SlimDiffSR: Toward Lightweight and Efficient Remote Sensing Image Super-Resolution via Diffusion Model Distillation
Pith reviewed 2026-05-21 01:03 UTC · model grok-4.3
The pith
SlimDiffSR distills and prunes a diffusion model to accelerate remote sensing super-resolution up to 200 times with competitive quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By linking reconstruction difficulty to diffusion timesteps through uncertainty guidance and applying structured pruning with frequency-separable, direction-separable, and query-driven modules suited to remote sensing imagery, along with MMD-based distillation, SlimDiffSR creates an efficient single-step model that achieves substantial acceleration and parameter reduction while delivering competitive perceptual quality on remote sensing benchmarks.
What carries the argument
The uncertainty-guided timestep assignment for single-step teacher construction and the structured pruning strategy with frequency-separable convolution, direction-separable convolution, and query-driven global aggregation modules.
If this is right
- Practical deployment of generative super-resolution becomes possible in remote sensing workflows with limited computational resources.
- The model outperforms existing lightweight diffusion baselines in terms of efficiency while matching perceptual quality.
- Real-world remote sensing applications benefit from faster processing of high-resolution imagery without heavy hardware requirements.
Where Pith is reading between the lines
- The separable convolution designs could inspire efficiency improvements in other computer vision tasks involving directional or frequency-specific data.
- Extending the uncertainty-guided approach to multi-step distillation might further optimize the quality-efficiency tradeoff in generative models.
- Applying similar pruning to diffusion models for natural images could test the domain-specific advantages claimed here.
Load-bearing premise
The proposed uncertainty-guided timestep assignment and domain-specific pruning modules will preserve the generative quality of the original diffusion model on real-world remote sensing data after aggressive structured pruning.
What would settle it
Running SlimDiffSR and a full multi-step diffusion model on a diverse set of unseen real-world remote sensing images and finding significantly degraded perceptual quality or visible artifacts in the lightweight version would falsify the claim of competitive quality at high efficiency.
Figures











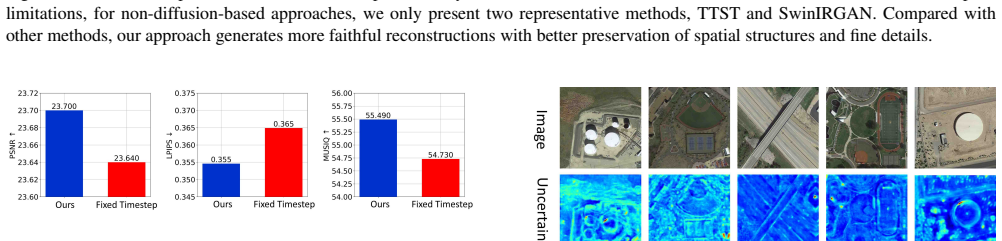



read the original abstract
Diffusion models have recently achieved remarkable performance in image super-resolution (SR), but their high computational cost limits practical deployment in remote sensing applications. To address this issue, we propose SlimDiffSR, a lightweight and efficient diffusion-based framework for real-world remote sensing image super-resolution. Unlike existing single-step diffusion methods that rely on fixed timesteps, we first introduce an uncertainty-guided timestep assignment strategy to construct a stronger single-step teacher model, where reconstruction difficulty is explicitly linked to diffusion timesteps, enabling adaptive generative strength. Building upon this teacher, we further present a structured pruning strategy tailored to remote sensing imagery, which systematically removes redundant semantic modules and replaces standard operations with lightweight designs, including frequency-separable convolution, direction-separable convolution, and a query-driven global aggregation module. These components explicitly exploit the unique characteristics of remote sensing data, such as sparse high-frequency details, strong directional patterns, and long-range spatial dependencies. To enhance knowledge transfer, we incorporate Maximum Mean Discrepancy (MMD) into the distillation process to align feature distributions between the teacher and student models. Extensive experiments on multiple remote sensing benchmarks demonstrate that SlimDiffSR achieves a favorable balance between efficiency and reconstruction quality. In particular, it attains up to $200\times$ inference acceleration and a $20\times$ reduction in model parameters compared with multi-step diffusion models, while achieving competitive perceptual quality and clearly outperforming existing lightweight diffusion baselines in efficiency. The code is available at: https://github.com/wwangcece/SlimDiffSR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SlimDiffSR, a lightweight diffusion-based framework for real-world remote sensing image super-resolution. It first constructs a single-step teacher via an uncertainty-guided timestep assignment strategy that links reconstruction difficulty to diffusion timesteps. This teacher is then distilled into a student model using structured pruning that replaces standard operations with frequency-separable convolution, direction-separable convolution, and a query-driven global aggregation module, explicitly motivated by remote-sensing data properties such as sparse high-frequency content, directional patterns, and long-range dependencies. Knowledge transfer is further improved by incorporating Maximum Mean Discrepancy (MMD) into the distillation loss. The central empirical claims are up to 200× inference acceleration and 20× parameter reduction relative to multi-step diffusion baselines while preserving competitive perceptual quality on remote-sensing benchmarks.
Significance. If the reported efficiency gains are reproducible and the quality holds on diverse real-world remote-sensing imagery, the work would provide a practical route to deploying diffusion-based super-resolution in compute-constrained remote-sensing pipelines. The domain-specific pruning and distillation choices constitute a targeted response to the computational barriers that currently limit diffusion SR outside controlled laboratory settings.
major comments (3)
- [§3.2] §3.2 (uncertainty-guided timestep assignment): the precise definition and computation of per-pixel or per-patch uncertainty used to select the single timestep is not formalized; without an explicit equation or algorithm, it is unclear whether the claimed adaptive generative strength is a direct consequence of the construction or an empirical outcome that may not generalize.
- [§4] §4 (experimental results): the headline 200× acceleration and 20× parameter-reduction figures are stated without reference to the exact baseline models, hardware platform, or batch-size settings used for timing; the absence of these details in the evaluation section makes it impossible to verify that the gains are load-bearing for the central efficiency claim rather than artifacts of unstated measurement choices.
- [§3.3] §3.3 (structured pruning): the criterion for identifying and removing “redundant semantic modules” is described only qualitatively; a quantitative importance score or pruning schedule (e.g., via Eq. (X) or Algorithm 1) is required to substantiate that the 20× reduction is achieved without circular reliance on post-hoc tuning.
minor comments (3)
- [Figure 2] Figure 2 (architecture diagram) would benefit from explicit labeling of the frequency-separable and direction-separable blocks to match the textual description in §3.3.
- [§3.4] The MMD loss formulation in §3.4 should include the kernel choice and bandwidth selection procedure, as these hyperparameters directly affect the reported distillation quality.
- [§2] A short paragraph comparing SlimDiffSR to recent non-diffusion lightweight SR methods (e.g., those based on efficient transformers) would strengthen the positioning in the related-work section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for improving clarity and rigor, particularly regarding formalization of key components and experimental details. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (uncertainty-guided timestep assignment): the precise definition and computation of per-pixel or per-patch uncertainty used to select the single timestep is not formalized; without an explicit equation or algorithm, it is unclear whether the claimed adaptive generative strength is a direct consequence of the construction or an empirical outcome that may not generalize.
Authors: We agree that the original description of the uncertainty-guided timestep assignment lacked sufficient formalization. In the revised manuscript, Section 3.2 now includes an explicit definition of per-patch uncertainty as the variance of pixel-wise reconstruction errors estimated over a small set of forward diffusion steps, together with the assignment rule that maps higher uncertainty to earlier timesteps. We have also added Algorithm 1 that details the computation and selection procedure. This formulation makes the adaptive generative strength a direct consequence of the construction rather than an empirical observation. revision: yes
-
Referee: [§4] §4 (experimental results): the headline 200× acceleration and 20× parameter-reduction figures are stated without reference to the exact baseline models, hardware platform, or batch-size settings used for timing; the absence of these details in the evaluation section makes it impossible to verify that the gains are load-bearing for the central efficiency claim rather than artifacts of unstated measurement choices.
Authors: We appreciate this observation. The reported 200× acceleration and 20× parameter reduction were obtained by comparing against the multi-step diffusion baseline (the teacher model before distillation) on an NVIDIA RTX 3090 GPU with batch size 1 and 256×256 input patches. In the revised Section 4 we have added a dedicated timing subsection that lists all baseline models, hardware specifications, batch sizes, and measurement protocol (including warm-up iterations) to ensure the efficiency claims are fully reproducible and load-bearing. revision: yes
-
Referee: [§3.3] §3.3 (structured pruning): the criterion for identifying and removing “redundant semantic modules” is described only qualitatively; a quantitative importance score or pruning schedule (e.g., via Eq. (X) or Algorithm 1) is required to substantiate that the 20× reduction is achieved without circular reliance on post-hoc tuning.
Authors: We concur that a quantitative criterion strengthens the pruning description. The revised Section 3.3 now defines an importance score for each semantic module as the average L2 norm of its output feature maps computed on a held-out remote-sensing validation set. Modules below a threshold (determined by a single hyper-parameter sweep reported in the supplement) are removed according to the schedule in new Equation (3). This explicit score and schedule replace the previous qualitative account and demonstrate that the 20× reduction follows systematically from the importance ordering. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical pipeline consisting of uncertainty-guided timestep assignment, structured pruning with separable convolutions and query-driven modules, plus MMD distillation. All performance claims (200× acceleration, 20× parameter reduction, competitive perceptual quality) are reported as measured outcomes on remote-sensing benchmarks rather than derived quantities. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the construction is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Remote sensing imagery exhibits sparse high-frequency details, strong directional patterns, and long-range spatial dependencies that can be explicitly exploited by specialized convolutions and aggregation modules.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
uncertainty-guided timestep assignment strategy... frequency-separable convolution, direction-separable convolution, and a query-driven global aggregation module... MMD into the distillation process
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
structured pruning strategy tailored to remote sensing imagery... 200× inference acceleration and a 20× reduction in model parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 10
work page 2021
-
[2]
Adversarial diffusion compression for real-world image super-resolution
Bin Chen, Gehui Li, Rongyuan Wu, Xindong Zhang, Jie Chen, Jian Zhang, and Lei Zhang. Adversarial diffusion compression for real-world image super-resolution. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 28208–28220, 2025. 2, 4, 8, 11
work page 2025
-
[3]
Activating more pixels in image super- resolution transformer
Xiangyu Chen, Xintao Wang, Jiantao Zhou, Yu Qiao, and Chao Dong. Activating more pixels in image super- resolution transformer. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22367–22377, 2023. 1
work page 2023
-
[4]
Yu-Zhang Chen, Tsung-Jung Liu, and Kuan-Hsien Liu. Super-resolution of satellite images based on two- dimensional rrdb and edge-enhanced generative adversarial network. In2022 IEEE International Conference on Consumer Electronics (ICCE), pages 1–4. IEEE, 2022. 4
work page 2022
-
[5]
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sens- ing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017. 10
work page 2017
-
[6]
Learning a deep convolutional network for image super-resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part IV 13, pages 184–199. Springer,
work page 2014
-
[7]
Adaptive sparseness using jeffreys prior
M ´ario Figueiredo. Adaptive sparseness using jeffreys prior. Advances in neural information processing systems, 14,
-
[8]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 1
work page 2020
-
[9]
Comparing hybrid nn-hmm and rnn for temporal modeling in gesture recognition
Nicolas Granger and Moun ˆım A el Yacoubi. Comparing hybrid nn-hmm and rnn for temporal modeling in gesture recognition. InNeural Information Processing: 24th In- ternational Conference, ICONIP 2017, Guangzhou, China, November 14-18, 2017, Proceedings, Part II 24, pages 147–
work page 2017
-
[10]
A kernel two-sample test.The journal of machine learning research, 13(1):723– 773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bern- hard Sch¨olkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723– 773, 2012. 3, 9
work page 2012
-
[11]
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, et al. Skysense: A multi-modal remote sens- ing foundation model towards universal interpretation for earth observation imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27672–27683, 2024. 9
work page 2024
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1
work page 2020
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 10
work page 2022
-
[14]
Bo Huang, Huihui Song, Hengbin Cui, Jigen Peng, and Zongben Xu. Spatial and spectral image fusion using sparse matrix factorization.IEEE Transactions on Geoscience and Remote Sensing, 52(3):1693–1704, 2013. 1
work page 2013
-
[15]
Percep- tual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Percep- tual losses for real-time style transfer and super-resolution. InComputer Vision–ECCV 2016: 14th European Confer- ence, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, pages 694–711. Springer, 2016. 1
work page 2016
-
[16]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 11
work page 2021
-
[17]
Samar Khanna, Patrick Liu, Linqi Zhou, Chenlin Meng, Robin Rombach, Marshall Burke, David Lobell, and Stefano Ermon. Diffusionsat: A generative foundation model for satellite imagery.arXiv preprint arXiv:2312.03606, 2023. 4
-
[18]
Bk-sdm: A lightweight, fast, and cheap ver- sion of stable diffusion
Bo-Kyeong Kim, Hyoung-Kyu Song, Thibault Castells, and Shinkook Choi. Bk-sdm: A lightweight, fast, and cheap ver- sion of stable diffusion. InEuropean Conference on Com- puter Vision, pages 381–399. Springer, 2024. 2
work page 2024
-
[19]
Accurate image super-resolution using very deep convolutional net- works
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional net- works. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1646–1654, 2016. 1, 3
work page 2016
-
[20]
Classsr: A general framework to accelerate super- resolution networks by data characteristic
Xiangtao Kong, Hengyuan Zhao, Yu Qiao, and Chao Dong. Classsr: A general framework to accelerate super- resolution networks by data characteristic. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12016–12025, 2021. 5
work page 2021
-
[21]
Charis Lanaras, Jos ´e Bioucas-Dias, Silvano Galliani, Em- manuel Baltsavias, and Konrad Schindler. Super-resolution of sentinel-2 images: Learning a globally applicable deep neural network.ISPRS Journal of Photogrammetry and Re- mote Sensing, 146:305–319, 2018. 4
work page 2018
-
[22]
Photo- realistic single image super-resolution using a generative ad- versarial network
Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo- realistic single image super-resolution using a generative ad- versarial network. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4681–4690,
-
[23]
Sen Lei, Zhenwei Shi, and Wenjing Mo. Transformer-based multistage enhancement for remote sensing image super- resolution.IEEE Transactions on Geoscience and Remote Sensing, 60:1–11, 2021. 11
work page 2021
-
[24]
Srdiff: Single image super-resolution with diffusion probabilistic models
Haoying Li, Yifan Yang, Meng Chang, Shiqi Chen, Huajun Feng, Zhihai Xu, Qi Li, and Yueting Chen. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing, 479:47–59, 2022. 4
work page 2022
-
[25]
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS journal of photogram- metry and remote sensing, 159:296–307, 2020. 1, 10
work page 2020
-
[26]
Xinrui Li, Jianlong Wu, Xinchuan Huang, Chong Chen, Weili Guan, Xian-Sheng Hua, and Liqiang Nie. Megasr: Mining customized semantics and expressive guidance for image super-resolution.arXiv e-prints, pages arXiv–2503,
-
[27]
Yadong Li, Sebastien Mavromatis, Feng Zhang, Zhenhong Du, Jean Sequeira, Zhongyi Wang, Xianwei Zhao, and Renyi Liu. Single-image super-resolution for remote sensing im- ages using a deep generative adversarial network with lo- cal and global attention mechanisms.IEEE Transactions on Geoscience and Remote Sensing, 60:1–24, 2021. 4
work page 2021
-
[28]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1833–1844,
-
[29]
Jie Liang, Hui Zeng, and Lei Zhang. Details or artifacts: A locally discriminative learning approach to realistic im- age super-resolution. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5657–5666, 2022. 1
work page 2022
-
[30]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean Conference on Computer Vision, pages 430–448. Springer, 2024. 1, 4, 11
work page 2024
-
[31]
Bo Liu, Heng Li, Yutao Zhou, Yuqing Peng, Ahmed Elazab, and Changmiao Wang. A super resolution method for re- mote sensing images based on cascaded conditional wasser- stein gans. In2020 IEEE 3rd International Conference on In- formation Communication and Signal Processing (ICICSP), pages 284–289. IEEE, 2020. 4
work page 2020
-
[32]
Residual denoising diffu- sion models
Jiawei Liu, Qiang Wang, Huijie Fan, Yinong Wang, Yan- dong Tang, and Liangqiong Qu. Residual denoising diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2773– 2783, 2024. 2, 4
work page 2024
-
[33]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787,
-
[34]
Wen Ma, Zongxu Pan, Feng Yuan, and Bin Lei. Super- resolution of remote sensing images via a dense residual gen- erative adversarial network.Remote Sensing, 11(21):2578,
-
[35]
Qian Ning, Weisheng Dong, Xin Li, Jinjian Wu, and Guang- ming Shi. Uncertainty-driven loss for single image super- resolution.Advances in Neural Information Processing Sys- tems, 34:16398–16409, 2021. 2, 5
work page 2021
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 4
work page 2022
-
[37]
Chitwan Saharia, Jonathan Ho, William Chan, Tim Sali- mans, David J Fleet, and Mohammad Norouzi. Image super- resolution via iterative refinement.IEEE transactions on pattern analysis and machine intelligence, 45(4):4713–4726,
-
[38]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[39]
Xin-Yi Tong, Gui-Song Xia, Qikai Lu, Huanfeng Shen, Shengyang Li, Shucheng You, and Liangpei Zhang. Land- cover classification with high-resolution remote sensing im- ages using transferable deep models.Remote Sensing of En- vironment, 237:111322, 2020. 1
work page 2020
-
[40]
Caglayan Tuna, Gozde Unal, and Elif Sertel. Single-frame super resolution of remote-sensing images by convolutional neural networks.International journal of remote sensing, 39 (8):2463–2479, 2018. 3
work page 2018
-
[41]
Zander S Venter, Oscar Brousse, Igor Esau, and Fred Meier. Hyperlocal mapping of urban air temperature using remote sensing and crowdsourced weather data.Remote Sensing of Environment, 242:111791, 2020. 1
work page 2020
-
[42]
p+: Ex- tended textual conditioning in text-to-image generation,
Andrey V oynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. p+: Extended textual conditioning in text-to- image generation.arXiv preprint arXiv:2303.09522, 2023. 2, 8
-
[43]
Ce Wang and Wanjie Sun. Semantic guided large scale factor remote sensing image super-resolution with generative dif- fusion prior.ISPRS Journal of Photogrammetry and Remote Sensing, 220:125–138, 2025. 4
work page 2025
-
[44]
Ce Wang and Wanjie Sun. Controllable reference-guided dif- fusion with local-global fusion for real-world remote sensing super-resolution.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2026. 10, 12
work page 2026
-
[45]
Timestep-aware diffusion model for extreme image rescal- ing
Ce Wang, Zhenyu Hu, Wanjie Sun, and Zhenzhong Chen. Timestep-aware diffusion model for extreme image rescal- ing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 15594–15603, 2025. 2, 6
work page 2025
-
[46]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12):5929–5949, 2024. 1, 2, 4
work page 2024
-
[47]
Esrgan: En- hanced super-resolution generative adversarial networks
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: En- hanced super-resolution generative adversarial networks. In Proceedings of the European conference on computer vision (ECCV) workshops, pages 0–0, 2018. 11
work page 2018
-
[48]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
work page 1905
-
[49]
Zhihao Wang, Jian Chen, and Steven CH Hoi. Deep learn- ing for image super-resolution: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(10):3365– 3387, 2020. 1
work page 2020
-
[50]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024. 2, 4
work page 2024
-
[51]
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Yanfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. Aid: A benchmark data set for performance evaluation of aerial scene classification.IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965–3981, 2017. 10
work page 2017
-
[52]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Be- longie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liang- pei Zhang. Dota: A large-scale dataset for object detection in aerial images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983,
-
[53]
Ediffsr: An efficient diffusion prob- abilistic model for remote sensing image super-resolution
Yi Xiao, Qiangqiang Yuan, Kui Jiang, Jiang He, Xianyu Jin, and Liangpei Zhang. Ediffsr: An efficient diffusion prob- abilistic model for remote sensing image super-resolution. IEEE Transactions on Geoscience and Remote Sensing, 62: 1–14, 2023. 4, 11
work page 2023
-
[54]
Yi Xiao, Qiangqiang Yuan, Kui Jiang, Jiang He, Chia-Wen Lin, and Liangpei Zhang. Ttst: A top-k token selective trans- former for remote sensing image super-resolution.IEEE Transactions on Image Processing, 33:738–752, 2024. 11
work page 2024
-
[55]
High quality remote sensing image super-resolution using deep memory connected network
Wenjia Xu, XU Guangluan, Yang Wang, Xian Sun, Daoyu Lin, and WU Yirong. High quality remote sensing image super-resolution using deep memory connected network. In IGARSS 2018-2018 IEEE International Geoscience and Re- mote Sensing Symposium, pages 8889–8892. IEEE, 2018. 4
work page 2018
-
[56]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022. 11
work page 2022
-
[57]
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. Resshift: Efficient diffusion model for image super- resolution by residual shifting.Advances in Neural Infor- mation Processing Systems, 36:13294–13307, 2023. 1, 2, 4
work page 2023
-
[58]
Aiping Zhang, Zongsheng Yue, Renjing Pei, Wenqi Ren, and Xiaochun Cao. Degradation-guided one-step im- age super-resolution with diffusion priors.arXiv preprint arXiv:2409.17058, 2024. 2, 4, 11
-
[59]
Jizhou Zhang, Tingfa Xu, Jianan Li, Shenwang Jiang, and Yuhan Zhang. Single-image super resolution of remote sens- ing images with real-world degradation modeling.Remote Sensing, 14(12):2895, 2022. 4
work page 2022
-
[60]
Ntire 2020 chal- lenge on perceptual extreme super-resolution: Methods and results
Kai Zhang, Shuhang Gu, and Radu Timofte. Ntire 2020 chal- lenge on perceptual extreme super-resolution: Methods and results. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition workshops, pages 492– 493, 2020. 12
work page 2020
-
[61]
Real-world image super-resolution as multi-task learning
Wenlong Zhang, Xiaohui Li, Guangyuan Shi, Xiangyu Chen, Yu Qiao, Xiaoyun Zhang, Xiao-Ming Wu, and Chao Dong. Real-world image super-resolution as multi-task learning. Advances in Neural Information Processing Systems, 36: 21003–21022, 2023. 1
work page 2023
-
[62]
Residual dense network for image super-resolution
Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018. 1
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.