Knowledge-Graph Paths as Intermediate Supervision for Self-Evolving Search Agents
Pith reviewed 2026-05-08 11:40 UTC · model grok-4.3
The pith
Knowledge-graph paths supply relational context and partial rewards to improve self-evolving search agents over standard self-play.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
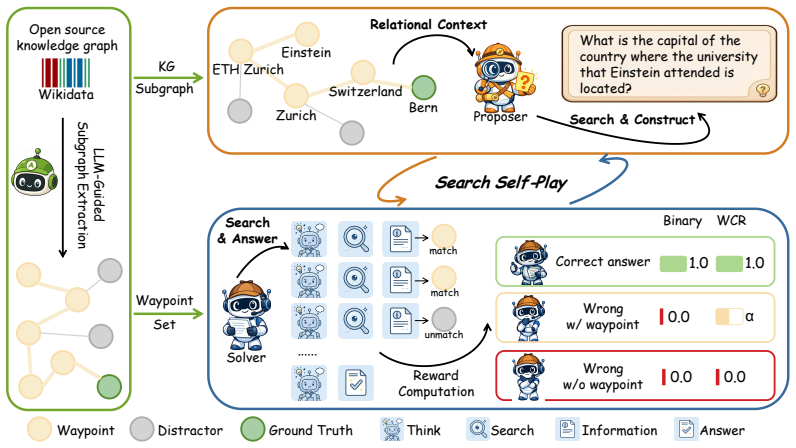
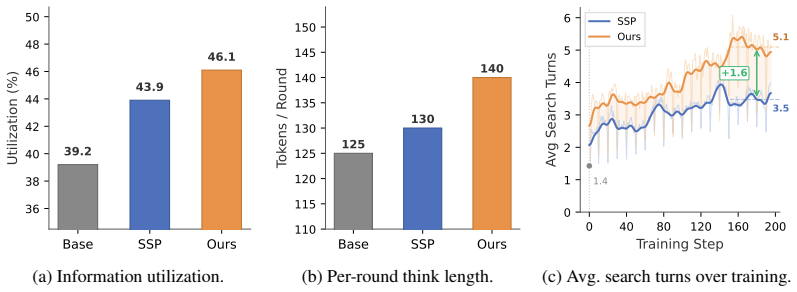
By grounding question construction in LLM-guided knowledge-graph subgraphs and introducing Waypoint Coverage Reward that grants partial credit for covering entities on the construction path, the method supplies both relational context for the proposer and process-level feedback for the solver, raising average scores over standard SSP in every tested configuration.
What carries the argument
Knowledge-graph paths reused as intermediate supervision for subgraph-grounded question construction and for waypoint-coverage reward shaping.
If this is right
- The proposer produces more valid questions because it draws on connected relational context rather than isolated answer entities.
- The solver receives useful training signal from trajectories that reach some but not all of the construction-path entities.
- Gains are largest on multi-hop QA tasks where intermediate entities naturally serve as waypoints.
- The same lightweight path reuse works across different base models without task-specific human process labels.
Where Pith is reading between the lines
- The overlap between construction and solving paths could be tested in other self-play agent loops that generate their own tasks.
- If the method scales, it suggests graph-structured data can substitute for some human supervision in agent training more broadly.
- Dynamic updates to the underlying knowledge graph might reveal whether the waypoint signal remains stable over long self-evolution runs.
Load-bearing premise
Knowledge-graph subgraphs give reliable relational context for valid questions and the entities on a construction path overlap usefully with the entities needed to solve the same question.
What would settle it
Training the same agents without the knowledge-graph path components and finding no improvement in average benchmark scores would show the supervision is not doing the claimed work.
Figures






read the original abstract
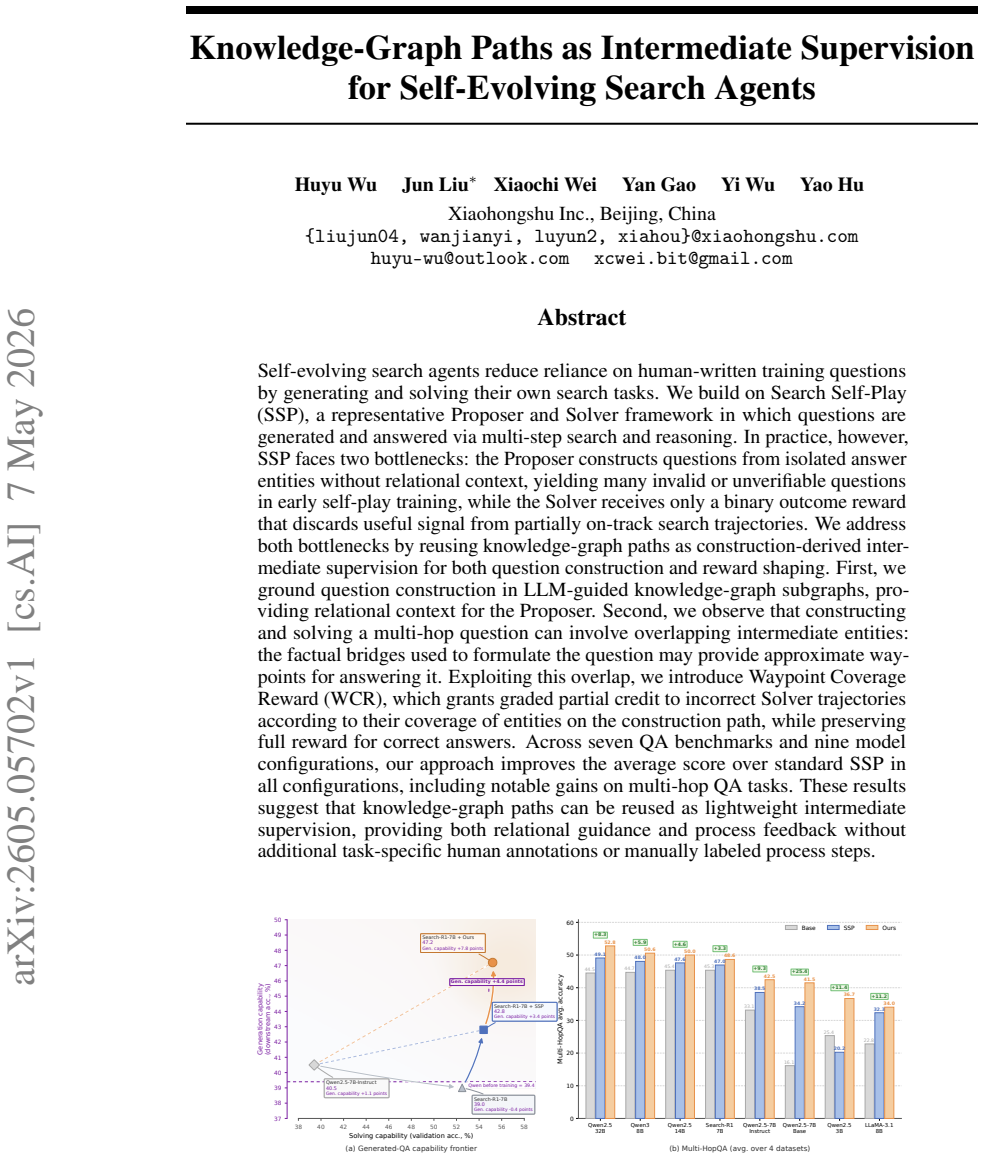
Self-evolving search agents reduce reliance on human-written training questions by generating and solving their own search tasks. We build on Search Self-Play (SSP), a representative Proposer and Solver framework in which questions are generated and answered via multi-step search and reasoning. In practice, however, SSP faces two bottlenecks: the Proposer constructs questions from isolated answer entities without relational context, yielding many invalid or unverifiable questions in early self-play training, while the Solver receives only a binary outcome reward that discards useful signal from partially on-track search trajectories. We address both bottlenecks by reusing knowledge-graph paths as construction-derived intermediate supervision for both question construction and reward shaping. First, we ground question construction in LLM-guided knowledge-graph subgraphs, providing relational context for the Proposer. Second, we observe that constructing and solving a multi-hop question can involve overlapping intermediate entities: the factual bridges used to formulate the question may provide approximate waypoints for answering it. Exploiting this overlap, we introduce Waypoint Coverage Reward (WCR), which grants graded partial credit to incorrect Solver trajectories according to their coverage of entities on the construction path, while preserving full reward for correct answers. Across seven QA benchmarks and nine model configurations, our approach improves the average score over standard SSP in all configurations, including notable gains on multi-hop QA tasks. These results suggest that knowledge-graph paths can be reused as lightweight intermediate supervision, providing both relational guidance and process feedback without additional task-specific human annotations or manually labeled process steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
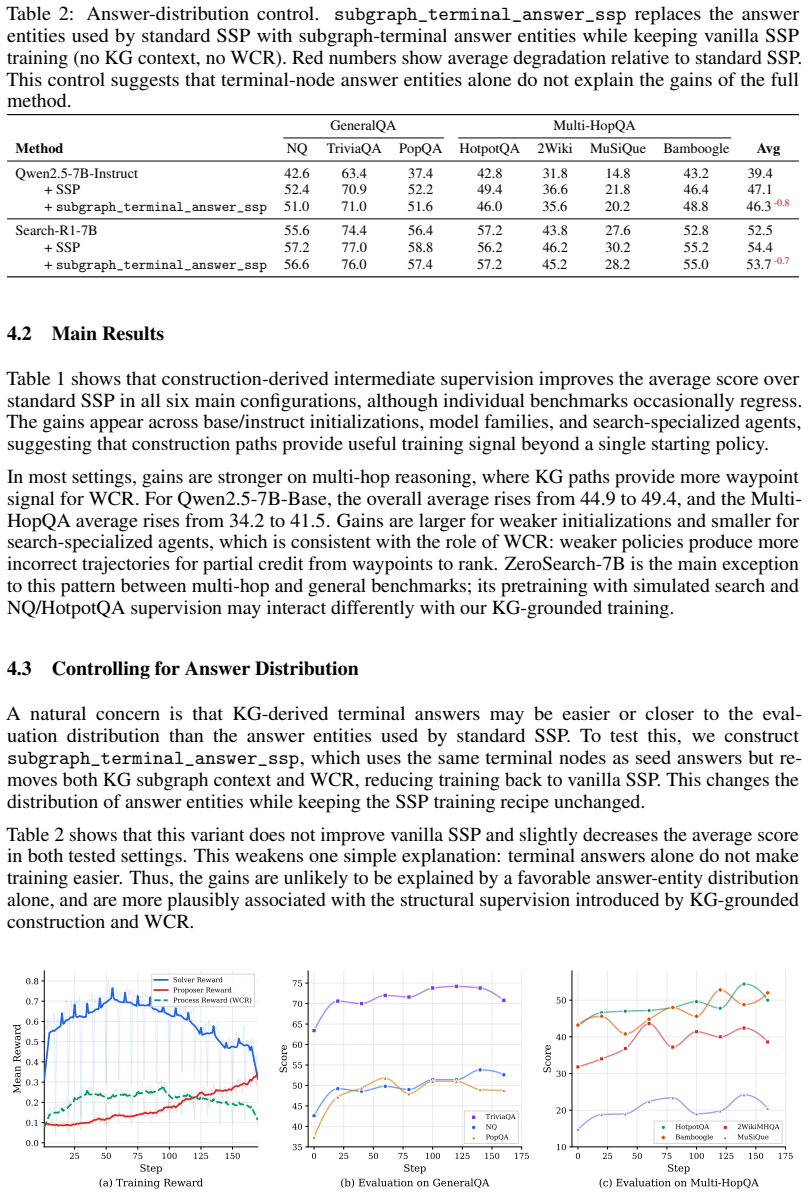
Summary. The paper proposes enhancements to Search Self-Play (SSP) for self-evolving search agents. It grounds the Proposer in LLM-guided knowledge-graph subgraphs to supply relational context during question construction and introduces Waypoint Coverage Reward (WCR) to shape the Solver's reward by granting partial credit proportional to coverage of entities on the construction path. The central claim is that this yields consistent improvements over standard SSP across seven QA benchmarks and nine model configurations, with particular gains on multi-hop tasks, all without additional human annotations.
Significance. If the claimed gains are robust and attributable to the proposed mechanisms, the work demonstrates a lightweight reuse of existing knowledge graphs to supply both construction guidance and process-level supervision. This could reduce dependence on human-written questions and binary rewards in self-play training loops, offering a practical route to stronger multi-hop reasoning agents.
major comments (2)
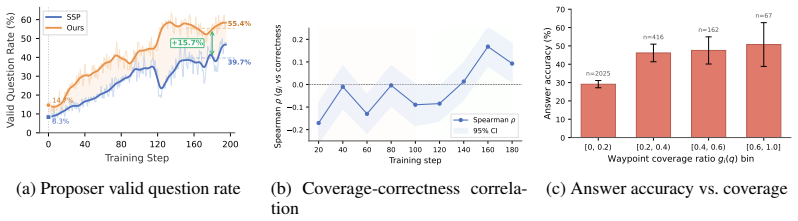
- [§3.2] §3.2 (Waypoint Coverage Reward definition): The manuscript motivates WCR by the observation that 'constructing and solving a multi-hop question can involve overlapping intermediate entities,' yet supplies no quantitative overlap statistics (e.g., mean entity coverage on successful versus unsuccessful trajectories or correlation with final correctness). Without such measurements, it is impossible to verify that WCR supplies useful partial-reward signal rather than incidental or uncorrelated credit, which directly undermines the claim that WCR addresses the binary-outcome bottleneck.
- [§4] §4 (Experimental results): The paper asserts improvements 'in all configurations' and 'notable gains on multi-hop QA tasks' but reports neither an ablation that isolates WCR from the KG-grounded proposer alone nor any overlap or correlation analysis between construction paths and solver trajectories. Because the headline claim rests on both mechanisms working together, the absence of these load-bearing controls leaves the source of the gains unverifiable.
minor comments (2)
- [Abstract] The abstract states results 'across seven QA benchmarks and nine model configurations' without enumerating either the benchmarks or the configurations (e.g., base LLMs, temperatures, or KG sources). Adding this enumeration would improve reproducibility.
- [§3.2] Notation for the WCR formula is introduced without an explicit equation number or pseudocode listing; a numbered definition would clarify how coverage is computed and normalized.
Simulated Author's Rebuttal
We appreciate the referee's constructive comments and positive view of the work's potential significance. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Waypoint Coverage Reward definition): The manuscript motivates WCR by the observation that 'constructing and solving a multi-hop question can involve overlapping intermediate entities,' yet supplies no quantitative overlap statistics (e.g., mean entity coverage on successful versus unsuccessful trajectories or correlation with final correctness). Without such measurements, it is impossible to verify that WCR supplies useful partial-reward signal rather than incidental or uncorrelated credit, which directly undermines the claim that WCR addresses the binary-outcome bottleneck.
Authors: We thank the referee for highlighting this gap in the current presentation. The motivation for WCR derives from our empirical observation during development that construction paths frequently share intermediate entities with solver trajectories on multi-hop questions. We agree that quantitative validation is needed to confirm the partial-reward signal is useful rather than incidental. In the revised manuscript, we will add a dedicated analysis subsection reporting mean entity coverage rates on successful versus unsuccessful trajectories, along with correlation statistics between coverage and final answer correctness, computed from the existing experimental trajectories. revision: yes
-
Referee: [§4] §4 (Experimental results): The paper asserts improvements 'in all configurations' and 'notable gains on multi-hop QA tasks' but reports neither an ablation that isolates WCR from the KG-grounded proposer alone nor any overlap or correlation analysis between construction paths and solver trajectories. Because the headline claim rests on both mechanisms working together, the absence of these load-bearing controls leaves the source of the gains unverifiable.
Authors: We acknowledge that the reported experiments compare only the full combined approach against standard SSP and therefore do not isolate the individual contributions of the KG-grounded proposer and WCR. To address this, the revised version will include an ablation study evaluating the KG-grounded proposer paired with the original binary reward (i.e., without WCR). Results from this ablation, together with the overlap and correlation analysis described in the response to the first comment, will be added to §4 to make the source of the observed gains, especially on multi-hop tasks, more transparent and verifiable. revision: yes
Circularity Check
No circularity: empirical method validated on external benchmarks without self-referential derivations
full rationale
The paper introduces an empirical extension to Search Self-Play (SSP) by grounding question construction in LLM-guided KG subgraphs and adding Waypoint Coverage Reward (WCR) based on observed entity overlap. No equations, fitted parameters, or derivations are present that reduce to the authors' own inputs by construction. Performance claims rest on experiments across seven external QA benchmarks and nine model configurations, using standard metrics and public KGs rather than internal loops or self-citations that bear the central load. The overlap assumption is stated as an observation but is not used to define the reward by fiat; gains are reported as measured outcomes. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Knowledge graphs contain accurate relational paths that can be extracted as subgraphs to guide valid multi-hop question generation
- domain assumption Construction paths and solving trajectories share sufficient intermediate entities to make waypoint coverage a useful proxy for progress
invented entities (1)
-
Waypoint Coverage Reward (WCR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Question generation.Each model’s Proposer generates questions using 10,000 seed entities with 2 rollouts per seed (20,000 trajectories total). Generation uses temperature 0.8, a maximum of 2,048 tokens per response, and up to 10 search turns per trajectory, with top-3 document retrieval at each turn
-
[2]
Only QA pairs that pass both stages are retained
Filtering.Generated trajectories are filtered using the same pipeline as during self-play training and the same answer-verification rules as in the main experiments. Only QA pairs that pass both stages are retained
-
[3]
Downstream training.The same base model (Qwen2.5-7B-Instruct) is trained from scratch on the filtered QA pairs using the GRPO objective (batch size 256, learning rate 1×10−6, 5 epochs) with the standard SSP Solver prompt and multi-turn search environment, but with self-play disabled; the model only learns to solve the generated questions
-
[4]
Evaluation.The trained model is evaluated on held-out validation benchmarks (HotpotQA) using the same answer-verification rules as in the main experiments. Generation statistics.Table 6 reports the number of valid QA pairs retained after filtering. Our method (Search-R1 + Ours) achieves the highest pass rate (61.8%), producing 12,357 valid QA pairs from 2...
work page 2025
-
[5]
resolve ambiguous bridging facts. Do not mention correct_answer or titles of intermediate gold-chain nodes. You MAY paraphrase node texts into natural-language clues, but each clue must still be grounded in a distinctive property of some node on the KG path. ## Non-negotiable Constraints (apply WHILE drafting, not after) A)Unique solvability: The final an...
-
[6]
Decide the solve trajectory: Translate the gold chain into a natural sequence of solver actions/searches WITHOUT naming hidden entities
-
[7]
Near/after the divergence point, add constraints that exclude distractors
Embed distractor pressure early; disambiguate late: Use shared attributes early so distractors remain plausible. Near/after the divergence point, add constraints that exclude distractors
-
[8]
Do not provide options, intermediate answers, or explanations
Write the final question text: Write ONE concise question that implicitly encodes a non-trivial multi-step solve trajectory. Do not provide options, intermediate answers, or explanations. You must conduct reasoning inside <think> and </think> first every time you get new information. After reasoning, if you find you lack some knowledge, you can call a sea...
- [9]
-
[10]
Each search call MUST be wrapped as:<search> your query </search>
Optional search phase (only if needed): If you still lack verifiable facts after reasoning, you MAY call the search tool. Each search call MUST be wrapped as:<search> your query </search>
-
[11]
Final output (when ready): Output ONLY the final question wrapped as: <question> [The question text only. No spoilers. No options. No explanations.]</question>
-
[12]
Prohibited: Do NOT output any other tags besides <think>, <search>, <question>. Do NOT output partial tags (e.g., “<think>” without “</think>”). Do NOT include any text outside the allowed tags. Figure 11: Proposer system prompt defining task, constraints, and output format. 30 F.2.2 Proposer User Prompt Proposer User Prompt ## Input (ONE JSON object) Min...
work page 1990
-
[13]
The model answer must accurately respond to the question and be consistent with the reference answer in meaning
-
[14]
For numerical questions, the values must be equal or very close
-
[15]
For textual questions, the core meaning must be correct
-
[16]
Differences in wording or language are allowed as long as the core answer is the same
-
[17]
If the model answer includes the correct answer and does not contain conflicting information, it is also considered correct. Please respond only with "Correct" or "Wrong". Do not provide any additional explanation. Figure 14: LLM-as-a-Judge prompt for semantic answer evaluation when exact-match fails. 32 F.4.2 Difficulty Evaluation Prompt The difficulty e...
work page 1991
-
[18]
You MUST include the difficulty level inside tags:<difficulty>1-5</difficulty>
-
[19]
You MUST output a JSON object with fields"overall_difficulty"and"reasoning" No other text or fields are allowed. Figure 15: Difficulty evaluation prompt assessing question complexity on a 1–5 scale for question- difficulty analysis. 33
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.