Uncertainty Estimation in Instance Segmentation of Affordances via Bayesian Visual Transformers
Pith reviewed 2026-05-07 17:55 UTC · model grok-4.3
The pith
Bayesian visual transformers with ensemble and sampling methods achieve a 7.4 percentage point gain on weighted F-beta score for affordance instance segmentation on the IIT-Aff dataset while providing calibrated epistemic and aleatoric uncertainty maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results show that the global consensus of multiple sub-networks of Bayesian models improve deterministic networks due to a better mask refinement and generalization. This fact, joined with the more powerful features extracted by attention-based mechanisms, represent an improvement of +7.4 p.p on the F_β^w score in the challenging IIT-Aff dataset. Bayesian models are also better calibrated, producing less overconfident probabilities and with a better uncertainty estimation.
Load-bearing premise
That the chosen ensemble and sampling approximations in the Bayesian visual transformer architecture reliably separate epistemic from aleatoric uncertainty and that the observed gains on the IIT-Aff dataset generalize beyond the specific training and evaluation splits used.
Figures



read the original abstract
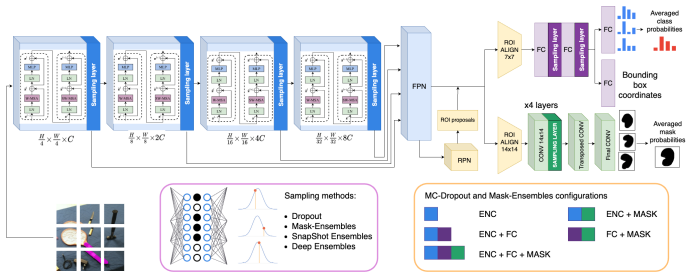
Visual affordances identify regions in an image with potential interactions, offering a novel paradigm for scene understanding. Recognizing affordances allows autonomous robots to act more naturally, could enhance human-robot interactions, enrich augmented reality systems, and benefit prosthetic vision devices. Accurate and localized prediction of affordance regions, rather than general saliency maps is crucial for these applications. We present a model for instance segmentation of affordances by adopting sample-based and ensembles approaches for uncertainty estimation. We extend an attention-based architecture for our novel task, showing with detailed ablation experiments the effects of each component. By comparing the distribution of these different detections, we extract pixel-wise epistemic and aleatoric variances at both the semantic and spatial levels. In addition, we propose a novel measure called Probability-based Mask Quality, which enables a comprehensive analysis of semantic and spatial variations in a probabilistic instance segmentation model. Our results show that the global consensus of multiple sub-networks of Bayesian models improve deterministic networks due to a better mask refinement and generalization. This fact, joined with the more powerful features extracted by attention-based mechanisms, represent an improvement of +7.4 p.p on the $F_{\beta}^w$ score in the challenging IIT-Aff dataset. Bayesian models are also better calibrated, producing less overconfident probabilities and with a better uncertainty estimation. Qualitative results show that aleatoric variance appears in the contour of the objects, while the epistemic variance is observed in visual challenging pixels, adding interpretability to the neural network.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a Bayesian Visual Transformer architecture for instance segmentation of visual affordances, using ensemble and sampling-based approximations to estimate epistemic and aleatoric uncertainty. It introduces a Probability-based Mask Quality metric for analyzing probabilistic outputs and claims that the consensus across Bayesian sub-networks, combined with attention-based features, yields better mask refinement, generalization, and calibration than deterministic networks, with a reported +7.4 p.p. gain in F_β^w on the IIT-Aff dataset. Qualitative results are said to show aleatoric variance at object contours and epistemic variance at challenging pixels.
Significance. If the gains can be robustly isolated to the Bayesian components rather than the attention backbone, the work would contribute a practical uncertainty-aware approach to affordance segmentation with potential utility in robotics and AR. The new mask quality measure and explicit epistemic/aleatoric separation add interpretability value, but the current presentation leaves the attribution of improvements unverified.
major comments (2)
- [Abstract] Abstract: The central claim attributes the +7.4 p.p. F_β^w improvement and better calibration to 'global consensus of multiple sub-networks of Bayesian models' plus attention features, yet no explicit ablation compares the full Bayesian VT against a deterministic VT with identical backbone, training protocol, and attention layers. Without this isolation, the load-bearing assumption that uncertainty estimation drives mask refinement cannot be evaluated.
- [Abstract] Abstract: Ablation experiments on each component are referenced, but the text supplies no quantitative results, baseline definitions, statistical significance tests, or error analysis for the reported calibration and uncertainty improvements. This prevents verification of whether the ensemble/sampling approximations reliably separate epistemic from aleatoric uncertainty on the IIT-Aff splits.
minor comments (2)
- The notation F_β^w is used without an explicit definition or reference to its weighting scheme in the provided text; a brief equation or citation would improve clarity.
- The Probability-based Mask Quality metric is introduced as novel but its exact formulation (e.g., how probability distributions over masks are aggregated) is not detailed in the abstract; a dedicated methods subsection would aid reproducibility.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ensemble and Monte-Carlo sampling methods provide a practical approximation to epistemic uncertainty in neural networks for segmentation tasks
invented entities (1)
-
Probability-based Mask Quality
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. J. Gibson, The theory of affordances, Hilldale, USA 1 (1977) 67–82
work page 1977
-
[2]
R. R. Murphy, Case studies of applying gibson’s ecological approach to mobile robots, IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans 29 (1999) 105–111
work page 1999
-
[3]
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al., Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
work page 2023
-
[4]
M. Sanchez-Garcia, R. Martinez-Cantin, J. J. Guerrero, Semantic and structural image segmentation for prosthetic vision, Plos one 15 (2020) e0227677
work page 2020
-
[5]
T. Nagarajan, C. Feichtenhofer, K. Grauman, Grounded human-object interaction hotspots from video, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 8688–8697
work page 2019
-
[6]
K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask r-cnn, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2961– 2969
work page 2017
-
[7]
J. Doherty, B. Gardiner, E. Kerr, N. Siddique, Bifpn-yolo: One-stage object de- tection integrating bi-directional feature pyramid networks, Pattern Recognition 160 (2025) 111209
work page 2025
-
[8]
A. Furnari, G. M. Farinella, What would you expect? anticipating egocentric actions with rolling-unrolling lstms and modality attention, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 6252–6261. 28
work page 2019
-
[9]
T. Nagarajan, Y . Li, C. Feichtenhofer, K. Grauman, Ego-topo: Environment affordances from egocentric video, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 163–172
work page 2020
-
[10]
C. Guo, G. Pleiss, Y . Sun, K. Q. Weinberger, On calibration of modern neural networks, in: International Conference on Machine Learning, PMLR, 2017, pp. 1321–1330
work page 2017
-
[11]
D. Morilla-Cabello, L. Mur-Labadia, R. Martinez-Cantin, E. Montijano, Robust fusion for Bayesian semantic mapping, 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2023)
work page 2023
-
[12]
L. Mur-Labadia, R. Martinez-Cantin, J. Guerrero, Bayesian deep learning for af- fordance segmentation in images, in: 2023 International Conference on Robotics and Automation (ICRA), IEEE, 2023
work page 2023
-
[13]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, B. Guo, Swin trans- former: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10012–10022
work page 2021
-
[14]
Y . Gal, Z. Ghahramani, Dropout as a Bayesian approximation: Representing model uncertainty in deep learning, in: International Conference on Machine Learning (ICML), PMLR, 2016, pp. 1050–1059
work page 2016
-
[15]
N. Durasov, T. Bagautdinov, P. Baque, P. Fua, Masksembles for uncertainty esti- mation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13539–13548
work page 2021
-
[16]
B. Lakshminarayanan, A. Pritzel, C. Blundell, Simple and scalable predictive uncertainty estimation using deep ensembles, Advances in neural information processing systems 30 (2017)
work page 2017
- [17]
-
[18]
H. S. Koppula, A. Saxena, Anticipating human activities using object affordances for reactive robotic response, IEEE Transactions on Pattern Analysis and Machine Intelligence 38 (2015) 14–29
work page 2015
-
[19]
L. Mur-Labadia, J. J. Guerrero, R. Martinez-Cantin, Multi-label affordance map- ping from egocentric vision, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 5238–5249
work page 2023
-
[20]
L. Montesano, M. Lopes, A. Bernardino, J. Santos-Victor, Learning object af- fordances: from sensory–motor coordination to imitation, IEEE Transactions on Robotics 24 (2008) 15–26
work page 2008
-
[21]
S. Yang, W. Zhang, R. Song, J. Cheng, H. Wang, Y . Li, Watch and act: Learning robotic manipulation from visual demonstration, IEEE Transactions on Systems, Man, and Cybernetics: Systems (2023)
work page 2023
- [22]
-
[23]
A. Nguyen, D. Kanoulas, D. G. Caldwell, N. Tsagarakis, Object-based affor- dances detection with convolutional neural networks and dense conditional ran- dom fields, in: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2017, pp. 5908–5915
work page 2017
- [24]
-
[25]
T.-T. Do, A. Nguyen, I. Reid, Affordancenet: An end-to-end deep learning ap- proach for object affordance detection, in: 2018 International Conference on Robotics and Automation (ICRA), IEEE, 2018, pp. 5882–5889. 30
work page 2018
-
[26]
C. N. D. Minh, S. Z. Gilani, S. M. S. Islam, D. Suter, Learning affordance seg- mentation: An investigative study, in: 2020 Digital Image Computing: Tech- niques and Applications (DICTA), IEEE, 2020, pp. 1–8
work page 2020
-
[27]
H. Caselles-Dupré, M. Garcia-Ortiz, D. Filliat, Are standard object segmen- tation models sufficient for learning affordance segmentation?, arXiv preprint arXiv:2107.02095 (2021)
-
[28]
T. Apicella, A. Xompero, P. Gastaldo, A. Cavallaro, Segmenting object affor- dances: Reproducibility and sensitivity to scale, in: European Conference on Computer Vision Workshops, Springer, 2024, pp. 286–304
work page 2024
-
[29]
K. Fang, T.-L. Wu, D. Yang, S. Savarese, J. J. Lim, Demo2vec: Reasoning object affordances from online videos, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2139–2147
work page 2018
-
[30]
G. Li, N. Tsagkas, J. Song, R. Mon-Williams, S. Vijayakumar, K. Shao, L. Sevilla-Lara, Learning precise affordances from egocentric videos for robotic manipulation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 10581–10591
work page 2025
-
[31]
M. Heidinger, S. Jauhri, V . Prasad, G. Chalvatzaki, 2handedafforder: Learning precise actionable bimanual affordances from human videos, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 14743– 14753
work page 2025
-
[32]
S. Qian, W. Chen, M. Bai, X. Zhou, Z. Tu, L. E. Li, Affordancellm: Ground- ing affordance from vision language models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7587–7597
work page 2024
-
[33]
C. Cuttano, G. Rosi, G. Trivigno, G. Averta, What does clip know about peeling a banana?, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2238–2247. 31
work page 2024
-
[34]
G. Li, D. Sun, L. Sevilla-Lara, V . Jampani, One-shot open affordance learning with foundation models, in: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 3086–3096
work page 2024
-
[35]
J. Tang, G. Zheng, J. Yu, S. Yang, Cotdet: Affordance knowledge prompting for task driven object detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 3068–3078
work page 2023
-
[36]
D. Wu, Y . Fu, S. Huang, Y . Liu, F. Jia, N. Liu, F. Dai, T. Wang, R. M. Anwer, F. S. Khan, et al., Ragnet: Large-scale reasoning-based affordance segmentation benchmark towards general grasping, in: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2025, pp. 11980–11990
work page 2025
-
[37]
X. Wang, X. Yang, Y . Xu, Y . Wu, Z. Li, N. Zhao, Affordbot: 3d fine-grained embodied reasoning via multimodal large language models, in: Advances in Neural Information Processing Systems, 2025
work page 2025
-
[38]
D. Lu, L. Kong, T. Huang, G. H. Lee, Geal: Generalizable 3d affordance learn- ing with cross-modal consistency, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1680–1690
work page 2025
-
[39]
W. Moon, H. S. Seong, J.-P. Heo, Selective contrastive learning for weakly su- pervised affordance grounding, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5210–5220
work page 2025
-
[40]
T. Apicella, A. Xompero, A. Cavallaro, Visual affordance prediction: Survey and reproducibility, arXiv preprint arXiv:2505.05074 (2025)
-
[41]
T. Papamarkou, M. Skoularidou, K. Palla, L. Aitchison, J. Arbel, D. Dunson, M. Filippone, V . Fortuin, P. Hennig, J. M. Hernández-Lobato, et al., Position: Bayesian deep learning is needed in the age of large-scale ai, in: International Conference on Machine Learning, PMLR, 2024, pp. 39556–39586
work page 2024
-
[42]
V . D. Wild, S. Ghalebikesabi, D. Sejdinovic, J. Knoblauch, A rigorous link be- tween deep ensembles and (variational) bayesian methods, in: Advances in Neu- ral Information Processing Systems, 2023, pp. 39782–39811. 32
work page 2023
-
[43]
B. G. Doan, A. Shamsi, X.-Y . Guo, A. Mohammadi, H. Alinejad-Rokny, D. Sejdi- novic, D. Teney, D. C. Ranasinghe, E. Abbasnejad, Bayesian low-rank learning (bella): A practical approach to bayesian neural networks, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 2025, pp. 16298–16307
work page 2025
-
[44]
J. Postels, H. Blum, C. Cadena, R. Siegwart, L. V . Gool, F. Tombari, Quantifying aleatoric and epistemic uncertainty using density estimation in latent space, Pro- ceedings of the 39th Conference on Uncertainty in Artificial Intelligence (2023)
work page 2023
- [45]
- [46]
- [47]
-
[48]
A. Gleave, G. Irving, Uncertainty estimation for language reward models, arXiv preprint arXiv:2203.07472 (2022)
-
[49]
H. Wang, Q. Ji, Beyond dirichlet-based models: when bayesian neural networks meet evidential deep learning, in: The 40th Conference on Uncertainty in Artifi- cial Intelligence, 2024
work page 2024
-
[50]
A. Kendall, Y . Gal, What uncertainties do we need in Bayesian deep learning for computer vision?, 31st Conference on Neural Information Processing Systems (NIPS) (2017)
work page 2017
-
[51]
G.-P. Ji, L. Zhu, M. Zhuge, K. Fu, Fast camouflaged object detection via edge- based reversible re-calibration network, Pattern Recognition 123 (2022) 108414
work page 2022
-
[52]
S. Kim, P. Chikontwe, S. An, S. H. Park, Uncertainty-aware semi-supervised few shot segmentation, Pattern Recognition 137 (2023) 109292. 33
work page 2023
-
[53]
S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detec- tion with region proposal networks, Advances in neural information processing systems 28 (2015)
work page 2015
- [54]
-
[55]
R. Margolin, L. Zelnik-Manor, A. Tal, How to evaluate foreground maps?, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2014, pp. 248–255
work page 2014
-
[56]
D. Hall, F. Dayoub, J. Skinner, H. Zhang, D. Miller, P. Corke, G. Carneiro, A. An- gelova, N. Sünderhauf, Probabilistic object detection: Definition and evaluation, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision (W ACV), 2020, pp. 1031–1040
work page 2020
-
[57]
H. W. Kuhn, The hungarian method for the assignment problem, Naval research logistics quarterly 2 (1955) 83–97
work page 1955
-
[58]
G. W. Brier, et al., Verification of forecasts expressed in terms of probability, Monthly weather review 78 (1950) 1–3
work page 1950
-
[59]
C. Yin, Q. Zhang, Object affordance detection with boundary-preserving network for robotic manipulation tasks, Neural Computing and Applications 34 (2022) 17963–17980
work page 2022
- [60]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.