Recognition: 2 theorem links
· Lean TheoremFMI_SU_Yotkova_Kastreva at SemEval-2026 Task 13: Lightweight Detection of LLM-Generated Code via Stylometric Signals
Pith reviewed 2026-05-08 18:01 UTC · model grok-4.3
The pith
A lightweight system of ratio-based stylometric features, parsing signals, and a shallow decision tree detects LLM-generated code across unseen languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
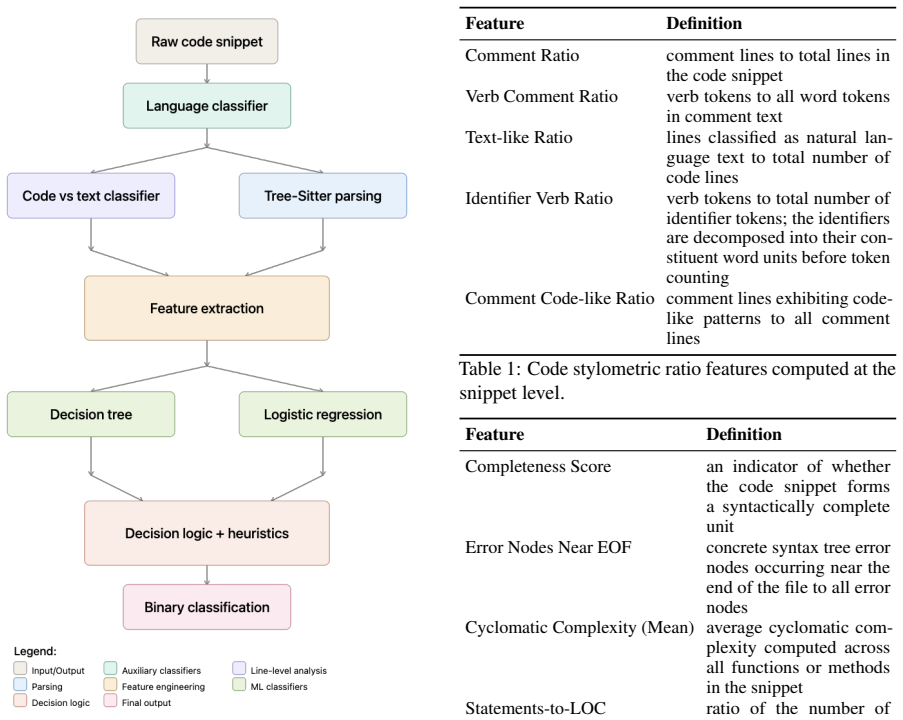
The central claim is that ratio-based stylometric features less sensitive to snippet length, extracted with parsing engines and programming-language and code-versus-text classifiers, can be combined with a shallow decision tree and data-derived heuristic rules to yield accurate binary predictions of LLM-generated code while remaining computationally efficient and requiring only CPU resources for training.
What carries the argument
Ratio-based stylometric features that capture length-independent signals from code structure and descriptiveness, routed through a shallow decision tree augmented by heuristic rules.
If this is right
- The pipeline achieves competitive binary classification without any pretrained neural encoders.
- Training uses only CPU resources and inference completes in near-instant time.
- The same feature set and decision-tree-plus-heuristics structure supports generalization across the languages and scenarios required by the SemEval task.
- Heuristic rules derived from data analysis can be layered on top of the learned tree to refine final predictions.
Where Pith is reading between the lines
- The same lightweight pipeline could be embedded in code-review tools to provide immediate flags for possible AI assistance without requiring server-side GPUs.
- Persistent differences captured by the ratio features may remain detectable even after future LLMs are trained to mimic human coding styles more closely.
- The approach invites direct comparison experiments that swap the decision tree for other shallow models to measure how much of the performance is carried by the features versus the classifier.
- Because the system avoids large models, it could serve as a baseline for studying whether detection difficulty scales with model size or training data volume.
Load-bearing premise
The ratio-based stylometric features and parsing signals will continue to separate human and generated code reliably when the system encounters programming languages and application domains absent from training data.
What would settle it
A test set of code snippets drawn from a previously unseen programming language and domain where the system’s accuracy falls to chance level or below a simple majority-class baseline would falsify the generalization claim.
Figures

read the original abstract
SemEval-2026 Task 13 investigates machine-generated code detection across multiple programming languages and application scenarios, asking participating systems to generalize to unseen languages and domains. This paper describes our participation in Subtask A (binary classification) and explores both pretrained code encoders and lightweight feature-based methods. We design ratio-based features that are less sensitive to snippet length. To support the extraction of descriptiveness-related signals, we use parsing engines and a programming-language classifier. Additionally, we train a separate code-vs-text line classifier to identify raw natural language segments embedded within samples. We combine a shallow decision tree with heuristic rules derived from data analysis to produce the final predictions. Our approach is computationally efficient, requires only CPU resources for training, and achieves near-instant inference time, offering a lightweight alternative to large pretrained models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the FMI_SU_Yotkova_Kastreva team's entry in SemEval-2026 Task 13 Subtask A (binary classification of LLM-generated vs. human-written code). The central contribution is a lightweight pipeline that extracts ratio-based stylometric features (designed to be length-insensitive), parsing-derived signals for descriptiveness, a separate line-level code-vs-text classifier, and a programming-language identifier; these feed a shallow decision tree augmented by data-derived heuristic rules. The authors emphasize that the system trains and runs on CPU only with near-instant inference, positioning it as a practical alternative to pretrained code encoders while addressing the task's requirement to generalize across unseen languages and domains.
Significance. If the performance numbers and generalization results hold, the work is useful as a reproducible, low-resource baseline for code-generation detection. The explicit focus on stylometric ratios and parsing signals provides interpretability and efficiency advantages that are valuable in shared-task settings where heavy models may be impractical. The engineering choices directly target the task's cross-language and cross-domain constraints without introducing new theoretical machinery.
minor comments (3)
- [Abstract] Abstract: the claim of 'near-instant inference time' and 'computationally efficient' training would be strengthened by reporting concrete wall-clock times, model sizes, or FLOPs on the official test sets rather than qualitative statements.
- [Method] The description of how the heuristic rules were derived from data analysis and how they interact with the decision tree outputs lacks sufficient detail for exact reproduction; a pseudocode listing or explicit rule set would help.
- [Experiments] No ablation table isolating the contribution of the ratio-based features versus the parsing signals versus the line classifier is provided; adding one would clarify which components drive the claimed generalization.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance as a reproducible low-resource baseline, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The manuscript is a standard shared-task system description. It reports feature engineering (ratio-based stylometric signals, parsing-derived descriptiveness features, and a separate code-vs-text line classifier) followed by training a shallow decision tree plus data-derived heuristics. No equations, formal derivations, or predictions are presented that reduce by construction to fitted inputs or self-citations. The pipeline is explicitly empirical and trained on the SemEval task data; generalization is a task requirement rather than an internal assumption that collapses the argument. No load-bearing self-citation chains or ansatzes appear in the provided text.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design ratio-based features that are less sensitive to snippet length... combine a shallow decision tree with heuristic rules derived from data analysis to produce the final predictions.
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the decision tree classifier achieves a macro-averaged F1 score of 65.62... Decision Tree, depth = 2 + heuristic 67.35
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi:10.48550/arXiv.1409.0252 , eprint =
A Comparative Study of Programming Languages in Rosetta Code , url =. doi:10.48550/arXiv.1409.0252 , eprint =
-
[2]
Wang, Yue and Le, Hung and Gotmare, Akhilesh Deepak and Bui, Nghi D. Q. and Li, Junnan and Hoi, Steven C. H. , booktitle =. 2023 , pages =
2023
-
[3]
Clement and Dawn Drain and Neel Sundaresan and Jian Yin and Daxin Jiang and Ming Zhou , bibsource =
Daya Guo and Shuo Ren and Shuai Lu and Zhangyin Feng and Duyu Tang and Shujie Liu and Long Zhou and Nan Duan and Alexey Svyatkovskiy and Shengyu Fu and Michele Tufano and Shao Kun Deng and Colin B. Clement and Dawn Drain and Neel Sundaresan and Jian Yin and Daxin Jiang and Ming Zhou , bibsource =. GraphCodeBERT: Pre-training Code Representations with Data...
-
[4]
Twitch Chat Test Data , url =
-
[5]
StackOverflow Questions Filtered (2011--2021) , url =
2011
-
[6]
An Empirical Study to Evaluate
Wang, Jian and Liu, Shangqing and Xie, Xiaofei and Li, Yi , booktitle =. An Empirical Study to Evaluate. doi:10.1145/3691620.3695468 , pages =
-
[7]
Nature , number =
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , doi =. Nature , number =
-
[8]
Asleep at the Keyboard?
Pearce, Hammond and Ahmad, Baleegh and Tan, Benjamin and Dolan-Gavitt, Brendan and Karri, Ramesh , doi =. Asleep at the Keyboard?. Communications of the ACM , number =
-
[9]
Evaluating the Effectiveness of
Nunes, Henrique Gomes and Figueiredo, Eduardo and Rocha, Larissa and Nadi, Sarah and Ferreira, Fischer and Esteves dos Santos, Geanderson , journal =. Evaluating the Effectiveness of
-
[10]
Vaithilingam, Priyan and Zhang, Tianyi and Glassman, Elena L. , booktitle =. Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models , url =. doi:10.1145/3491101.3519665 , pages =
-
[11]
Issues in Detection of
Bukhari, Sufiyan Ahmed , school =. Issues in Detection of
-
[12]
Journal of Applied Learning & Teaching , number =
Sullivan, Miriam and Kelly, Andrew and McLaughlan, Paul , doi =. Journal of Applied Learning & Teaching , number =
-
[13]
Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks , url =
Veselovsky, Veniamin and Horta Ribeiro, Manoel and West, Robert , journal =. Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks , url =
-
[14]
Droid : A Resource Suite for AI -Generated Code Detection
Orel, Daniil and Paul, Indraneil and Gurevych, Iryna and Nakov, Preslav , booktitle =. doi:10.18653/v1/2025.emnlp-main.1593 , pages =
-
[15]
Orel, Daniil and Azizov, Dilshod and Nakov, Preslav , booktitle =
-
[16]
Orel, Daniil and Azizov, Dilshod and Paul, Indraneil and Wang, Yuxia and Gurevych, Iryna and Nakov, Preslav , booktitle =
-
[17]
Dunay, Omer and Cheng, Daniel and Tait, Adam and Thakkar, Parth and Rigby, Peter C. and Chiu, Andy and Ahmad, Imad and Ganesan, Arun and Maddila, Chandra and Murali, Vijayaraghavan and Tayyebi, Ali and Nagappan, Nachiappan , booktitle =. Multiline. doi:10.1145/3663529.3663836 , pages =
-
[18]
Resolving Code Review Comments with Machine Learning , url =
Froemmgen, Alexander and Austin, Jacob and Choy, Peter and Ghelani, Nimesh and Kharatyan, Lera and Surita, Gabriela and Khrapko, Elena and Lamblin, Pascal and Manzagol, Pierre-Antoine and Revaj, Marcus and Tabachnyk, Maxim and Tarlow, Daniel and Villela, Kevin and Zheng, Daniel and Chandra, Satish and Maniatis, Petros , booktitle =. Resolving Code Review ...
-
[19]
Automatic Detection of
Rahman, Musfiqur and Khatoonabadi, SayedHassan and Abdellatif, Ahmad and Shihab, Emad , journal =. Automatic Detection of
-
[20]
Efficient Training of Language Models to Fill in the Middle , url =
Bavarian, Mohammad and Jun, Heewoo and Tezak, Nikolas and Schulman, John and McLeavey, Christine and Tworek, Jerry and Chen, Mark , journal =. Efficient Training of Language Models to Fill in the Middle , url =
-
[21]
, journal =
Xu, Zhenyu and Sheng, Victor S. , journal =
-
[22]
Feng, Zhangyin and Guo, Daya and Tang, Duyu and Duan, Nan and Feng, Xiaocheng and Gong, Ming and Shou, Linjun and Qin, Bing and Liu, Ting and Jiang, Daxin and Zhou, Ming , booktitle =. doi:10.18653/v1/2020.findings-emnlp.139 , editor =
-
[23]
and Di Rocco, Juri and Di Sipio, Claudio and Rubei, Riccardo and Di Ruscio, Davide and Di Penta, Massimiliano , doi =
Nguyen, Phuong T. and Di Rocco, Juri and Di Sipio, Claudio and Rubei, Riccardo and Di Ruscio, Davide and Di Penta, Massimiliano , doi =. Journal of Systems and Software , pages =
-
[24]
Reassessing Code Authorship Attribution in the Era of Language Models , url =
Dipongkor, Atish Kumar and Yao, Ziyu and Moran, Kevin , journal =. Reassessing Code Authorship Attribution in the Era of Language Models , url =
-
[25]
Qwen2.5-1M Technical Report , url =
Yang, An and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Huang, Haoyan and Jiang, Jiandong and Tu, Jianhong and Zhang, Jianwei and Zhou, Jingren and Lin, Junyang and Dang, Kai and Yang, Kexin and Yu, Le and Li, Mei and Sun, Minmin and Zhu, Qin and Men, Rui and He, Tao and Xu, Weijia and Yin, Wenbiao and Yu, Wenyuan and Qiu, Xiafei and...
-
[26]
Can pre-trained code embeddings improve model performance? Revisiting the use of code embeddings in software engineering tasks , url =
Ding, Zishuo and Li, Heng and Shang, Weiyi and Chen, Tse-Hsun Peter , doi =. Can pre-trained code embeddings improve model performance? Revisiting the use of code embeddings in software engineering tasks , url =. Empirical Software Engineering , number =
-
[27]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , url =
Rudin, Cynthia , doi =. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , url =. Nature Machine Intelligence , pages =
-
[28]
TestGenEval: A Real World Unit Test Generation and Test Completion Benchmark , url =
Jain, Kush and Synnaeve, Gabriel and Roziere, Baptiste , booktitle =. TestGenEval: A Real World Unit Test Generation and Test Completion Benchmark , url =
-
[29]
Suresh, Tarun and Reddy, Revanth Gangi and Xu, Yifei and Nussbaum, Zach and Mulyar, Andriy and Duderstadt, Brandon and Ji, Heng , booktitle =
-
[30]
Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[31]
MAC : A Multi-Agent Framework for Interactive User Clarification in Multi-turn Conversations
Acikgoz, Emre Can and Oh, Jinoh and Jeon, Joo Hyuk and Hao, Jie and Ji, Heng and Hakkani-Tur, Dilek and Tur, Gokhan and Li, Xiang and Ma, Chengyuan and Fan, Xing. MAC : A Multi-Agent Framework for Interactive User Clarification in Multi-turn Conversations. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[32]
F low S witch: A State-Aware Framework for Workflow Transitions in Adaptive Dialogue Agents
Chang, Wen Yu and Qiu, Luning and Liu, Yi-Hung and Chen, Yun-Nung. F low S witch: A State-Aware Framework for Workflow Transitions in Adaptive Dialogue Agents. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[33]
Personality Expression in Spoken Dialogue Systems: From Text to Speech
Yamamoto, Kenta and Komatani, Kazunori. Personality Expression in Spoken Dialogue Systems: From Text to Speech. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[34]
Reproducing Proficiency-Conditioned Dialogue Features with Full-duplex Spoken Dialogue Models
Obi, Takao and Yoshikawa, Sadahiro and Saeki, Mao and Eguchi, Masaki and Matsuyama, Yoichi. Reproducing Proficiency-Conditioned Dialogue Features with Full-duplex Spoken Dialogue Models. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[35]
Automatic Evaluation of Open-Domain Real Conversations: Combining Encoder-Based, Dialogue-Based Features and Large Language Models Ratings
Conforto L \'o pez, Cristina and Estecha-Goritagoitia, Marcos and Rodriguez-Cantelar, Mario and Cordoba, Ricardo and D ' Haro, Luis Fernando. Automatic Evaluation of Open-Domain Real Conversations: Combining Encoder-Based, Dialogue-Based Features and Large Language Models Ratings. Proceedings of the 16th International Workshop on Spoken Dialogue System Te...
2026
-
[36]
Do audio and visual tokenizers capture backchannels?
Favre, Benoit and Boudin, Auriane. Do audio and visual tokenizers capture backchannels?. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[37]
The Context Trap: Why End-to-End Audio Language Models Fail Multi-turn Dialogues
Tam, Zhi Rui and Chang, Wen Yu and Chen, Yun-Nung. The Context Trap: Why End-to-End Audio Language Models Fail Multi-turn Dialogues. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[38]
Analysing Next Speaker Prediction in Multi-Party Conversation Using Multimodal Large Language Models
Mori, Taiga and Inoue, Koji and Lala, Divesh and Ochi, Keiko and Kawahara, Tatsuya. Analysing Next Speaker Prediction in Multi-Party Conversation Using Multimodal Large Language Models. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[39]
Exploring Emotional Nuances in Spoken Dialogue: Dataset Construction and Prediction of Emotional Dialogue Breakdown
Nakaguro, Hyuga and Yoshino, Koichiro. Exploring Emotional Nuances in Spoken Dialogue: Dataset Construction and Prediction of Emotional Dialogue Breakdown. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[40]
Effects of Dialogue Corpora Properties on Fine-Tuning a Moshi-Based Spoken Dialogue Model
Abe, Yuto and Saeki, Mao and Ohashi, Atsumoto and Takamichi, Shinnosuke and Fujie, Shiyna and Kobayashi, Tetsunori and Ogawa, Tetsuji and Higashinaka, Ryuichiro. Effects of Dialogue Corpora Properties on Fine-Tuning a Moshi-Based Spoken Dialogue Model. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[41]
Mixed-Initiative Dialogue Management for Human-Virtual Agents Interaction in Forum Theatre Inspired Training
Otofa, Samuel and Zerenini, Yacine and Bechet, Frederic and Favre, Benoit and Pergandi, Jean-Marie and Ochs, Magalie. Mixed-Initiative Dialogue Management for Human-Virtual Agents Interaction in Forum Theatre Inspired Training. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[42]
Analyzing Utterance Selection for Unnoticeable Topic Induction in Target-Guided Conversation Systems
Yoshida, Kai and Yoshino, Koichiro. Analyzing Utterance Selection for Unnoticeable Topic Induction in Target-Guided Conversation Systems. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[43]
Development of an Evaluation System for a Fan-Engagement Chat Application Using LLM -as-a-Judge
Fujita, Yuki and Sasaki, Yasunobu and Arashi, Ryota and Ototake, Hokuto and Takahashi, Shinya. Development of an Evaluation System for a Fan-Engagement Chat Application Using LLM -as-a-Judge. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[44]
A Dialogue Agent to Let Users Experience and Gently Enhance the ``Gyaru-Mind''
Ikegami, Momoka and Kato, Takuya and Aoyagi, Saizo and Hirai, Tatsunori. A Dialogue Agent to Let Users Experience and Gently Enhance the ``Gyaru-Mind''. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[45]
Towards a proactive cooking companion for the elderly
Esteve, Katarina and Fredriksson, Morgan and Gustafson, Joakim and Kontogiorgos, Dimosthenis and Mashiyi-Veikkola, Timo. Towards a proactive cooking companion for the elderly. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[46]
Conversational AI for Virtual Standardized Patients using a Speech-to-Speech LLM
Emerson, Andrew and Evanini, Keelan and Somay, Su and Frome, Kevin and Ha, Le An and Harik, Polina. Conversational AI for Virtual Standardized Patients using a Speech-to-Speech LLM. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[47]
Can Small-Scale LLM s Balance Content Accuracy and Speaker Faithfulness in Noisy F rench Dialogue Summarization?
Abrougui, Rim and Lechien, Guillaume and Savatier, Elisabeth and Laurent, Beno \^i t. Can Small-Scale LLM s Balance Content Accuracy and Speaker Faithfulness in Noisy F rench Dialogue Summarization?. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[48]
ORCHESTRA : AI -Driven Microservices Architecture to Create Personalized Experiences
Bellver, Jaime and Ramos-Varela, Samuel and Guragain, Anmol and C \'o rdoba, Ricardo and D ' Haro, Luis Fernando. ORCHESTRA : AI -Driven Microservices Architecture to Create Personalized Experiences. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[49]
Benchmarking Multilingual Temporal Reasoning in LLM s: The Temporal Reasoning Dataset
Mazzia, Vittorio and Pollastrini, Sandro and Bernardi, Davide and Rubagotti, Chiara and Amberti, Daniele. Benchmarking Multilingual Temporal Reasoning in LLM s: The Temporal Reasoning Dataset. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[50]
Retrospective Speech Recognition for Spoken Dialogue System: Exploiting Subsequent Utterances to Enhance ASR Performance
Takeda, Ryu and Komatani, Kazunori. Retrospective Speech Recognition for Spoken Dialogue System: Exploiting Subsequent Utterances to Enhance ASR Performance. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[51]
From Fact to Judgment: Investigating the Impact of Task Framing on LLM Conviction in Dialogue Systems
Rabbani, Parisa and Bozdag, Nimet Beyza and Hakkani-Tur, Dilek. From Fact to Judgment: Investigating the Impact of Task Framing on LLM Conviction in Dialogue Systems. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[52]
Minimal Clips, Maximum Salience: Long Video Summarization via Key Moment Extraction
Pennec, Galann and Liu, Zhengyuan and Asher, Nicholas and Muller, Philippe and Chen, Nancy. Minimal Clips, Maximum Salience: Long Video Summarization via Key Moment Extraction. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[53]
Multilingual and Continuous Backchannel Prediction: A Cross-lingual Study
Inoue, Koji and Elmers, Mikey and Fu, Yahui and Pang, Zi Haur and Mori, Taiga and Lala, Divesh and Ochi, Keiko and Kawahara, Tatsuya. Multilingual and Continuous Backchannel Prediction: A Cross-lingual Study. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[54]
Vanishing point of attention: A platform for adaptive driver dialogue experiments
Fredriksson, Morgan and Yaici, Yanis and Lam, Kevin and Konigsmann, Jurgen and Edlund, Jens. Vanishing point of attention: A platform for adaptive driver dialogue experiments. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[55]
When social robots see our sketches: evaluating human perception of a robot and a VLM model performance in a drawing task
Daniilidou, Viktoria Paraskevi and Ilinykh, Nikolai and Maraev, Vladislav. When social robots see our sketches: evaluating human perception of a robot and a VLM model performance in a drawing task. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[56]
Adding Determinism to a Dialogue Agent for a Robotic Environment
Garcia Anakabe, Oihana and Cocola, Riccardo and Aceta, Cristina. Adding Determinism to a Dialogue Agent for a Robotic Environment. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[57]
Context-Aware Language Understanding in Human-Robot Dialogue with LLM s
Stoyanchev, Svetlana and Farag, Youmna and Keizer, Simon and Li, Mohan and Doddipatla, Rama Sanand. Context-Aware Language Understanding in Human-Robot Dialogue with LLM s. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[58]
Learning Vision-Language Alignment in Unified LLM s with 24 Text Tokens per Image
Irmiger, Nicola and Xu, Yixuan and Kreft, Raphael and Davtyan, Aram and Kaufmann, Manuel and Schlag, Imanol. Learning Vision-Language Alignment in Unified LLM s with 24 Text Tokens per Image. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[59]
Incorporating Respect into LLM -Based Academic Feedback: A BI - R Framework for Instructing Students after Q & A Sessions
Aiba, Mayuko and Saito, Daisuke and Minematsu, Nobuaki. Incorporating Respect into LLM -Based Academic Feedback: A BI - R Framework for Instructing Students after Q & A Sessions. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[60]
The Complementary Role of Para-linguistic cues for Robust Pronunciation Assessment
El Kheir, Yassine and Chowdhury, Shammur Absar and Ali, Ahmed. The Complementary Role of Para-linguistic cues for Robust Pronunciation Assessment. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[61]
Evaluating LLM Style Transfer Through Readability-Based Age Assessments
Di Maro, Maria and Origlia, Antonio and Bilo, Leonilda and Meo, Roberta and Maturi, Pietro and Nappo, Francesca. Evaluating LLM Style Transfer Through Readability-Based Age Assessments. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[62]
S peak RL : Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning
Acikgoz, Emre Can and Oh, Jinoh and Hao, Jie and Jeon, Joo Hyuk and Ji, Heng and Hakkani-Tur, Dilek and Tur, Gokhan and Li, Xiang and Ma, Chengyuan and Fan, Xing. S peak RL : Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[63]
Adaptive Multimodal Sentiment Analysis with Stream-Based Active Learning for Spoken Dialogue Systems
Ajichi, Atsuto and Hayashi, Takato and Komatani, Kazunori and Okada, Shogo. Adaptive Multimodal Sentiment Analysis with Stream-Based Active Learning for Spoken Dialogue Systems. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[64]
Predicting Turn-Taking in Child -- Adult Conversations Using Voice Activity Projection
Brahimi, Youcef and Blanc, C \'e sar and Fourtassi, Abdellah. Predicting Turn-Taking in Child -- Adult Conversations Using Voice Activity Projection. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[65]
Supporting human operators during customer service interactions with agentic- RAG
Barrionuevo-Valenzuela, Juan and Calder \'o n-Gonz \'a lez, Daniel and Callejas, Zoraida and Griol, David. Supporting human operators during customer service interactions with agentic- RAG. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[66]
Analysis of Child-Caregiver Interactions for Developing a Caregiver Spoken Dialogue System
Yamashita, Sanae and Mochizuki, Shota and Kuma, Yuko and Sakai, Ray and Sasaki, Ayaka and Higashinaka, Ryuichiro. Analysis of Child-Caregiver Interactions for Developing a Caregiver Spoken Dialogue System. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[67]
Can code-switching improve the user experience with a dialogue system app for recording endangered languages?
Brixey, Jacqueline and Traum, David. Can code-switching improve the user experience with a dialogue system app for recording endangered languages?. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[68]
Estimating Relationships between Participants in Multi-Party Chat Corpus
Fukushige, Akane and Inoue, Koji and Ochi, Keiko and Kawahara, Tatsuya and Yamashita, Sanae and Higashinaka, Ryuichiro. Estimating Relationships between Participants in Multi-Party Chat Corpus. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[69]
WER is Unaware: Assessing How ASR Errors Distort Clinical Understanding in Patient Facing Dialogue
Ellis, Zachary and Joselowitz, Jared and Deo, Yash and He, Yajie Vera and Kalygina, Anna and Higham, Aisling and Rahimzadeh, Mana and Jia, Yan and Habli, Ibrahim and Lim, Ernest. WER is Unaware: Assessing How ASR Errors Distort Clinical Understanding in Patient Facing Dialogue. Proceedings of the 16th International Workshop on Spoken Dialogue System Techn...
2026
-
[70]
and Giorgini, Paolo
Fumi, Lorenzo and Bombieri, Marco and Allievi, Sara and Bonvini, Stefano and Chaspari, Theodora and Zenati, Marco A. and Giorgini, Paolo. R eflect OR : an LLM -based Agent for Post-Operative Surgical Debriefing. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[71]
Detecting Mental Manipulation in Speech via Synthetic Multi-Speaker Dialogue
Chen, Run and Liang, Wen and Gong, Ziwei and Ai, Lin and Hirschberg, Julia. Detecting Mental Manipulation in Speech via Synthetic Multi-Speaker Dialogue. Proceedings of the 16th International Workshop on Spoken Dialogue System Technology. 2026
2026
-
[72]
C o V a P h: A Vision-Language Multi-Agent Dialogue System for Tool-Augmented Pharmacogenetic Reasoning and Personalized Guidance
Lu, Shang-Chun Luke and Yang, Hsin and Xue, Hui-Hsin and Tsai, Ping Lin and Weng, Yu Jing and Li, Shiou-Chi and Huang, Jen-Wei and Chang, Hui Hua. C o V a P h: A Vision-Language Multi-Agent Dialogue System for Tool-Augmented Pharmacogenetic Reasoning and Personalized Guidance. Proceedings of the 16th International Workshop on Spoken Dialogue System Techno...
2026
-
[73]
Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[74]
Research on LLM s-Empowered Conversational AI for Sustainable Behaviour Change
Chen, Ben. Research on LLM s-Empowered Conversational AI for Sustainable Behaviour Change. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[75]
Deep Reinforcement Learning of LLM s​ using RLHF
Levandovsky, Enoch. Deep Reinforcement Learning of LLM s​ using RLHF. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[76]
Conversational Collaborative Robots
Kranti, Chalamalasetti. Conversational Collaborative Robots. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[77]
Dialogue System using Large Language Model-based Dynamic Slot Generation
Hashimoto, Ekai. Dialogue System using Large Language Model-based Dynamic Slot Generation. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[78]
Towards Adaptive Human-Agent Collaboration in Real-Time Environments
Nakae, Kaito. Towards Adaptive Human-Agent Collaboration in Real-Time Environments. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[79]
Towards Human-Like Dialogue Systems: Integrating Multimodal Emotion Recognition and Non-Verbal Cue Generation
Jiang, Jingjing. Towards Human-Like Dialogue Systems: Integrating Multimodal Emotion Recognition and Non-Verbal Cue Generation. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
-
[80]
Controlling Dialogue Systems with Graph-Based Structures
Hilgendorf, Laetitia Mina. Controlling Dialogue Systems with Graph-Based Structures. Proceedings of the 21st Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.