Recognition: unknown
Seeing What Shouldn't Be There: Counterfactual GANs for Medical Image Attribution
Pith reviewed 2026-05-08 16:42 UTC · model grok-4.3
The pith
A cycle-consistent GAN generates counterfactual medical images to provide complete class-oriented feature attributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A counterfactual explanation based class-oriented feature attribution method is built on generative adversarial networks with a cyclical-consistent loss function to generate plausible counterfactual instances whose differences from the original image highlight causally relevant features for medical image classification. This overcomes the incompleteness of discriminative visualization methods that rely on minimal feature sets and addresses the implausibility issues in prior counterfactual techniques. Experiments across synthetic, tuberculosis, and BraTS datasets confirm the method's efficacy, and it establishes baseline results on BraTS while introducing a novel evaluation for counterfactual
What carries the argument
Cycle-consistent generative adversarial networks that produce counterfactual instances to enable self-explanatory analogy-based explanations by altering images in ways that flip the classifier output.
If this is right
- The method visualizes deformities in medical images more comprehensively than minimal-feature approaches.
- It supplies self-explanatory analogy-based explanations for radiologists.
- Existing counterfactual techniques are shown to produce implausible instances, limiting their utility.
- Baseline performance is established on the BraTS dataset for future comparisons.
Where Pith is reading between the lines
- Clinicians could compare original and altered images directly to verify AI-driven diagnoses.
- The technique might apply to other image classification tasks where showing missing features aids interpretability.
- Minimizing generator artifacts could further increase reliability in high-stakes medical settings.
Load-bearing premise
The cycle-consistent GAN produces plausible counterfactual instances whose differences from the original image correspond to causally relevant features rather than artifacts of the generator.
What would settle it
A test showing that the generated counterfactual images either fail to change the classifier prediction as expected or contain visible artifacts unrelated to known medical pathologies in the tuberculosis or BraTS data would falsify the claim of effective feature attribution.
Figures

















read the original abstract
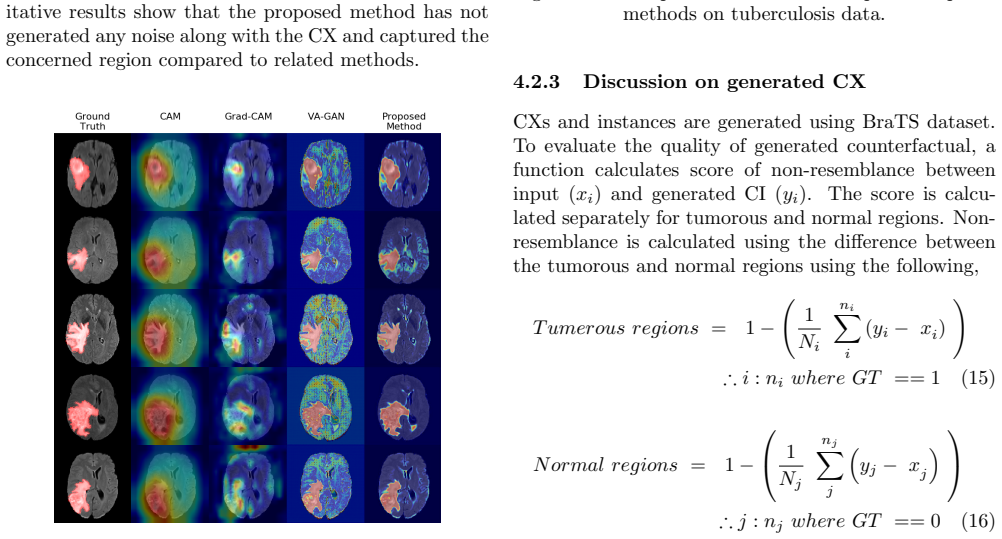
Ascription of an image gives insights into the objects that influence the classification of the whole image or its pixels towards a specific category. These insights help radiologists to visualize deformities in medical imaging. Most of the existing visualization techniques are based on discriminative models and highlight regions of the input image participating in the decision-making of a classifier. However, these approaches do not take all noticeable objects into account as their objective is to classify the input by using a minimal set of discriminative features. To overcome the issue, a counterfactual explanation (CX) based class-oriented feature attribution method is proposed. A counterfactual explanation (CX) explicates a causal reasoning process of the form: "if X had not happened, then Y would not have happened". The method is built on generative adversarial networks (GANs) with a cyclical-consistent loss function. We evaluate our method on three datasets: synthetic, tuberculosis and BraTS. All experiments confirm the efficacy of the proposed method. This study also highlighted the limitations of existing counterfactual explanation techniques in producing plausible counterfactual instances (CIs). Accompanying CXs with believable CIs thus provides self-explanatory analogy-based explanations. To this end, a CI generation method is proposed. Also, a novel technique is used to evaluate the quality of CI. The baseline results are produced on the BraTS dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a counterfactual explanation (CX) based class-oriented feature attribution method for medical images, constructed using generative adversarial networks (GANs) with a cycle-consistent loss. The method generates plausible counterfactual instances (CIs) of the opposite class and derives attribution maps by subtracting these from the input image, aiming to highlight causally relevant features rather than minimal discriminative ones used by prior visualization techniques. It evaluates the approach on synthetic data, a tuberculosis dataset, and the BraTS dataset, claims to confirm efficacy across all experiments, highlights limitations of existing CX techniques, introduces a novel CI quality evaluation technique, and provides baseline results on BraTS.
Significance. If the empirical claims hold under rigorous validation, the work could meaningfully advance interpretable machine learning for medical imaging by shifting from purely discriminative attributions to counterfactual ones that offer self-explanatory, analogy-based insights. This addresses a documented shortcoming in prior CX methods regarding plausibility of generated instances and could improve clinical utility for radiologists by better aligning attributions with disease-relevant anatomy.
major comments (3)
- [Abstract] Abstract: the statement 'All experiments confirm the efficacy of the proposed method' is unsupported by any reported quantitative metrics, ablation studies, error analysis, or statistical comparisons, so the central efficacy claim rests on unshown details.
- [Experiments] Evaluation on three datasets: no quantitative checks (e.g., classifier re-evaluation on edited images, expert segmentation overlap with known causal features, or comparison against ground-truth interventions) are described to verify that pixel differences isolate disease features rather than GAN artifacts or unrelated anatomy changes, leaving the attribution validity untested.
- [Experiments] BraTS baseline results: while baselines are mentioned, the absence of specific performance numbers, tables, or direct comparisons to prior CX techniques prevents assessment of whether the cycle-consistent GAN approach improves upon existing methods.
minor comments (2)
- [Abstract] The phrasing 'cyclical-consistent loss function' should be corrected to the standard term 'cycle-consistent loss' for consistency with the literature.
- [Method] Notation for the attribution map computation (input minus counterfactual) could be formalized with an equation to improve clarity.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below, agreeing where revisions are needed to improve clarity and rigor while defending the core contributions based on the presented evaluations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement 'All experiments confirm the efficacy of the proposed method' is unsupported by any reported quantitative metrics, ablation studies, error analysis, or statistical comparisons, so the central efficacy claim rests on unshown details.
Authors: We agree that the abstract phrasing overstates the support, as the evaluations are primarily qualitative (visual assessment of plausible CIs and attribution maps) along with the novel CI quality technique. We will revise the abstract to state that the experiments illustrate the method's potential via visual results on the three datasets, without claiming comprehensive confirmation of efficacy. revision: yes
-
Referee: [Experiments] Evaluation on three datasets: no quantitative checks (e.g., classifier re-evaluation on edited images, expert segmentation overlap with known causal features, or comparison against ground-truth interventions) are described to verify that pixel differences isolate disease features rather than GAN artifacts or unrelated anatomy changes, leaving the attribution validity untested.
Authors: The current manuscript does not describe such quantitative checks, focusing instead on visual demonstrations and the proposed CI quality evaluation to highlight advantages over prior CX methods. We acknowledge this leaves room for questions about artifacts. We will add a limitations discussion and incorporate at least one quantitative validation, such as classifier output changes after region editing, in the revision. revision: partial
-
Referee: [Experiments] BraTS baseline results: while baselines are mentioned, the absence of specific performance numbers, tables, or direct comparisons to prior CX techniques prevents assessment of whether the cycle-consistent GAN approach improves upon existing methods.
Authors: The manuscript references baseline results on BraTS but omits specific numbers and tables, which was an incomplete presentation. We will expand this section with quantitative metrics, tables, and direct comparisons to prior CX techniques to allow assessment of improvements. revision: yes
Circularity Check
No circularity: novel construction from standard components with empirical evaluation
full rationale
The paper introduces a counterfactual explanation method built on CycleGAN-style generators with cycle-consistent loss for producing class-oriented attributions via image subtraction. No load-bearing equations, fitted parameters renamed as predictions, or self-citations appear in the provided abstract or description that would reduce the central claim to its own inputs by construction. The derivation is presented as an original assembly of existing GAN techniques, with efficacy shown through experiments on synthetic, TB, and BraTS datasets rather than tautological re-derivation. This qualifies as a self-contained proposal without detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
General Data Protection Regulation, 2016
European Commission. General Data Protection Regulation, 2016
2016
-
[2]
Bakas, H
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. S. Kirby, J. B. Freymann, K. Fara- hani, and C. Davatzikos. Advancing the cancer genome atlas glioma mri collections with expert segmentation labels and radiomic features.Scien- tific data, 4:170117, 2017
2017
-
[3]
C. F. Baumgartner, K. Kamnitsas, J. Matthew, T. P. Fletcher, S. Smith, L. M. Koch, B. Kainz, and D. Rueckert. Sononet: real-time detection and lo- calisation of fetal standard scan planes in freehand ultrasound.IEEE transactions on medical imaging, 36(11):2204–2215, 2017
2017
-
[4]
C. F. Baumgartner, K. Kamnitsas, J. Matthew, S. Smith, B. Kainz, and D. Rueckert. Real-time standard scan plane detection and localisation in fe- tal ultrasound using fully convolutional neural net- works. InInternational Conference on Medical Im- age Computing and Computer-Assisted Interven- tion, pages 203–211. Springer, 2016
2016
-
[5]
C. F. Baumgartner, L. M. Koch, K. Can Tezcan, J. Xi Ang, and E. Konukoglu. Visual feature attri- bution using wasserstein gans. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8309–8319, 2018. 14 [S. Murtaza]
2018
-
[6]
Bernal, K
J. Bernal, K. Kushibar, D. S. Asfaw, S. Valverde, A. Oliver, R. Mart´ ı, and X. Llad´ o. Deep convolu- tional neural networks for brain image analysis on magnetic resonance imaging: a review.Artificial intelligence in medicine, 95:64–81, 2019
2019
-
[7]
Carter, Z
S. Carter, Z. Armstrong, L. Schubert, I. Johnson, and C. Olah. Activation atlas.Distill, 4(3):e15, 2019
2019
-
[8]
D. V. Carvalho, E. M. Pereira, and J. S. Car- doso. Machine learning interpretability: A sur- vey on methods and metrics.Electronics, 8(8):832, 2019
2019
-
[9]
Chang, E
C.-H. Chang, E. Creager, A. Goldenberg, and D. Duvenaud. Explaining image classifiers by coun- terfactual generation. 2018
2018
-
[10]
Ciaparrone, F
G. Ciaparrone, F. L. S´ anchez, S. Tabik, L. Troiano, R. Tagliaferri, and F. Herrera. Deep learning in video multi-object tracking: A survey.Neurocom- puting, 2019
2019
-
[11]
Dabkowski and Y
P. Dabkowski and Y. Gal. Real time image saliency for black box classifiers. InAdvances in Neural Information Processing Systems, pages 6967–6976, 2017
2017
-
[12]
Dhurandhar, P.-Y
A. Dhurandhar, P.-Y. Chen, R. Luss, C.-C. Tu, P. Ting, K. Shanmugam, and P. Das. Explanations based on the missing: Towards contrastive explana- tions with pertinent negatives. InAdvances in Neu- ral Information Processing Systems, pages 592–603, 2018
2018
-
[13]
X. Feng, J. Yang, A. F. Laine, and E. D. An- gelini. Discriminative localization in cnns for weakly-supervised segmentation of pulmonary nod- ules. InInternational Conference on Medical Im- age Computing and Computer-Assisted Interven- tion, pages 568–576. Springer, 2017
2017
-
[14]
R. C. Fong and A. Vedaldi. Interpretable explana- tions of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, pages 3429–3437, 2017
2017
-
[15]
A. A. Freitas. A critical review of multi-objective optimization in data mining: a position paper. ACM SIGKDD Explorations Newsletter, 6(2):77– 86, 2004
2004
-
[16]
Comprehensible classification mod- els: a position paper.ACM SIGKDD explorations newsletter, 15(1):1–10, 2014
Freitas, Alex A. Comprehensible classification mod- els: a position paper.ACM SIGKDD explorations newsletter, 15(1):1–10, 2014
2014
-
[17]
Gao and J
Y. Gao and J. A. Noble. Detection and characteri- zation of the fetal heartbeat in free-hand ultrasound sweeps with weakly-supervised two-streams convo- lutional networks. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 305–313. Springer, 2017
2017
-
[18]
Z. Ge, S. Demyanov, R. Chakravorty, A. Bowl- ing, and R. Garnavi. Skin disease recognition us- ing deep saliency features and multimodal learn- ing of dermoscopy and clinical images. InInter- national Conference on Medical Image Computing and Computer-Assisted Intervention, pages 250–
-
[19]
L. H. Gilpin, D. Bau, B. Z. Yuan, A. Bajwa, M. Specter, and L. Kagal. Explaining explanations: An overview of interpretability of machine learning. In2018 IEEE 5th International Conference on data science and advanced analytics (DSAA), pages 80–
-
[20]
Girshick, J
R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detec- tion and semantic segmentation. InProceedings of the IEEE conference on computer vision and pat- tern recognition, pages 580–587, 2014
2014
-
[21]
W. M. Gondal, J. M. K¨ ohler, R. Grzeszick, G. A. Fink, and M. Hirsch. Weakly-supervised localiza- tion of diabetic retinopathy lesions in retinal fundus images. In2017 IEEE International Conference on Image Processing (ICIP), pages 2069–2073. IEEE, 2017
2069
-
[22]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. InAd- vances in neural information processing systems, pages 2672–2680, 2014
2014
-
[23]
What do we need to build explainable AI systems for the medical domain?
A. Holzinger, C. Biemann, C. S. Pattichis, and D. B. Kell. What do we need to build explainable ai systems for the medical domain?arXiv preprint arXiv:1712.09923, 2017
work page Pith review arXiv 2017
-
[24]
Isola, J.-Y
P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adver- sarial networks. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 1125–1134, 2017
2017
-
[25]
Jaeger, S
S. Jaeger, S. Candemir, S. Antani, Y.-X. J. W´ ang, P.-X. Lu, and G. Thoma. Two public chest x- ray datasets for computer-aided screening of pul- monary diseases.Quantitative imaging in medicine and surgery, 4(6):475, 2014. 15 [S. Murtaza]
2014
-
[26]
Karpathy and L
A. Karpathy and L. Fei-Fei. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3128–3137, 2015
2015
- [27]
-
[28]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Im- agenet classification with deep convolutional neural networks. InAdvances in neural information pro- cessing systems, pages 1097–1105, 2012
2012
-
[29]
LeCun, Y
Y. LeCun, Y. Bengio, and G. Hinton. Deep learn- ing.nature, 521(7553):436–444, 2015
2015
-
[31]
Z. C. Lipton. The mythos of model interpretability. arXiv preprint arXiv:1606.03490, 2016
work page Pith review arXiv 2016
-
[32]
L. v. d. Maaten and G. Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
2008
-
[33]
B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy- Cramer, K. Farahani, J. Kirby, Y. Burren, N. Porz, J. Slotboom, R. Wiest, et al. The multi- modal brain tumor image segmentation benchmark (brats).IEEE transactions on medical imaging, 34(10):1993–2024, 2014
1993
-
[34]
T. Miller. Explanation in artificial intelligence: In- sights from the social sciences.Artificial Intelli- gence, 267:1–38, 2019
2019
-
[35]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero. Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784, 2014
work page internal anchor Pith review arXiv 2014
-
[36]
Molnar.Interpretable machine learning
C. Molnar.Interpretable machine learning. Lulu. com, 2019
2019
-
[37]
Murtaza, S
S. Murtaza, S. Belharbi, M. A. Guichemerre, M. Pedersoli, and E. Granger. Ted-loc: Text dis- tillation for weakly supervised object localization. CoRR, 2025
2025
-
[38]
Murtaza, S
S. Murtaza, S. Belharbi, M. Pedersoli, and E. Granger. A realistic protocol for evaluation of weakly supervised object localization. InWACV, 2025
2025
-
[39]
Murtaza, S
S. Murtaza, S. Belharbi, M. Pedersoli, A. Sarraf, and E. Granger. DIPS: Discriminative pseudo- label sampling with self-supervised transformers for weakly supervised object localization.IVC Journal, 2023
2023
-
[40]
Murtaza, S
S. Murtaza, S. Belharbi, M. Pedersoli, A. Sarraf, and E. Granger. Discriminative sampling of pro- posals in self-supervised transformers for weakly su- pervised object localization. InWACV Workshop, 2023
2023
-
[41]
Murtaza, M
S. Murtaza, M. Pedersoli, A. Sarraf, and E. Granger. Leveraging transformers for weakly supervised object localization in unconstrained videos. InIAPRw, 2024
2024
-
[42]
J. E. D. B. D. Parikh, S. L. Y. Goyal, and Z. Wu. Counterfactual visual explanations. ICML, 2019
2019
-
[43]
Plumb, D
G. Plumb, D. Molitor, and A. S. Talwalkar. Model agnostic supervised local explanations. InAdvances in Neural Information Processing Systems, pages 2515–2524, 2018
2018
-
[44]
M. T. Ribeiro, S. Singh, and C. Guestrin. Why should i trust you?: Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144. ACM, 2016
2016
-
[45]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image seg- mentation. InInternational Conference on Medical image computing and computer-assisted interven- tion, pages 234–241. Springer, 2015
2015
-
[46]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[47]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedan- tam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE Interna- tional Conference on Computer Vision, pages 618– 626, 2017
2017
-
[49]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv preprint arXiv:1312.6034, 2013
work page Pith review arXiv 2013
- [50]
-
[51]
Sundararajan, A
M. Sundararajan, A. Taly, and Q. Yan. Axiomatic attribution for deep networks. InProceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3319–3328. JMLR. org, 2017
2017
-
[52]
Vinyals, A
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: A neural image caption generator. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3156–3164, 2015
2015
- [53]
-
[54]
J. Yosinski, J. Clune, A. Nguyen, T. Fuchs, and H. Lipson. Understanding neural net- works through deep visualization.arXiv preprint arXiv:1506.06579, 2015
- [55]
-
[56]
M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. InEuro- pean conference on computer vision, pages 818–833. Springer, 2014
2014
-
[57]
Zhang, S
J. Zhang, S. A. Bargal, Z. Lin, J. Brandt, X. Shen, and S. Sclaroff. Top-down neural attention by ex- citation backprop.International Journal of Com- puter Vision, 126(10):1084–1102, 2018
2018
-
[58]
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discrimina- tive localization. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2921–2929, 2016
2016
-
[59]
J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProceedings of the IEEE international conference on computer vi- sion, pages 2223–2232, 2017
2017
- [60]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.