Disentangled Learning Improves Implicit Neural Representations for Medical Reconstruction
Pith reviewed 2026-05-08 17:28 UTC · model grok-4.3
The pith
DisINR disentangles shared population priors from subject-specific details in INRs to enable pre-training on raw measurements and efficient medical image reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DisINR introduces a shared encoder-decoder pair and subject-specific encoders whose features are jointly decoded for image reconstruction; the shared modules are pre-trained directly from limited raw measurements using differentiable forward models, and during test-time adaptation only the subject-specific encoder is optimized while the shared pair remains frozen, thereby preserving population priors and avoiding catastrophic forgetting.
What carries the argument
Shared encoder-decoder pair pre-trained via differentiable forward models on raw data, combined with subject-specific encoders for joint feature decoding during reconstruction.
Load-bearing premise
Pre-training the shared encoder-decoder directly from raw measurements captures population priors that stay useful and stable once the modules are frozen during subject-specific fine-tuning.
What would settle it
An experiment on a medical imaging dataset in which jointly optimizing the shared modules during adaptation produces higher reconstruction accuracy than freezing them after pre-training would falsify the claimed benefit of the disentanglement.
Figures










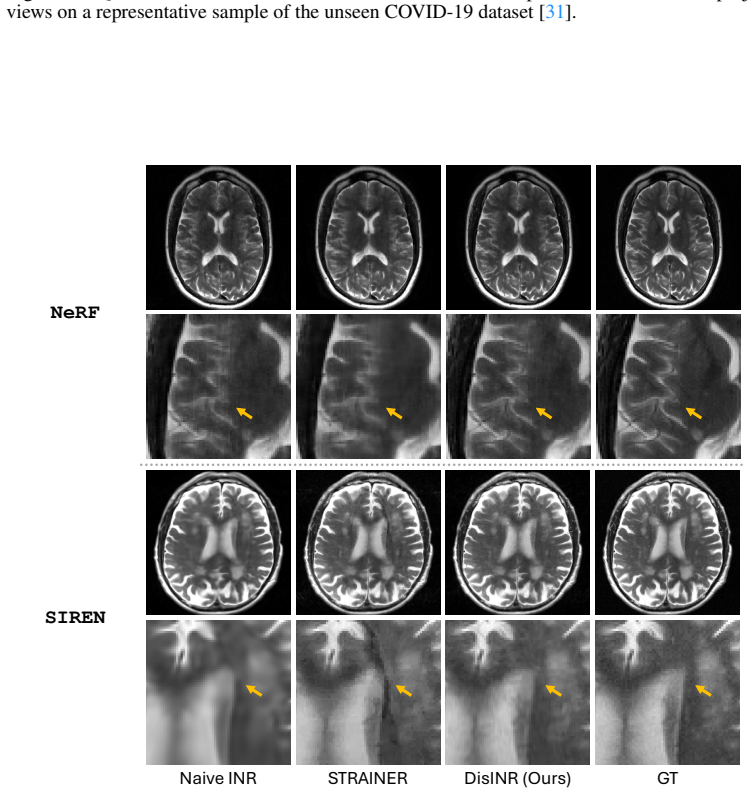


read the original abstract
Implicit neural representations (INRs) have emerged as a powerful paradigm for medical imaging via physics-informed unsupervised learning. Classical INRs optimize an entire network from scratch for each subject, leading to inefficient training and suboptimal imaging quality. Recent initialization-based approaches attempt to inject population priors into pre-trained networks, yet they rely on high-quality images and often suffer from catastrophic forgetting during fine-tuning. We present DisINR, a novel INR framework that explicitly disentangles shared and subject-specific representations. DisINR introduces a shared encoder-decoder pair and subject-specific encoders, whose features are jointly decoded for image reconstruction. By integrating differentiable forward models, it pre-trains the shared modules directly from limited raw measurements, removing the need for pre-acquired high-quality images. During test-time adaptation, only the subject-specific encoder is optimized, while the shared pair remains frozen, effectively preserving learned priors. Extensive evaluations on three representative medical imaging tasks show that DisINR significantly outperforms state-of-the-art INRs in both reconstruction accuracy and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DisINR, a disentangled implicit neural representation framework for medical imaging. It consists of a shared encoder-decoder pair pre-trained directly from limited raw measurements using differentiable forward models to capture population priors, along with subject-specific encoders whose features are jointly decoded for reconstruction. At test time, only the subject-specific encoder is fine-tuned while the shared modules remain frozen to preserve the learned priors. The authors claim that this yields significant improvements in both reconstruction accuracy and efficiency over state-of-the-art INRs across three representative medical imaging tasks.
Significance. If the central claims hold, DisINR could meaningfully advance physics-informed unsupervised learning for medical reconstruction by enabling efficient test-time adaptation that avoids both per-subject full optimization and catastrophic forgetting, while eliminating the need for high-quality pre-acquired images. The direct pre-training from raw measurements via differentiable forward models is a notable strength that addresses a practical bottleneck in the field.
major comments (2)
- The central claim depends on the pre-trained shared priors remaining stable and useful when frozen during subject-specific adaptation. However, the manuscript provides no quantitative evidence on this (e.g., reconstruction gap between frozen vs. unfrozen shared modules, or performance sensitivity to pre-training data volume), leaving the key assumption untested and the efficiency/accuracy claims unsupported.
- Abstract: The assertion of 'significant outperformance' and 'extensive evaluations' on three tasks is not accompanied by any quantitative metrics, error bars, baseline details, or statistical significance tests. This makes it impossible to assess the magnitude or reliability of the reported gains.
minor comments (1)
- The description of feature combination between shared and subject-specific encoders lacks explicit equations or a diagram, which could lead to ambiguity in reproducing the joint decoding step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important aspects that will strengthen the presentation of our results. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: The central claim depends on the pre-trained shared priors remaining stable and useful when frozen during subject-specific adaptation. However, the manuscript provides no quantitative evidence on this (e.g., reconstruction gap between frozen vs. unfrozen shared modules, or performance sensitivity to pre-training data volume), leaving the key assumption untested and the efficiency/accuracy claims unsupported.
Authors: We agree that an explicit ablation quantifying the contribution of the frozen shared modules would provide stronger support for the central claim. In the revised manuscript we will add a new experiment that directly compares reconstruction accuracy when the shared encoder-decoder pair is frozen versus allowed to adapt during test-time optimization. We will also report performance curves as a function of the number of pre-training subjects to demonstrate sensitivity to data volume. These results will be presented in a dedicated subsection of the experimental analysis. revision: yes
-
Referee: Abstract: The assertion of 'significant outperformance' and 'extensive evaluations' on three tasks is not accompanied by any quantitative metrics, error bars, baseline details, or statistical significance tests. This makes it impossible to assess the magnitude or reliability of the reported gains.
Authors: We acknowledge that the abstract would be more informative with concrete numbers. In the revision we will update the abstract to include representative quantitative results (e.g., mean PSNR/SSIM gains with standard deviations) for each of the three tasks, name the primary baselines, and state that the reported improvements are statistically significant according to paired t-tests (p < 0.05). The detailed tables, error bars, and full statistical analysis already present in the experimental section will remain unchanged. revision: yes
Circularity Check
No significant circularity in the DisINR derivation chain
full rationale
The paper introduces a novel architectural framework (DisINR) that explicitly disentangles shared encoder-decoder modules from subject-specific encoders, pre-trains the shared components directly on raw measurements via differentiable forward models, and freezes the shared modules during test-time adaptation. The central claims rest on empirical outperformance across three medical imaging tasks rather than any mathematical derivation that reduces outputs to inputs by construction. No equations are shown that equate a 'prediction' to a fitted parameter, no self-citations serve as load-bearing uniqueness theorems, and no ansatzes are smuggled in via prior work. The method is presented as an independent design choice whose value is demonstrated by reconstruction accuracy and efficiency metrics, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Differentiable forward models exist for the three medical imaging modalities considered
invented entities (1)
-
DisINR architecture with shared encoder-decoder and subject-specific encoders
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. G. Armato III, G. McLennan, L. Bidaut, M. F. McNitt-Gray, C. R. Meyer, A. P. Reeves, B. Zhao, D. R. Aberle, C. I. Henschke, E. A. Hoffman, et al. The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans.Medical physics, 38(2):915–931, 2011
work page 2011
-
[2]
M. Beister, D. Kolditz, and W. A. Kalender. Iterative reconstruction methods in x-ray ct.Physica medica, 28(2):94–108, 2012
work page 2012
-
[3]
Y . Cai, J. Wang, A. Yuille, Z. Zhou, and A. Wang. Structure-aware sparse-view x-ray 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11174–11183, 2024
work page 2024
-
[4]
Y . Chen and X. Wang. Transformers as meta-learners for implicit neural representations. In European Conference on Computer Vision, pages 170–187. Springer, 2022
work page 2022
- [5]
- [6]
-
[7]
J. Feng, R. Feng, Q. Wu, X. Shen, L. Chen, X. Li, L. Feng, J. Chen, Z. Zhang, C. Liu, et al. Spatiotemporal implicit neural representation for unsupervised dynamic mri reconstruction. IEEE Transactions on Medical Imaging, 2025
work page 2025
-
[8]
R. Feng, Q. Wu, J. Feng, H. She, C. Liu, Y . Zhang, and H. Wei. Imjense: scan-specific implicit representation for joint coil sensitivity and image estimation in parallel mri.IEEE Transactions on Medical Imaging, 43(4):1539–1553, 2023
work page 2023
-
[9]
J. A. Fessler. Model-based image reconstruction for mri.IEEE signal processing magazine, 27(4):81–89, 2010
work page 2010
-
[10]
P. Friedrich, F. Bieder, and P. C. Cattin. Medfuncta: Modality-agnostic representations based on efficient neural fields.arXiv e-prints, pages arXiv–2502, 2025
work page 2025
-
[11]
M. G. Harisinghani, A. O’Shea, and R. Weissleder. Advances in clinical mri technology.Science Translational Medicine, 11(523):eaba2591, 2019
work page 2019
- [12]
- [13]
-
[14]
J. S. Jørgensen, E. Ametova, G. Burca, G. Fardell, E. Papoutsellis, E. Pasca, K. Thielemans, M. Turner, R. Warr, W. R. Lionheart, et al. Core imaging library-part i: a versatile python framework for tomographic imaging.Philosophical Transactions of the Royal Society A, 379(2204):20200192, 2021
work page 2021
-
[15]
C. Kim, D. Lee, S. Kim, M. Cho, and W.-S. Han. Generalizable implicit neural representations via instance pattern composers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11808–11817, 2023
work page 2023
-
[16]
D. P. Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 10
work page internal anchor Pith review arXiv 2014
-
[17]
F. Knoll, J. Zbontar, A. Sriram, M. J. Muckley, M. Bruno, A. Defazio, M. Parente, K. J. Geras, J. Katsnelson, H. Chandarana, et al. fastmri: A publicly available raw k-space and dicom dataset of knee images for accelerated mr image reconstruction using machine learning.Radiology: Artificial Intelligence, 2(1):e190007, 2020
work page 2020
-
[18]
J. Lee, J. Tack, N. Lee, and J. Shin. Meta-learning sparse implicit neural representations. Advances in Neural Information Processing Systems, 34:11769–11780, 2021
work page 2021
-
[19]
Y . Li, J. Deng, and Y . Zhang. Universal mapping and patient-specific prior implicit neural representation for enhanced high-resolution mri in mri-guided radiotherapy.Medical physics, 52(7):e17863, 2025
work page 2025
-
[20]
Y . Liu, J. Xie, J. Wu, Z.-X. Cui, Q. Zhu, J. Cheng, H. Wang, Z. Song, D. Liang, and Y . Zhu. Physics-guided self-supervised implicit neural representation for accelerated T1ρ mapping. IEEE Transactions on Biomedical Engineering, pages 1–14, 2025
work page 2025
- [21]
-
[22]
C. H. McCollough, A. C. Bartley, R. E. Carter, B. Chen, T. A. Drees, P. Edwards, D. R. Holmes III, A. E. Huang, F. Khan, S. Leng, et al. Low-dose ct for the detection and classification of metastatic liver lesions: results of the 2016 low dose ct grand challenge.Medical physics, 44(10):e339–e352, 2017
work page 2016
-
[23]
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
work page 2021
- [24]
- [25]
-
[26]
E. Papoutsellis, E. Ametova, C. Delplancke, G. Fardell, J. S. Jørgensen, E. Pasca, M. Turner, R. Warr, W. R. Lionheart, and P. J. Withers. Core imaging library-part ii: multichannel reconstruction for dynamic and spectral tomography.Philosophical Transactions of the Royal Society A, 379(2204):20200193, 2021
work page 2021
-
[27]
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y . Bengio, and A. Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
work page 2019
-
[28]
V . Rangarajan, S. Maiya, M. Ehrlich, and A. Shrivastava. Siedd: Shared-implicit encoder with discrete decoders.arXiv preprint arXiv:2506.23382, 2025
-
[29]
G. D. Rubin. Computed tomography: revolutionizing the practice of medicine for 40 years. Radiology, 273(2S):S45–S74, 2014
work page 2014
-
[30]
L. I. Rudin, S. Osher, and E. Fatemi. Nonlinear total variation based noise removal algorithms. Physica D: nonlinear phenomena, 60(1-4):259–268, 1992
work page 1992
-
[31]
S. Shakouri, M. A. Bakhshali, P. Layegh, B. Kiani, F. Masoumi, S. Ataei Nakhaei, and S. M. Mostafavi. Covid19-ct-dataset: an open-access chest ct image repository of 1000+ patients with confirmed covid-19 diagnosis.BMC research notes, 14(1):178, 2021
work page 2021
-
[32]
L. Shen, J. Pauly, and L. Xing. Nerp: implicit neural representation learning with prior embedding for sparsely sampled image reconstruction.IEEE Transactions on Neural Networks and Learning Systems, 35(1):770–782, 2022
work page 2022
-
[33]
V . Sitzmann, E. Chan, R. Tucker, N. Snavely, and G. Wetzstein. Metasdf: Meta-learning signed distance functions.Advances in Neural Information Processing Systems, 33:10136–10147, 2020. 11
work page 2020
-
[34]
V . Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein. Implicit neural representations with periodic activation functions.Advances in neural information processing systems, 33:7462– 7473, 2020
work page 2020
-
[35]
N. Stolt-Ansó, J. McGinnis, J. Pan, K. Hammernik, and D. Rueckert. Nisf: Neural im- plicit segmentation functions. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 734–744. Springer, 2023
work page 2023
-
[36]
Y . Sun, J. Liu, M. Xie, B. Wohlberg, and U. S. Kamilov. Coil: Coordinate-based internal learning for tomographic imaging.IEEE Transactions on Computational Imaging, 7:1400–1412, 2021
work page 2021
-
[37]
M. Tancik, B. Mildenhall, T. Wang, D. Schmidt, P. P. Srinivasan, J. T. Barron, and R. Ng. Learned initializations for optimizing coordinate-based neural representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2846–2855, 2021
work page 2021
-
[38]
J.-B. Thibault, K. D. Sauer, C. A. Bouman, and J. Hsieh. A three-dimensional statistical approach to improved image quality for multislice helical ct.Medical physics, 34(11):4526– 4544, 2007
work page 2007
-
[39]
K. Vyas, A. I. Humayun, A. Dashpute, R. G. Baraniuk, A. Veeraraghavan, and G. Balakrish- nan. Learning transferable features for implicit neural representations.Advances in Neural Information Processing Systems, 37:42268–42291, 2024
work page 2024
-
[40]
K. Vyas, A. Veeraraghavan, and G. Balakrishnan. Fit pixels, get labels: Meta-learned implicit networks for image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 194–203. Springer, 2025
work page 2025
-
[41]
T. Wang, W. Xia, J. Lu, and Y . Zhang. A review of deep learning ct reconstruction from incomplete projection data.IEEE Transactions on Radiation and Plasma Medical Sciences, 8(2):138–152, 2023
work page 2023
-
[42]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
work page 2004
-
[43]
Q. Wu, L. Chen, C. Wang, H. Wei, S. K. Zhou, J. Yu, and Y . Zhang. Unsupervised polychromatic neural representation for ct metal artifact reduction.Advances in Neural Information Processing Systems, 36:69605–69624, 2023
work page 2023
-
[44]
Q. Wu, C. Du, X. Tian, J. Yu, Y . Zhang, and H. Wei. Moner: Motion correction in undersampled radial MRI with unsupervised neural representation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[45]
Q. Wu, R. Feng, H. Wei, J. Yu, and Y . Zhang. Self-supervised coordinate projection network for sparse-view computed tomography.IEEE Transactions on Computational Imaging, 9:517–529, 2023
work page 2023
-
[46]
D. Xu, H. Liu, X. Miao, D. O’Connor, J. E. Scholey, W. Yang, M. Feng, M. Ohliger, H. Lin, D. Ruan, et al. Accelerated patient-specific non-cartesian mri reconstruction using implicit neural representations.International Journal of Radiation Oncology* Biology* Physics, 2025
work page 2025
-
[47]
K. Yan, X. Wang, L. Lu, L. Zhang, A. P. Harrison, M. Bagheri, and R. M. Summers. Deep lesion graphs in the wild: relationship learning and organization of significant radiology image findings in a diverse large-scale lesion database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9261–9270, 2018
work page 2018
-
[48]
G. Zang, R. Idoughi, R. Li, P. Wonka, and W. Heidrich. Intratomo: self-supervised learning- based tomography via sinogram synthesis and prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1960–1970, 2021
work page 1960
-
[49]
R. Zha, Y . Zhang, and H. Li. Naf: neural attenuation fields for sparse-view cbct reconstruction. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 442–452. Springer, 2022. 12 A Appendix A.1 Experimental Details Data Pre-processingIn our experiments, we include two classical medical imaging tasks: under- sampl...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.