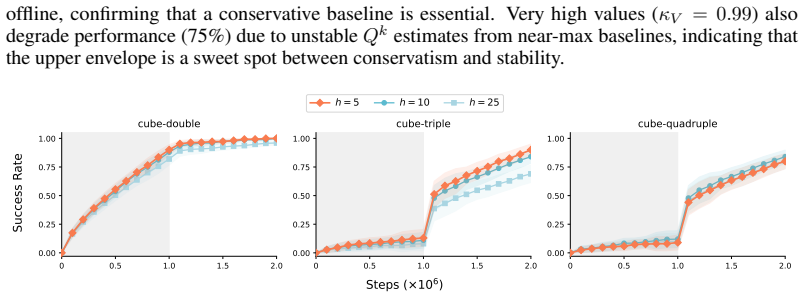
Recognition: unknown
Adaptive Q-Chunking for Offline-to-Online Reinforcement Learning
Pith reviewed 2026-05-08 15:06 UTC · model grok-4.3
The pith
Adaptive Q-Chunking selects chunk sizes by comparing normalized advantages to a per-horizon baseline, delivering better performance than fixed sizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Adaptive Q-Chunking (AQC), which resolves both failures by comparing the advantage of each chunk size relative to a per-horizon baseline, normalized by the discount factor. This criterion converts biased wrong answers into unbiased near-random choices when no genuine signal exists, and becomes discriminative when a particular scale enables better planning. We prove theoretical bounds on the advantage selector's noise immunity and on the value dominance of adaptive chunking over any fixed chunk size. We demonstrate that AQC achieves state-of-the-art offline and online success rates on OGBench and Robomimic, and can be applied to enhance the performance of large-scale VLA models.
What carries the argument
the advantage selector that compares the advantage of each chunk size relative to a per-horizon baseline and normalizes by the discount factor
If this is right
- Adaptive chunking dominates any fixed chunk size in expected value.
- The selector maintains performance even when critic estimates contain substantial noise.
- AQC delivers state-of-the-art results on OGBench and Robomimic for both offline and online phases.
- The technique improves large-scale VLA models on complex robotic tasks such as those in RoboCasa-GR1.
Where Pith is reading between the lines
- The same normalization principle might help other variable-horizon or multi-scale decision problems in RL.
- In practice, AQC could reduce the need for manual tuning of chunk size hyperparameters across different tasks.
- Extensions to continuous chunk size selection or learned chunk predictors seem natural next steps.
Load-bearing premise
That comparing advantages relative to per-horizon baselines and normalizing by the discount factor reliably converts biased critic values into unbiased or near-random selections in low-signal states without introducing new biases or depending on unstated properties of the learned value functions.
What would settle it
An experiment that measures selection frequencies in low-value states and checks whether the distribution remains near-uniform random under the normalized advantage rule, or that compares final policy returns of AQC against the best fixed chunk size on the same trained critics.
Figures









read the original abstract
Offline-to-online reinforcement learning with action chunking eliminates multi-step off-policy bias and enables temporally coherent exploration, but all existing methods use a fixed chunk size across every state. This is suboptimal: near contact events the agent needs short chunks for reactive control, while during free-space motion long chunks provide better credit assignment. The natural solution is to train critics for several chunk sizes and select the best one at each state, but naive comparison of learned critic values systematically collapses to the shortest chunk due to discount-scale mismatch, and degrades to noise in low-value states. We propose Adaptive Q-Chunking (AQC), which resolves both failures by comparing the advantage of each chunk size relative to a per-horizon baseline, normalized by the discount factor. This criterion converts biased wrong answers into unbiased near-random choices when no genuine signal exists, and becomes discriminative when a particular scale enables better planning. We prove theoretical bounds on the advantage selector's noise immunity and on the value dominance of adaptive chunking over any fixed chunk size. We demonstrate that AQC achieves state-of-the-art offline and online success rates on OGBench and Robomimic, and can be applied to enhance the performance of large-scale VLA models that predict action sequences, significantly boosting performance on RoboCasa-GR1 tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Adaptive Q-Chunking (AQC) for offline-to-online RL using action chunking. It claims that fixed chunk sizes are suboptimal for different states (e.g., short for contact, long for free motion), and that direct comparison of Q-values fails due to discount factor scaling and noise in low-value states. AQC selects chunk size by comparing normalized advantages relative to per-horizon baselines. Theoretical bounds are proven for the selector's noise immunity and adaptive chunking's value dominance over fixed sizes. Empirical results show SOTA offline and online success rates on OGBench and Robomimic, and improvements for VLA models on RoboCasa-GR1 tasks.
Significance. This work tackles a practical challenge in RL for robotics and sequential decision making by enabling adaptive temporal abstraction. The proposed normalization to mitigate bias in critic comparisons is novel and, if the theoretical guarantees hold, could influence future designs of chunked policies. The application to large VLA models demonstrates broader impact. However, the significance depends on whether the central mechanism performs as claimed without introducing new biases.
major comments (2)
- [Theoretical analysis (noise immunity bounds)] Theoretical analysis (noise immunity bounds): The bound on the advantage selector's noise immunity relies on the normalized advantage A_h = (Q_h(s, a_h) - b_h(s)) / discount_factor leading to unbiased near-random selection in low-signal states. This requires that residual biases in the learned critics are horizon-independent after baseline subtraction. If baselines b_h are derived from the same biased critic family, systematic preferences may persist, undermining the claim that it converts biased wrong answers into unbiased choices. This is central to resolving the identified failures.
- [Empirical evaluation] Empirical evaluation: The reported SOTA results on OGBench and Robomimic, and gains on RoboCasa-GR1, are presented without sufficient detail on whether the normalization truly eliminates discount-scale mismatch or if post-hoc choices influence the gains. Ablations isolating the effect of the adaptive selector versus fixed chunking would strengthen the claims.
minor comments (2)
- [Abstract] The abstract is clear but could specify the set of chunk sizes used or how the per-horizon baseline is exactly formulated for better reproducibility.
- [Notation] Ensure consistent use of symbols for discount factor and horizons throughout the paper to avoid notation confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify and strengthen our manuscript. We address each major comment point by point below, outlining planned revisions where appropriate.
read point-by-point responses
-
Referee: Theoretical analysis (noise immunity bounds): The bound on the advantage selector's noise immunity relies on the normalized advantage A_h = (Q_h(s, a_h) - b_h(s)) / discount_factor leading to unbiased near-random selection in low-signal states. This requires that residual biases in the learned critics are horizon-independent after baseline subtraction. If baselines b_h are derived from the same biased critic family, systematic preferences may persist, undermining the claim that it converts biased wrong answers into unbiased choices. This is central to resolving the identified failures.
Authors: We appreciate the referee highlighting this subtlety in the assumptions underlying the noise-immunity bounds. The per-horizon baselines are indeed computed from the same critic family, and our normalization by the discount factor is intended to remove scale-dependent bias while converting low-signal states to near-uniform selection. However, we acknowledge that the analysis implicitly assumes that any remaining critic biases are not systematically correlated across horizons in a manner that would favor one chunk size. This is a valid point that merits explicit discussion. In the revised manuscript we will expand the theoretical section to state this assumption clearly, provide a brief remark on its implications for the selector, and include an additional sentence in the proof sketch addressing bias correlation. We do not believe this undermines the central claims but agree that greater transparency strengthens the presentation. revision: partial
-
Referee: Empirical evaluation: The reported SOTA results on OGBench and Robomimic, and gains on RoboCasa-GR1, are presented without sufficient detail on whether the normalization truly eliminates discount-scale mismatch or if post-hoc choices influence the gains. Ablations isolating the effect of the adaptive selector versus fixed chunking would strengthen the claims.
Authors: We agree that the empirical section would benefit from additional detail and targeted ablations. In the revision we will insert new experiments that directly compare Adaptive Q-Chunking against fixed-chunk baselines both with and without the proposed normalization, report performance variance across multiple random seeds, and provide implementation specifics confirming that no post-hoc hyperparameter tuning beyond standard offline-to-online practices was applied. These additions will isolate the contribution of the adaptive selector and demonstrate that the observed gains arise from the mechanism rather than implementation artifacts. revision: yes
Circularity Check
No significant circularity; central criterion uses standard RL advantage estimation without reducing to fitted self-inputs
full rationale
The derivation relies on comparing advantages A_h = Q_h(s, a_h) - b_h(s) normalized by discount factor to select chunk sizes, building directly on established RL concepts of advantage and discounting. No equations or claims reduce the selector to a quantity defined by the paper's own fitted parameters or prior self-citations. Theoretical bounds on noise immunity and value dominance are stated as proven from general assumptions on value functions rather than by construction from the method itself. Empirical claims reference external benchmarks (OGBench, Robomimic, RoboCasa-GR1) without the success rates being forced by the selection rule. This yields a minor score reflecting normal self-reference to RL foundations but no load-bearing circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- set of chunk sizes
axioms (1)
- domain assumption Normalized advantage relative to per-horizon baseline yields unbiased chunk-size selection
Reference graph
Works this paper leans on
-
[1]
Reincarnating reinforcement learning: Reusing prior computation to accelerate progress
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron C Courville, and Marc Belle- mare. Reincarnating reinforcement learning: Reusing prior computation to accelerate progress. Advances in neural information processing systems, 35:28955–28971, 2022
2022
-
[2]
OPAL: Of- fline primitive discovery for accelerating offline reinforcement learning
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, and Ofir Nachum. OPAL: Of- fline primitive discovery for accelerating offline reinforcement learning. InInternational Con- ference on Learning Representations, 2021. URL https://openreview.net/forum?id= V69LGwJ0lIN
2021
-
[3]
Hindsight experience replay
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. Advances in Neural Information Processing Systems, 30, 2017
2017
-
[4]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
2017
-
[5]
Option discovery using deep skill chaining
Akhil Bagaria and George Konidaris. Option discovery using deep skill chaining. InInterna- tional Conference on Learning Representations, 2019
2019
-
[6]
Effectively learning initiation sets in hierarchical reinforcement learning
Akhil Bagaria, Ben Abbatematteo, Omer Gottesman, Matt Corsaro, Sreehari Rammohan, and George Konidaris. Effectively learning initiation sets in hierarchical reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[7]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castaneda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[10]
Feudal reinforcement learning.Advances in neural information processing systems, 5, 1992
Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning.Advances in neural information processing systems, 5, 1992
1992
-
[11]
Hierarchical reinforcement learning with the maxq value function decomposition.Journal of artificial intelligence research, 13:227–303, 2000
Thomas G Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition.Journal of artificial intelligence research, 13:227–303, 2000
2000
-
[12]
Revisiting fundamentals of experience replay
William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, and Will Dabney. Revisiting fundamentals of experience replay. InInternational conference on machine learning, pages 3061–3071. PMLR, 2020
2020
-
[13]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning, pages 1587–1596. PMLR, 2018
2018
-
[14]
Hierarchical skills for efficient exploration.Advances in Neural Information Processing Systems, 34:11553–11564, 2021
Jonas Gehring, Gabriel Synnaeve, Andreas Krause, and Nicolas Usunier. Hierarchical skills for efficient exploration.Advances in Neural Information Processing Systems, 34:11553–11564, 2021
2021
-
[15]
EMaQ: Expected-max q-learning operator for simple yet effective offline and online RL
Seyed Kamyar Seyed Ghasemipour, Dale Schuurmans, and Shixiang Shane Gu. EMaQ: Expected-max q-learning operator for simple yet effective offline and online RL. InInternational Conference on Machine Learning, pages 3682–3691. PMLR, 2021
2021
-
[16]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. PMLR, 2018. 10
2018
-
[17]
Rainbow: Combining improve- ments in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improve- ments in deep reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[18]
Approximately optimal approximate reinforcement learning
Sham Kakade and John Langford. Approximately optimal approximate reinforcement learning. InProceedings of the Nineteenth International Conference on Machine Learning, ICML ’02, page 267–274, San Francisco, CA, USA, 2002. Morgan Kaufmann Publishers Inc. ISBN 1558608737
2002
-
[19]
Changyeon Kim, Haone Lee, Younggyo Seo, Kimin Lee, and Yuke Zhu. DEAS: Detached value learning with action sequence for scalable offline RL.arXiv preprint arXiv:2510.07730, 2025
-
[20]
University of Massachusetts Amherst, 2011
George Dimitri Konidaris.Autonomous robot skill acquisition. University of Massachusetts Amherst, 2011
2011
-
[21]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q-learning.arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review arXiv 2021
-
[22]
Revisiting Peng’s Q(λ) for modern reinforcement learning
Tadashi Kozuno, Yunhao Tang, Mark Rowland, Rémi Munos, Steven Kapturowski, Will Dabney, Michal Valko, and David Abel. Revisiting Peng’s Q(λ) for modern reinforcement learning. In International Conference on Machine Learning, pages 5794–5804. PMLR, 2021
2021
-
[23]
Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation.Advances in neural information processing systems, 29, 2016
Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation.Advances in neural information processing systems, 29, 2016
2016
-
[24]
Conservative Q-learning for offline reinforcement learning.Advances in Neural Information Processing Systems, 33:1179– 1191, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-learning for offline reinforcement learning.Advances in Neural Information Processing Systems, 33:1179– 1191, 2020
2020
-
[25]
Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic Q-ensemble. InConference on Robot Learning, pages 1702–1712. PMLR, 2022
2022
-
[26]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review arXiv 2005
-
[27]
TOP-ERL: Transformer-based off-policy episodic reinforcement learning
Ge Li, Dong Tian, Hongyi Zhou, Xinkai Jiang, Rudolf Lioutikov, and Gerhard Neumann. TOP-ERL: Transformer-based off-policy episodic reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=N4NhVN30ph
2025
-
[28]
Reinforcement learning with action chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=XUks1Y96NR
2025
-
[29]
Decoupled q-chunking
Qiyang Li, Seohong Park, and Sergey Levine. Decoupled q-chunking. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=aqGNdZQL9l
2026
-
[30]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=AlGy9vbc1B1
2023
-
[31]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. In5th Annual Conference on Robot Learning, 2021. URLhttps://openreview.net/forum?id=JrsfBJtDFdI
2021
-
[32]
Q-cut—dynamic discovery of sub-goals in reinforcement learning
Ishai Menache, Shie Mannor, and Nahum Shimkin. Q-cut—dynamic discovery of sub-goals in reinforcement learning. InMachine Learning: ECML 2002: 13th European Conference on Machine Learning Helsinki, Finland, August 19–23, 2002 Proceedings 13, pages 295–306. Springer, 2002. 11
2002
-
[33]
Safe and efficient off-policy reinforcement learning
Rémi Munos, Tom Stepleton, Anna Harutyunyan, and Marc Bellemare. Safe and efficient off-policy reinforcement learning. InAdvances in Neural Information Processing Systems, volume 29, 2016
2016
-
[34]
Data-efficient hierarchical reinforcement learning.Advances in neural information processing systems, 31, 2018
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning.Advances in neural information processing systems, 31, 2018
2018
- [35]
-
[36]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. AW AC: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review arXiv 2006
-
[37]
Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning.Advances in Neural Information Processing Systems, 36, 2024
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[38]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems, 2024. URL https://arxiv.org/abs/ 2406.02523
work page internal anchor Pith review arXiv 2024
-
[39]
OGBench: Benchmark- ing offline goal-conditioned RL
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. OGBench: Benchmark- ing offline goal-conditioned RL. InThe Thirteenth International Conference on Learning Rep- resentations, 2025. URLhttps://openreview.net/forum?id=M992mjgKzI
2025
-
[40]
Horizon reduction makes RL scalable
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes RL scalable. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= hguaupzLCU
2025
-
[41]
Flow q-learning.arXiv:2502.02538, 2025
Seohong Park, Qiyang Li, and Sergey Levine. Flow Q-learning. InInternational Conference on Machine Learning, 2025. URLhttps://arxiv.org/abs/2502.02538
-
[42]
Accelerating reinforcement learning with learned skill priors
Karl Pertsch, Youngwoon Lee, and Joseph Lim. Accelerating reinforcement learning with learned skill priors. InConference on robot learning, pages 188–204. PMLR, 2021
2021
-
[43]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[44]
Coarse-to-fine q-network with action sequence for data- efficient reinforcement learning
Younggyo Seo and Pieter Abbeel. Coarse-to-fine q-network with action sequence for data- efficient reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=VoFXUNc9Zh
2025
-
[45]
Continuous control with coarse-to-fine re- inforcement learning
Younggyo Seo, Jafar Uruç, and Stephen James. Continuous control with coarse-to-fine re- inforcement learning. In8th Annual Conference on Robot Learning, 2024. URL https: //openreview.net/forum?id=WjDR48cL3O
2024
-
[46]
Learning robot skills with temporal variational inference
Tanmay Shankar and Abhinav Gupta. Learning robot skills with temporal variational inference. InInternational Conference on Machine Learning, pages 8624–8633. PMLR, 2020
2020
-
[47]
Using relative novelty to identify useful temporal abstrac- tions in reinforcement learning
Özgür ¸ Sim¸ sek and Andrew G Barto. Using relative novelty to identify useful temporal abstrac- tions in reinforcement learning. InProceedings of the twenty-first international conference on Machine learning, page 95, 2004
2004
-
[48]
Özgür ¸ Sim¸ sek and Andrew G. Barto. Betweenness centrality as a basis for forming skills. Workingpaper, University of Massachusetts Amherst, April 2007
2007
-
[49]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998. 12
1998
-
[50]
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
1999
-
[51]
Dong Tian, Ge Li, Hongyi Zhou, Onur Celik, and Gerhard Neumann. Chunking the critic: A transformer-based soft actor-critic with n-step returns.arXiv preprint arXiv:2503.03660, 2025
-
[52]
Strategic attentive writer for learning macro-actions.Advances in neural information processing systems, 29, 2016
Alexander Vezhnevets, V olodymyr Mnih, Simon Osindero, Alex Graves, Oriol Vinyals, John Agapiou, et al. Strategic attentive writer for learning macro-actions.Advances in neural information processing systems, 29, 2016
2016
-
[53]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. InInternational conference on machine learning, pages 3540–3549. PMLR, 2017
2017
-
[54]
Latent skill planning for exploration and transfer
Kevin Xie, Homanga Bharadhwaj, Danijar Hafner, Animesh Garg, and Florian Shkurti. Latent skill planning for exploration and transfer. InInternational Conference on Learning Represen- tations, 2021. URLhttps://openreview.net/forum?id=jXe91kq3jAq
2021
-
[55]
Policy expansion for bridging offline-to-online reinforcement learning
Haichao Zhang, Wei Xu, and Haonan Yu. Policy expansion for bridging offline-to-online reinforcement learning. InThe Eleventh International Conference on Learning Representations,
-
[56]
URLhttps://openreview.net/forum?id=-Y34L45JR6z
-
[57]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review arXiv 2023
-
[58]
Lights Out
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online reinforcement learning fine-tuning need not retain offline data. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=HN0CYZbAPw. 13 A Limitations and Future Work Despite its empirical effectiveness, our method...
2025
-
[59]
5.f ω(s, x, u) :S ×R hada ×[0,1]7→R hada — the flow-matching behavior policy, parame- terized by a velocity prediction network
¯Qϕ, ¯Qψ, ¯Vξ — exponential-moving-average target networks for each of the above, updated with decayτ= 0.005. 5.f ω(s, x, u) :S ×R hada ×[0,1]7→R hada — the flow-matching behavior policy, parame- terized by a velocity prediction network. Given a transition (st, at:t+h−1, st+h, r(h) t )∼ D where r(h) t =Ph−1 j=0 γjrt+j and continuation mask mt =Qh−1 j=0 γc...
-
[60]
At each re-query states, the selector incurs mis-selection probability at most2¯εK/(γkmin∆(s))
-
[61]
When a mis-selection occurs, the value loss per mistake is bounded by ¯Rk/γk
-
[62]
Over the trajectory, the expected number of mis-selections in the discounted horizon is at most (1/(1−γ))·2¯ε K/(γkmin∆(s))
-
[63]
downward
The total regret is the product of expected mis-selection count and per-mis-selection loss. A full proof appears in Appendix I.5. Corollary H.12(Uniform Regret Bound).If∆(s)≥∆>0for alls, then ∥V AQC −V †∥∞ ≤ 2¯εK (1−γ)γ kmin∆ ·max k∈K ¯Rk γk .(31) This bound shows that the regret scales linearly with the critic error and inversely with the advantage gap. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.