Measuring Differences between Conditional Distributions using Kernel Embeddings
Pith reviewed 2026-05-08 19:19 UTC · model grok-4.3
The pith
Kernel embeddings define a family of metrics for measuring differences between conditional distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
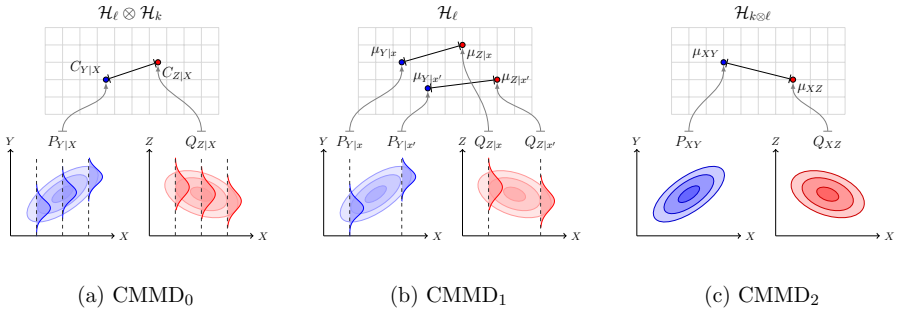
The CMMD consists of a family of metrics which we call levels, with three special cases each using a different type of RKHS embedding: CMMD0 (conditional mean operators), CMMD1 (conditional mean embeddings), and CMMD2 (joint mean embeddings). We additionally introduce a general level s CMMD, clarifying the required assumptions, and establishing mathematical connections between the levels through the lens of operator-based smoothing. In addition to reviewing previously proposed estimators, we introduce a novel doubly robust estimator for the CMMD that maintains consistency provided at least one of the underlying models is correctly specified.
What carries the argument
The conditional maximum mean discrepancy (CMMD) family, which quantifies differences between conditional distributions through RKHS embeddings at varying levels connected by operator smoothing.
If this is right
- The levels of CMMD provide a hierarchy allowing comparisons under different assumptions on the conditional distributions.
- The doubly robust estimator enables consistent measurement of discrepancies without requiring full correctness of both models.
- CMMD supports statistical testing that detects complex conditional dependencies, as verified in numerical experiments.
- Operator smoothing establishes explicit mathematical links between different embedding-based approaches to conditional comparison.
Where Pith is reading between the lines
- The smoothing connections between levels suggest the framework could unify other kernel-based conditional tests beyond those reviewed.
- The robustness property may extend naturally to settings like causal effect estimation where conditional distributions are central.
- Applying the general level s CMMD to high-dimensional or structured data could reveal practical performance differences among levels.
Load-bearing premise
The doubly robust estimator maintains consistency only when at least one of the models for the conditional distribution or the embedding is correctly specified.
What would settle it
An experiment where the estimator fails to converge to the true value when both the conditional distribution model and the embedding model are deliberately misspecified would challenge the consistency claim.
Figures








read the original abstract
Comparing conditional distributions is a fundamental challenge in statistics and machine learning, with applications across a wide range of domains. While proposed methods for measuring discrepancies using kernel embeddings of distributions in a reproducing kernel Hilbert space (RKHS) provide powerful non-parametric techniques, the existing literature remains fragmented and lacks a unified theoretical treatment. This paper addresses this gap by establishing a coherent framework for studying kernel-based methods to measure divergence between conditional distributions through what we refer to as conditional maximum mean discrepancy (CMMD). The CMMD consists of a family of metrics which we call levels, with three special cases each using a different type of RKHS embedding: CMMD$_0$ (conditional mean operators), CMMD$_1$ (conditional mean embeddings), and CMMD$_2$ (joint mean embeddings). We additionally introduce a general level $s$ CMMD, clarifying the required assumptions, and establishing mathematical connections between the levels through the lens of operator-based smoothing. In addition to reviewing previously proposed estimators, we introduce a novel doubly robust estimator for the CMMD that maintains consistency provided at least one of the underlying models is correctly specified. We provide numerical experiments demonstrating that the CMMD effectively captures complex conditional dependencies for statistical testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified framework called conditional maximum mean discrepancy (CMMD) for measuring differences between conditional distributions via RKHS kernel embeddings. It defines a family of metrics at different 'levels': CMMD0 using conditional mean operators, CMMD1 using conditional mean embeddings, CMMD2 using joint mean embeddings, plus a general level-s version. Mathematical connections between levels are established through operator-based smoothing, assumptions are clarified, prior estimators are reviewed, and a novel doubly robust estimator is introduced whose consistency requires only that at least one of the two nuisance models (conditional distribution or embedding) is correctly specified. Numerical experiments illustrate effectiveness for statistical testing of conditional dependencies.
Significance. If the claimed connections via smoothing operators and the doubly-robust consistency property hold with the stated proofs, the work provides a coherent unification of previously fragmented kernel methods for conditional discrepancies. The doubly robust estimator is a clear practical advance in the semiparametric RKHS setting, and the level-s generalization with explicit assumptions strengthens the theoretical foundation. These elements would make the manuscript a useful reference for nonparametric conditional inference.
major comments (1)
- [§4.2] §4.2, Theorem 4 (doubly robust estimator): the consistency argument under the 'at least one correct model' condition is load-bearing for the main contribution; the provided derivation should explicitly bound the cross-term bias using the RKHS norm of the smoothing operator rather than invoking it only asymptotically.
minor comments (3)
- [Abstract] Abstract: the description of numerical experiments omits the specific datasets, sample sizes, and baseline methods used; a one-sentence summary would improve clarity.
- [§3.1] §3.1, Eq. (7): the notation for the conditional mean operator could be aligned more explicitly with the subsequent level-1 and level-2 definitions to ease comparison.
- [§5] §5: the caption of Figure 2 should state the kernel bandwidth selection procedure and the number of Monte Carlo repetitions for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and for the constructive comment on the doubly robust estimator. We address the point below.
read point-by-point responses
-
Referee: [§4.2] §4.2, Theorem 4 (doubly robust estimator): the consistency argument under the 'at least one correct model' condition is load-bearing for the main contribution; the provided derivation should explicitly bound the cross-term bias using the RKHS norm of the smoothing operator rather than invoking it only asymptotically.
Authors: We thank the referee for highlighting this point. We agree that the current derivation of the cross-term bias in the proof of Theorem 4 relies on an asymptotic argument and would benefit from an explicit finite-sample bound expressed via the RKHS norm of the smoothing operator (as introduced in the operator-smoothing connections of Section 3). In the revised manuscript we will expand the proof in §4.2 to derive and insert this bound, using the same operator-norm control already established for the level-s family. The revised argument will remain fully rigorous under the stated 'at least one correct model' condition and will not alter the theorem statement or its implications. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines the CMMD family via standard RKHS embeddings (conditional mean operators, mean embeddings, joint embeddings) and operator smoothing, then reviews estimators and proposes a doubly-robust one whose consistency property follows directly from semiparametric theory requiring only one correct nuisance model. No derivation step reduces by construction to a fitted parameter, self-referential definition, or load-bearing self-citation; all connections are derived from established kernel and operator theory without renaming known results or smuggling ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reproducing kernel Hilbert spaces admit well-defined mean embeddings and conditional mean operators for the distributions of interest.
invented entities (1)
-
CMMD levels (0, 1, 2, and general s)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (J(x) = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CMMD_s^2(P_Y|X, Q_Z|X) = ‖Δ C_XX^{s/2}‖^2 = Tr(Δ* Δ C_XX^s) where s ≥ 0. ... intuitively higher levels correspond to greater amounts of smoothing caused by the marginal distribution of X.
-
IndisputableMonolith/Foundation (forcing chain, parameter-free derivations)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a novel doubly robust estimator for the CMMD that maintains consistency provided at least one of the underlying models is correctly specified.
-
IndisputableMonolith/Foundation/AlexanderDuality (integer dimension forcing)alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Considering fractional levels of smoothing gives rise to a general level s CMMD which we investigate further in this work.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Judea Pearl , journal =
-
[2]
Shimodaira, Hidetoshi , journal =. Improving predictive inference under covariate shift by weighting the log-likelihood function , volume =
-
[3]
Bickel, Steffen and Br. Discriminative. Journal of Machine Learning Research , number =
-
[4]
Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation , year =
Masashi Sugiyama and Motoaki Kawanabe , publisher =. Machine Learning in Non-Stationary Environments: Introduction to Covariate Shift Adaptation , year =
- [5]
-
[6]
Marx, Charlie and Zalouk, Sofian and Ermon, Stefano , booktitle =. Calibration by
-
[7]
Generalized kernel two-sample tests , volume =
Song, Hoseung and Chen, Hao , journal =. Generalized kernel two-sample tests , volume =
-
[8]
Gretton, Arthur and Fukumizu, Kenji and Teo, Choon and Song, Le and Sch. A. Advances in
-
[9]
A Kernel Test of Goodness of Fit , year =
Chwialkowski, Kacper and Strathmann, Heiko and Gretton, Arthur , booktitle =. A Kernel Test of Goodness of Fit , year =
- [10]
-
[11]
Smola, Alex and Gretton, Arthur and Song, Le and Sch. A. Algorithmic
-
[12]
Advances in Neural Information Processing Systems , title =
Massiani, Pierre-Fran. Advances in Neural Information Processing Systems , title =
- [13]
- [14]
-
[15]
Lee, Seongchan and Cha, Suman and Kim, Ilmun , note =. General
-
[16]
Xiaoyu Hu and Jing Lei , journal =. A Two-Sample Conditional Distribution Test Using Conformal Prediction and Weighted Rank Sum , volume =
-
[17]
Conference on Uncertainty in Artificial Intelligence , year =
Boeken, Philip and Mooij, Joris , title =. Conference on Uncertainty in Artificial Intelligence , year =
-
[18]
Teymur, Onur and Filippi, Sarah , journal =. A
-
[19]
Conditional Distributional Treatment Effects: Doubly Robust Estimation and Testing , author=. 2026 , note =
work page 2026
-
[20]
Smoothing noisy data with spline functions:
Craven, Peter and Wahba, Grace , journal =. Smoothing noisy data with spline functions:
-
[21]
Singh, Rahul and Xu, Liyuan and Gretton, Arthur , title =. Biometrika , volume =
-
[22]
Conditional mean embeddings as regressors , year =
Gr\". Conditional mean embeddings as regressors , year =
-
[23]
A Measure-Theoretic Approach to Kernel Conditional Mean Embeddings , year =
Park, Junhyung and Muandet, Krikamol , booktitle =. A Measure-Theoretic Approach to Kernel Conditional Mean Embeddings , year =
-
[24]
Klebanov, Ilja and Schuster, Ingmar and Sullivan, T. J. , journal =. A
- [25]
-
[26]
Moskvichev, Peter and Sejdinovic, Dino , title =. 2025 , booktitle =
work page 2025
-
[27]
Optimal Rates for Regularized Conditional Mean Embedding Learning , year =
Li, Zhu and Meunier, Dimitri and Mollenhauer, Mattes and Gretton, Arthur , booktitle =. Optimal Rates for Regularized Conditional Mean Embedding Learning , year =
-
[28]
Muandet, Krikamol and Fukumizu, Kenji and Sriperumbudur, Bharath and Sch. Kernel. 2017 , month = jun, journal =
work page 2017
-
[29]
Arthur Gretton and Karsten M. Borgwardt and Malte J. Rasch and Bernhard Sch. A Kernel Two-Sample Test , journal =. 2012 , volume =
work page 2012
-
[30]
Advances in Neural Information Processing Systems , title =
Fukumizu, Kenji and Gretton, Arthur and Sun, Xiaohai and Sch\". Advances in Neural Information Processing Systems , title =
-
[31]
Fukumizu, Kenji and Bach, Francis R. and Jordan, Michael I. , journal =. Dimensionality
-
[32]
and Fukumizu, Kenji and Lanckriet, Gert R
Sriperumbudur, Bharath K. and Fukumizu, Kenji and Lanckriet, Gert R. G. , year =. Universality,. Journal of Machine Learning Research , volume =
-
[33]
Song, Le and Huang, Jonathan and Smola, Alex and Fukumizu, Kenji , title =. 2009 , booktitle =
work page 2009
-
[34]
Conference on Artificial Intelligence and Statistics , year =
Nonparametric Tree Graphical Models , author =. Conference on Artificial Intelligence and Statistics , year =
-
[35]
Song, Le and Fukumizu, Kenji and Gretton, Arthur , journal=. Kernel Embeddings of Conditional Distributions: A Unified Kernel Framework for Nonparametric Inference in Graphical Models , year=
-
[36]
Conditional Generative Moment-Matching Networks , year =
Ren, Yong and Zhu, Jun and Li, Jialian and Luo, Yucen , booktitle =. Conditional Generative Moment-Matching Networks , year =
-
[37]
International Conference on Learning Representations , year=
Calibration tests beyond classification , author=. International Conference on Learning Representations , year=
-
[38]
International Conference on Machine Learning , year =
Conditional Distributional Treatment Effect with Kernel Conditional Mean Embeddings and U-Statistic Regression , author =. International Conference on Machine Learning , year =
-
[39]
Glaser, Pierre and Paul, Steffanie and Hummer, Alissa M. and Deane, Charlotte M. and Marks, Debora S. and Amin, Alan N. , title =. 2024 , booktitle =
work page 2024
-
[40]
Characteristic and Universal Tensor Product Kernels , journal =
Zolt. Characteristic and Universal Tensor Product Kernels , journal =. 2018 , volume =
work page 2018
-
[41]
Regularised Least-Squares Regression with Infinite-Dimensional Output Space , author=. 2022 , note =
work page 2022
-
[42]
Journal of Machine Learning Research , pages =
Fine, Shai and Scheinberg, Katya , title =. Journal of Machine Learning Research , pages =. 2002 , volume =
work page 2002
-
[43]
Imbens, Guido W. and Rubin, Donald B. , year=. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction , publisher=
- [44]
-
[45]
Daniel G. Horvitz and Donovan J. Thompson , journal =. A Generalization of Sampling Without Replacement from a Finite Universe , volume =
-
[46]
Doubly Robust Kernel Statistics for Testing Distributional Treatment Effects , author=. 2024 , journal=
work page 2024
-
[47]
Shimizu, Eiki and Fukumizu, Kenji and Sejdinovic, Dino , title =. 2024 , booktitle =
work page 2024
-
[48]
Paul R. Rosenbaum , journal =. Conditional Permutation Tests and the Propensity Score in Observational Studies , volume =
-
[49]
MNIST handwritten digit database , author=
-
[50]
Advances in Neural Information Processing Systems , year =
Learning from Distributions via Support Measure Machines , author =. Advances in Neural Information Processing Systems , year =
-
[51]
Advances in Neural Information Processing Systems , year=
Variational learning on aggregate outputs with Gaussian processes , author=. Advances in Neural Information Processing Systems , year=
-
[52]
Advances in Neural Information Processing Systems , year=
Deconditional downscaling with gaussian processes , author=. Advances in Neural Information Processing Systems , year=
-
[53]
Advances in Neural Information Processing Systems , year=
Bayesimp: Uncertainty quantification for causal data fusion , author=. Advances in Neural Information Processing Systems , year=
-
[54]
Statistical inference for generative models with maximum mean discrepancy , author=
-
[55]
Advances in Approximate Bayesian Inference , title =
Ch. Advances in Approximate Bayesian Inference , title =
-
[56]
Journal of Machine Learning Research , volume=
Counterfactual mean embeddings , author=. Journal of Machine Learning Research , volume=
- [57]
-
[58]
Advances in Neural Information Processing Systems , year=
RKHS-SHAP: Shapley values for kernel methods , author=. Advances in Neural Information Processing Systems , year=
-
[59]
Advances in Neural Information Processing Systems , year=
Explaining the uncertain: Stochastic Shapley values for Gaussian process models , author=. Advances in Neural Information Processing Systems , year=
-
[60]
Journal of Machine Learning Research , volume=
Learning theory for distribution regression , author=. Journal of Machine Learning Research , volume=
-
[61]
Transactions of the American mathematical society , volume=
Theory of reproducing kernels , author=. Transactions of the American mathematical society , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.