Joint Energy Management and Coordinated AIGC Workload Scheduling for Distributed Data Centers: A Diffusion-Aided Reward Shaping Approach
Pith reviewed 2026-05-10 15:13 UTC · model grok-4.3
The pith
A diffusion model synthesizes reward signals to enable effective reinforcement learning for AIGC workload scheduling and energy management in distributed data centers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that by integrating a diffusion model to shape rewards through a multi-step denoising process with deep reinforcement learning, it becomes possible to learn effective policies for joint energy management and coordinated AIGC workload scheduling despite the reward sparsity induced by coupled decisions on job transfers and inference configurations.
What carries the argument
Diffusion model-aided reward shaping that generates complementary reward signals via multi-step denoising to support DRL under sparse feedback.
If this is right
- Effective handling of electricity price variations and AIGC model heterogeneity across providers.
- Improved convergence of the learning process for scheduling policies.
- Higher achieved system utility balancing service revenue against costs and penalties.
- Greater flexibility in utilizing diverse energy resources in the data centers.
Where Pith is reading between the lines
- This reward shaping technique could be tested in other domains involving complex interdependent decisions, such as cloud resource allocation or smart grid management.
- Further experiments could examine whether the diffusion model requires retraining for new AIGC models or if it generalizes across different content generation tasks.
- Combining the approach with other techniques like hierarchical reinforcement learning might address even larger scale distributed systems.
Load-bearing premise
The diffusion model can consistently generate meaningful and non-misleading reward signals that help overcome the sparsity without distorting the optimization objective.
What would settle it
Conducting experiments where the DRL agent is trained solely with the original sparse rewards on identical real-world AIGC models and datasets, and finding comparable or superior performance in convergence and utility, would indicate that the diffusion-aided shaping is not necessary.
Figures











read the original abstract
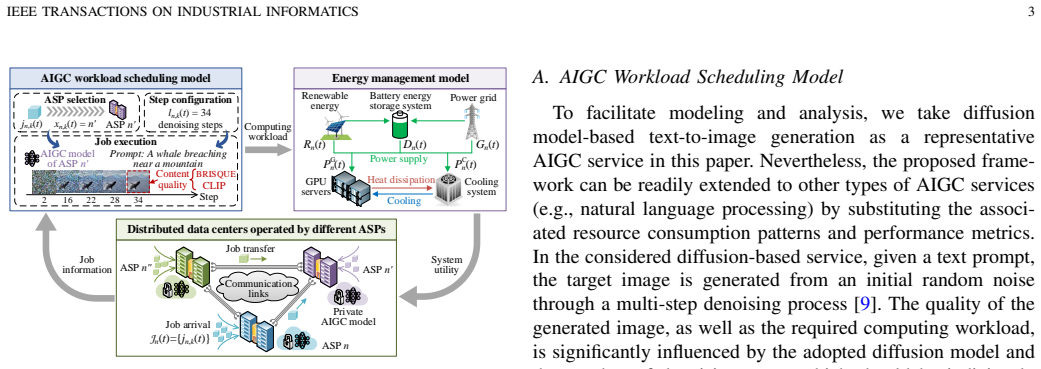
Artificial intelligence-generated content (AIGC) has emerged as a transformative paradigm for automating the creation of diverse and customized content, giving rise to rapidly growing computational workloads in cloud data centers. It is imperative for AIGC service providers (ASPs) to strategically schedule AIGC workloads to reduce data center energy costs while guaranteeing high-quality content generation. However, the distinctive characteristics of AIGC services pose critical challenges, including model heterogeneity across ASPs, implicit service quality evaluation, and complex inference process control. To tackle these challenges, we propose a joint energy management and coordinated AIGC workload scheduling framework, which introduces an explicit mathematical characterization of service quality to promote both job transfer among ASPs and fine-grained inference process configuration. Moreover, various energy resources within data centers are jointly considered to enhance power usage flexibility. Subsequently, a system utility maximization problem is formulated to balance AIGC service revenue with operational penalties and costs. Nevertheless, the strong coupling among job scheduling decisions induces severe reward sparsity, which limits the effectiveness of existing deep reinforcement learning (DRL) algorithms. To address this issue, we develop a diffusion model-aided reward shaping approach to synthesize complementary reward signals through a multi-step denoising process. This approach is seamlessly integrated with DRL to enable efficient learning of scheduling policies under sparse environmental feedback. Experiments based on real-world models and datasets demonstrate that our scheme effectively accommodates electricity price fluctuations and AIGC model heterogeneity, while achieving superior learning convergence and system utility compared with benchmark methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a joint energy management and coordinated AIGC workload scheduling framework for distributed data centers. It provides an explicit mathematical characterization of service quality to enable job transfer and inference configuration, jointly models various energy resources, and formulates a system utility maximization problem balancing revenue against energy costs and penalties. To address severe reward sparsity induced by coupled scheduling decisions in DRL, it introduces a diffusion model-aided reward shaping method that synthesizes complementary signals via multi-step denoising, which is integrated with DRL for policy learning. Experiments on real-world models and datasets are claimed to show effective accommodation of electricity price fluctuations and model heterogeneity, along with superior convergence and utility versus benchmarks.
Significance. If the diffusion-based shaping is validated to provide policy-preserving or unbiased signals, the work could advance DRL applications to resource allocation in emerging AIGC services by offering a practical technique for sparse-reward MDPs with coupled decisions. The explicit service-quality modeling and joint energy-resource consideration represent concrete engineering contributions that align with real data-center operations. The approach's novelty in applying diffusion models to reward synthesis for this domain is a potential strength, though its load-bearing role requires clearer isolation.
major comments (2)
- [Diffusion model-aided reward shaping] The diffusion model-aided reward shaping approach (described after the problem formulation): the claim that multi-step denoising synthesizes complementary signals to overcome sparsity lacks any derivation showing that the resulting rewards are consistent with the original MDP's optimality (e.g., via potential-based shaping that preserves the optimal policy) or that they avoid systematic bias in long-term value estimates for revenue minus energy/penalty costs. This is central to the contribution and must be addressed with a proof sketch or formal argument.
- [Experiments] Experiments section (and abstract claims): no ablation is reported that isolates the diffusion component from other modeling choices such as the explicit service-quality characterization or the joint energy-resource model. Without this, end-to-end superiority on real-world traces cannot establish whether the denoising step is load-bearing or merely correlated with other improvements.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative metric (e.g., percentage improvement in utility or convergence speed) with error bars to support the superiority claim.
- [System Model] Notation for AIGC model heterogeneity, job-transfer decisions, and shaped reward components should be introduced with a dedicated table or consistent definitions early in the system model to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, outlining the revisions we will incorporate to strengthen the theoretical grounding and experimental validation of the diffusion-aided reward shaping approach.
read point-by-point responses
-
Referee: [Diffusion model-aided reward shaping] The diffusion model-aided reward shaping approach (described after the problem formulation): the claim that multi-step denoising synthesizes complementary signals to overcome sparsity lacks any derivation showing that the resulting rewards are consistent with the original MDP's optimality (e.g., via potential-based shaping that preserves the optimal policy) or that they avoid systematic bias in long-term value estimates for revenue minus energy/penalty costs. This is central to the contribution and must be addressed with a proof sketch or formal argument.
Authors: We agree that the current manuscript lacks a formal derivation establishing policy preservation or bias analysis for the shaped rewards. While the diffusion process is designed to generate signals consistent with the original reward distribution, we will add a new subsection with a proof sketch. This will frame the multi-step denoising as a potential-based shaping function (extending Ng et al.'s framework) under the assumption that the learned diffusion model approximates the true reward measure, thereby preserving the optimal policy. We will also include a bias-variance analysis for the long-term value estimates and discuss conditions under which systematic bias is avoided, supported by additional theoretical arguments. revision: yes
-
Referee: [Experiments] Experiments section (and abstract claims): no ablation is reported that isolates the diffusion component from other modeling choices such as the explicit service-quality characterization or the joint energy-resource model. Without this, end-to-end superiority on real-world traces cannot establish whether the denoising step is load-bearing or merely correlated with other improvements.
Authors: We concur that isolating the diffusion component is essential for validating its load-bearing role. In the revised manuscript, we will add a dedicated ablation study in the Experiments section. This will compare the full proposed framework against a variant that retains the explicit service-quality characterization and joint energy-resource modeling but replaces the diffusion-aided shaping with standard sparse-reward DRL (e.g., vanilla DQN or PPO). Results on the same real-world traces will quantify the incremental gains in convergence speed and system utility attributable to the denoising process. revision: yes
Circularity Check
No significant circularity; derivation is self-contained algorithmic proposal
full rationale
The paper introduces a joint optimization framework for AIGC scheduling and energy management, then proposes a diffusion model-based reward shaping technique as an independent algorithmic addition to DRL to mitigate reward sparsity. No load-bearing step reduces the claimed performance gain or shaped reward to a fitted parameter, self-citation chain, or definitional equivalence with the input MDP; the denoising process is presented as a novel synthesis method rather than a renaming or self-referential fit. The central utility maximization and scheduling decisions remain externally motivated by the problem characteristics, with experiments on real-world traces serving as validation rather than circular confirmation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of AI-generated content (AIGC),
Y . Cao, S. Li, Y . Liuet al., “A survey of AI-generated content (AIGC),” ACM Comput. Surv., vol. 57, no. 5, 2025
work page 2025
-
[2]
Diffusion models in vision: A survey,
F.-A. Croitoru, V . Hondru, R. T. Ionescuet al., “Diffusion models in vision: A survey,”IEEE Trans. Pattern Anal. Machine Intell., vol. 45, no. 9, pp. 10 850–10 869, 2023
work page 2023
-
[3]
ChatGPT statistics 2025: 10 facts you won’t believe!
“ChatGPT statistics 2025: 10 facts you won’t believe!” 2025. [Online]. Available: https://aimojo.io/chatgpt-statistics-facts/
work page 2025
-
[4]
ChatGPT’s monthly carbon footprint equivalent to 260 transatlantic flights,
“ChatGPT’s monthly carbon footprint equivalent to 260 transatlantic flights,” 2025. [On- line]. Available: https://sustainability-news.net/net-zero/ chatgpts-monthly-carbon-footprint-equivalent-to-260-transatlantic-flights/
work page 2025
-
[5]
Joint energy and computation workload management for geo-distributed data centers,
R. Wang, R. Wu, L. Liuet al., “Joint energy and computation workload management for geo-distributed data centers,” pp. 2115–2128, 2025
work page 2025
-
[6]
Data center job scheduling and energy management under uncertain environments,
Z. Ding, S. Chen, Y . Sunet al., “Data center job scheduling and energy management under uncertain environments,”IEEE Trans. Ind. Applicat., vol. 61, no. 4, pp. 5489–5500, 2025
work page 2025
-
[7]
Diffusion-based reinforcement learning for edge-enabled AI-generated content services,
H. Du, Z. Li, D. Niyatoet al., “Diffusion-based reinforcement learning for edge-enabled AI-generated content services,”IEEE Trans. Mobile Comput., vol. 23, no. 9, pp. 8902–8918, 2024
work page 2024
-
[8]
Reinforcement learning with LLMs interaction for distributed diffusion model services,
H. Du, R. Zhang, D. Niyatoet al., “Reinforcement learning with LLMs interaction for distributed diffusion model services,”IEEE Trans. Pattern Anal. Machine Intell., vol. 47, no. 10, pp. 8838–8855, 2025
work page 2025
-
[9]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProc. Adv. Neural Inform. Process. Syst. (NeurIPS), vol. 33, 2020, pp. 6840–6851
work page 2020
-
[10]
Characterizing and scheduling of diffusion process for text-to-image generation in edge networks,
S. Gao, P. Yang, Y . Konget al., “Characterizing and scheduling of diffusion process for text-to-image generation in edge networks,”IEEE Trans. Mobile Comput., vol. 24, no. 10, pp. 11 137–11 150, 2025
work page 2025
-
[11]
Electricity cost minimization for multi-workflow allocation in geo-distributed data centers,
S. Wang, H. Zhang, T. Wuet al., “Electricity cost minimization for multi-workflow allocation in geo-distributed data centers,”IEEE Trans. Services Comput., vol. 18, no. 3, pp. 1397–1411, 2025
work page 2025
-
[12]
S. Chen, J. Li, Q. Yuanet al., “Two-timescale joint optimization of task scheduling and resource scaling in multi-data center system based on multi-agent deep reinforcement learning,”IEEE Trans. Parallel Distrib. Syst., vol. 35, no. 12, pp. 2331–2346, 2024
work page 2024
-
[13]
Y . Wang, W. Sun, P. Renet al., “Multi-objective low-carbon scheduling method for data centers based on ensemble reinforcement learning,” IEEE Trans. Smart Grid, vol. 17, no. 1, pp. 297–308, 2026
work page 2026
-
[14]
Y . Ran, H. Yin, T. Sunet al., “D3T: Dual-timescale optimization of task scheduling and thermal management for energy efficient geo-distributed data centers,”IEEE Trans. Parallel Distrib. Syst., vol. 37, no. 1, pp. 230–246, 2026
work page 2026
-
[15]
Privacy-preserving energy sharing among cloud service providers via collaborative job scheduling,
Y . Sun, Z. Ding, Y . Yanet al., “Privacy-preserving energy sharing among cloud service providers via collaborative job scheduling,”IEEE Trans. Smart Grid, vol. 16, no. 2, pp. 1168–1180, 2025
work page 2025
-
[16]
T. Jin, L. Bai, M. Yanet al., “Unlocking spatio-temporal flexibility of data centers in multiple regional peer-to-peer energy transaction markets,”IEEE Trans. Power Syst., vol. 40, no. 5, pp. 3914–3927, 2025
work page 2025
-
[17]
Z. Zhao, L. Fan, and Z. Han, “Optimal data center energy manage- ment with hybrid quantum-classical multi-cuts Benders’ decomposition method,”IEEE Trans. Sustain. Energy, vol. 15, no. 2, pp. 847–858, 2024
work page 2024
-
[18]
Learning-enabled adaptive power capping scheme for cloud data centers,
Y . Sun, Z. Ding, P. Dehghanianet al., “Learning-enabled adaptive power capping scheme for cloud data centers,”IEEE Trans. Smart Grid, vol. 16, no. 6, pp. 4755–4767, 2025
work page 2025
-
[19]
Optimal energy management of internet data center with distributed energy resources,
K. Zhou, Z. Fei, and X. Lu, “Optimal energy management of internet data center with distributed energy resources,”IEEE Trans. Cloud Comput., vol. 11, no. 3, pp. 2285–2295, 2023
work page 2023
-
[20]
L. Zhang, M. Ai, K. Liuet al., “Reliability enhancement strategies for workflow scheduling under energy consumption constraints in clouds,” IEEE Trans. Sustain. Comput., vol. 9, no. 2, pp. 155–169, 2024
work page 2024
-
[21]
Joint workload scheduling in geo- distributed data centers considering UPS power losses,
G. Ye, F. Gao, J. Fanget al., “Joint workload scheduling in geo- distributed data centers considering UPS power losses,”IEEE Trans. Ind. Applicat., vol. 59, no. 1, pp. 612–626, 2023
work page 2023
-
[22]
Online request scheduling for quality- aware diffusion-based AIGC services,
H. Yang, Y . Zheng, L. Jiaoet al., “Online request scheduling for quality- aware diffusion-based AIGC services,”IEEE Trans. Netw., 2025. IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS 15
work page 2025
-
[23]
Dynamic flow scheduling for DNN training workloads in data centers,
X. Zhao, C. Wu, and X. Zhu, “Dynamic flow scheduling for DNN training workloads in data centers,”IEEE Trans. Netw. Service Manag., vol. 21, no. 6, pp. 6643–6657, 2024
work page 2024
-
[24]
GreenFlow: A carbon-efficient scheduler for deep learning workloads,
D. Gu, Y . Zhao, P. Sunet al., “GreenFlow: A carbon-efficient scheduler for deep learning workloads,”IEEE Trans. Parallel Distrib. Syst., vol. 36, no. 2, pp. 168–184, 2025
work page 2025
-
[25]
S. Zhang, M. Xu, W. Y . Bryan Limet al., “Sustainable AIGC workload scheduling of geo-distributed data centers: A multi-agent reinforcement learning approach,” inProc. IEEE Glob. Commun. Conf. (GLOBECOM), 2023, pp. 3500–3505
work page 2023
-
[26]
GreenDLS: An energy-efficient and SLO-aware deep learning serving system,
M. Hao, X. Tian, S. Yanget al., “GreenDLS: An energy-efficient and SLO-aware deep learning serving system,”IEEE Trans. Comput., 2025
work page 2025
-
[27]
N. Hogade and S. Pasricha, “Game-theoretic deep reinforcement learn- ing to minimize carbon emissions and energy costs for AI inference workloads in geo-distributed data centers,”IEEE Trans. Sustain. Com- put., vol. 10, no. 4, pp. 628–641, 2025
work page 2025
-
[28]
QoE-aware offloading and resource allocation for MEC-empowered AIGC services,
J. Wu, X. Zhuang, M. Tanget al., “QoE-aware offloading and resource allocation for MEC-empowered AIGC services,”IEEE Trans. Mobile Comput., vol. 24, no. 10, pp. 9664–9682, 2025
work page 2025
-
[29]
Q. Wang, X. Mei, H. Liuet al., “Energy-aware non-preemptive task scheduling with deadline constraint in DVFS-enabled heterogeneous clusters,”IEEE Trans. Parallel Distrib. Syst., vol. 33, no. 12, pp. 4083– 4099, 2022
work page 2022
-
[30]
Optimal sizing of energy station in the multienergy system integrated with data center,
J. Lyu, S. Zhang, H. Chenget al., “Optimal sizing of energy station in the multienergy system integrated with data center,”IEEE Trans. Ind. Applicat., vol. 57, no. 2, pp. 1222–1234, 2021
work page 2021
-
[31]
Lyapunov optimization in online battery energy storage system control for commercial buildings,
J. Shi, Z. Ye, H. O. Gaoet al., “Lyapunov optimization in online battery energy storage system control for commercial buildings,”IEEE Trans. Smart Grid, vol. 14, no. 1, pp. 328–340, 2023
work page 2023
-
[32]
DRESS: Diffusion model-based reward shaping scheme for intelligent networks,
F. You, H. Du, X. Houet al., “DRESS: Diffusion model-based reward shaping scheme for intelligent networks,”IEEE Trans. Signal Process- ing, vol. 73, pp. 4285–4300, 2025
work page 2025
-
[33]
Y . Fu, P. Qin, and K. Wu, “SC3-MDRA: A new approach to coordinating bi-level age of information in AA V-enabled 6G integrated networks,” IEEE Trans. Netw., vol. 34, pp. 49–63, 2026
work page 2026
-
[34]
Policy invariance under reward transformations: Theory and application to reward shaping,
A. Y . Ng, D. Harada, and S. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” inProc. Int. Conf. Mach. Learn. (ICML), 1999
work page 1999
-
[35]
Reward shaping for reinforcement learning with an assistant reward agent,
H. Ma, K. Sima, T. V . V oet al., “Reward shaping for reinforcement learning with an assistant reward agent,” inProc. Int. Conf. Mach. Learn. (ICML), 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.