Recognition: 2 theorem links
An Agent-Oriented Pluggable Experience-RAG Skill for Experience-Driven Retrieval Strategy Orchestration
Pith reviewed 2026-05-08 18:07 UTC · model grok-4.3
The pith
Retrieval strategy selection can be encapsulated as a pluggable agent skill that consults experience memory to adapt across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
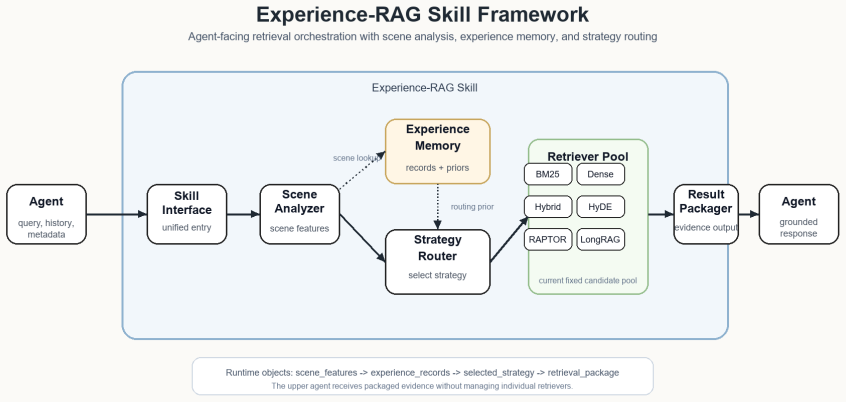
Experience-RAG Skill, an agent-oriented pluggable retrieval orchestration layer positioned between the agent and the retriever pool, analyzes the current scene, consults an experience memory, selects an appropriate retrieval strategy, and returns structured evidence to the agent. Under a fixed candidate pool, it achieves an overall nDCG@10 of 0.8924 on BeIR/nq, BeIR/hotpotqa, and BeIR/scifact, outperforming fixed single-retriever baselines and remaining competitive with Adaptive-RAG-style routing. The results suggest that retrieval strategy selection can be productively encapsulated as a reusable agent skill rather than being hard-coded in the upper workflow.
What carries the argument
Experience-RAG Skill: a pluggable layer that analyzes the current scene, consults experience memory to select a retrieval strategy from a fixed pool, and supplies structured evidence back to the agent.
If this is right
- Different tasks such as factoid QA, multi-hop reasoning, and scientific verification can each receive a tailored retrieval strategy without any change to the agent's core logic.
- The modular skill design keeps performance competitive with specialized routing systems while remaining reusable across agents.
- New retrieval strategies can be added to the candidate pool and become available through the same experience-driven selection process.
- Experience memory accumulates selections over time, allowing the skill to improve its choices on repeated or similar scenes without retraining the agent.
Where Pith is reading between the lines
- The same experience-driven selection pattern could apply to other agent decisions such as tool choice or prompting style.
- If the memory remains small and task-agnostic, the approach may scale to agents that encounter a wider range of retrieval needs without custom engineering per domain.
- One could test whether the skill still works when the retriever pool itself changes dynamically during operation.
Load-bearing premise
An experience memory can reliably guide selection of retrieval strategies across heterogeneous tasks without introducing overhead or performance loss that offsets the gains.
What would settle it
A controlled test on a new task or retriever pool where the skill's choices produce lower nDCG than the single best fixed retriever or add measurable extra latency that reduces end-to-end performance.
Figures
read the original abstract
Retrieval-augmented generation systems often assume that one fixed retrieval pipeline is sufficient across heterogeneous tasks, yet factoid question answering, multi-hop reasoning, and scientific verification exhibit different retrieval preferences. We present Experience-RAG Skill, an agent-oriented pluggable retrieval orchestration layer positioned between the agent and the retriever pool. The proposed skill analyzes the current scene, consults an experience memory, selects an appropriate retrieval strategy, and returns structured evidence to the agent. Under a fixed candidate pool, Experience-RAG Skill achieves an overall nDCG@10 of 0.8924 on BeIR/nq, BeIR/hotpotqa, and BeIR/scifact, outperforming fixed single-retriever baselines and remaining competitive with Adaptive-RAG-style routing. The results suggest that retrieval strategy selection can be productively encapsulated as a reusable agent skill rather than being hard-coded in the upper workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an 'Experience-RAG Skill' as a pluggable, agent-oriented layer for orchestrating retrieval strategies in retrieval-augmented generation (RAG) systems. Positioned between the agent and a pool of retrievers, the skill analyzes the current query scene, consults an experience memory to select an appropriate retrieval strategy, and returns structured evidence. The central empirical claim is that, under a fixed candidate pool, this skill achieves an overall nDCG@10 of 0.8924 across BeIR/nq, BeIR/hotpotqa, and BeIR/scifact, outperforming fixed single-retriever baselines while remaining competitive with Adaptive-RAG-style routing. The authors suggest that retrieval strategy selection can be usefully encapsulated as a reusable agent skill.
Significance. If the reported performance gains are reproducible and attributable to the proposed experience-driven orchestration rather than implementation specifics, this work could meaningfully advance agentic RAG systems by providing a modular, pluggable mechanism for handling task-specific retrieval preferences. This addresses a practical limitation in current RAG deployments where a single fixed pipeline is often assumed sufficient across diverse tasks like factoid QA, multi-hop reasoning, and scientific fact verification. The pluggable skill design offers potential for reusability and easier integration into larger agent workflows.
major comments (1)
- [Abstract and Experimental Results] Abstract and Experimental Results: The manuscript reports a specific aggregate nDCG@10 of 0.8924 and claims of outperformance over fixed single-retriever baselines and competitiveness with Adaptive-RAG-style routing, yet supplies no description of the experience memory structure, the process for populating or updating it, the decision procedure or algorithm for selecting a retrieval strategy from the pool, the exact composition of the fixed candidate pool, or the precise implementations and hyper-parameters of the compared baselines. These omissions are load-bearing for the central claim, as the empirical results are the primary evidence offered for the utility of the Experience-RAG Skill.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying the need for greater implementation detail to support the central empirical claims. We address the major comment below and will revise the manuscript to improve reproducibility and clarity.
read point-by-point responses
-
Referee: The manuscript reports a specific aggregate nDCG@10 of 0.8924 and claims of outperformance over fixed single-retriever baselines and competitiveness with Adaptive-RAG-style routing, yet supplies no description of the experience memory structure, the process for populating or updating it, the decision procedure or algorithm for selecting a retrieval strategy from the pool, the exact composition of the fixed candidate pool, or the precise implementations and hyper-parameters of the compared baselines. These omissions are load-bearing for the central claim, as the empirical results are the primary evidence offered for the utility of the Experience-RAG Skill.
Authors: We agree that the current manuscript does not supply these implementation details, which are necessary for reproducibility and for readers to assess the source of the reported performance. In the revised version we will expand the methodology and experimental sections to describe the experience memory structure, the process for populating and updating it, the decision procedure for selecting a retrieval strategy, the exact composition of the fixed candidate pool, and the precise implementations together with hyper-parameters of the baselines. These additions will be supported by pseudocode and tables drawn from our experimental setup and will be placed in the main text or an appendix. The reported nDCG@10 figure and comparative claims will remain unchanged. revision: yes
Circularity Check
No significant circularity; empirical benchmark claim stands independently
full rationale
The paper introduces Experience-RAG Skill as a pluggable orchestration layer that analyzes scenes and consults experience memory for retrieval strategy selection. Its central performance claim (overall nDCG@10 of 0.8924 on three BeIR datasets, outperforming fixed single-retriever baselines) is presented as the direct outcome of experimental evaluation under a fixed candidate pool. No equations, self-definitional constructs, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The result does not reduce to its own inputs by construction and remains externally falsifiable via the reported benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Experience memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv preprint arXiv:2005.11401, 2020
work page internal anchor Pith review arXiv 2005
-
[2]
REALM: Retrieval-Augmented Language Model Pre-Training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-Augmented Language Model Pre-Training. In Proceedings of ICML, 2020
2020
-
[3]
Gautier Izacard and Edouard Grave. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. arXiv preprint arXiv:2007.01282, 2021
-
[4]
Improving Language Models by Retrieving from Trillions of Tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, et al. Improving Language Models by Retrieving from Trillions of Tokens. In Proceedings of ICML, 2022
2022
-
[5]
Query Rewriting in Retrieval-Augmented Large Language Models
Xueguang Ma, Yeyun Gong, Pengcheng He, et al. Query Rewriting in Retrieval-Augmented Large Language Models. In Proceedings of EMNLP, 2023
2023
-
[6]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
Parth Sarthi, Salman Abdullah, Aman Tuli, et al. RAPTOR: Recursive Abstractive Pro- cessing for Tree-Organized Retrieval. arXiv preprint arXiv:2401.18059, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Active retrieval augmented genera- tion,
Zhengbao Jiang, Frank F. Xu, Luyu Gao, et al. Active Retrieval Augmented Generation. arXiv preprint arXiv:2305.06983, 2023
-
[8]
Corrective Retrieval Augmented Generation
Shengnan Yan et al. CRAG: Corrective Retrieval Augmented Generation. arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai et al. Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection. arXiv preprint arXiv:2310.11511, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
arXiv preprint arXiv:2406.15319
Jinhao Jiang, Yuhui Xu, Ming Feng, et al. LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs. arXiv preprint arXiv:2406.15319, 2024. 4
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, et al. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of ICLR, 2023
2023
-
[12]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, et al. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
HuggingGPT: Solving AI Tasks with Chat- GPT and its Friends in Hugging Face
Yongliang Shen, Kaitao Song, Xu Tan, et al. HuggingGPT: Solving AI Tasks with Chat- GPT and its Friends in Hugging Face. In Advances in Neural Information Processing Systems, 2023
2023
-
[14]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large Language Model Connected with Massive APIs. arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L
Theodore R. Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L. Griffiths. Cog- nitive Architectures for Language Agents. Transactions on Machine Learning Research, 2023
2023
-
[16]
Precise zero-shot dense retrieval without relevance labels,
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise Zero-Shot Dense Retrieval without Relevance Labels. arXiv preprint arXiv:2212.10496, 2022
- [17]
-
[18]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Nandan Thakur, Nils Reimers, Andreas Rueckle, et al. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. arXiv preprint arXiv:2104.08663, 2021. A Supplementary Experiments A.1 Ablation Study To better understand where the gains of Experience-RAG Skill come from, we also evaluated several ablated variants. The full Exp...
work page internal anchor Pith review arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.