vol. 25, pp. 3785–3800, Jan. 2026
2026
-
[14]
Efficient transformer in ference for extremely weak edge devices using masked autoencoders,
T. Liu, P . Li, Y . Gu, and P . Liu, “Efficient transformer in ference for extremely weak edge devices using masked autoencoders,” in Proc. IEEE Int. Conf. Commun. (ICC), 2023, pp. 1718–1723
2023
-
[15]
Attent ion- aware semantic communications for collaborative inference,
J. Im, N. Kwon, T. Park, J. Woo, J. Lee, and Y . Kim, “Attent ion- aware semantic communications for collaborative inference,” IEEE Internet Things J. , vol. 11, no. 22, pp. 37008–37020, Nov. 2024
2024
-
[16]
J. Park, Y . Oh, Y . Kim, and Y .-S. Jeon, ”Vision transform er-based seman- tic communications with importance-aware quantization,” IEEE Internet Things J. , vol. 12, no. 17, pp. 35662–35677, Sep. 2025
2025
-
[17]
Attention is all you need,
A. V aswani et al., “Attention is all you need,” Adv. Neural Inf. Process. Syst., vol. 30, 2017, pp. 5998–6008
2017
-
[18]
Adaptive semantic token communication for transformer-b ased edge in- ference,
A. Devoto, J. Pomponi, M. Merluzzi, P . Di Lorenzo, and S. Scardapane, “Adaptive semantic token communication for transformer-b ased edge in- ference,” IEEE Trans. Mach. Learn. Commun. Netw. , vol. 4, pp. 422–437, Jan. 2026
2026
-
[19]
Large-language-model enabled semanti c communication systems,
Z. Wang et al., “Large-language-model enabled semanti c communication systems,” 2024, arXiv preprint arXiv:2407.14112
-
[20]
Semantic coding for t ext transmission: An iterative design,
S. Y ao, K. Niu, S. Wang, and J. Dai, “Semantic coding for t ext transmission: An iterative design,” IEEE Trans. Cogn. Commun. Netw. , vol. 8, no. 4, pp. 1594–1603, Dec. 2022
2022
-
[21]
Conte xt-aware iterative token detection and masked transmission for wireless token communica- tion,
J. Shin, J. Park, J. Park, J. Choi, and Y .-S. Jeon, “Conte xt-aware iterative token detection and masked transmission for wireless token communica- tion,” 2026, arXiv preprint arXiv:2601.17770
-
[22]
Capacity of wireless channels,
A. Goldsmith, “Capacity of wireless channels,” in Wireless communica- tion. Cambridge, U.K.: Cambridge Univ. Press, 2005
2005
-
[23]
Tse and P
D. Tse and P . Viswanath, Fundamentals of Wireless Communication . Cambridge, U.K.: Cambridge Univ. Press, 2005
2005
-
[24]
Turbo equali zation: principles and new results,
M. T ¨ uchler, R. Koetter, and A. C. Singer, “Turbo equali zation: principles and new results,” IEEE Trans. Commun., vol. 50, no. 5, pp. 754–767, May 2002
2002
-
[25]
On the general BER expression of one- and two- dimensional amplitude modulations,
K. Cho and D. Y oon, “On the general BER expression of one- and two- dimensional amplitude modulations,” IEEE Trans. Commun. , vol. 50, no. 7, pp. 1074–1080, Jul. 2002
2002
-
[26]
Europarl: A parallel corpus for statistical machine translation,
P . Koehn, “Europarl: A parallel corpus for statistical machine translation,” in Proc. Mach. Transl. Summit X: Papers , 2005, pp. 79–86
2005
-
[27]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointe r sentinel mixture models,” 2016, arXiv preprint arXiv:1609.07843
work page internal anchor Pith review arXiv 2016
-
[28]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Y . Wu et al., “Google’s neural machine translation syst em: Bridging the gap between human and machine translation,” 2016, arXiv preprint arXiv:1609.08144
work page internal anchor Pith review arXiv 2016
-
[29]
Large language model enhanced multi-a gent systems for 6G communications,
F. Jiang et al., “Large language model enhanced multi-a gent systems for 6G communications,” IEEE Wireless Commun. , vol. 31, no. 6, pp. 48–55, Dec. 2024
2024
-
[30]
Exploring LLM-based multi-agent situat ion awareness for zero-trust space-air-ground integrated network,
X. Cao et al., “Exploring LLM-based multi-agent situat ion awareness for zero-trust space-air-ground integrated network,” IEEE J. Sel. Areas Commun., vol. 43, no. 6, pp. 2230–2247, Jun. 2025
2025
-
[31]
Min ilm: Deep self-attention distillation for task-agnostic compr ession of pretrained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Y ang, and M. Zhou, “Min ilm: Deep self-attention distillation for task-agnostic compr ession of pretrained transformers,” Adv. Neural Inf. Process. Syst. , pp. 5776–5788, 2020
2020
-
[32]
MPNet: Masked and perm uted pre- training for language understanding,
K. Song, X. Tan, T. Qin, and J. Lu, “MPNet: Masked and perm uted pre- training for language understanding,” Adv. Neural Inf. Process. Syst. , pp. 16857–16867, 2020
2020
-
[33]
A method for the construction of minimum -redundancy codes,
D. A. Huffman, “A method for the construction of minimum -redundancy codes,” Proc. Inst. Radio Eng. , vol. 40, no. 9, pp. 1098–1101, 1952
1952
-
[34]
Low-density parity-check codes,
R. G. Gallager, “Low-density parity-check codes,” IRE Trans. Inf. Theory, vol. 8, no. 1, pp. 21–28, Jan. 1962
1962
-
[35]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sut skever, “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.