Recognition: unknown
A Robust Unsupervised Domain Adaptation Framework for Medical Image Classification Using RKHS-MMD
Pith reviewed 2026-05-07 17:51 UTC · model grok-4.3
The pith
A framework aligns chest X-ray distributions from different centers by adding an RKHS-MMD loss to standard classification training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that embedding the RKHS-MMD term inside a transfer-learning pipeline lets the model minimize the distance between source and target feature distributions in a reproducing kernel Hilbert space while preserving discriminative power for the classification task, thereby raising target-domain accuracy on chest radiographs collected at a second medical center.
What carries the argument
The RKHS-MMD loss, a kernel-based statistic that quantifies and penalizes the difference between the mean embeddings of source and target features inside a reproducing kernel Hilbert space.
If this is right
- Target-domain accuracy rises when the RKHS-MMD term is optimized jointly with the classification loss.
- RKHS-MMD produces tighter domain alignment than the unkernelized maximum mean discrepancy on the same medical-image pairs.
- The resulting model requires fewer labeled examples from the new center to reach usable performance.
- The same joint-loss structure can be applied to other pairs of medical imaging sites that exhibit modality shifts.
Where Pith is reading between the lines
- If the alignment holds across scanner vendors, hospitals could deploy a single model to incoming streams of images from newly purchased equipment.
- The same loss construction might serve as a lightweight regularizer inside semi-supervised pipelines that already have a small number of target labels.
- Failure modes would appear if the source and target label distributions differ substantially, a case not tested in the reported experiments.
Load-bearing premise
Aligning the two chest X-ray distributions through the RKHS-MMD term is enough to close the domain gap without causing negative transfer that would lower target accuracy.
What would settle it
An experiment in which adding the RKHS-MMD loss to the training objective lowers classification accuracy on the target chest X-ray set relative to a baseline trained without any adaptation term.
Figures



read the original abstract
Labeling medical images is a major bottleneck in the field of medical imaging, as it requires domain-specific expertise, and it gets further complicated due to variability across different medical centers and different imaging devices. Such heterogeneity introduces domain shifts and modality discrepancies, which limits the generalization of trained models. To address this important challenge, we propose an unsupervised domain adaptation framework that combines transfer learning with a Reproducing Kernel Hilbert Space based Maximum Mean Discrepancy loss for the alignment of source and target domains. By jointly optimizing classification and RKHS-MMD losses, the methodology enhances generalization to unannotated medical datasets while diminishing reliance on manual annotation. Experimental evaluations presented on two chest X-ray datasets, which are obtained from different medical centers, show outstanding improvements over models trained without adaptation. Furthermore, we perform a comparative study to see that RKHS-MMD performs better than the standard Maximum Mean Discrepancy in reducing modality gap, emphasizing its effectiveness for medical image classification and also its strong capability in advanced AI-driven medical diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an unsupervised domain adaptation framework for medical image classification that combines transfer learning with a Reproducing Kernel Hilbert Space Maximum Mean Discrepancy (RKHS-MMD) loss to align source and target domain distributions. It evaluates the approach on two chest X-ray datasets from different medical centers, claiming outstanding improvements over models trained without adaptation and superior performance to standard MMD in reducing the modality gap.
Significance. If the reported empirical gains hold under scrutiny, the work has moderate practical significance for medical AI by enabling cross-center generalization without target-domain labels, thereby addressing annotation bottlenecks. The direct comparison to standard MMD is a useful contribution, though the method builds directly on established UDA techniques without new theoretical machinery.
major comments (2)
- Abstract: The central claim of 'outstanding improvements' and superiority over standard MMD is asserted without any quantitative metrics, baseline details, statistical tests, or protocol description. While the full manuscript includes accuracy tables on source/target domains and a RKHS-MMD vs. MMD comparison, the absence of these elements in the abstract undermines immediate assessment of whether the data support the headline result.
- Experimental evaluation section: The assumption that RKHS-MMD alignment reduces domain shift without negative transfer is load-bearing for the robustness claim, yet no ablation studies or analysis of potential target-domain performance degradation are reported; this leaves open whether the joint optimization harms classification accuracy in some regimes.
minor comments (2)
- Clarify the exact kernel function, bandwidth selection procedure, and implementation details of the RKHS-MMD term to support reproducibility.
- Add p-values or confidence intervals to the accuracy tables to substantiate the comparative superiority statements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and robustness of our manuscript. We address each major comment point by point below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: Abstract: The central claim of 'outstanding improvements' and superiority over standard MMD is asserted without any quantitative metrics, baseline details, statistical tests, or protocol description. While the full manuscript includes accuracy tables on source/target domains and a RKHS-MMD vs. MMD comparison, the absence of these elements in the abstract undermines immediate assessment of whether the data support the headline result.
Authors: We agree that the abstract would benefit from including key quantitative support for the claims to enable immediate assessment. The full paper reports specific accuracy gains (e.g., target-domain improvements of several percentage points over the non-adapted baseline and better alignment than standard MMD), but these were omitted from the abstract for brevity. We will revise the abstract to incorporate concise quantitative metrics, baseline references, and a brief note on the evaluation protocol while preserving its high-level nature. revision: yes
-
Referee: Experimental evaluation section: The assumption that RKHS-MMD alignment reduces domain shift without negative transfer is load-bearing for the robustness claim, yet no ablation studies or analysis of potential target-domain performance degradation are reported; this leaves open whether the joint optimization harms classification accuracy in some regimes.
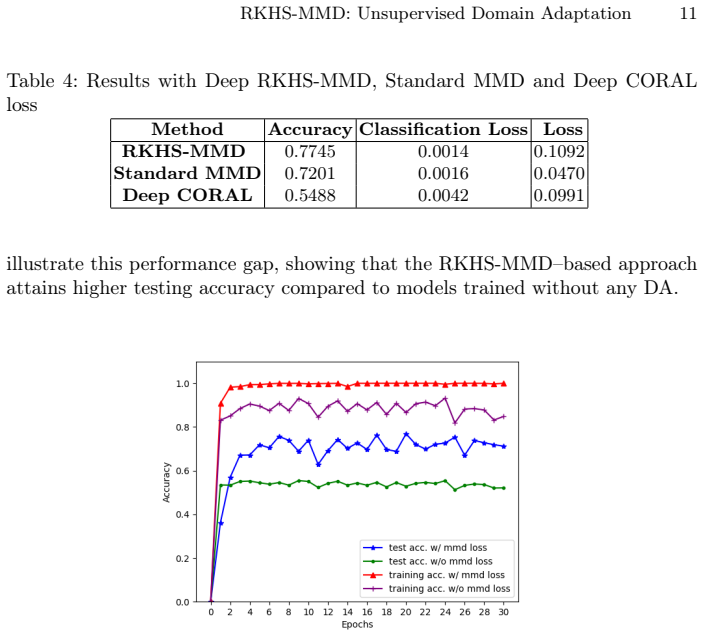
Authors: We acknowledge that explicit verification of no negative transfer strengthens the robustness claim. Our reported results show that the jointly optimized model consistently achieves higher target-domain accuracy than the source-only baseline across both chest X-ray datasets, with no observed degradation. To directly address the concern, we will add an ablation study in the revised manuscript that varies the RKHS-MMD loss weight and reports the resulting target accuracies, demonstrating stable or improved performance without harm in the tested regimes. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a standard unsupervised domain adaptation method by jointly optimizing a classification loss with the established RKHS-MMD discrepancy measure for aligning source and target distributions in medical imaging. No derivation step reduces by construction to its own inputs: the RKHS-MMD term is an off-the-shelf kernel statistic, not redefined or fitted in a self-referential manner, and the reported gains are empirical comparisons against baselines on external chest X-ray datasets from different centers. The central claim therefore rests on independent experimental validation rather than any self-definition, fitted-input renaming, or load-bearing self-citation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unified deep supervised domain adaptation and generalization,
S. Motiian, M. Piccirilli, D. A. Adjeroh, and G. Doretto, “Unified deep supervised domain adaptation and generalization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 5715–5725. 2 12 Sachan et al
2017
-
[2]
Unsupervised domain adaptation by backpropaga- tion,
Y. Ganin and V. Lempitsky, “Unsupervised domain adaptation by backpropaga- tion,” inInternational conference on machine learning. PMLR, 2015, pp. 1180–
2015
-
[3]
Imagenet large scale visual recognition chal- lenge,
O.Russakovsky,J.Deng,H.Su,J.Krause,S.Satheesh,S.Ma,Z.Huang,A.Karpa- thy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition chal- lenge,”International journal of computer vision, vol. 115, pp. 211–252, 2015. 2
2015
-
[4]
Quiñonero-Candela, M
J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence, Dataset shift in machine learning. Mit Press, 2022. 2
2022
-
[5]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical image computing and computer- assisted intervention–MICCAI 2015: 18th international conference, Munich, Ger- many, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241. 2
2015
-
[6]
Domain adaptive learning based on sample-dependent and learnable kernels,
X. Lu, Z. Ma, and Y. Lin, “Domain adaptive learning based on sample-dependent and learnable kernels,”arXiv preprint arXiv:2102.09340, 2021. 2
-
[7]
Return of frustratingly easy domain adaptation,
B. Sun, J. Feng, and K. Saenko, “Return of frustratingly easy domain adaptation,” inProceedings of the AAAI conference on artificial intelligence, vol. 30, no. 1, 2016. 3
2016
-
[8]
Deep coral: Correlation alignment for deep domain adapta- tion,
B. Sun and K. Saenko, “Deep coral: Correlation alignment for deep domain adapta- tion,” inComputer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part III 14. Springer, 2016, pp. 443–
2016
-
[9]
Exploring the limits of weakly supervised pretraining,
D. Mahajan, R. Girshick, V. Ramanathan, K. He, M. Paluri, Y. Li, A. Bharambe, and L. Van Der Maaten, “Exploring the limits of weakly supervised pretraining,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 181–196. 3, 4
2018
-
[12]
Deep Domain Confusion: Maximizing for Domain Invariance
E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell, “Deep domain con- fusion: Maximizing for domain invariance,”arXiv preprint arXiv:1412.3474, 2014. 3
work page Pith review arXiv 2014
-
[13]
Imagenet classification with deep convolutionalneuralnetworks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutionalneuralnetworks,”Advances in neural information processing systems, vol. 25, 2012. 3
2012
-
[14]
Learning transferable features with deep adaptation networks,
M. Long, Y. Cao, J. Wang, and M. Jordan, “Learning transferable features with deep adaptation networks,” inInternational conference on machine learning. PMLR, 2015, pp. 97–105. 3
2015
-
[15]
Deep subdomain adaptation network for image classification,
Y. Zhu, F. Zhuang, J. Wang, G. Ke, J. Chen, J. Bian, H. Xiong, and Q. He, “Deep subdomain adaptation network for image classification,”IEEE transactions on neural networks and learning systems, vol. 32, no. 4, pp. 1713–1722, 2020. 3
2020
-
[16]
Auc-oriented domain adaptation: from theory to algorithm,
Z. Yang, Q. Xu, S. Bao, P. Wen, Y. He, X. Cao, and Q. Huang, “Auc-oriented domain adaptation: from theory to algorithm,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 3
2023
-
[17]
Unsupervised domain adaptation via deep conditional adaptation network,
P. Ge, C.-X. Ren, X.-L. Xu, and H. Yan, “Unsupervised domain adaptation via deep conditional adaptation network,”Pattern Recognition, vol. 134, p. 109088,
-
[18]
3 RKHS-MMD: Unsupervised Domain Adaptation 13
-
[19]
A survey of unsupervised deep domain adaptation,
G. Wilson and D. J. Cook, “A survey of unsupervised deep domain adaptation,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 11, no. 5, pp. 1–46, 2020. 3
2020
-
[20]
Conditional adversarial domain adaptation,
M. Long, Z. Cao, J. Wang, and M. I. Jordan, “Conditional adversarial domain adaptation,”Advances in neural information processing systems, vol. 31, 2018. 4
2018
-
[21]
Maximum classifier discrep- ancy for unsupervised domain adaptation,
K. Saito, K. Watanabe, Y. Ushiku, and T. Harada, “Maximum classifier discrep- ancy for unsupervised domain adaptation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3723–3732. 4
2018
-
[22]
Domain adapta- tion using pseudo labels for covid-19 detection,
R. Yuan, Q. Li, J. Hou, J. Xu, Y. Zhang, R. Feng, and H. Chen, “Domain adapta- tion using pseudo labels for covid-19 detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5141–5148. 4
2024
-
[23]
Semi-supervised domain adaptation via minimax entropy,
K. Saito, D. Kim, S. Sclaroff, T. Darrell, and K. Saenko, “Semi-supervised domain adaptation via minimax entropy,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 8050–8058. 4
2019
-
[24]
Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation,
J. Liang, D. Hu, and J. Feng, “Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation,” inInternational confer- ence on machine learning. PMLR, 2020, pp. 6028–6039. 4
2020
-
[25]
Generalized cross entropy loss for training deep neural networks with noisy labels,
Z. Zhang and M. Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels,”Advances in neural information processing systems, vol. 31, 2018. 5
2018
-
[26]
Labeled optical coherence tomography (oct) and chest x-ray images for classification,
D. Kermany, “Labeled optical coherence tomography (oct) and chest x-ray images for classification,”Mendeley data, 2018. 8
2018
-
[27]
Curated dataset for covid-19 posterior-anterior chest radiography images (x- rays),
U. Sait, K. Lal, S. Prajapati, R. Bhaumik, T. Kumar, S. Sanjana, and K. Bhalla, “Curated dataset for covid-19 posterior-anterior chest radiography images (x- rays),”Mendeley Data, vol. 1, no. J, 2020. 8
2020
-
[28]
Efficientnetv2: Smaller models and faster training,
M. Tan and Q. Le, “Efficientnetv2: Smaller models and faster training,” inInter- national conference on machine learning. PMLR, 2021, pp. 10096–10106. 8
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.