Distributed Quantum Circuit Optimisation: Evaluating Global and Local encodings
Pith reviewed 2026-05-12 03:07 UTC · model grok-4.3
The pith
Circuit optimisation does not uniformly benefit distributed quantum execution, with global, local, and hybrid strategies trading off computational, communication, and compilation costs differently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
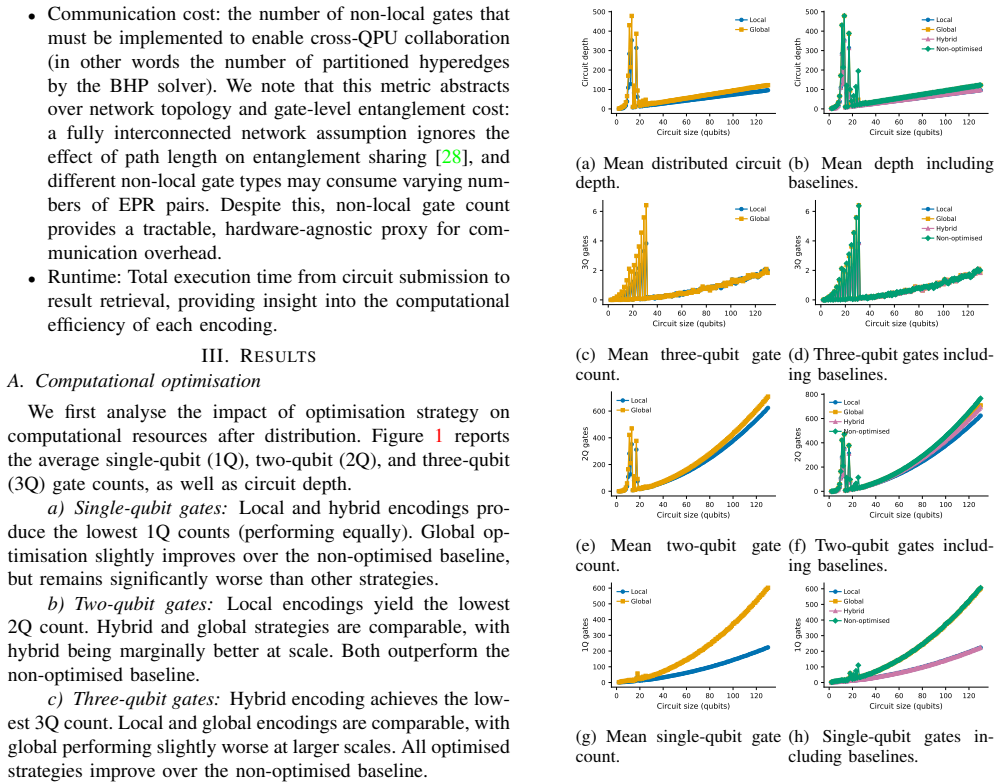
Using a large benchmark suite of quantum algorithms and telegate-based partitioning, the study shows that global circuit optimisation minimises computational resources like gate counts and circuit depth while achieving the lowest compilation overhead. Local optimisation, applied after partitioning, can reduce communication cost by lowering induced non-local gates even without being explicitly communication-aware. The hybrid strategy reduces both computational and communication overheads but incurs significantly higher compilation time.
What carries the argument
Comparison of global optimisation (full circuit before partition), local optimisation (per-partition after), and hybrid strategies, evaluated via telegate-based partitioning that counts non-local gates as communication cost.
If this is right
- Global optimisation produces the smallest total gate counts, shallowest depth, and fastest compilation for distributed workloads.
- Local optimisation can decrease the number of non-local gates that must cross processors even though it ignores communication during its passes.
- Hybrid optimisation simultaneously lowers both computational resources and communication overhead.
- No single strategy improves every measured cost at once; each choice creates a distinct trade-off profile.
Where Pith is reading between the lines
- This suggests distributed quantum compilers could benefit from optimisation passes that explicitly track and minimise non-local operations rather than applying local tweaks after the fact.
- The hybrid approach's high compilation time points to a possible bottleneck for scaling to larger algorithms where preprocessing must stay fast.
- Results indicate that benchmarks focused only on gate count may miss communication savings available from simple local optimisation.
Load-bearing premise
The large benchmark suite of quantum algorithms and telegate-based partitioning provide a representative approximation of computational, communication, and classical preprocessing costs in real distributed quantum architectures.
What would settle it
Running the same optimised distributed circuits on actual multi-processor quantum hardware and measuring real execution time, communication latency, and error rates against the paper's approximated gate counts and overheads would test whether the reported benefits hold.
Figures

read the original abstract
As distributed quantum architectures begin to emerge, understanding the interaction between quantum circuit optimisation and circuit partitioning becomes increasingly important. In this work, we study how circuit optimisation influences distributed quantum workloads under system-level trade-offs. We compare three compilation strategies (global optimisation, local optimisation, and a hybrid approach) across a large benchmark suite of quantum algorithms. Using telegate-based partitioning, we evaluate the resulting distributed circuits in terms of gate counts, circuit depth, the number of induced non-local gates, and compilation overhead, thereby approximating computational, communication, and classical preprocessing costs. Our results show that circuit optimisation does not uniformly benefit distributed execution. Global optimisation minimises computational resources and achieves the lowest compilation overhead. Local optimisation can reduce communication cost even though it is not explicitly communication-aware. The hybrid strategy can simultaneously reduce both computational and communication overhead, but at the expense of significantly increased compilation time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the effects of quantum circuit optimization on distributed quantum execution under telegate-based partitioning. It compares three strategies—global optimization, local optimization, and a hybrid approach—across a large benchmark suite of quantum algorithms. The evaluation uses metrics of gate counts, circuit depth, induced non-local gates, and compilation overhead to approximate computational, communication, and classical preprocessing costs. The central claim is that optimization does not uniformly benefit distributed circuits: global optimization minimizes computational resources and compilation overhead, local optimization reduces communication cost despite not being communication-aware, and the hybrid strategy reduces both computational and communication overhead at the expense of significantly higher compilation time.
Significance. If the reported empirical trade-offs are reproducible and the benchmark suite is representative, the work would offer useful guidance on selecting optimization strategies for emerging distributed quantum architectures, clarifying that global, local, and hybrid approaches produce distinct impacts on resource and overhead metrics. However, the absence of any methodology, data, or implementation details in the provided manuscript makes it impossible to assess whether these distinctions are correctly measured or generalizable.
major comments (2)
- Abstract: the manuscript asserts specific comparative outcomes ('Global optimisation minimises computational resources...', 'Local optimisation can reduce communication cost...', 'The hybrid strategy can simultaneously reduce both...') but supplies no methodology, benchmark list, optimization implementations, partitioning algorithm, metric definitions, raw data, error bars, or statistical analysis, so the claims cannot be verified or reproduced from the text.
- Abstract: the evaluation is said to approximate 'computational, communication, and classical preprocessing costs' via gate counts, depth, non-local gates, and overhead, yet no concrete definitions, formulas, or measurement procedures are given, leaving open whether the reported non-uniform benefits follow from the chosen metrics or from unstated assumptions about the telegate model.
minor comments (1)
- The title refers to 'encodings' while the abstract discusses 'optimisation' and 'compilation strategies'; a brief clarification of how the two concepts relate would improve readability.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater clarity on methodology and metrics. We address each major comment below. The full manuscript contains the benchmark details, implementations, and metric definitions referenced in the abstract; we are prepared to revise the abstract for improved self-containment where feasible.
read point-by-point responses
-
Referee: Abstract: the manuscript asserts specific comparative outcomes ('Global optimisation minimises computational resources...', 'Local optimisation can reduce communication cost...', 'The hybrid strategy can simultaneously reduce both...') but supplies no methodology, benchmark list, optimization implementations, partitioning algorithm, metric definitions, raw data, error bars, or statistical analysis, so the claims cannot be verified or reproduced from the text.
Authors: The abstract summarises the principal empirical outcomes of the study. The complete manuscript specifies the benchmark suite, the three optimisation strategies and their implementations, the telegate-based partitioning procedure, all metric definitions, and the full set of results including any statistical considerations. We can revise the abstract to include a short clause directing readers to the relevant sections for full reproducibility. revision: partial
-
Referee: Abstract: the evaluation is said to approximate 'computational, communication, and classical preprocessing costs' via gate counts, depth, non-local gates, and overhead, yet no concrete definitions, formulas, or measurement procedures are given, leaving open whether the reported non-uniform benefits follow from the chosen metrics or from unstated assumptions about the telegate model.
Authors: The main text defines each proxy metric explicitly: gate count and depth for computational cost, number of induced non-local gates for communication cost under the telegate model (where non-local operations are realised via remote gates), and measured compilation time for classical preprocessing overhead. These choices follow directly from the telegate execution model described in the paper. We will add a brief clarifying sentence to the abstract if length permits. revision: partial
Circularity Check
Empirical benchmark evaluation exhibits no circularity
full rationale
The paper's central claims consist of direct empirical observations from comparing global, local, and hybrid optimization strategies across a benchmark suite under telegate-based partitioning, using measured metrics of gate counts, depth, non-local gates, and overhead. No equations, derivations, fitted parameters, predictions, or self-citations are present in the available text that would reduce any result to its inputs by construction. The evaluation is self-contained against external benchmarks and does not invoke uniqueness theorems, ansatzes, or renamings that loop back to prior assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Telegate-based partitioning is a valid model for distributed quantum computation costs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that circuit optimisation does not uniformly benefit distributed execution. Global optimisation minimises computational resources and achieves the lowest compilation overhead. Local optimisation can reduce communication cost even though it is not explicitly communication-aware.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using telegate-based partitioning, we evaluate the resulting distributed circuits in terms of gate counts, circuit depth, the number of induced non-local gates, and compilation overhead
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Elementary gates for quantum computation,
A. Barencoet al., “Elementary gates for quantum computation,”Phys- ical review A, 1995
work page 1995
-
[2]
Cognac: Circuit optimization via gradients and noise- aware compilation,
F. V oichicket al., “Cognac: Circuit optimization via gradients and noise- aware compilation,”arXiv preprint:2311.02769, 2023
-
[3]
Automated optimization of large quantum circuits with continuous parameters,
Y . Namet al., “Automated optimization of large quantum circuits with continuous parameters,”npj Quantum Information
-
[4]
Optimising quantum circuits is generally hard,
J. van de Wetering and M. Amy, “Optimising quantum circuits is generally hard,”arXiv preprint:2310.05958, 2023
-
[5]
Exact quantum circuit optimization is co-nqp- hard,
A. H. Kjelstrømet al., “Exact quantum circuit optimization is co-nqp- hard,”arXiv preprint:2510.16420, 2025
-
[6]
Breaking down quantum compilation: Profiling and identifying costly passes,
F. Zilket al., “Breaking down quantum compilation: Profiling and identifying costly passes,” in2025 IEEE ISVLSI
-
[7]
Reducing the compilation time of quantum circuits using pre-compilation on the gate level,
N. Quetschlichet al., “Reducing the compilation time of quantum circuits using pre-compilation on the gate level,” inQCE, 2023
work page 2023
-
[8]
Optimized compiler for distributed quantum comput- ing,
D. Cuomoet al., “Optimized compiler for distributed quantum comput- ing,”ACM Transactions on Quantum Computing, 2023
work page 2023
-
[9]
Efficient gate reordering for distributed quantum compiling in data centers,
R. Mengoniet al., “Efficient gate reordering for distributed quantum compiling in data centers,” inQCE, 2025
work page 2025
-
[10]
Distributed quantum error mitigation: Global and local zne encodings,
M. Gragera Garces, “Distributed quantum error mitigation: Global and local zne encodings,” inQUNAP , INFOCOM, 2026
work page 2026
-
[11]
Optimization of resource-aware parallel and dis- tributed computing: a review: P. czarnul et al
P. Czarnulet al., “Optimization of resource-aware parallel and dis- tributed computing: a review: P. czarnul et al.”The Journal of Super- computing, 2025
work page 2025
-
[12]
Automated distribution of quantum circuits via hypergraph partitioning,
P. Andres-Martinez and C. Heunen, “Automated distribution of quantum circuits via hypergraph partitioning,”Physical Review A
-
[13]
Review of distributed quantum computing: From single qpu to high performance quantum computing,
D. Barralet al., “Review of distributed quantum computing: From single qpu to high performance quantum computing,”Computer Science Review, 2025
work page 2025
-
[14]
Simulating large quantum circuits on a small quantum computer,
T. Penget al., “Simulating large quantum circuits on a small quantum computer,”Physical review letters, 2020
work page 2020
-
[15]
Circuit knitting facing exponential sampling-overhead scaling bounded by entanglement cost,
M. Jinget al., “Circuit knitting facing exponential sampling-overhead scaling bounded by entanglement cost,”Physical Review A
-
[16]
Approximate quantum circuit reconstruction,
D. Chenet al., “Approximate quantum circuit reconstruction,”QCE, 2022
work page 2022
-
[17]
M.-T. Lauet al., “A lazy resynthesis approach for simultaneous t gate and two-qubit gate optimization of quantum circuits,”arXiv preprint:2508.04092, 2025
-
[18]
Towards optimal topology aware quantum circuit synthesis,
M. G. Daviset al., “Towards optimal topology aware quantum circuit synthesis,” inQCE, 2020
work page 2020
-
[19]
Optimized compilation for distributed quantum computing,
M. Bandiniet al., “Optimized compilation for distributed quantum computing,”arXiv preprint:2602.24062, 2026
-
[20]
Autocomm: A framework for enabling efficient commu- nication in distributed quantum programs
A. Wuet al., “Autocomm: A framework for enabling efficient commu- nication in distributed quantum programs.” IEEE, 2022
work page 2022
-
[21]
Distributing circuits over heterogeneous, modular quantum computing network architectures,
P. Andres-Martinezet al., “Distributing circuits over heterogeneous, modular quantum computing network architectures,”Quantum Science and Technology, 2024
work page 2024
-
[22]
A modular quantum compilation framework for distributed quantum computing,
D. Ferrariet al., “A modular quantum compilation framework for distributed quantum computing,”IEEE TQE, 2023
work page 2023
-
[23]
Mqt bench: Benchmarking software and design automation tools for quantum computing,
N. Quetschlichet al., “Mqt bench: Benchmarking software and design automation tools for quantum computing,”Quantum, 2023
work page 2023
-
[24]
Open source software in quantum computing,
M. Fingerhuthet al., “Open source software in quantum computing,” PloS one, 2018
work page 2018
-
[25]
On the distortion of partitioning performance by random quantum circuits,
M. Gragera Garces, “On the distortion of partitioning performance by random quantum circuits,” inDisQIC, ICDCS, 2026
work page 2026
-
[26]
High-quality hypergraph partitioning,
S. Schlaget al., “High-quality hypergraph partitioning,”ACM Journal of Experimental Algorithmics, 2023
work page 2023
-
[27]
Set transpiler optimization level,
IBM Corporation, “Set transpiler optimization level,” quantum.cloud.ibm.com/docs/en/guides/set-optimization, feb 2025
work page 2025
-
[28]
Entanglement-efficient distribution of quantum circuits over large-scale quantum networks,
F. Burtet al., “Entanglement-efficient distribution of quantum circuits over large-scale quantum networks,” inQCE, 2025
work page 2025
-
[29]
Non-identity-check is qma complete,
D. Janzinget al., “Non-identity-check is qma complete,”International Journal of Quantum Information, 2005
work page 2005
-
[30]
tket: a retargetable compiler for nisq devices,
S. Sivarajahet al., “tket: a retargetable compiler for nisq devices,” Quantum Science & Technology, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.