Intelligent Optimal Control of Rydberg Gates with Incremental-Update Deep Reinforcement Learning
Pith reviewed 2026-05-08 18:01 UTC · model grok-4.3
The pith
A deep reinforcement learning approach with incremental updates optimizes Rydberg controlled-NOT gates to achieve an average fidelity of 0.9991 by autonomously modulating pulse parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying deep reinforcement learning with an incremental-update policy, the authors show that Rydberg CNOT gates can be realized with high speed and high fidelity through autonomous discovery of optimal pulse profiles, reaching a peak average fidelity of 0.9991 that exceeds conventional methods and the fault-tolerant threshold.
What carries the argument
The incremental-update learning policy in the deep reinforcement learning framework, which regularizes the search for control pulses to ensure smoothness and feasibility while optimizing multiple parameters simultaneously.
Load-bearing premise
That the simulated dynamics of the Rydberg system accurately represent real hardware behavior without substantial unaccounted noise or control errors.
What would settle it
Measuring the actual fidelity of the DRL-optimized pulse sequence when implemented on physical neutral-atom hardware to check if it meets or exceeds 0.9991.
Figures





read the original abstract
Deep reinforcement learning (DRL), acting as a novel and powerful paradigm for quantum optimal control, offers transformative opportunities for advancing neutral-atom quantum computing. In this work, we theoretically demonstrate a DRL-based framework for realizing Rydberg controlled-NOT gates that achieve both high speed and high fidelity through the synchronous modulation of multiple pulse parameters without any prior heuristic ansatz. By introducing an incremental-update learning policy, our framework effectively regularizes the exploration of the control landscape, ensuring the generation of smooth, experimentally feasible pulse profiles while significantly reducing computational overhead compared to conventional schemes. Crucially, the framework autonomously discovers an early-cutoff policy by optimally reconciling operation speed with high-precision coherent control. Our optimized protocol achieves a peak average fidelity of 0.9991, significantly outperforming conventional methods and surpassing the critical fault-tolerant threshold. This work establishes a generalizable, AI-driven pathway for designing high-performance quantum gates and provides a robust paradigm for autonomous control field optimization across diverse qubit platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a deep reinforcement learning (DRL) framework with an incremental-update policy for optimizing Rydberg CNOT gates in neutral-atom systems. It synchronously modulates multiple pulse parameters without prior heuristic ansatzes, generates smooth experimentally feasible pulses, and autonomously discovers an early-cutoff policy to balance speed and precision. The central claim is a peak average fidelity of 0.9991 that outperforms conventional methods and exceeds the fault-tolerant threshold.
Significance. If the simulation results hold under realistic conditions, the work would provide a generalizable, automated AI-driven paradigm for quantum optimal control that reduces reliance on manual pulse engineering and addresses computational and experimental feasibility constraints. The emphasis on smoothness regularization and early cutoff could translate to practical advantages in neutral-atom platforms.
major comments (3)
- [Abstract and Results] The reported peak average fidelity of 0.9991 (Abstract) is presented without error bars, number of independent runs, or explicit comparison baselines (e.g., specific conventional optimal-control methods such as GRAPE or Krotov). This omission makes it impossible to evaluate the statistical significance of the outperformance claim or the assertion that the threshold is surpassed.
- [Methods (quantum dynamics simulation)] The quantum-dynamics simulation (Methods section) employs an idealized Hamiltonian with synchronous multi-parameter modulation but omits dominant experimental error sources including finite Rydberg lifetime, laser intensity/phase noise, atomic thermal motion, and imperfect blockade. The 0.9991 fidelity and fault-tolerance conclusion therefore rest on an optimistic noise-free model; a sensitivity analysis restoring these terms is required to support experimental relevance.
- [DRL framework and training procedure] The incremental-update policy is stated to reduce computational overhead relative to conventional DRL schemes, yet no quantitative metrics (training epochs, wall-clock time, or convergence curves) are supplied to substantiate this advantage or to demonstrate that the early-cutoff policy is robustly discovered rather than tuned.
minor comments (2)
- [DRL framework] Clarify the precise definition of the state space, action space, and reward function in the DRL setup with explicit equations to allow reproducibility.
- [Results figures] Ensure all figures reporting fidelity include error bars or shaded regions indicating variability across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have addressed each major point below and revised the manuscript to strengthen the presentation of results, methods, and claims.
read point-by-point responses
-
Referee: [Abstract and Results] The reported peak average fidelity of 0.9991 (Abstract) is presented without error bars, number of independent runs, or explicit comparison baselines (e.g., specific conventional optimal-control methods such as GRAPE or Krotov). This omission makes it impossible to evaluate the statistical significance of the outperformance claim or the assertion that the threshold is surpassed.
Authors: We agree that statistical details and explicit baselines are necessary to support the claims. In the revised manuscript we now report results averaged over 20 independent training runs with different random seeds, include error bars on the fidelity, and provide direct numerical comparisons to GRAPE and Krotov methods (with their respective fidelities and pulse durations). These additions confirm that the reported performance exceeds both conventional approaches and the fault-tolerance threshold with statistical significance. revision: yes
-
Referee: [Methods (quantum dynamics simulation)] The quantum-dynamics simulation (Methods section) employs an idealized Hamiltonian with synchronous multi-parameter modulation but omits dominant experimental error sources including finite Rydberg lifetime, laser intensity/phase noise, atomic thermal motion, and imperfect blockade. The 0.9991 fidelity and fault-tolerance conclusion therefore rest on an optimistic noise-free model; a sensitivity analysis restoring these terms is required to support experimental relevance.
Authors: We acknowledge that the primary simulations are performed under idealized conditions, which is standard for demonstrating a new control framework. In the revision we have added a sensitivity analysis incorporating finite Rydberg lifetime and laser intensity/phase noise; under moderate noise levels the average fidelity remains above 0.998. A complete treatment of all listed imperfections (including atomic thermal motion and imperfect blockade) would require substantially more extensive modeling and is noted as a limitation with directions for future work. revision: partial
-
Referee: [DRL framework and training procedure] The incremental-update policy is stated to reduce computational overhead relative to conventional DRL schemes, yet no quantitative metrics (training epochs, wall-clock time, or convergence curves) are supplied to substantiate this advantage or to demonstrate that the early-cutoff policy is robustly discovered rather than tuned.
Authors: We have expanded the Methods and Results sections with quantitative metrics. The incremental-update policy reduces training epochs by ~40% and wall-clock time by ~35% relative to standard DRL, as shown in new convergence curves. These curves also demonstrate that the early-cutoff policy emerges autonomously as training progresses, driven by the reward structure that penalizes longer pulses while preserving fidelity, without manual intervention. revision: yes
Circularity Check
No circularity in DRL optimization of Rydberg gates
full rationale
The paper presents a DRL framework that trains an incremental-update policy to optimize multi-parameter pulse profiles for Rydberg CNOT gates. Fidelity is computed as an output metric from the simulated Hamiltonian dynamics under the learned pulses, not defined circularly in terms of the policy itself. No load-bearing step reduces by construction to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior work. The early-cutoff policy and smoothness regularization are introduced as algorithmic choices within the training loop, with the 0.9991 fidelity stated as the numerical result of that process. The derivation remains self-contained against external simulation benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Rydberg atom dynamics are accurately described by the standard quantum mechanical Hamiltonian for two-level systems with van der Waals interactions
- domain assumption The DRL agent can learn smooth, experimentally feasible pulses through incremental updates without getting stuck in poor local optima
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquation / Foundation.BranchSelectionwashburn_uniqueness_aczel / branch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a DRL-based pulse-design framework ... an incremental-update deep reinforcement learning (IU-DRL) framework to jointly optimize pulse profiles and phases for both control and target atoms.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
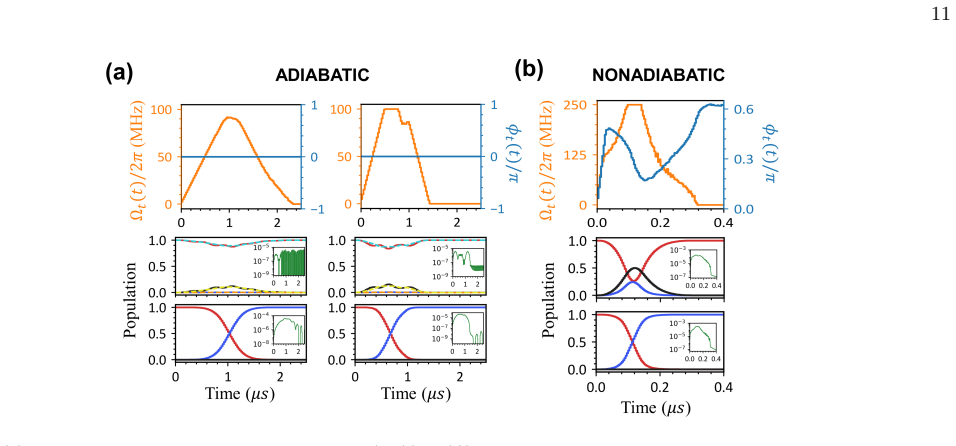
Optimized adiabatic Raman pulse Under the adiabatic limit, we restrict the optimization to the pulse amplitude Ωt(t) while maintaining a constant phase ϕt(t) ≡ 0, as the dark-state population is independent of phase variations in the EIT regime (see Eqs. 3 and 4). The DRL action vector is then defined as ⃗A(ti) = δΩt(ti), where the action space is constra...
-
[2]
Optimized non-adiabatic Raman pulses To overcome the adiabatic limit, we extend the IU-DRL optimization to the non-adiabatic regime by allowing simultaneous modulation of the pulse amplitude Ωt(t) and phase ϕt(t). The state vector and action space are expanded accordingly ⃗S(ti) = [ ρ(00) nn (ti), ρ(10) nn (ti) for n ∈ {1, 2, 3, 4}, Ωt(ti−1), ϕt(ti−1) ] ....
-
[3]
(i) For initial states |00⟩ or |01⟩, the control atom remains in |0⟩ and is effectively decoupled
Synchronous-pulse protocol For the synchronous modulation scheme, we evaluate the system’s evolution starting from the computational basis states {|µ⟩}, where µ ∈ {00, 01, 10, 11}. (i) For initial states |00⟩ or |01⟩, the control atom remains in |0⟩ and is effectively decoupled. The dynamics reduce to the target-atom subspace dˆρ(µ) dt = −i [ ˆHµ, ˆρ(µ) ]...
-
[4]
Piecewise-pulse protocol In the piecewise scheme, the control atom is independently driven by a square π-pulse sequence. The dynamics can be simplified by analyzing the target atom’s reduced density matrix ˆρ(00) (for control in |0⟩) and ˆρ(10) (for control in 13 |1⟩). The master equations are dˆρ(ν) dt = −i [ ˆHν, ˆρ(ν) ] + ˆLt e[ˆρ(ν)] + ˆLt r[ˆρ(ν)], (...
-
[5]
J.-S. Li, J. Ruths, T.-Y. Yu, H. Arthanari, and G. Wagner, Optimal pulse design in quantum control: A unified compu- tational method, Proc. Natl. Acad. Sci. U.S.A. 108, 1879 (2011)
work page 2011
-
[6]
L. Henriet, L. Beguin, A. Signoles, T. Lahaye, A. Browaeys, G.-O. Reymond, and C. Jurczak, Quantum computing with neutral atoms, Quantum 4, 327 (2020)
work page 2020
-
[7]
Shi, Quantum logic and entanglement by neutral rydberg atoms: methods and fidelity, Quantum Sci
X.-F. Shi, Quantum logic and entanglement by neutral rydberg atoms: methods and fidelity, Quantum Sci. Technol. 7, 023002 (2022)
work page 2022
- [8]
-
[9]
S. J. Evered, D. Bluvstein, M. Kalinowski, S. Ebadi, T. Manovitz, H. Zhou, S. H. Li, A. A. Geim, T. T. Wang, N. Maskara, H. Levine, G. Semeghini, M. Greiner, V. Vuletić, and M. D. Lukin, High-fidelity parallel entangling gates on a neutral-atom quantum computer, Nature 622, 268 (2023)
work page 2023
-
[10]
R. B.-S. Tsai, X. Sun, A. L. Shaw, R. Finkelstein, and M. Endres, Benchmarking and fidelity response theory of high-fidelity rydberg entangling gates, PRX Quantum 6, 010331 (2025)
work page 2025
-
[11]
B. Grinkemeyer, E. Guardado-Sanchez, I. Dimitrova, D. Shchepanovich, G. E. Mandopoulou, J. Borregaard, V. Vuletić, and M. D. Lukin, Error-detected quantum operations with neutral atoms mediated by an optical cavity, Science 387, 1301 (2025)
work page 2025
-
[12]
Z. Fu, P. Xu, Y. Sun, Y.-Y. Liu, X.-D. He, X. Li, M. Liu, R.-B. Li, J. Wang, L. Liu, and M.-S. Zhan, High-fidelity entanglement of neutral atoms via a rydberg-mediated single-modulated-pulse controlled-phase gate, Phys. Rev. A 105, 042430 (2022)
work page 2022
-
[13]
S. Jandura, J. D. Thompson, and G. Pupillo, Optimizing rydberg gates for logical-qubit performance, PRX Quantum 4, 020336 (2023)
work page 2023
-
[14]
R. Liu, X. Yang, and J. Li, Robust quantum optimal control for markovian quantum systems, Phys. Rev. A 110, 012402 (2024)
work page 2024
- [15]
-
[16]
M.-H. Zhang and J. Qian, Multiobjective optimization for robust holonomic quantum gates, Phys. Rev. A 112, 042620 (2025)
work page 2025
-
[17]
J. H. M. Jensen, J. J. Sørensen, K. Mølmer, and J. F. Sherson, Time-optimal control of collisional √swap gates in ultracold atomic systems, Phys. Rev. A 100, 052314 (2019)
work page 2019
-
[18]
S. Jandura and G. Pupillo, Time-optimal two-and three-qubit gates for rydberg atoms, Quantum 6, 712 (2022)
work page 2022
-
[19]
P.-Y. Song, J.-F. Wei, P. Xu, L.-L. Yan, M. Feng, S.-L. Su, and G. Chen, Fast realization of high-fidelity nonadiabatic holonomic quantum gates with a time-optimal-control technique in rydberg atoms, Phys. Rev. A 109, 022613 (2024)
work page 2024
-
[20]
G. Giudici, S. Veroni, G. Giudice, H. Pichler, and J. Zeiher, Fast entangling gates for rydberg atoms via resonant dipole- dipole interaction, PRX Quantum 6, 030308 (2025)
work page 2025
-
[21]
N. Khaneja, T. Reiss, C. Kehlet, T. Schulte-Herbrüggen, and S. J. Glaser, Optimal control of coupled spin dynamics: design of nmr pulse sequences by gradient ascent algorithms, J. Magn. Reson. 172, 296 (2005)
work page 2005
-
[23]
B. Shao, X. Yang, R. Liu, Y. Zhai, D. Lu, T. Xin, and J. Li, Multiple classical noise mitigation by multiobjective robust quantum optimal control, Phys. Rev. Appl. 21, 034042 (2024)
work page 2024
-
[24]
S. Fauquenot, A. Sarkar, and S. Feld, Open and closed loop approaches for energy efficient quantum optimal control, Adv. Quantum Technol. 8, 2400690 (2025)
work page 2025
-
[25]
Y. Song, J. Li, Y.-J. Hai, Q. Guo, and X.-H. Deng, Optimizing quantum control pulses with complex constraints and few variables through autodifferentiation, Phys. Rev. A 105, 012616 (2022) . 14
work page 2022
- [26]
- [27]
-
[28]
U. Las Heras, U. Alvarez-Rodriguez, E. Solano, and M. Sanz, Genetic algorithms for digital quantum simulations, Phys. Rev. Lett. 116, 230504 (2016)
work page 2016
-
[29]
G. Acampora, A. Chiatto, and A. Vitiello, Genetic algorithms as classical optimizer for the quantum approximate opti- mization algorithm, Appl. Soft Comput. 142, 110296 (2023)
work page 2023
-
[30]
W. Deng, S. Shang, X. Cai, H. Zhao, Y. Zhou, H. Chen, and W. Deng, Quantum differential evolution with cooperative coevolution framework and hybrid mutation strategy for large scale optimization, Knowledge-based Syst. 224, 107080 (2021)
work page 2021
-
[31]
A. Chernikov, S. S. Sysoev, E. A. Vashukevich, and T. Y. Golubeva, Heralded gate search with genetic algorithms for quantum computation, Phys. Rev. A 108, 012609 (2023)
work page 2023
-
[32]
A. Llenas and L. Lamata, Digital-analog quantum genetic algorithm using rydberg-atom arrays, Phys. Rev. A 110, 042603 (2024)
work page 2024
-
[33]
Z. Zhang, T.-W. Hsu, T. Y. Tan, D. H. Slichter, A. M. Kaufman, M. Marinelli, and C. A. Regal, High optical access cryogenic system for rydberg atom arrays with a 3000-second trap lifetime, PRX Quantum 6, 020337 (2025)
work page 2025
- [34]
-
[35]
S. Zeytinoğlu and S. Sugiura, Error-robust quantum signal processing using rydberg atoms, Phys. Rev. Res. 6, 013003 (2024)
work page 2024
-
[36]
X. Wang, S. Wang, X. Liang, D. Zhao, J. Huang, X. Xu, B. Dai, and Q. Miao, Deep reinforcement learning: A survey, IEEE Trans. Neural Netw. Learning Syst. 35, 5064 (2024)
work page 2024
-
[37]
V. N. Ivanova-Rohling, N. Rohling, and G. Burkard, Reinforcement learning approach for finding exchange-only gate sequences for cnot with optimized gate time, EPJ Quantum Technol. 12, 53 (2025)
work page 2025
- [38]
-
[39]
L. Moro, M. G. A. Paris, M. Restelli, and E. Prati, Quantum compiling by deep reinforcement learning, Commun. Phys. 4, 178 (2021)
work page 2021
-
[40]
S. Giordano and M. A. Martin-Delgado, Reinforcement-learning generation of four-qubit entangled states, Phys. Rev. Res. 4, 043056 (2022)
work page 2022
- [41]
-
[42]
V. V. Sivak, A. Eickbusch, H. Liu, B. Royer, I. Tsioutsios, and M. H. Devoret, Model-free quantum control with reinforce- ment learning, Phys. Rev. X 12, 011059 (2022)
work page 2022
-
[43]
R. Zen, J. Olle, L. Colmenarez, M. Puviani, M. Müller, and F. Marquardt, Quantum circuit discovery for fault-tolerant logical state preparation with reinforcement learning, Phys. Rev. X 15, 041012 (2025)
work page 2025
- [44]
-
[45]
S. Li, Y. Fan, X. Li, X. Ruan, Q. Zhao, Z. Peng, R.-B. Wu, J. Zhang, and P. Song, Robust quantum control using reinforcement learning from demonstration, npj Quantum Inf. 11, 124 (2025)
work page 2025
-
[46]
D. F. Wise, J. J. Morton, and S. Dhomkar, Using deep learning to understand and mitigate the qubit noise environment, PRX Quantum 2, 010316 (2021)
work page 2021
- [47]
-
[48]
L. Isenhower, E. Urban, X. L. Zhang, A. T. Gill, T. Henage, T. A. Johnson, T. G. Walker, and M. Saffman, Demonstration of a neutral atom controlled-not quantum gate, Phys. Rev. Lett. 104, 010503 (2010)
work page 2010
-
[49]
A. M. Farouk, I. I. Beterov, P. Xu, S. Bergamini, and I. I. Ryabtsev, Parallel implementation of CNOT N and C 2NOT2 gates via homonuclear and heteronuclear förster interactions of rydberg atoms, Photonics 10, 1280 (2023)
work page 2023
-
[50]
Y. Ding, Y. Ban, J. D. Martín-Guerrero, E. Solano, J. Casanova, and X. Chen, Breaking adiabatic quantum control with deep learning, Phys. Rev. A 103, L040401 (2021)
work page 2021
-
[51]
R. Porotti, A. Essig, B. Huard, and F. Marquardt, Deep reinforcement learning for quantum state preparation with weak nonlinear measurements, Quantum 6, 747 (2022)
work page 2022
-
[52]
J. P. Bonilla Ataides, D. K. Tuckett, S. D. Bartlett, S. T. Flammia, and B. J. Brown, The xzzx surface code, Nat. Commun. 12, 2172 (2021)
work page 2021
-
[53]
Y. Sun, P. Xu, P.-X. Chen, and L. Liu, Controlled phase gate protocol for neutral atoms via off-resonant modulated driving, Phys. Rev. Appl. 13, 024059 (2020)
work page 2020
-
[54]
Q. Wu, J. Xing, and H. Yin, Soft-controlled quantum gate with enhanced robustness and undegraded dynamics in rydberg atoms, EPJ Quantum Technol. 11, 1 (2024)
work page 2024
-
[55]
K. Zhao, W.-G. Ma, Z. Wang, H. Li, K. Huang, Y.-H. Shi, K. Xu, and H. Fan, Microwave-activated high-fidelity three-qubit gate scheme for fixed-frequency superconducting qubits, Phys. Rev. Appl. 24, 034064 (2025)
work page 2025
- [56]
-
[57]
Y. Baum, M. Amico, S. Howell, M. Hush, M. Liuzzi, P. Mundada, T. Merkh, A. R. Carvalho, and M. J. Biercuk, 15 Experimental deep reinforcement learning for error-robust gate-set design on a superconducting quantum computer, PRX Quantum 2, 040324 (2021)
work page 2021
- [58]
-
[59]
Y. Yin, T. Xiao, X. Deng, M. He, J. Fan, and G. Zeng, Discovering autonomous quantum error correction via deep reinforcement learning, Phys. Rev. A 112, 062618 (2025)
work page 2025
-
[60]
R. Lin, H.-S. Zhong, Y. Li, Z.-R. Zhao, L.-T. Zheng, T.-R. Hu, H.-M. Wu, Z. Wu, W.-J. Ma, Y. Gao, Y.-K. Zhu, Z.-F. Su, W.-L. Ouyang, Y.-C. Zhang, J. Rui, M.-C. Chen, C.-Y. Lu, and J.-W. Pan, Ai-enabled parallel assembly of thousands of defect-free neutral atom arrays, Phys. Rev. Lett. 135, 060602 (2025)
work page 2025
-
[61]
R.-B. Wu, B. Chu, D. H. Owens, and H. Rabitz, Data-driven gradient algorithm for high-precision quantum control, Phys. Rev. A 97, 042122 (2018)
work page 2018
-
[62]
D. Dong and I. R. Petersen, Quantum estimation, control and learning: Opportunities and challenges, Annu. Rev. Control. 54, 243 (2022)
work page 2022
-
[63]
R. S. Sutton, A. G. Barto, et al. , Reinforcement learning: An introduction , 1st ed. (MIT press Cambridge, Cambridge, MA, USA, 1998)
work page 1998
- [64]
-
[65]
M. S. Alam, N. F. Berthusen, and P. P. Orth, Quantum logic gate synthesis as a markov decision process, npj Quantum Inf. 9, 108 (2023)
work page 2023
-
[66]
Schmidhuber, Deep learning in neural networks: An overview, Neural Netw
J. Schmidhuber, Deep learning in neural networks: An overview, Neural Netw. 61, 85 (2015)
work page 2015
-
[67]
K. McDonnell, L. F. Keary, and J. D. Pritchard, Demonstration of a quantum gate using electromagnetically induced transparency, Phys. Rev. Lett. 129, 200501 (2022)
work page 2022
-
[68]
Y. Wu, S. Kolkowitz, S. Puri, and J. D. Thompson, Erasure conversion for fault-tolerant quantum computing in alkaline earth rydberg atom arrays, Nat. Commun. 13, 4657 (2022)
work page 2022
-
[69]
P. M. Poggi, F. C. Lombardo, and D. A. Wisniacki, Time-optimal control fields for quantum systems with multiple avoided crossings, Phys. Rev. A 92, 053411 (2015)
work page 2015
-
[70]
L. S. Theis, F. Motzoi, F. K. Wilhelm, and M. Saffman, High-fidelity rydberg-blockade entangling gate using shaped, analytic pulses, Phys. Rev. A 94, 032306 (2016)
work page 2016
- [71]
- [72]
-
[73]
R. Porotti, D. Tamascelli, M. Restelli, and E. Prati, Coherent transport of quantum states by deep reinforcement learning, Commun. Phys. 2, 61 (2019)
work page 2019
-
[74]
U. Boscain, M. Sigalotti, and D. Sugny, Introduction to the pontryagin maximum principle for quantum optimal control, PRX Quantum 2, 030203 (2021)
work page 2021
-
[75]
L. T. Brady, C. L. Baldwin, A. Bapat, Y. Kharkov, and A. V. Gorshkov, Optimal protocols in quantum annealing and quantum approximate optimization algorithm problems, Phys. Rev. Lett. 126, 070505 (2021)
work page 2021
-
[76]
Y. Oda, D. Lucarelli, K. Schultz, B. D. Clader, and G. Quiroz, Optimally band-limited noise filtering for single-qubit gates, Phys. Rev. Appl. 19, 014062 (2023)
work page 2023
- [77]
-
[78]
B. Sarma and M. J. Hartmann, Designing fast quantum gates using optimal control with a reinforcement-learning ansatz, Phys. Rev. Appl. 23, 014015 (2025)
work page 2025
-
[79]
J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, Trust region policy optimization, in Proc. Mach. Learn. Res., Vol. 37 (PMLR, Lille, France, 2015) pp. 1889–1897
work page 2015
-
[80]
B. J. Pearson, J. L. White, T. C. Weinacht, and P. H. Bucksbaum, Coherent control using adaptive learning algorithms, Phys. Rev. A 63, 063412 (2001)
work page 2001
-
[81]
T.-N. Xu, Y. Ding, J. D. Martín-Guerrero, and X. Chen, Robust two-qubit gate with reinforcement learning and dropout, Phys. Rev. A 110, 032614 (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.