Graph-SND: Sparse Aggregation for Behavioral Diversity in Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-08 16:34 UTC · model grok-4.3
The pith
Graph-SND measures behavioral diversity in agent teams by averaging distances only over edges of a chosen graph rather than every pair.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Graph-SND replaces the complete-graph average of SND with a weighted average over the edges of an arbitrary graph G. It recovers SND exactly when G equals the complete graph K_n, defines a localized O(|E|) measure for any fixed sparse G, and yields an unbiased Horvitz-Thompson estimator for random edge samples. For fixed sparse graphs the paper proves forwarding-index distortion bounds for expanders and a spectral refinement under low-rank distance structure; for random d-regular graphs it proves an unconditional probabilistic bound of order O(D_max / sqrt(n)).
What carries the argument
Graph-SND, the weighted average of pairwise behavioral distances taken only over the edges of an arbitrary graph G
If this is right
- Diversity measurement becomes linear in the number of edges for any fixed sparse graph instead of quadratic in team size.
- Random edge sampling produces an unbiased estimator whose error concentrates as O(1/sqrt(m)) in the number of samples m.
- Expander graphs and low-rank distance matrices keep the sparse approximation within explicit distortion bounds.
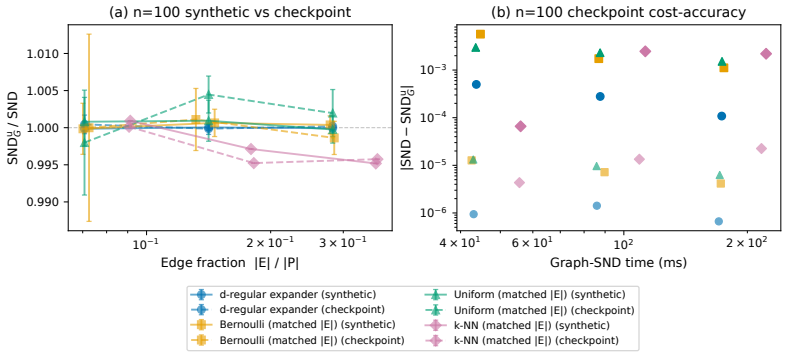
- A Bernoulli-0.1 edge sample matches full SND within 0.13 percent while cutting metric time by about 10x in n=100 PPO runs.
- The same sparse measure can be dropped into closed-loop diversity control without changing the underlying semantics.
Where Pith is reading between the lines
- The same edge-sampling idea could be applied to other pairwise statistics in multi-agent settings such as cooperation or conflict measures.
- Random regular expanders at Theta(n log n) edges appear sufficient for near-exact recovery even without assuming low-rank structure on the distances.
- The speedup factor of order binom(n,2)/|E| suggests the method remains practical up to team sizes of several hundred agents on current hardware.
- If the distance matrix is approximately low-rank in real tasks, even fewer edges than the expander bound may suffice.
Load-bearing premise
The matrix of distances between agent behaviors has enough low-rank or expander-friendly structure that averages over a sparse or sampled graph stay close to the full pairwise average.
What would settle it
Compute both full SND and Graph-SND on teams of 100 agents whose behaviors produce a distance matrix without low-rank structure and check whether their ratio deviates from 1 by more than the stated O(D_max / sqrt(n)) bound with higher probability than predicted.
Figures











read the original abstract
System Neural Diversity (SND) measures behavioral heterogeneity in multi-agent reinforcement learning by averaging pairwise distances over all $\binom{n}{2}$ agent pairs, making each call quadratic in team size. We introduce Graph-SND, which replaces this complete-graph average with a weighted average over the edges of an arbitrary graph $G$. Three regimes follow: $G=K_n$ recovers SND exactly; a fixed sparse $G$ defines a localized diversity measure at $O(|E|)$ cost; and random edge samples yield an unbiased Horvitz-Thompson estimator and a normalized sample mean with $O(1/\sqrt{m})$ concentration in the sampled edge count $m$. For fixed sparse graphs we prove forwarding-index distortion bounds for expanders and a spectral refinement under low-rank distance structure; for random $d$-regular graphs we prove an unconditional probabilistic $\widetilde{\mathcal{O}}(D_{\max}/\sqrt{n})$ bound. On VMAS we verify recovery, unbiasedness, concentration, and wall-clock scaling, with a PettingZoo TVD panel checking non-Gaussian transfer. In a 500-iteration $n=100$ PPO run, Bernoulli-$0.1$ Graph-SND tracks full SND while reducing per-call metric time by about $10\times$, and frozen-policy GPU timing up to $n=500$ follows the predicted $\binom{n}{2}/|E|$ speedup. Random $d$-regular expanders empirically achieve $\mathrm{SND}_{G}^{\mathrm{u}}/\mathrm{SND} \in [0.9987, 1.0013]$ at $\Theta(n \log n)$ edges. In DiCo diversity control at $n=50$, Bernoulli-$0.1$ Graph-SND preserves set-point tracking with paired reward differences indistinguishable from zero across nine matched cells while cutting per-call metric cost by ${\sim}9.5\times$. Together, these results show that the SND aggregation bottleneck can be removed without changing the metric's semantics, yielding a drop-in sparse alternative that scales beyond complete-graph SND and supports both passive measurement and closed-loop diversity control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Graph-SND, which generalizes System Neural Diversity (SND) by replacing the quadratic complete-graph average of pairwise behavioral distances with a weighted average over the edges of an arbitrary graph G. It establishes exact recovery of SND when G = K_n, an unbiased Horvitz-Thompson estimator under random edge sampling with O(1/sqrt(m)) concentration, forwarding-index distortion bounds for expanders, a spectral refinement under low-rank distance structure, and an unconditional probabilistic O~(D_max/sqrt(n)) bound for random d-regular graphs. Experiments on VMAS verify recovery, unbiasedness, concentration, and scaling (including 10x speedup at n=100 and up to n=500), while DiCo closed-loop diversity control at n=50 shows indistinguishable reward outcomes with ~9.5x cost reduction; random d-regular expanders empirically achieve ratios in [0.9987, 1.0013].
Significance. If the stated theorems hold, the work removes the quadratic aggregation bottleneck in SND while preserving semantics, enabling diversity measurement and control at larger team sizes in MARL. Strengths include the exact-recovery guarantee, unbiased estimator, explicit distortion bounds (expanders, spectral, unconditional regular-graph), and reproducible empirical tracking on VMAS/PettingZoo and DiCo with closed-loop verification. This combination of parameter-light theory and scaling experiments positions the method as a practical drop-in replacement.
major comments (2)
- [Abstract] Abstract (theorems paragraph): the unconditional probabilistic bound O~(D_max/sqrt(n)) for random d-regular graphs is load-bearing for the claim that sparse Graph-SND remains faithful at scale; the manuscript should state the precise theorem (including any hidden constants or logarithmic factors) and the proof sketch, as the current summary invokes standard expander properties without showing how they combine with the distance matrix to yield this rate.
- [Spectral refinement and expander sections] Spectral refinement and expander sections: the distortion bounds invoke low-rank or expander-friendly structure on the distance matrix, yet the VMAS experiments report only aggregate ratios without reporting the observed rank or eigenvalue decay of the distance matrices; this leaves the applicability of the refinement bounds unverified for the tested regimes.
minor comments (2)
- [Introduction] Notation: the symbols SND_G^u and the precise weighting scheme for arbitrary G should be defined at first use in the introduction rather than deferred to the methods section.
- [Experiments] Experiments: the PettingZoo TVD panel and the nine matched DiCo cells would benefit from explicit reporting of the number of random seeds and the exact statistical test used to declare reward differences 'indistinguishable from zero'.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. The two major comments identify opportunities to improve the precision of the theoretical claims and the empirical verification of the underlying assumptions. We address each comment below and will incorporate the requested clarifications and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (theorems paragraph): the unconditional probabilistic bound O~(D_max/sqrt(n)) for random d-regular graphs is load-bearing for the claim that sparse Graph-SND remains faithful at scale; the manuscript should state the precise theorem (including any hidden constants or logarithmic factors) and the proof sketch, as the current summary invokes standard expander properties without showing how they combine with the distance matrix to yield this rate.
Authors: We agree that a more explicit statement strengthens the abstract. The current use of the tilde-O notation hides polylogarithmic factors that arise from the expander mixing time and the concentration bounds applied to the distance matrix. In the revision we will update the abstract to state the bound as O~(D_max polylog(n)/sqrt(n)) and will add a concise proof sketch in the main theoretical section on random d-regular graphs. The sketch will explicitly combine the forwarding-index distortion for d-regular expanders with the maximum distance D_max via the spectral gap to obtain the stated rate, making the derivation transparent. revision: yes
-
Referee: [Spectral refinement and expander sections] Spectral refinement and expander sections: the distortion bounds invoke low-rank or expander-friendly structure on the distance matrix, yet the VMAS experiments report only aggregate ratios without reporting the observed rank or eigenvalue decay of the distance matrices; this leaves the applicability of the refinement bounds unverified for the tested regimes.
Authors: This observation is correct and points to a useful addition. To verify that the low-rank and expander-friendly assumptions hold in the regimes tested, we will augment the VMAS experimental section with an analysis of the behavioral distance matrices. We will report the effective numerical rank (eigenvalues above a small threshold) and the eigenvalue decay profiles for representative distance matrices drawn from the VMAS environments. These diagnostics will allow readers to assess the applicability of the spectral refinement and expander bounds to the observed approximation ratios. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation begins from the pre-existing SND definition (pairwise behavioral distance average) and replaces the complete-graph sum with a weighted sum over edges of an arbitrary graph G. Exact recovery on G = K_n follows immediately by definition of the weights. All subsequent claims—unbiasedness of the Horvitz-Thompson estimator under random edge sampling, O(1/sqrt(m)) concentration, expander distortion bounds, spectral low-rank refinement, and the unconditional O(D_max/sqrt(n)) bound for random d-regular graphs—are obtained by direct application of standard, externally established results in sampling theory and spectral graph theory. No equation reduces a reported diversity value to a parameter fitted on the same data, no ansatz is smuggled via self-citation, and no uniqueness theorem is imported from the authors' prior work to force the construction. The paper therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bernoulli sampling probability =
0.1
axioms (2)
- standard math Horvitz-Thompson estimator yields unbiased estimates under random edge sampling
- standard math Forwarding-index and spectral properties of expanders bound distortion for low-rank distance matrices
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , year =
Matteo Bettini and Ajay Shankar and Amanda Prorok , title =. Journal of Machine Learning Research , year =
-
[2]
Matteo Bettini and Ajay Shankar and Amanda Prorok , title =. Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
-
[3]
Forty-first International Conference on Machine Learning (ICML) , year =
Matteo Bettini and Ryan Kortvelesy and Amanda Prorok , title =. Forty-first International Conference on Machine Learning (ICML) , year =
-
[4]
Matteo Bettini and Ryan Kortvelesy and Jan Blumenkamp and Amanda Prorok , title =. Proceedings of the 16th International Symposium on Distributed Autonomous Robotic Systems (DARS) , publisher =
-
[5]
arXiv preprint arXiv:2506.09434 , year=
M. Amir and Matteo Bettini and Amanda Prorok , title =. arXiv preprint arXiv:2506.09434 , year =
-
[6]
arXiv preprint arXiv:2412.16244 , year=
Matteo Bettini and Ryan Kortvelesy and Amanda Prorok , title =. arXiv preprint arXiv:2412.16244 , year =
- [7]
- [8]
-
[9]
Kevin R. McKee and Joel Z. Leibo and Charlie Beattie and Richard Everett , title =. Autonomous Agents and Multi-Agent Systems , year =
-
[10]
International Conference on Machine Learning (ICML) , year =
Siyi Hu and Chuanlong Xie and Xiaodan Liang and Xiaojun Chang , title =. International Conference on Machine Learning (ICML) , year =
-
[11]
Jack Parker-Holder and Aldo Pacchiano and Krzysztof M. Choromanski and Stephen J. Roberts , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[12]
International Conference on Machine Learning (ICML) , year =
Andrei Lupu and Brandon Cui and Hengyuan Hu and Jakob Foerster , title =. International Conference on Machine Learning (ICML) , year =
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Xiangyu Liu and Hangtian Jia and Ying Wen and Yujing Hu and Yingfeng Chen and Changjie Fan and Zhipeng Hu and Yaodong Yang , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[14]
arXiv preprint arXiv:2106.05802 , year =
Yifan Yu and Haobin Jiang and Zongqing Lu , title =. arXiv preprint arXiv:2106.05802 , year =
-
[15]
Ani Hsieh and Vijay Kumar , title =
Amanda Prorok and M. Ani Hsieh and Vijay Kumar , title =. IEEE Transactions on Robotics , year =
-
[16]
Conference on Robot Learning (CoRL) , year =
Jan Blumenkamp and Amanda Prorok , title =. Conference on Robot Learning (CoRL) , year =
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Sainbayar Sukhbaatar and Arthur Szlam and Rob Fergus , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[18]
International Conference on Machine Learning (ICML) , year =
Tonghan Wang and Heng Dong and Victor Lesser and Chongjie Zhang , title =. International Conference on Machine Learning (ICML) , year =
-
[19]
International Conference on Learning Representations (ICLR) , year =
Tonghan Wang and Tarun Gupta and Bei Peng and Anuj Mahajan and Shimon Whiteson and Chongjie Zhang , title =. International Conference on Learning Representations (ICLR) , year =
-
[20]
American Control Conference (ACC) , year =
Philip Twu and Yasamin Mostofi and Magnus Egerstedt , title =. American Control Conference (ACC) , year =
-
[21]
Ling Li and Alcherio Martinoli and Yaser S. Abu-Mostafa , title =. Adaptive Behavior , year =
-
[22]
Stanley and Jeff Clune and Joel Lehman and Risto Miikkulainen , title =
Kenneth O. Stanley and Jeff Clune and Joel Lehman and Risto Miikkulainen , title =. Nature Machine Intelligence , year =
-
[23]
Journal of the American Statistical Association , year =
Wassily Hoeffding , title =. Journal of the American Statistical Association , year =
-
[24]
The Annals of Mathematical Statistics , year =
Wassily Hoeffding , title =. The Annals of Mathematical Statistics , year =
-
[25]
Daniel G. Horvitz and Donovan J. Thompson , title =. Journal of the American Statistical Association , year =
- [26]
-
[27]
Concentration Inequalities for Sampling Without Replacement , journal =
R. Concentration Inequalities for Sampling Without Replacement , journal =. 2015 , volume =
work page 2015
-
[28]
Fan R. K. Chung and Edward G. Coffman and Martin I. Reiman and Burton Simons , title =. IEEE Transactions on Information Theory , year =
-
[29]
Discrete Applied Mathematics , year =
Marie-Claude Heydemann and Jean-Claude Meyer and Dominique Sotteau , title =. Discrete Applied Mathematics , year =
-
[30]
Tom Leighton and Satish Rao , title =. Journal of the ACM , year =
-
[31]
Memoirs of the American Mathematical Society , year =
Joel Friedman , title =. Memoirs of the American Mathematical Society , year =
-
[32]
A Probabilistic Proof of an Asymptotic Formula for the Number of Labelled Regular Graphs , journal =
B. A Probabilistic Proof of an Asymptotic Formula for the Number of Labelled Regular Graphs , journal =. 1980 , volume =
work page 1980
- [33]
-
[34]
Surveys in Combinatorics , series =
Colin McDiarmid , title =. Surveys in Combinatorics , series =
-
[35]
Leslie Pack Kaelbling and Michael L. Littman and Anthony R. Cassandra , title =. Artificial Intelligence , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.