Recognition: unknown
Pro²Assist: Continuous Step-Aware Proactive Assistance with Multimodal Egocentric Perception for Long-Horizon Procedural Tasks
Pith reviewed 2026-05-08 17:11 UTC · model grok-4.3
The pith
Pro²Assist uses continuous multimodal reasoning from AR glasses to deliver timely proactive assistance throughout long-horizon procedural tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
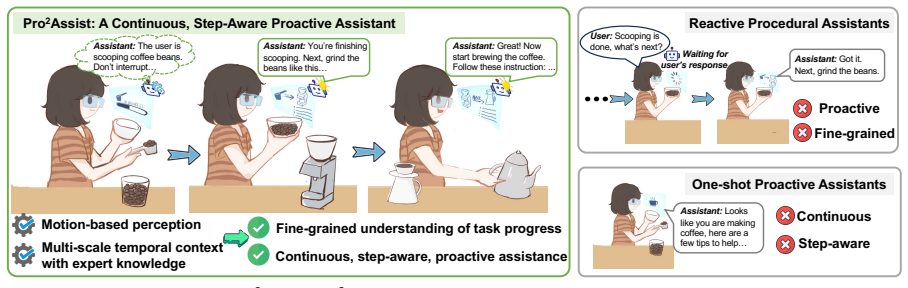
Pro²Assist is a step-aware proactive assistant that continuously tracks fine-grained task progress and reasons over the user's evolving state to provide timely assistance throughout tasks. It leverages multimodal data from augmented reality glasses for motion-based perception, extracts step-oriented procedural context from multi-scale temporal dynamics and task-specific expert knowledge, and performs continuous reasoning to infer user needs and display timely assistance on the glasses themselves.
What carries the argument
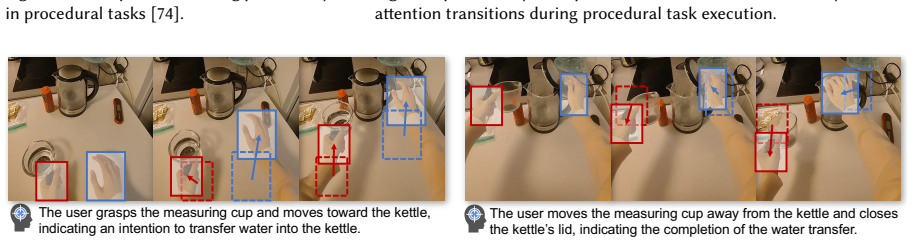
The continuous reasoning process that fuses motion-based egocentric perception from AR glasses with step-oriented procedural context drawn from multi-scale temporal dynamics and task-specific expert knowledge.
If this is right
- The system outperforms the strongest prior baselines by more than 21 percent in procedural action understanding accuracy.
- It reaches up to 2.29 times the proactive timing accuracy of existing methods.
- A user study with 20 participants indicates that 90 percent find the assistance useful in practice.
- The approach supports continuous help across entire long-horizon sequences rather than isolated short events.
Where Pith is reading between the lines
- The same continuous-reasoning pattern could be adapted to non-glasses wearables if equivalent motion and context streams are available.
- Extending the context extraction step to new task domains would require only updated expert knowledge rather than retraining the entire perception pipeline.
- If timing accuracy gains hold, the method could reduce user errors in safety-critical procedures by surfacing reminders before mistakes occur.
Load-bearing premise
Multimodal data from AR glasses together with extracted step-oriented procedural context can reliably and continuously infer the user's evolving state and needs across diverse real-world long-horizon tasks.
What would settle it
A side-by-side trial in which participants complete varied long procedural tasks while wearing the glasses, with independent observers measuring whether the system's assistance appears at moments that actually match the user's demonstrated needs and whether action-understanding accuracy exceeds the best baseline by the reported margin.
Figures




















read the original abstract
Procedural tasks with multiple ordered steps are ubiquitous in daily life. Recent advances in multimodal large language models (MLLMs) have enabled personal assistants that support daily activities. However, existing systems primarily provide reactive guidance triggered by user queries, or limited proactive assistance for isolated short-term events rather than long-horizon procedural tasks. In this work, we introduce Pro$^2$Assist, a step-aware proactive assistant that continuously tracks fine-grained task progress and reasons over the user's evolving state to provide timely assistance throughout tasks. Pro$^2$Assist leverages multimodal data from augmented reality (AR) glasses to achieve motion-based perception. It then extracts step-oriented procedural context from multi-scale temporal dynamics and task-specific expert knowledge. Based on both sensory input and procedural context, Pro$^2$Assist performs continuous reasoning to infer user needs and display timely assistance on AR glasses. We evaluate Pro$^2$Assist using a dataset curated from public sources and a real-world dataset collected on our testbed with AR glasses. Extensive evaluations show that Pro$^2$Assist outperforms the best-performing baselines by over 21% in procedural action understanding accuracy, and it achieves up to 2.29x the proactive timing accuracy of baselines. A user study with 20 participants further shows that 90% find Pro$^2$Assist useful, indicating its effectiveness for real-world procedural assistance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Pro²Assist, a system for continuous step-aware proactive assistance in long-horizon procedural tasks. It uses multimodal egocentric perception from AR glasses for motion-based tracking of user actions and progress. The core pipeline extracts step-oriented procedural context from multi-scale temporal dynamics combined with task-specific expert knowledge, then performs continuous reasoning over sensory input and this context to infer evolving user needs and deliver timely assistance displayed on the AR glasses. Evaluations on a dataset curated from public sources plus a real-world testbed dataset show Pro²Assist outperforming best baselines by over 21% in procedural action understanding accuracy and up to 2.29× in proactive timing accuracy; a user study with 20 participants reports 90% finding the system useful.
Significance. If the central claims hold under more rigorous generality testing, the work would be significant for advancing proactive multimodal AI assistants beyond reactive or short-horizon systems, particularly through the integration of AR-based egocentric perception with procedural reasoning. Credit is due for the real-world data collection on an AR testbed, the quantitative gains over baselines, and the inclusion of a user study providing practical validation. The approach addresses a relevant gap in continuous assistance for everyday procedural activities.
major comments (3)
- [§3.2] §3.2 (Procedural Context Extraction): The extraction of step-oriented procedural context explicitly incorporates 'task-specific expert knowledge' alongside multi-scale temporal dynamics. No ablation study isolates the contribution of this expert-knowledge component, nor is there evidence (e.g., zero-shot transfer results or description of how the knowledge is obtained) that it generalizes beyond the evaluated task families. This is load-bearing for the headline claims of reliable continuous inference of user state across diverse long-horizon procedures.
- [§4.1] §4.1 (Datasets and Evaluation Setup): The real-world testbed dataset is described only at high level ('curated from public sources and real-world testbed'). Missing are concrete details on the number of distinct long-horizon tasks, total procedure instances, diversity metrics, and exactly how task-specific expert knowledge was supplied or tuned for each task. Without these, the reported 21% action-understanding and 2.29× timing gains cannot be assessed for robustness outside the training distribution.
- [§4.3] §4.3 (User Study): The claim that 90% of 20 participants found Pro²Assist useful is presented without statistical analysis, task breakdown, or comparison of subjective metrics against the same baselines used in the quantitative experiments. This weakens the supporting evidence for real-world effectiveness.
minor comments (2)
- [Abstract] The term 'proactive timing accuracy' is used in the abstract and results but is not formally defined until later; an early definition or equation would improve readability.
- [Figures] Figure captions for the system overview and qualitative examples could include more detail on what each panel illustrates (e.g., specific steps or failure modes of baselines).
Simulated Author's Rebuttal
Thank you for the detailed and constructive feedback on our manuscript. We appreciate the referee's recognition of the significance of our work on proactive assistance for long-horizon tasks. Below, we provide point-by-point responses to the major comments and indicate the revisions we will make to address them.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Procedural Context Extraction): The extraction of step-oriented procedural context explicitly incorporates 'task-specific expert knowledge' alongside multi-scale temporal dynamics. No ablation study isolates the contribution of this expert-knowledge component, nor is there evidence (e.g., zero-shot transfer results or description of how the knowledge is obtained) that it generalizes beyond the evaluated task families. This is load-bearing for the headline claims of reliable continuous inference of user state across diverse long-horizon procedures.
Authors: We agree that isolating the contribution of the task-specific expert knowledge is important for validating its role in the system. In the revised manuscript, we will include an ablation study that compares the full Pro²Assist pipeline against a variant without the expert knowledge component, reporting the resulting drops in action understanding and timing accuracy. Additionally, we will provide a detailed description of how the expert knowledge is obtained—specifically, by structuring standard procedural instructions from task documentation into a step-oriented format—and demonstrate its application across the evaluated task families. While we do not claim zero-shot generalization to entirely novel task domains outside our testbed, we will include results on held-out procedures within the same families to support the generalization claims within the scope of our evaluation. revision: yes
-
Referee: [§4.1] §4.1 (Datasets and Evaluation Setup): The real-world testbed dataset is described only at high level ('curated from public sources and real-world testbed'). Missing are concrete details on the number of distinct long-horizon tasks, total procedure instances, diversity metrics, and exactly how task-specific expert knowledge was supplied or tuned for each task. Without these, the reported 21% action-understanding and 2.29× timing gains cannot be assessed for robustness outside the training distribution.
Authors: We acknowledge that more granular dataset statistics are necessary for assessing the robustness of our results. In the revised version, we will expand Section 4.1 to include: the exact number of distinct long-horizon tasks (broken down by category, e.g., cooking, assembly, maintenance), the total number of procedure instances, diversity metrics such as average number of steps per task and variance in task duration, and a precise description of how task-specific expert knowledge was supplied (via manual structuring of public task manuals into our procedural context format) and tuned (using a consistent template across tasks with task-specific step names and dependencies). This will allow readers to better evaluate the generalizability of the reported performance gains. revision: yes
-
Referee: [§4.3] §4.3 (User Study): The claim that 90% of 20 participants found Pro²Assist useful is presented without statistical analysis, task breakdown, or comparison of subjective metrics against the same baselines used in the quantitative experiments. This weakens the supporting evidence for real-world effectiveness.
Authors: We agree that additional analysis would strengthen the user study section. In the revision, we will add statistical analysis to the 90% usefulness finding, such as confidence intervals or binomial tests for significance. We will also provide a task breakdown showing usefulness ratings per task category and include comparisons of subjective metrics (e.g., perceived timeliness and helpfulness) against the baseline systems from the quantitative experiments. These additions will be based on the existing participant responses and will be presented in a new table or figure. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation
full rationale
The paper presents a system architecture for proactive assistance using AR glasses, multimodal perception, and procedural context extraction, then reports performance gains via comparisons to baselines on public and real-world datasets plus a user study. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that reduce any central claim to its own inputs by construction. The evaluation methodology is described as independent of the system outputs being measured.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude-Sonnet-4.5
2025. Claude-Sonnet-4.5. https://www.anthropic.com/claude/sonnet
2025
-
[2]
2025. Ollama. https://ollama.com/
2025
-
[3]
RayNeo X3 Pro
2025. RayNeo X3 Pro. https://rayneo.cn/x3pro.html
2025
-
[4]
Google Gemini
2026. Google Gemini. https://gemini.google.com/
2026
-
[5]
Magic Leap 2 Devices
2026. Magic Leap 2 Devices. https://www.magicleap.com/legal/devices-ml2
2026
-
[6]
Meta Orion
2026. Meta Orion. https://www.meta.com/emerging-tech/orion/
2026
-
[7]
SentenceTransformers Documentation
2026. SentenceTransformers Documentation. https://www.sbert.net/
2026
- [8]
-
[9]
Peri Akiva, Jing Huang, Kevin J Liang, Rama Kovvuri, Xingyu Chen, Matt Feiszli, Kristin Dana, and Tal Hassner. 2023. Self-supervised object detection from egocentric videos. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5225–5237
2023
-
[10]
Riku Arakawa, Jill Fain Lehman, and Mayank Goel. 2024. Prism-q&a: Step-aware voice assistant on a smartwatch enabled by multimodal procedure tracking and large language models.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 4 (2024), 1–26
2024
-
[11]
Riku Arakawa, Prasoon Patidar, Will Page, Jill Lehman, and Mayank Goel. 2025. Scaling Context-Aware Task Assistants that Learn from Demonstration and Adapt through Mixed-Initiative Dialogue. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–19
2025
-
[12]
Riku Arakawa, Hiromu Yakura, and Mayank Goel. 2024. PrISM-Observer: Intervention agent to help users perform everyday procedures sensed using a smartwatch. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–16
2024
-
[13]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review arXiv 2025
-
[14]
Andrea Bandini and José Zariffa. 2020. Analysis of the hands in egocentric vision: A survey.IEEE transactions on pattern analysis and machine intelligence45, 6 (2020), 6846–6866
2020
-
[15]
Siddhant Bansal, Chetan Arora, and C.V. Jawahar. 2022. My View is the Best View: Procedure Learning from Egocentric Videos. In European Conference on Computer Vision (ECCV)
2022
-
[16]
Yuwei Bao, Keunwoo Yu, Yichi Zhang, Shane Storks, Itamar Bar-Yossef, Alex de la Iglesia, Megan Su, Xiao Zheng, and Joyce Chai
-
[17]
InFindings of the Association for Computational 24 Linguistics: EMNLP 2023
Can foundation models watch, talk and guide you step by step to make a cake?. InFindings of the Association for Computational 24 Linguistics: EMNLP 2023. 12325–12341
2023
-
[18]
Justin Chan, Solomon Nsumba, Mitchell Wortsman, Achal Dave, Ludwig Schmidt, Shyamnath Gollakota, and Kelly Michaelsen. 2024. Detecting clinical medication errors with AI enabled wearable cameras.NPJ Digital Medicine7, 1 (2024), 287
2024
-
[19]
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, et al. 2021. Dexycb: A benchmark for capturing hand grasping of objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9044–9053
2021
-
[20]
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun
-
[21]
InForty-first International Conference on Machine Learning
Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. InForty-first International Conference on Machine Learning
-
[22]
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. 2024. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18407–18418
2024
-
[23]
Tuochao Chen, Nicholas Scott Batchelder, Alisa Liu, Noah A Smith, and Shyamnath Gollakota. 2025. LLAMAPIE: Proactive In-Ear Conversation Assistants. InFindings of the Association for Computational Linguistics: ACL 2025. 13801–13824
2025
-
[24]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al
-
[25]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24185–24198
-
[26]
Sijie Cheng, Zhicheng Guo, Jingwen Wu, Kechen Fang, Peng Li, Huaping Liu, and Yang Liu. 2024. Egothink: Evaluating first-person perspective thinking capability of vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14291–14302
2024
-
[27]
Dongwook Choi, Taeyoon Kwon, Dongil Yang, Hyojun Kim, and Jinyoung Yeo. 2025. Designing Memory-Augmented AR Agents for Spatiotemporal Reasoning in Personalized Task Assistance. In2025 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct). IEEE, 113–119
2025
-
[28]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. 2024. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing. 1107–1128
2024
-
[29]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. 2022. A survey on in-context learning.arXiv preprint arXiv:2301.00234(2022)
work page internal anchor Pith review arXiv 2022
-
[30]
Anup Doshi and Mohan Manubhai Trivedi. 2009. On the roles of eye gaze and head dynamics in predicting driver’s intent to change lanes.IEEE Transactions on Intelligent Transportation Systems10, 3 (2009), 453–462
2009
-
[31]
Anup Doshi and Mohan M Trivedi. 2012. Head and eye gaze dynamics during visual attention shifts in complex environments.Journal of vision12, 2 (2012), 9–9
2012
-
[32]
Pardis Emami-Naeini, Janarth Dheenadhayalan, Yuvraj Agarwal, and Lorrie Faith Cranor. 2021. Which privacy and security attributes most impact consumers’ risk perception and willingness to purchase IoT devices?. In2021 IEEE Symposium on Security and Privacy (SP). IEEE, 519–536
2021
-
[33]
Jakob Engel, Kiran Somasundaram, Michael Goesele, Albert Sun, Alexander Gamino, Andrew Turner, Arjang Talattof, Arnie Yuan, Bilal Souti, Brighid Meredith, et al. 2023. Project aria: A new tool for egocentric multi-modal ai research.arXiv preprint arXiv:2308.13561 (2023)
work page internal anchor Pith review arXiv 2023
-
[34]
Alireza Fathi, Xiaofeng Ren, and James M Rehg. 2011. Learning to recognize objects in egocentric activities. InCVPR 2011. IEEE, 3281–3288
2011
-
[35]
Alessandro Flaborea, Guido Maria D’Amely Di Melendugno, Leonardo Plini, Luca Scofano, Edoardo De Matteis, Antonino Furnari, Giovanni Maria Farinella, and Fabio Galasso. 2024. Prego: online mistake detection in procedural egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18483–18492
2024
-
[36]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al
-
[37]
A survey on llm-as-a-judge.The Innovation(2024)
2024
-
[38]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al . 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[39]
Lin Huang, Boshen Zhang, Zhilin Guo, Yang Xiao, Zhiguo Cao, and Junsong Yuan. 2021. Survey on depth and RGB image-based 3D hand shape and pose estimation.Virtual Reality & Intelligent Hardware3, 3 (2021), 207–234
2021
-
[40]
Yifei Huang, Jilan Xu, Baoqi Pei, Lijin Yang, Mingfang Zhang, Yuping He, Guo Chen, Xinyuan Chen, Yaohui Wang, Zheng Nie, et al
-
[41]
Vinci: A real-time smart assistant based on egocentric vision-language model for portable devices.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–33
2025
-
[42]
Youngkyoon Jang, Brian Sullivan, Casimir Ludwig, Iain Gilchrist, Dima Damen, and Walterio Mayol-Cuevas. 2019. EPIC-Tent: An Egocentric Video Dataset for Camping Tent Assembly. InInternational Conference on Computer Vision (ICCV) Workshops
2019
-
[43]
2024.Ultralytics YOLO11
Glenn Jocher and Jing Qiu. 2024.Ultralytics YOLO11. https://github.com/ultralytics/ultralytics 25
2024
- [44]
-
[45]
Anna Kukleva, Fadime Sener, Edoardo Remelli, Bugra Tekin, Eric Sauser, Bernt Schiele, and Shugao Ma. 2024. X-mic: Cross-modal instance conditioning for egocentric action generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26364–26373
2024
-
[46]
Shih-Po Lee, Zijia Lu, Zekun Zhang, Minh Hoai, and Ehsan Elhamifar. 2024. Error detection in egocentric procedural task videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18655–18666
2024
-
[47]
Chenyi Li, Guande Wu, Gromit Yeuk-Yin Chan, Dishita Gdi Turakhia, Sonia Castelo Quispe, Dong Li, Leslie Welch, Claudio Silva, and Jing Qian. 2025. Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–24
2025
-
[48]
Yuanqi Li, Arthi Padmanabhan, Pengzhan Zhao, Yufei Wang, Guoqing Harry Xu, and Ravi Netravali. 2020. Reducto: On-camera filtering for resource-efficient real-time video analytics. InProceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer commu...
2020
-
[49]
Yin Li, Zhefan Ye, and James M Rehg. 2015. Delving into egocentric actions. InProceedings of the IEEE conference on computer vision and pattern recognition. 287–295
2015
-
[50]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. 2015. Microsoft COCO: Common Objects in Context. arXiv:1405.0312 [cs.CV] https://arxiv.org/abs/1405.0312
work page internal anchor Pith review arXiv 2015
- [51]
- [52]
-
[53]
Rachel McCloud, Carly Perez, Mesfin Awoke Bekalu, and K Viswanath. 2022. Using smart speaker technology for health and well-being in an older adult population: pre-post feasibility study.JMIR aging5, 2 (2022), e33498
2022
-
[54]
Microsoft. 2026. Microsoft Azure Speech. https://azure.microsoft.com/en-us/products/ai-foundry/tools/speech Accessed: 2026-01-21
2026
-
[55]
Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. 2020. End-to-end learning of visual representations from uncurated instructional videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9879–9889
2020
-
[56]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al . 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[57]
Kevin Pu, Ting Zhang, Naveen Sendhilnathan, Sebastian Freitag, Raj Sodhi, and Tanya R Jonker. 2025. ProMemAssist: Exploring Timely Proactive Assistance Through Working Memory Modeling in Multi-Modal Wearable Devices. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–19
2025
-
[58]
A Raouf and S Arora. 1980. Effect of informational load, index of difficulty direction and plane angles of discrete moves in a combined manual and decision task.International Journal of Production Research18, 1 (1980), 117–128
1980
-
[59]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. 2022. LAION-5B: An open large-scale dataset for training next generation image-text m...
work page internal anchor Pith review arXiv 2022
-
[60]
Yuhan Shen, Lu Wang, and Ehsan Elhamifar. 2021. Learning to segment actions from visual and language instructions via differentiable weak sequence alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10156–10165
2021
-
[61]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. 2025. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Arthur Tang, Charles Owen, Frank Biocca, and Weimin Mou. 2003. Comparative effectiveness of augmented reality in object assembly. InProceedings of the SIGCHI conference on Human factors in computing systems. 73–80
2003
-
[63]
Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision. Springer, 402–419
2020
- [64]
- [65]
-
[66]
Ruiqi Wang, Peiqi Gao, Patrick Lynch, Tingjun Liu, Yejin Lee, Carolyn Baum, Lisa Tabor Connor, and Chenyang Lu. 2025. CHEF-VL: Detecting Cognitive Sequencing Errors in Cooking with Vision-language Models.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 4 (2025), 1–35. 26
2025
-
[67]
Tiannan Wang, Wangchunshu Zhou, Yan Zeng, and Xinsong Zhang. 2023. Efficientvlm: Fast and accurate vision-language models via knowledge distillation and modal-adaptive pruning. InFindings of the association for computational linguistics: ACL 2023. 13899–13913
2023
- [68]
- [69]
-
[70]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[71]
Ethan Wilson, Naveen Sendhilnathan, Charlie S Burlingham, Yusuf Mansour, Robert Cavin, Sai Deep Tetali, Ajoy Savio Fernandes, and Michael J Proulx. 2025. Eye gaze as a signal for conveying user attention in contextual AI systems. InProceedings of the 2025 symposium on eye tracking research and applications. 1–7
2025
-
[72]
Jay Zhangjie Wu, David Junhao Zhang, Wynne Hsu, Mengmi Zhang, and Mike Zheng Shou. 2023. Label-efficient online continual object detection in streaming video. InProceedings of the IEEE/CVF International Conference on Computer Vision. 19246–19255
2023
-
[73]
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, and Mike Zheng Shou
-
[74]
Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation.Advances in Neural Information Processing Systems37 (2024), 109922–109947
2024
-
[75]
Zhenyu Xu, Hailin Xu, Zhouyang Lu, Yingying Zhao, Rui Zhu, Yujiang Wang, Mingzhi Dong, Yuhu Chang, Qin Lv, Robert P Dick, et al. 2024. Can large language models be good companions? An LLM-based eyewear system with conversational common ground. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 2 (2024), 1–41
2024
-
[76]
Jiaqi Yan, Ruilong Ren, Jingren Liu, Shuning Xu, Ling Wang, Yiheng Wang, Xinlin Zhong, Yun Wang, Long Zhang, Xiangyu Chen, et al
- [77]
-
[78]
Bufang Yang, Yunqi Guo, Lilin Xu, Zhenyu Yan, Hongkai Chen, Guoliang Xing, and Xiaofan Jiang. 2025. Socialmind: Llm-based proactive ar social assistive system with human-like perception for in-situ live interactions.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 1 (2025), 1–30
2025
-
[79]
Bufang Yang, Lixing He, Neiwen Ling, Zhenyu Yan, Guoliang Xing, Xian Shuai, Xiaozhe Ren, and Xin Jiang. 2023. Edgefm: Leveraging foundation model for open-set learning on the edge. InProceedings of the 21st ACM Conference on Embedded Networked Sensor Systems. 111–124
2023
-
[80]
Bufang Yang, Lixing He, Kaiwei Liu, and Zhenyu Yan. 2024. Viassist: Adapting multi-modal large language models for users with visual impairments. In2024 IEEE International Workshop on Foundation Models for Cyber-Physical Systems & Internet of Things (FMSys). IEEE, 32–37
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.