Gradient Scaling Effects in Adaptive Spectral PINNs for Stiff Nonlinear ODEs
Pith reviewed 2026-05-08 16:39 UTC · model grok-4.3
The pith
The choice of initial-condition gating function induces time-dependent gradient scaling that alters optimization dominance in adaptive spectral PINNs for stiff ODEs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In adaptive spectral PINNs, the IC gating function induces explicit time-dependent gradient scaling which interacts with spectral representations during training and produces stiffness-dependent changes in relative dominance for exponential versus linear gates on a nonlinear stiff spring-pendulum ODE.
What carries the argument
The IC gating function (exponential or linear), which applies time-dependent modulation to enforce initial conditions and thereby generates explicit scaling factors on the gradients that interact with the adaptive Fourier spectral trunk.
If this is right
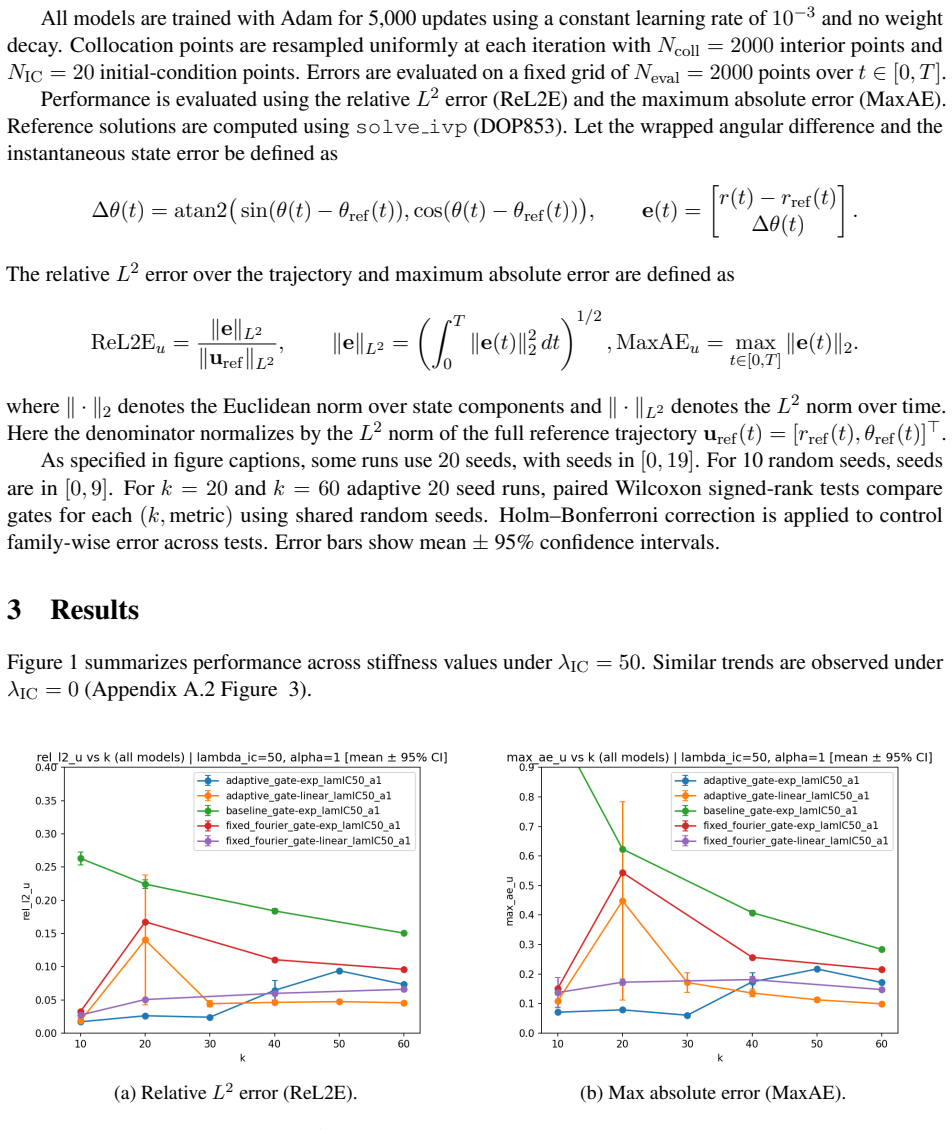
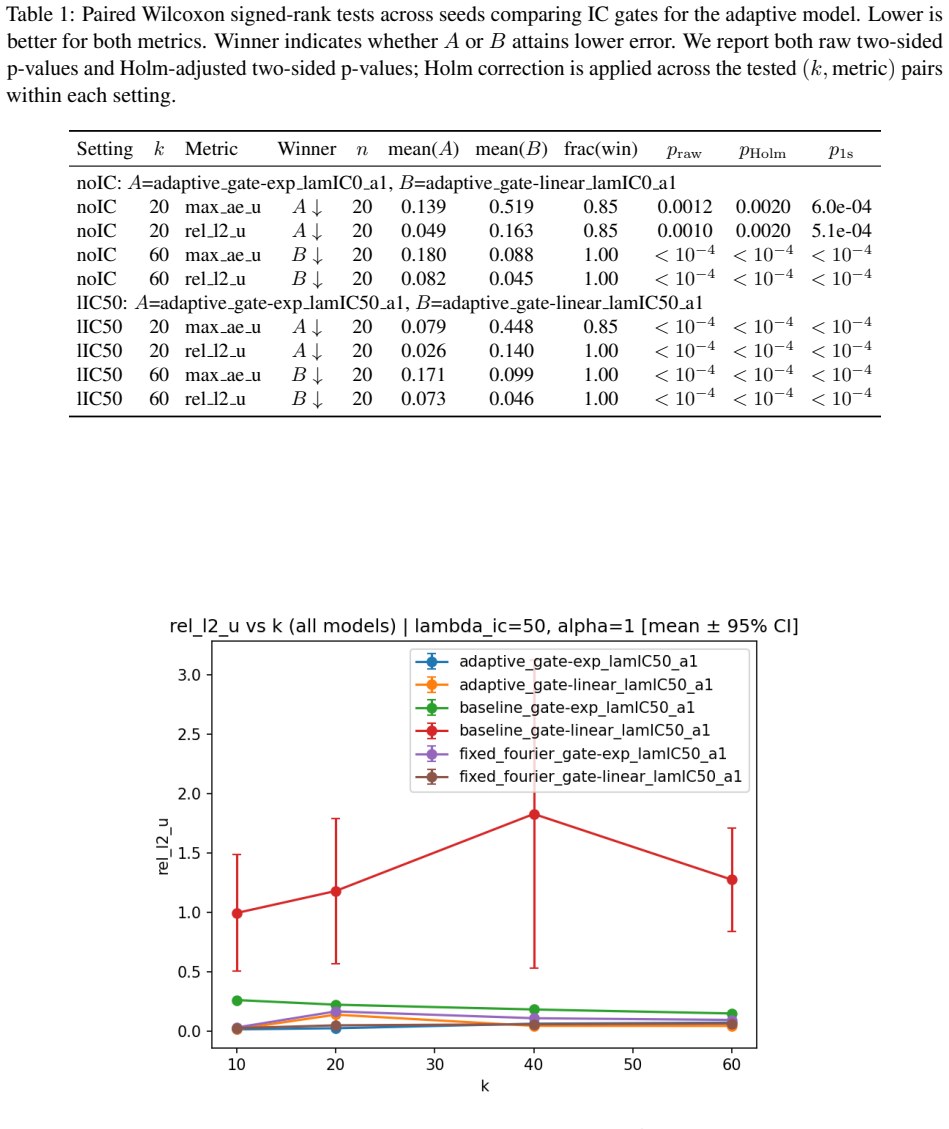
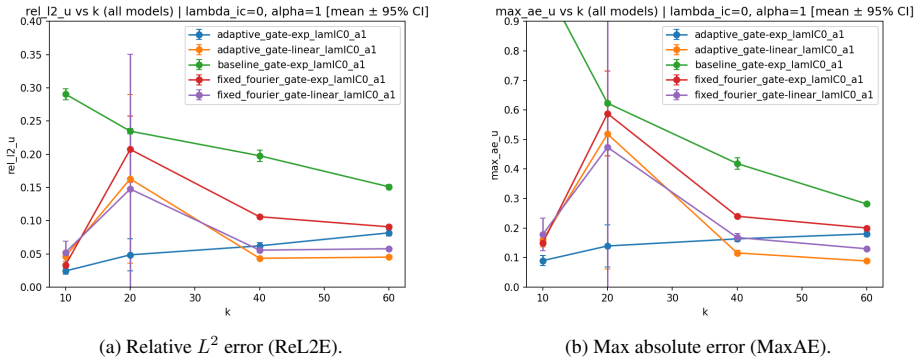
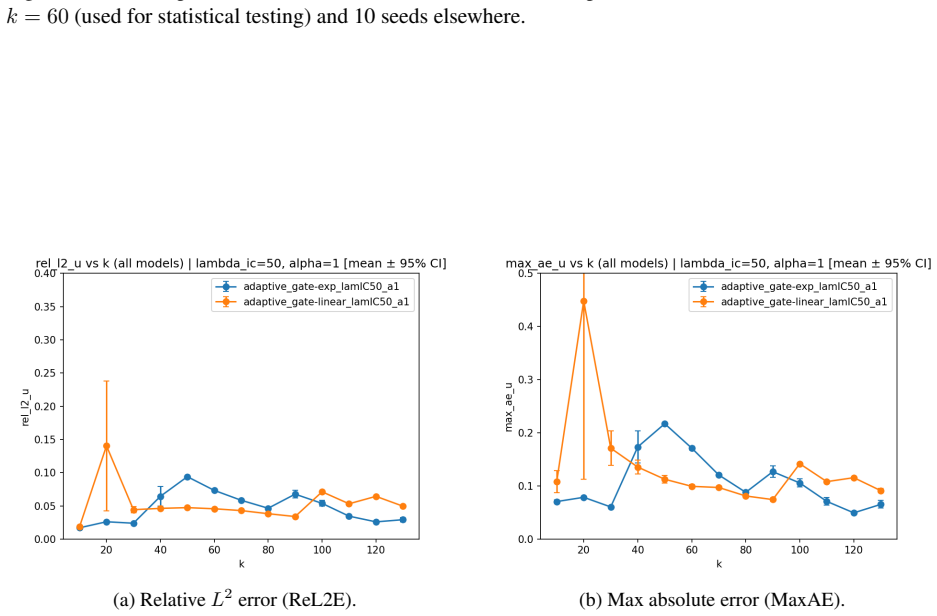
- At moderate stiffness (k=20) exponential gating often produces lower relative L2 and maximum pointwise error but with higher seed-to-seed variability.
- At higher stiffness (k=60) linear gating becomes preferable, with additional reversals appearing at still larger k values.
- The trends hold for both fixed and adaptive spectral trunks and are supported by paired Wilcoxon signed-rank tests with Holm correction.
- IC embeddings are therefore an active factor that materially shapes optimization conditioning in stiff regimes.
Where Pith is reading between the lines
- If the scaling mechanism is primary, similar stiffness-dependent reversals may appear when other IC enforcement techniques are used in non-spectral PINNs.
- Monitoring gradient norms over training time could allow dynamic selection of the gating function without exhaustive search.
- The interaction points to a possible design principle where gating is adapted to an online estimate of local stiffness.
Load-bearing premise
Observed performance differences between exponential and linear gates are caused by the induced gradient scaling rather than by other uncontrolled factors such as optimization hyperparameters or spectral adaptation details.
What would settle it
An experiment that artificially equalizes the gradient scaling factors between the two gating methods while holding all other training elements fixed and checks whether the stiffness-dependent performance reversal disappears.
Figures
read the original abstract
Physics-Informed Neural Networks (PINNs) often struggle to train reliably on stiff and oscillatory dynamical systems due to poor optimization conditioning. While prior work has emphasized representational remedies such as spectral parameterizations, the optimization implications of initial-condition (IC) embeddings in adaptive spectral PINNs have not been well characterized. In this work, we show that the choice of IC gating function induces explicit time-dependent gradient scaling, which interacts with spectral representations during training. Using a nonlinear stiff spring-pendulum ODE as a controlled benchmark, we compare exponential and linear IC gates in combination with fixed and adaptive Fourier spectral trunks. We observe stiffness-dependent changes in relative dominance for adaptive PINNs: at moderate stiffness ($k=20$), exponential gating often yields lower error but exhibits heterogeneous behavior across random seeds, whereas at higher stiffness ($k=60$), linear gating becomes preferable, with additional reversals observed at larger $k$. These trends hold for both relative $L^2$ error and maximum pointwise error and are confirmed by paired Wilcoxon signed-rank tests with Holm correction. Overall, our results demonstrate that IC embeddings are not a neutral design choice in PINNs: the induced gradient scaling materially shapes optimization conditioning in stiff regimes, with distinct sensitivity patterns in baseline and adaptive spectral models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on Gradient Scaling Effects in Adaptive Spectral PINNs for Stiff Nonlinear ODEs. It derives that exponential versus linear initial-condition (IC) gating functions induce distinct time-dependent multipliers on residual loss gradients. Using a nonlinear stiff spring-pendulum ODE benchmark, the work compares these gates in combination with fixed and adaptive Fourier spectral trunks. It reports stiffness-dependent reversals in relative dominance (exponential often lower error at k=20 with heterogeneous seed behavior; linear preferable at k=60, with further reversals at larger k) for both relative L² error and maximum pointwise error, supported by paired Wilcoxon signed-rank tests with Holm correction. The central claim is that IC embeddings are not neutral design choices because the induced gradient scaling materially shapes optimization conditioning in stiff regimes.
Significance. If the causal attribution to gradient scaling holds, the result is significant for PINN design: it shows that seemingly minor IC embedding choices can reverse performance trends across stiffness levels and interact with spectral adaptation, offering concrete guidance for stiff dynamical systems where standard PINNs fail. The statistical testing and dual error metrics add rigor to the benchmark. The work also highlights an under-characterized optimization aspect of spectral PINNs beyond representational capacity.
major comments (2)
- [Results] Results section: the reported stiffness-dependent performance reversals (exponential vs linear gates at k=20 vs k=60) are not isolated from confounding factors. No ablation reweights the loss to neutralize the gating-induced scaling factor, no per-epoch gradient-norm logs confirm the predicted time-dependent multiplier ratios, and no controls hold spectral adaptation schedule and optimizer hyperparameters fixed while varying only the scaling mechanism.
- [Methods] Methods section: the comparison of exponential and linear IC gates does not rule out alternative explanations for the observed reversals, such as differences in gate smoothness, saturation behavior, or unintended interactions with the adaptive frequency selection procedure, rather than the claimed explicit gradient scaling.
minor comments (2)
- [Abstract] The abstract states 'additional reversals observed at larger k' without specifying the exact k values tested or showing the full trend in a figure or table.
- Notation for the time-dependent multipliers induced by each gate should be introduced with an equation number in the derivation section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, clarifying our experimental controls and theoretical derivations while indicating revisions that will strengthen the presentation.
read point-by-point responses
-
Referee: [Results] Results section: the reported stiffness-dependent performance reversals (exponential vs linear gates at k=20 vs k=60) are not isolated from confounding factors. No ablation reweights the loss to neutralize the gating-induced scaling factor, no per-epoch gradient-norm logs confirm the predicted time-dependent multiplier ratios, and no controls hold spectral adaptation schedule and optimizer hyperparameters fixed while varying only the scaling mechanism.
Authors: We agree that further isolation of the scaling effect would be beneficial. Our design already fixes the spectral adaptation schedule, optimizer hyperparameters, network architecture, and all other training elements, varying solely the IC gate function between exponential and linear forms. The Methods section derives the explicit time-dependent multiplier on residual gradients induced by each gate. To address the request for confirmation, we will add per-epoch gradient-norm plots in the revised results section. A loss-reweighting ablation to neutralize the scaling is not straightforward, as it would fundamentally alter the optimization objective; we will instead add a discussion of this limitation and emphasize that the fixed-trunk controls already isolate the scaling while holding adaptation fixed. revision: partial
-
Referee: [Methods] Methods section: the comparison of exponential and linear IC gates does not rule out alternative explanations for the observed reversals, such as differences in gate smoothness, saturation behavior, or unintended interactions with the adaptive frequency selection procedure, rather than the claimed explicit gradient scaling.
Authors: The Methods section derives the gradient scaling explicitly as a multiplicative, time-dependent factor arising from the functional form of the gate applied to the IC embedding. Smoothness and saturation differences are intrinsic to how each gate generates this scaling factor rather than separate confounds. To rule out interactions with adaptation, we already include fixed (non-adaptive) Fourier trunk results, which exhibit the same stiffness-dependent reversals. We will revise the Methods section to more prominently highlight this control experiment and the derivation that isolates the scaling mechanism from other factors. revision: partial
Circularity Check
Empirical benchmark study with no load-bearing derivation that reduces to its inputs
full rationale
The paper is an empirical comparison of exponential vs. linear IC gating functions in adaptive spectral PINNs on a stiff ODE benchmark. It reports observed performance reversals at different stiffness levels (k=20 vs k=60) supported by Wilcoxon tests, without any derivation chain, fitted-parameter predictions, or self-citation that defines the central result by construction. No equations or claims reduce the reported gradient-scaling interaction to an input by definition; the work treats the scaling as an observed mechanism whose causal isolation is left to future controls. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Archives of Computational Methods in Engineering , year =
Stiff-PDEs and Physics-Informed Neural Networks , author =. Archives of Computational Methods in Engineering , year =
-
[2]
Advances in Neural Information Processing Systems , year =
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , author =. Advances in Neural Information Processing Systems , year =
-
[3]
Journal of Computational Physics , year =
When and Why PINNs Fail to Train: A Neural Tangent Kernel Perspective , author =. Journal of Computational Physics , year =
-
[6]
IEEE Transactions on Neural Networks , year =
Artificial neural networks for solving ordinary and partial differential equations , author =. IEEE Transactions on Neural Networks , year =
-
[7]
Mathematical & Computational Applications , volume =
Error Estimates and Generalized Trial Constructions for Solving ODEs Using Physics-Informed Neural Networks , author =. Mathematical & Computational Applications , volume =
-
[8]
Atmane Babni, Ismail Jamiai, and José Alberto Rodrigues. Error estimates and generalized trial constructions for solving odes using physics-informed neural networks. Mathematical & Computational Applications, 30 0 (6): 0 127, 2025
work page 2025
-
[9]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Cl \'e ment Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in Neural Information Processing Systems, 2018
work page 2018
-
[10]
Lagaris, Aristidis Likas, and Dimitrios I
Isaac E. Lagaris, Aristidis Likas, and Dimitrios I. Fotiadis. Artificial neural networks for solving ordinary and partial differential equations. IEEE Transactions on Neural Networks, 1998
work page 1998
-
[11]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks. arXiv preprint arXiv:2012.10047, 2020
-
[12]
When and why pinns fail to train: A neural tangent kernel perspective
Sifan Wang, Yujie Teng, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 2021
work page 2021
-
[13]
Xiaodong Xiong, Zhen Zhang, Rui Hu, Cheng Gao, and Zhi Deng. Separated-variable spectral neural networks: A physics-informed learning approach for high-frequency pdes. arXiv preprint arXiv:2508.00628, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.