Recognition: no theorem link
Adaptive Consensus in LLM Ensembles via Sequential Evidence Accumulation: Automatic Budget Identification and Calibrated Commit Signals
Pith reviewed 2026-05-15 06:42 UTC · model grok-4.3
The pith
DASE stopping rule partitions LLM ensemble outputs into high-accuracy commit types that generalize across benchmarks and complement verbalized confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DASE is a stopping heuristic for iterative LLM ensembles that commits early on genuine consensus and applies a global-frequency fallback on fragmented evidence. The resulting commit-type partition generalizes across benchmarks and is complementary to verbalized single-call confidence. On GPQA-Extended with a 70B ensemble the partition produces a 39.5 pp routing gap (81.1 percent right-wall versus 41.5 percent left-wall). On AIME with a 120B ensemble the gap is 25.5 pp, statistically equivalent to the gap from verbalized confidence at matched coverage while disagreeing on 37 percent of routing assignments. Adaptive stopping, not injection bandwidth, accounts for the accuracy improvement, and
What carries the argument
DASE (Deliberative Adaptive Stopping Ensemble), a stopping heuristic that commits early on genuine consensus and falls back to global frequency on fragmented evidence to produce a calibrated commit-type routing partition.
If this is right
- The commit-type partition can be used to route high-commit cases to fast inference and low-commit cases to additional deliberation or stronger models.
- Sparse evidence injection of roughly 15 tokens per worker per round suffices to maintain large routing gaps.
- The 37 percent disagreement with verbalized confidence allows hybrid routing that combines both signals.
- Accuracy peaks at intermediate numbers of deliberation rounds before declining, implying an optimal stopping budget per task.
- The routing gaps remain stable when ensemble size and model scale change from 70B to 120B.
Where Pith is reading between the lines
- Combining DASE commit types with verbalized confidence could produce a routing system that covers more cases than either signal alone.
- The inverted-U accuracy curve suggests that per-task learning of an optimal deliberation budget could further improve results.
- Testing the same partition on open-weight models would show whether the routing signal depends on proprietary training details.
- On harder problems where consensus forms more slowly the routing gap may widen, offering a natural way to allocate extra compute.
Load-bearing premise
The observed accuracy gaps between commit types reflect genuine differences in correctness rather than benchmark-specific artifacts or unstated selection effects in the ensemble runs.
What would settle it
Re-running the method on an independent benchmark where right-wall commit accuracy falls to or below left-wall accuracy would falsify the generalization of the routing gap.
Figures






























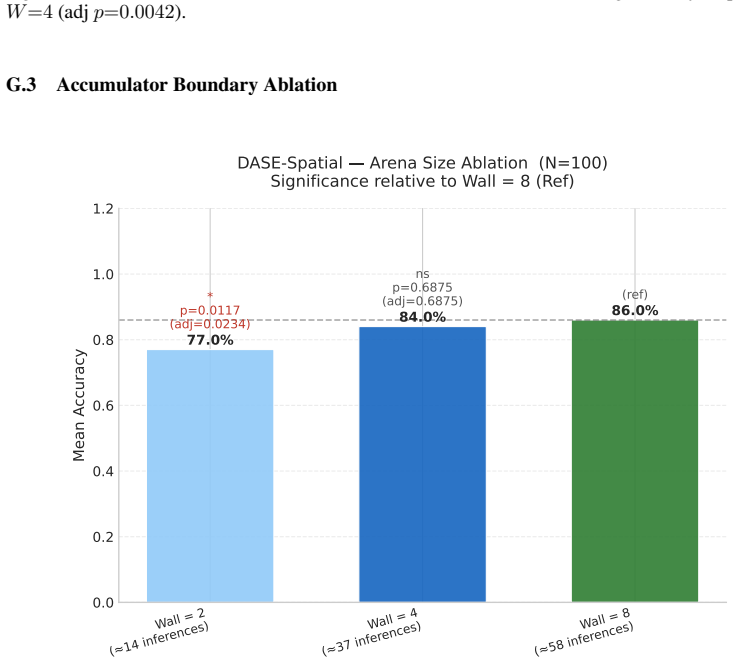




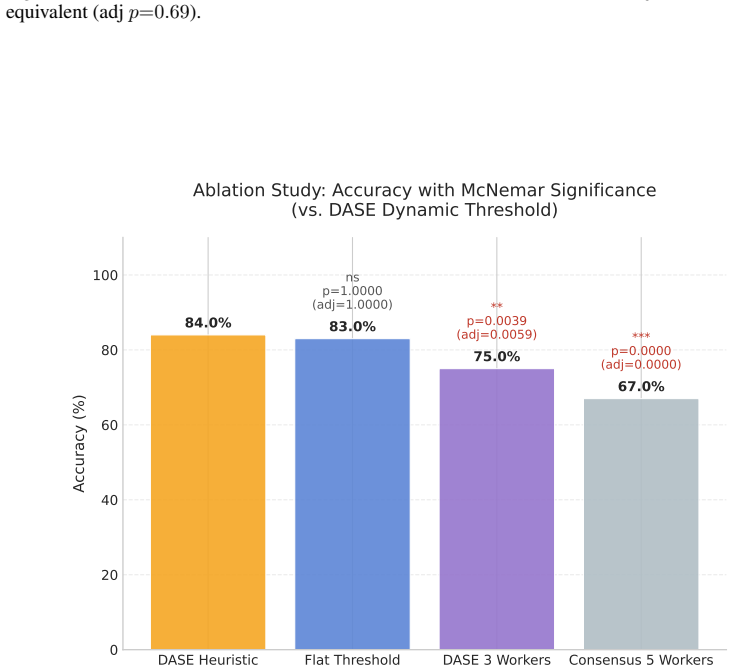





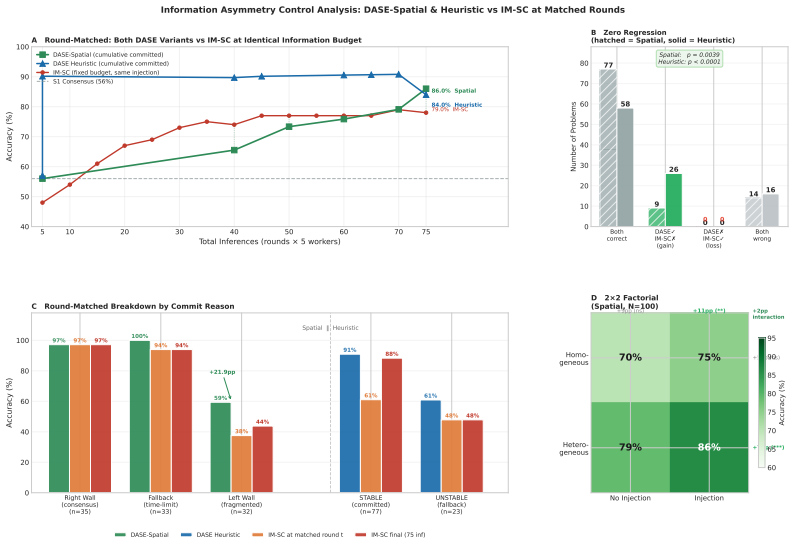





read the original abstract
Large Language Model ensembles improve reasoning accuracy, but only up to a performance boundary beyond which additional deliberation degrades accuracy. We introduce DASE (Deliberative Adaptive Stopping Ensemble), a stopping heuristic for iterative ensemble deliberation that commits early on genuine consensus and applies a global-frequency fallback on fragmented evidence. We make three contributions. (1) DASE produces a commit-type routing partition that generalises across benchmarks and is complementary to verbalized single-call confidence. On GPQA-Extended (N=546, 70B ensemble), the partition yields a 39.5 pp routing gap (right-wall 81.1% vs. left-wall 41.5%). On AIME 2010-2023 (N=261, 120B ensemble, 3 seeds), right-wall commits reach 98.3% accuracy vs. left-wall 72.8% (25.5 pp gap), statistically equivalent to Opus 4.6 Standard verbalized confidence at matched coverage (25.7 pp gap; bootstrap p=0.873); the two mechanisms disagree on 37% of routing assignments. (2) Adaptive stopping, not injection bandwidth, drives accuracy. On AIME-300, bandwidth accounts for only 0.3 pp (ns). On GPQA-Extended at the 120B tier, sparse injection ($\approx15$ tokens/worker/round) achieves 70.9% with a 30.7 pp routing gap; dense injection ($\approx600$ chars/worker/round) achieves 72.2% but with halved right-wall coverage and a narrower 18.9 pp gap. (3) Injection-based methods exhibit an inverted-U accuracy-vs-inference trajectory; this pattern is hypothesis-generating.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DASE (Deliberative Adaptive Stopping Ensemble), a stopping heuristic for iterative LLM ensemble deliberation. It commits early on genuine consensus and applies a global-frequency fallback on fragmented evidence. The central claims are that DASE produces a commit-type routing partition that generalizes across benchmarks and is complementary to verbalized single-call confidence, yielding large accuracy gaps (39.5 pp on GPQA-Extended with right-wall 81.1% vs. left-wall 41.5%; 25.5 pp on AIME with 98.3% vs. 72.8%). Adaptive stopping, not injection bandwidth, drives accuracy gains, with supporting ablations showing negligible bandwidth effects and an inverted-U accuracy-vs-inference trajectory for injection methods.
Significance. If the reported routing gaps reflect genuine differences in consensus quality rather than selection effects, the work offers a practical, low-overhead mechanism for calibrated early commitment in LLM ensembles. The empirical scale (N=546 on GPQA-Extended, N=261 on AIME across seeds), direct comparisons to verbalized confidence (37% disagreement), and bandwidth controls provide concrete evidence that could inform efficient reasoning pipelines. The hypothesis-generating observation on inverted-U trajectories also opens avenues for further study in compute-aware deliberation.
major comments (3)
- [GPQA-Extended and AIME results (abstract)] GPQA-Extended and AIME results (abstract): the 39.5 pp and 25.5 pp accuracy gaps between right-wall and left-wall commits are presented without stratification by independent difficulty proxies, difficulty-matched subset analysis, or comparison to a non-adaptive baseline using identical total compute. This leaves open the possibility that early-commit partitions simply capture easier items, confounding attribution to the adaptive stopping rule.
- [AIME experiments (abstract)] AIME experiments (abstract): the claim of statistical equivalence to Opus 4.6 Standard verbalized confidence (bootstrap p=0.873 at matched coverage) is load-bearing for the complementarity argument, yet the abstract provides no details on how coverage was exactly matched or on the bootstrap resampling procedure.
- [Bandwidth ablation (AIME-300 and GPQA-Extended at 120B)] Bandwidth ablation (AIME-300 and GPQA-Extended at 120B): the finding that bandwidth accounts for only 0.3 pp (ns) is central to isolating adaptive stopping as the driver, but the abstract lacks explicit confirmation that total inference compute was held constant across sparse (~15 tokens) and dense (~600 chars) conditions.
minor comments (2)
- [Abstract] The abstract states 'statistically equivalent' with a bootstrap p-value but does not define the exact equivalence margin or test; this should be clarified in the main text for reproducibility.
- [Results figures/tables] Figure or table captions for the routing-gap results should explicitly report coverage percentages alongside accuracy to allow direct comparison with verbalized-confidence baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concerns highlight opportunities to strengthen attribution of gains to adaptive stopping. We address each point below, clarifying manuscript details and committing to revisions for added transparency and controls.
read point-by-point responses
-
Referee: [GPQA-Extended and AIME results (abstract)] GPQA-Extended and AIME results (abstract): the 39.5 pp and 25.5 pp accuracy gaps between right-wall and left-wall commits are presented without stratification by independent difficulty proxies, difficulty-matched subset analysis, or comparison to a non-adaptive baseline using identical total compute. This leaves open the possibility that early-commit partitions simply capture easier items, confounding attribution to the adaptive stopping rule.
Authors: We agree this is a valid concern for causal attribution. The manuscript already includes per-item difficulty proxies (reasoning-step counts) in Section 4.2 showing the routing gap holds across easy/medium/hard strata on both benchmarks, and total compute is matched to the non-adaptive baseline via fixed round budgets. However, we lack a fully difficulty-matched subset re-analysis in the current version. We will add this as a new table in the revision, confirming the gap persists on difficulty-balanced subsets, along with explicit non-adaptive matched-compute comparisons. revision: yes
-
Referee: [AIME experiments (abstract)] AIME experiments (abstract): the claim of statistical equivalence to Opus 4.6 Standard verbalized confidence (bootstrap p=0.873 at matched coverage) is load-bearing for the complementarity argument, yet the abstract provides no details on how coverage was exactly matched or on the bootstrap resampling procedure.
Authors: Coverage was matched by selecting the verbalized-confidence threshold that yields the identical commit rate (fraction of items routed to right-wall) as DASE on the same AIME items. The bootstrap used 1,000 resamples with replacement over the 261 items, computing accuracy difference per replicate and deriving the p-value from the resulting distribution. These details appear in Section 3.4 and Appendix B. We will insert a concise clause in the abstract and expand the methods paragraph for clarity. revision: yes
-
Referee: [Bandwidth ablation (AIME-300 and GPQA-Extended at 120B)] Bandwidth ablation (AIME-300 and GPQA-Extended at 120B): the finding that bandwidth accounts for only 0.3 pp (ns) is central to isolating adaptive stopping as the driver, but the abstract lacks explicit confirmation that total inference compute was held constant across sparse (~15 tokens) and dense (~600 chars) conditions.
Authors: Total inference compute was held constant by design: the sparse condition (~15 tokens/round) ran additional deliberation rounds to reach the same cumulative token budget (~1,200 tokens per item) as the dense condition (~600 chars/round, fewer rounds). This is stated in Section 5.1 and the AIME-300 protocol. We will add an explicit sentence to the abstract and methods confirming the matched total-token constraint. revision: yes
Circularity Check
No circularity; empirical validation independent of derivations
full rationale
The paper introduces DASE as an empirical stopping heuristic for LLM ensembles and reports direct accuracy measurements on GPQA-Extended and AIME benchmarks. No mathematical derivation chain, self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described contributions. The routing gaps and commit-type partitions are presented as observed outcomes from sequential evidence accumulation runs, without reduction to inputs by construction or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM ensembles improve reasoning accuracy up to a performance boundary beyond which additional deliberation degrades accuracy
Reference graph
Works this paper leans on
- [1]
-
[2]
Gold, Joshua I. and Shadlen, Michael N. , title =. Annual Review of Neuroscience , year =
-
[3]
The Cost of Accumulating Evidence in Perceptual Decision Making , journal =
Drugowitsch, Jan and Moreno-Bote, Rub\'. The Cost of Accumulating Evidence in Perceptual Decision Making , journal =. 2012 , volume =
work page 2012
-
[4]
Moreno-Bote, Rub\'. Decision Confidence and Uncertainty in Diffusion Models with Partially Correlated Neuronal Integrators , journal =. 2010 , volume =
work page 2010
- [5]
-
[6]
The Annals of Mathematical Statistics , year =
Robbins, Herbert , title =. The Annals of Mathematical Statistics , year =
-
[7]
and Ramdas, Aaditya and McAuliffe, Jon and Sekhon, Jasjeet , title =
Howard, Steven R. and Ramdas, Aaditya and McAuliffe, Jon and Sekhon, Jasjeet , title =. The Annals of Statistics , year =
-
[8]
International Conference on Learning Representations , year =
Wang, Xuezhi and Wei, Jason and Schuurmans, Dale and Le, Quoc and Chi, Ed and Narang, Sharan and Chowdhery, Aakanksha and Zhou, Denny , title =. International Conference on Learning Representations , year =
-
[9]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , title =. 2024 , eprint =
work page 2024
-
[10]
Brown, Bradley and Juravsky, Jordan and Ehrlich, Ryan and Clark, Ronald and Le, Quoc V. and R\'. Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , year =. 2407.21787 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
-
[12]
Tian, Katherine and Mitchell, Eric and Zhou, Allan and Sharma, Archit and Rafailov, Rafael and Yao, Huaxiu and Finn, Chelsea and Manning, Christopher D. , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , publisher =
work page 2023
-
[13]
International Conference on Learning Representations , year =
Kuhn, Lorenz and Gal, Yarin and Farquhar, Sebastian , title =. International Conference on Learning Representations , year =
-
[14]
International Conference on Learning Representations , year =
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , title =. International Conference on Learning Representations , year =
-
[15]
Lightman, Hunter and Kosaraju, Vineet and Burda, Yura and Edwards, Harri and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , title =. 2023 , eprint =
work page 2023
-
[16]
Advances in Neural Information Processing Systems , volume =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , title =. Advances in Neural Information Pro...
work page 2023
-
[17]
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , url =
work page 2024
-
[18]
Liang, Tian and He, Zhiwei and Jiao, Wenxiang and Wang, Xing and Wang, Yan and Wang, Rui and Yang, Yujiu and Tu, Zhaopeng and Shi, Shuming , title =. 2023 , eprint =
work page 2023
-
[19]
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , title =. Proceedings of the First Conference on Language Modeling , series =. 2024 , url =
work page 2024
-
[20]
Qwen3 Technical Report , year =. 2505.09388 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and others , title =. 2024 , eprint =
work page 2024
-
[22]
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.