Recognition: 1 theorem link
Semantically Enriching Investor Micro-blogs for Opinion-Aware Emotion Analysis: A Practical Approach
Pith reviewed 2026-05-08 18:11 UTC · model grok-4.3
The pith
Adding opinion graphs to investor micro-blogs improves GNN emotion classification performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
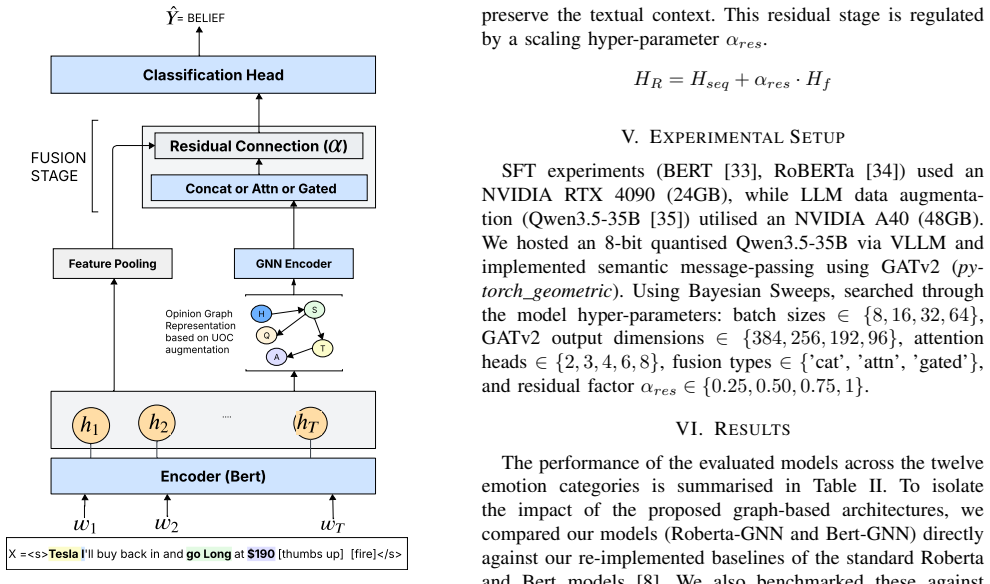
Augmenting the StockEmotions dataset with semantically structured opinion graphs derived from a declarative LLM pipeline on 10,000 StockTwits comments improves the classification performance of baseline GNN classifiers across different emotional spectrums.
What carries the argument
Opinion graphs generated by a declarative LLM pipeline that add granular semantic depth to each sentence's existing sentiment and emotion labels.
If this is right
- GNN classifiers achieve higher accuracy on emotion detection tasks once opinion semantics are added.
- Analysis gains the ability to link emotions to specific targets within investor comments.
- The approach supplies a scalable way to enrich other sentiment-labeled financial datasets with structured opinions.
- Performance gains appear across the full range of emotional categories rather than only in isolated classes.
Where Pith is reading between the lines
- If the pipeline remains reliable at scale, the method could be applied to real-time streams of millions of micro-blogs without additional human annotation.
- The same enrichment technique might transfer to non-financial domains such as product reviews or political discussion threads.
- Combining the opinion graphs with temporal or user-network features could further improve prediction of market-moving sentiment shifts.
Load-bearing premise
The opinion graphs produced by the LLM pipeline accurately and consistently capture the semantic structure of the financial microblog text without introducing substantial noise or artifacts.
What would settle it
A manual review of a sample of the generated opinion graphs that finds frequent mismatches with the intended meaning or structure in the original StockTwits sentences would falsify the usefulness of the enrichment step.
Figures


read the original abstract
While sentiment analysis is the staple of financial NLP, capturing the nuances of 'why' behind that sentiment remains a challenge. There have been attempts to address this by analysing investor emotions alongside sentiment; however, this does not provide the additional granularity required to understand the target of the emotion/sentiment. We address this by augmenting the StockEmotions dataset with semantically structured opinion graphs, which provide granular semantic depth to the existing sentiment and emotion labels. Using a declarative LLM pipeline, we augment the StockEmotions dataset with opinion graphs for each sentence, derived from 10,000 comments collected from StockTwits. In addition, we study the effect of introducing opinion semantics on baseline classifiers using Graph Neural Networks (GNNs). Our analysis demonstrates that incorporating opinion semantics improves classification performance across different emotional spectrums
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes augmenting the StockEmotions dataset with opinion graphs generated from 10,000 StockTwits investor microblog comments via a declarative LLM pipeline. These graphs are intended to add granular semantic structure to existing sentiment and emotion labels. The authors then evaluate the effect of this augmentation on baseline emotion classifiers by employing Graph Neural Networks (GNNs), asserting that the incorporation of opinion semantics yields improved classification performance across emotional categories.
Significance. If the claimed performance gains are demonstrated with rigorous metrics and the opinion graphs are shown to faithfully capture semantics, the work could provide a scalable, practical method for enriching financial NLP tasks with opinion-aware structure beyond coarse emotion labels. The declarative LLM approach for graph construction is potentially reproducible and extensible, but its contribution hinges on empirical validation that is currently absent.
major comments (3)
- [Abstract] Abstract: The assertion that 'incorporating opinion semantics improves classification performance across different emotional spectrums' is presented without any quantitative results, baseline details, metrics (accuracy, F1, etc.), error bars, or statistical significance tests. This is load-bearing for the central claim, as the experimental design and results cannot be assessed from the available text.
- [Method] Method: The declarative LLM pipeline for generating the 10k opinion graphs is described at a high level but includes no human validation, inter-annotator agreement, qualitative error analysis, or checks for LLM artifacts and prompt biases. This directly undermines the weakest assumption that the graphs accurately enrich the labels with true semantic structure rather than incidental features.
- [Experiments] Experiments/Evaluation: No details are supplied on GNN architecture, how opinion graphs are encoded or fused with text inputs, training procedure, dataset splits, or specific performance comparisons. Without these, the reported improvement cannot be reproduced or interpreted as evidence for the approach.
minor comments (1)
- [Abstract] The abstract refers to 'different emotional spectrums' without specifying the number or identity of emotion categories in StockEmotions, which would aid clarity.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our manuscript. We address each major comment point by point below, agreeing where revisions are needed to strengthen the paper's clarity, reproducibility, and empirical support. We will incorporate these changes in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'incorporating opinion semantics improves classification performance across different emotional spectrums' is presented without any quantitative results, baseline details, metrics (accuracy, F1, etc.), error bars, or statistical significance tests. This is load-bearing for the central claim, as the experimental design and results cannot be assessed from the available text.
Authors: We agree that the abstract should be more self-contained and include key quantitative support for the central claim. While the full manuscript reports these results in the Experiments section, we will revise the abstract to explicitly include performance metrics (e.g., F1-score gains across emotion categories), baseline comparisons, and reference to statistical significance to allow readers to assess the findings immediately. revision: yes
-
Referee: [Method] Method: The declarative LLM pipeline for generating the 10k opinion graphs is described at a high level but includes no human validation, inter-annotator agreement, qualitative error analysis, or checks for LLM artifacts and prompt biases. This directly undermines the weakest assumption that the graphs accurately enrich the labels with true semantic structure rather than incidental features.
Authors: We acknowledge that the current description of the LLM pipeline in Section 3 is high-level and lacks explicit validation steps. This is a valid concern. In the revision, we will add a new subsection detailing human validation on a sampled subset of graphs, including inter-annotator agreement metrics, qualitative error analysis, and sensitivity checks for prompt biases and LLM artifacts to better substantiate that the graphs provide genuine semantic enrichment. revision: yes
-
Referee: [Experiments] Experiments/Evaluation: No details are supplied on GNN architecture, how opinion graphs are encoded or fused with text inputs, training procedure, dataset splits, or specific performance comparisons. Without these, the reported improvement cannot be reproduced or interpreted as evidence for the approach.
Authors: We agree that additional experimental details are required for reproducibility and to fully interpret the results. We will substantially expand the Experiments section to specify the GNN architecture (e.g., layers and attention mechanisms), graph encoding and fusion with text inputs, training procedure and hyperparameters, dataset splits, baseline models, and complete performance comparisons including metrics, error bars, and statistical tests. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on external labels
full rationale
The paper describes an applied pipeline that generates opinion graphs from microblog text via a declarative LLM method, augments the StockEmotions dataset, and measures downstream GNN classification accuracy against baselines. No equations, derivations, fitted parameters, or self-referential definitions appear; the reported performance lift is a direct empirical comparison on held-out data rather than a quantity forced by construction from the inputs. The central claim therefore rests on observable classification metrics rather than reducing to its own assumptions by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can reliably extract and structure opinions into graphs from short financial microblog text
invented entities (1)
-
opinion graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Classifying sentiment in microblogs: is brevity an advantage?
A. Bermingham and A. F. Smeaton, “Classifying sentiment in microblogs: is brevity an advantage?” inProceedings of the 19th ACM International Conference on Information and Knowledge Management, ser. CIKM ’10. New York, NY , USA: Association for Computing Machinery, 2010, p. 1833–1836. [Online]. Available: https://doi.org/10.1145/1871437.1871741
-
[2]
Contextual semantics for sentiment analysis of twitter,
H. Saif, Y . He, M. Fernandez, and H. Alani, “Contextual semantics for sentiment analysis of twitter,”Information Processing & Management, vol. 52, no. 1, pp. 5–19, 2016, emotion and Sentiment in Social and Expressive Media. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0306457315000242
2016
-
[3]
Investor sentiment in the theoretical field of behavioural finance,
M. ´Angeles L ´opez-Cabarcos, A. M. P ´erez-Pico, P. V ´azquez- Rodr´ıguez, and M. L. L ´opez-P´erez, “Investor sentiment in the theoretical field of behavioural finance,”Economic Research-Ekonomska Istraˇzivanja, vol. 33, no. 1, pp. 2101–2119, 2020. [Online]. Available: https://doi.org/10.1080/1331677X.2018.1559748
-
[4]
Investor sentiment from internet message postings and the predictability of stock returns,
S.-H. Kim and D. Kim, “Investor sentiment from internet message postings and the predictability of stock returns,”Journal of Economic Behavior & Organization, vol. 107, pp. 708– 729, 2014, empirical Behavioral Finance. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167268114001206
2014
-
[5]
Efficient capital markets: A review of theory and empirical work,
E. F. Fama, “Efficient capital markets: A review of theory and empirical work,”The Journal of Finance, vol. 25, no. 2, pp. 383–417, 1970. [Online]. Available: http://www.jstor.org/stable/2325486
-
[6]
Investor sentiment and the cross-section of stock returns,
M. Baker and J. Wurgler, “Investor sentiment and the cross-section of stock returns,”The Journal of Finance, vol. 61, no. 4, pp. 1645–1680,
-
[7]
Available: http://www.jstor.org/stable/3874723
[Online]. Available: http://www.jstor.org/stable/3874723
-
[8]
Impacts of code of ethics on financial performance in the italian listed companies of bank sector,
M. Cuomo, D. Tortora, A. Mazzucchelli, G. Festa, A. Di Gregorio, G. Metalloet al., “Impacts of code of ethics on financial performance in the italian listed companies of bank sector,”Journal of Business Accounting and Finance Perspectives, vol. 1, no. 1, pp. 1–20, 2018
2018
-
[9]
J. Lee, H. L. Youn, J. Poon, and S. C. Han, “Stockemotions: Discover investor emotions for financial sentiment analysis and multivariate time series,”arXiv preprint arXiv:2301.09279, 2023
-
[10]
Towards semantic integration of opinions: Unified opinion concepts ontology and extraction task,
G. Negi, D. Dalal, O. Zayed, and P. Buitelaar, “Towards semantic integration of opinions: Unified opinion concepts ontology and extraction task,” inProceedings of the 5th Conference on Language, Data and Knowledge, M. Alam, A. Tchechmedjiev, J. Gracia, D. Gromann, M. P. di Buono, J. Monti, and M. Ionov, Eds. Naples, Italy: Unior Press, Sep. 2025, pp. 174–...
2025
-
[11]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amode...
2020
-
[12]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inAdvances in Neural In- formation Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 22 199–22 213
2022
-
[13]
Are they different? affect, feeling, emotion, sentiment, and opinion detection in text,
M. Munezero, C. S. Montero, E. Sutinen, and J. Pajunen, “Are they different? affect, feeling, emotion, sentiment, and opinion detection in text,”IEEE transactions on affective computing, vol. 5, no. 2, pp. 101– 111, 2014
2014
-
[14]
Stock market sentiment lexicon acquisition using microblogging data and statistical measures,
N. Oliveira, P. Cortez, and N. Areal, “Stock market sentiment lexicon acquisition using microblogging data and statistical measures,” Decision Support Systems, vol. 85, pp. 62–73, 2016. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167923616300240
2016
-
[15]
Learning stock market sentiment lexicon and sentiment-oriented word vector from StockTwits,
Q. Li and S. Shah, “Learning stock market sentiment lexicon and sentiment-oriented word vector from StockTwits,” inProceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), R. Levy and L. Specia, Eds. Vancouver, Canada: Association for Computational Linguistics, Aug. 2017, pp. 301–310. [Online]. Available: https://aclanth...
2017
-
[16]
D. Duxbury, T. G ¨arling, A. Gamble, and V . Klass, “How emotions influence behavior in financial markets: a conceptual analysis and emotion-based account of buy-sell preferences,”The European Journal of Finance, vol. 26, no. 14, pp. 1417–1438, 2020. [Online]. Available: https://doi.org/10.1080/1351847X.2020.1742758
-
[17]
Sentiment analysis and subjectivity
B. Liuet al., “Sentiment analysis and subjectivity.”Handbook of natural language processing, vol. 2, no. 2010, pp. 627–666, 2010
2010
-
[18]
Liu,Many Facets of Sentiment Analysis
B. Liu,Many Facets of Sentiment Analysis. Cham: Springer International Publishing, 2017, pp. 11–39. [Online]. Available: ”https://doi.org/10.1007/978-3-319-55394-8 2”
-
[19]
SemEval- 2016 task 5: Aspect based sentiment analysis,
M. Pontiki, D. Galanis, H. Papageorgiou, I. Androutsopoulos, S. Manandhar, M. AL-Smadi, M. Al-Ayyoub, Y . Zhao, B. Qin, O. De Clercq, V . Hoste, M. Apidianaki, X. Tannier, N. Loukachevitch, E. Kotelnikov, N. Bel, S. M. Jim ´enez-Zafra, and G. Eryi ˘git, “SemEval- 2016 task 5: Aspect based sentiment analysis,” inProceedings of the 10th International Worksh...
2016
-
[20]
Knowing what, how and why: A near complete solution for aspect-based sentiment analysis,
H. Peng, L. Xu, L. Bing, F. Huang, W. Lu, and L. Si, “Knowing what, how and why: A near complete solution for aspect-based sentiment analysis,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, pp. 8600–8607, Apr. 2020. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/6383
2020
-
[21]
SemEval-2017 task 5: Fine-grained sentiment analysis on financial microblogs and news,
K. Cortis, A. Freitas, T. Daudert, M. Huerlimann, M. Zarrouk, S. Handschuh, and B. Davis, “SemEval-2017 task 5: Fine-grained sentiment analysis on financial microblogs and news,” inProceedings of the 11th International Workshop on Semantic Evaluation (SemEval- 2017), S. Bethard, M. Carpuat, M. Apidianaki, S. M. Mohammad, D. Cer, and D. Jurgens, Eds. Vanco...
2017
-
[22]
An argument for basic emotions
P. Ekman, “An argument for basic emotions,”Cognition and Emotion, vol. 6, no. 3-4, pp. 169–200, 1992. [Online]. Available: https://doi.org/10.1080/02699939208411068
-
[23]
GoEmotions: A Dataset of Fine-Grained Emotions,
D. Demszky, D. Movshovitz-Attias, J. Ko, A. Cowen, G. Nemade, and S. Ravi, “GoEmotions: A Dataset of Fine-Grained Emotions,” in58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[24]
A systematic review of applications of natural language processing and future challenges with special emphasis in text-based emotion detection,
S. Kusal, S. Patil, J. Choudrie, K. Kotecha, D. V ora, and I. Pappas, “A systematic review of applications of natural language processing and future challenges with special emphasis in text-based emotion detection,” Artificial Intelligence Review, vol. 56, no. 12, pp. 15 129–15 215, 2023
2023
-
[25]
Emotion detection for social robots based on nlp transformers and an emotion ontology,
W. Graterol, J. Diaz-Amado, Y . Cardinale, I. Dongo, E. Lopes-Silva, and C. Santos-Libarino, “Emotion detection for social robots based on nlp transformers and an emotion ontology,”Sensors, vol. 21, no. 4, p. 1322, 2021
2021
-
[26]
Large language models as span annotators,
Z. Kasner, V . Zouhar, P. Schmidtov´a, I. Kart´aˇc, K. Onderkov´a, O. Pl´atek, D. Gkatzia, S. Mahamood, O. Du ˇsek, and S. Balloccu, “Large language models as span annotators,”arXiv preprint arXiv:2504.08697, 2025
-
[27]
Are large language models reliable argument quality annotators?
N. Mirzakhmedova, M. Gohsen, C. Chang, and B. Stein, “Are large language models reliable argument quality annotators?” inRobust Ar- gumentation Machines - First International Conference, RATIO 2024, Bielefeld, Germany, June 5-7, 2024, Proceedings, ser. Lecture Notes in Computer Science, P. Cimiano, A. Frank, M. Kohlhase, and B. Stein, Eds., vol. 14638. Sp...
2024
-
[28]
Large language models for propaganda span annotation,
M. Hasanain, F. Ahmad, and F. Alam, “Large language models for propaganda span annotation,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 14 522–14 532. [Online]. Available: https://aclanthology.org/202...
2024
-
[29]
Towards temporal knowledge-base creation for fine-grained opinion analysis with language models,
G. Negi, A. K. Ojha, O. Zayed, and P. Buitelaar, “Towards temporal knowledge-base creation for fine-grained opinion analysis with language models,”CoRR, vol. abs/2509.02363, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.02363
-
[30]
DSPy: Compiling declarative language model calls into state-of-the-art pipelines,
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. V . A, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, M. Zaharia, and C. Potts, “DSPy: Compiling declarative language model calls into state-of-the-art pipelines,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/fo...
2024
-
[31]
ProSA: Assessing and understanding the prompt sensitivity of LLMs,
J. Zhuo, S. Zhang, X. Fang, H. Duan, D. Lin, and K. Chen, “ProSA: Assessing and understanding the prompt sensitivity of LLMs,” in Findings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 1950–1976. [Online]. Availab...
2024
-
[32]
Optimizing instructions and demonstrations for multi- stage language model programs,
K. Opsahl-Ong, M. J. Ryan, J. Purtell, D. Broman, C. Potts, M. Zaharia, and O. Khattab, “Optimizing instructions and demonstrations for multi- stage language model programs,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Comput...
2024
-
[33]
How attentive are graph attention net- works?
S. Brody, U. Alon, and E. Yahav, “How attentive are graph attention net- works?” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=F72ximsx7C1
2022
-
[34]
BERT: Pre- training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds...
2019
-
[35]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review arXiv 1907
-
[36]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February
-
[37]
Available: https://qwen.ai/blog?id=qwen3.5
[Online]. Available: https://qwen.ai/blog?id=qwen3.5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.