Recognition: unknown
Enabling Federated Inference via Unsupervised Consensus Embedding
Pith reviewed 2026-05-08 15:02 UTC · model grok-4.3
The pith
Pretrained models can cooperate on predictions using only shared unlabeled data without sharing parameters or inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
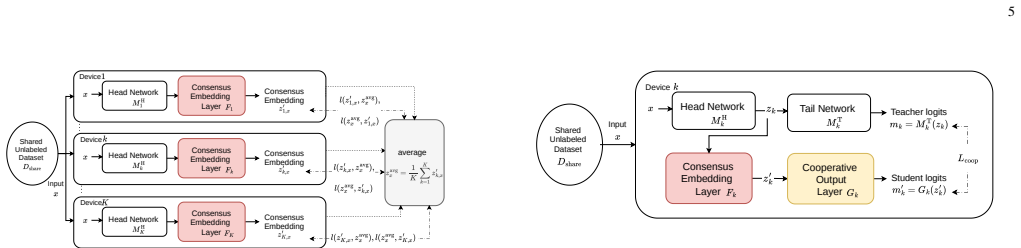
CE-FI enables pretrained models to cooperate at inference time without sharing model parameters or raw inputs and without assuming a common encoder. It introduces a Consensus Embedding layer that maps heterogeneous intermediate representations into a common embedding space and a Cooperative Output layer that produces predictions from these embeddings. Both layers are trained using shared unlabeled data only, so the cooperative stage does not require additional labeled data. Experiments on image classification benchmarks under diverse non-IID conditions show that CE-FI consistently outperforms solo inference and performs comparably to conventional methods that require stronger sharing.
What carries the argument
The Consensus Embedding layer, which maps heterogeneous intermediate representations from independently trained models into a single common space trained unsupervised on shared unlabeled data, paired with a Cooperative Output layer for final predictions.
If this is right
- Independent models achieve higher accuracy than any one alone by combining aligned features without exchanging data or parameters.
- The framework matches performance of methods that assume stronger sharing, such as common encoders or labeled data exchange.
- Representation alignment is the primary bottleneck, so improving it directly raises cooperative gains.
- The approach applies beyond images to text and time-series tasks depending on the output combination strategy.
Where Pith is reading between the lines
- Organizations could pool predictions across separately developed models while keeping training data and architectures fully private.
- If alignment techniques advance, the performance gap to fully centralized ensembles would shrink further.
- The method suggests testing whether the same unlabeled alignment works when models differ more radically in architecture or task.
Load-bearing premise
Enough shared unlabeled data is available and the models' intermediate features can be aligned into a useful common space without any labeled examples or shared architecture components.
What would settle it
No accuracy improvement over individual model predictions when the consensus embedding is applied to models whose intermediate representations have completely disjoint feature spaces on a standard benchmark.
Figures











read the original abstract
Cooperative inference across independently deployed machine learning models is increasingly desirable in distributed environments, as there is a growing need to leverage multiple models while keeping their data and model parameters private. However, existing cooperative frameworks typically rely on sharing input data, model parameters, or a common encoder, which limits their applicability in privacy-sensitive or cross-organizational settings. To address this challenge, we propose Consensus Embedding-based Federated Inference (CE-FI), a framework that enables pretrained models to cooperate at inference time without sharing model parameters or raw inputs and without assuming a common encoder. CE-FI introduces two components: a Consensus Embedding (CE) layer that maps heterogeneous intermediate representations into a common embedding space, and a Cooperative Output (CO) layer that produces predictions from these embeddings. Both layers are trained using shared unlabeled data only, so the cooperative stage does not require additional labeled data. Experiments on image classification benchmarks -- CIFAR-10 and CIFAR-100 -- under diverse non-IID conditions show that CE-FI consistently outperforms solo inference and performs comparably to conventional methods that require stronger sharing assumptions. Additional evaluations on text and time-series tasks indicate applicability beyond image classification, although performance depends on the ensemble strategy. Further analysis identifies representation alignment as the primary bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Consensus Embedding-based Federated Inference (CE-FI) to enable cooperation among independently trained models at inference time without sharing parameters, raw inputs, or assuming a common encoder. It introduces a Consensus Embedding (CE) layer to map heterogeneous intermediate representations into a shared space and a Cooperative Output (CO) layer for predictions, both trained solely on shared unlabeled data. Experiments on CIFAR-10 and CIFAR-100 under non-IID partitions report consistent gains over solo inference and performance comparable to stronger-sharing baselines; additional results on text and time-series tasks are presented, with representation alignment identified as the primary bottleneck.
Significance. If the unsupervised alignment step reliably preserves class-discriminative information across incompatible representation spaces, CE-FI would provide a practical route to privacy-preserving cooperative inference in cross-organizational settings. The empirical results on standard image benchmarks under non-IID conditions are a positive signal, and the extension to non-image modalities broadens potential impact. However, the absence of theoretical guarantees on alignment quality, the explicit dependence on external shared unlabeled data, and the authors' own identification of alignment as the dominant failure mode limit the strength of the contribution relative to existing federated or ensemble methods.
major comments (3)
- [Abstract, §5] Abstract and §5 (Experiments): the central claim of 'consistent outperformance over solo inference' is immediately qualified by the statements that 'performance depends on the ensemble strategy' and that 'representation alignment [is] the primary bottleneck.' No quantitative metric of alignment quality (e.g., class-separability in the CE space or correlation with downstream accuracy) is reported, so it is unclear whether the observed gains are robust or merely an artifact of favorable ensemble choices on the tested partitions.
- [§3] §3 (Method), definition of the CE layer: the unsupervised training objective on shared unlabeled data is presented without any analysis or ablation of how the amount, distribution, or domain shift of that unlabeled data affects alignment quality. Because the entire cooperative stage rests on this step, the lack of sensitivity analysis makes the practical applicability of CE-FI difficult to assess.
- [§4] §4 (Theoretical analysis) or equivalent: no bounds, convergence arguments, or even empirical verification are given that the unsupervised consistency/reconstruction losses preserve label-discriminative structure when the input representations come from independently trained models with incompatible architectures. The skeptic concern that alignment may fail without labels or a shared encoder therefore remains unaddressed at the load-bearing point of the argument.
minor comments (2)
- [§3] Notation for the CE and CO layers is introduced without a clear diagram or pseudocode listing the forward and training passes; a figure would improve readability.
- [§5] The non-IID partitioning details (Dirichlet parameter, number of clients, etc.) are described only at a high level; exact reproduction would require additional specification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight key areas where additional analysis and clarification can strengthen the manuscript. We address each major comment point-by-point below, with planned revisions to improve robustness and transparency.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and §5 (Experiments): the central claim of 'consistent outperformance over solo inference' is immediately qualified by the statements that 'performance depends on the ensemble strategy' and that 'representation alignment [is] the primary bottleneck.' No quantitative metric of alignment quality (e.g., class-separability in the CE space or correlation with downstream accuracy) is reported, so it is unclear whether the observed gains are robust or merely an artifact of favorable ensemble choices on the tested partitions.
Authors: We agree that quantitative metrics of alignment quality would better substantiate the claims and clarify the relationship between alignment success and performance gains. In the revised manuscript, we will add such metrics in §5, including class separability (silhouette score) and intra-class vs. inter-class distances in the CE space, as well as their correlation with downstream accuracy across different ensemble strategies. We will also explicitly state the conditions (e.g., when alignment quality exceeds a threshold) under which consistent outperformance is observed, rather than leaving it qualified only in the text. revision: yes
-
Referee: [§3] §3 (Method), definition of the CE layer: the unsupervised training objective on shared unlabeled data is presented without any analysis or ablation of how the amount, distribution, or domain shift of that unlabeled data affects alignment quality. Because the entire cooperative stage rests on this step, the lack of sensitivity analysis makes the practical applicability of CE-FI difficult to assess.
Authors: We acknowledge that sensitivity analysis on the shared unlabeled data is essential for assessing practical applicability. In the revision, we will include new ablations in §5 examining the effects of varying the amount of unlabeled data (e.g., 10%, 50%, 100% of available samples), different distributions (IID vs. non-IID partitions of the unlabeled set), and moderate domain shifts (e.g., using unlabeled data from a related but distinct source). These results will be presented alongside the main experiments to demonstrate robustness. revision: yes
-
Referee: [§4] §4 (Theoretical analysis) or equivalent: no bounds, convergence arguments, or even empirical verification are given that the unsupervised consistency/reconstruction losses preserve label-discriminative structure when the input representations come from independently trained models with incompatible architectures. The skeptic concern that alignment may fail without labels or a shared encoder therefore remains unaddressed at the load-bearing point of the argument.
Authors: The manuscript provides empirical verification through consistent performance gains on CIFAR-10/100 and extensions to text and time-series tasks, where the unsupervised losses enable cooperation without labels or shared encoders. However, we agree that more targeted empirical analysis of structure preservation would address the concern directly. In the revision, we will add in §5 visualizations (t-SNE of pre- and post-alignment representations) and quantitative measures (e.g., mutual information between CE embeddings and ground-truth labels) to show preservation of discriminative structure. Regarding theoretical bounds or convergence arguments, general guarantees for arbitrary heterogeneous architectures under purely unsupervised objectives are challenging to derive without strong assumptions and lie beyond the scope of this work; we will add an explicit discussion of this limitation in a new Limitations section. revision: partial
Circularity Check
No circularity: empirical method relies on external shared unlabeled data and independent training
full rationale
The paper presents an empirical framework (CE-FI) whose central claims are performance gains on CIFAR-10/100 and other benchmarks under non-IID conditions. These gains are measured against solo inference baselines using held-out test data and do not reduce, by any equation or self-citation in the provided text, to quantities defined solely in terms of the method's own fitted parameters. The CE and CO layers are trained on external shared unlabeled data; the alignment step is acknowledged as a potential bottleneck rather than derived as a theorem. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present in the abstract or reader summary. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of shared unlabeled data across all participating models that is sufficient for representation alignment
invented entities (2)
-
Consensus Embedding (CE) layer
no independent evidence
-
Cooperative Output (CO) layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evolutionary optimization of model merging recipes,
T. Akiba, M. Shing, Y . Tang, Q. Sun, and D. Ha, “Evolutionary optimization of model merging recipes,”Nature Mach. Intell., vol. 7, no. 2, pp. 195–204, Feb. 2025
2025
-
[2]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural Comput., vol. 3, no. 1, pp. 79–87, Mar. 1991
1991
-
[3]
Model inversion attacks that exploit confidence information and basic countermeasures,
M. Fredrikson, S. Jha, and T. Ristenpart, “Model inversion attacks that exploit confidence information and basic countermeasures,” inProc. 22nd ACM SIGSAC Conf. Comput. Commun. Secur., 2015, pp. 1322– 1333
2015
-
[4]
Towards federated inference: An online model ensemble framework for cooper- ative edge ai,
Z. Zhou, J. Xie, M. Huang, T. Ouyang, F. Liu, and X. Chen, “Towards federated inference: An online model ensemble framework for cooper- ative edge ai,” inProc. IEEE INFOCOM, 2025, pp. 1–10
2025
-
[5]
Fedserving: A federated prediction serving framework based on incentive mechanism,
J. Weng, J. Weng, H. Huang, C. Cai, and C. Wang, “Fedserving: A federated prediction serving framework based on incentive mechanism,” inProc. IEEE INFOCOM, 2021, pp. 1–10
2021
-
[6]
Cooperative edge inferences with online learning,
M. Li, R. Venkatesha Prasad, and G. Iosifidis, “Cooperative edge inferences with online learning,”IEEE Internet Things J., vol. 12, no. 22, pp. 46 611–46 625, 2025
2025
-
[7]
Decentralized low-latency collaborative inference via ensembles on the edge,
M. Malka, E. Farhan, H. Morgenstern, and N. Shlezinger, “Decentralized low-latency collaborative inference via ensembles on the edge,”IEEE Trans. Wireless Commun., vol. 24, no. 1, pp. 598–614, Jan. 2025
2025
-
[8]
Svcca: singular vector canonical correlation analysis for deep learning dynamics and interpretability,
M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein, “Svcca: singular vector canonical correlation analysis for deep learning dynamics and interpretability,” inProc. 31st Int. Conf. Neural Inf. Process. Syst., 2017, pp. 6078–6087. 18
2017
-
[9]
Convergent Learning: Do different neural networks learn the same representations?
Y . Li, J. Yosinski, J. Clune, H. Lipson, and J. Hopcroft, “Convergent learning: Do different neural networks learn the same representations?” arXiv:1511.07543, 2015
work page Pith review arXiv 2015
-
[10]
Neural network ensembles,
L. K. Hansen and P. Salamon, “Neural network ensembles,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 12, no. 10, pp. 993–1001, Oct. 1990
1990
-
[11]
Ensemble methods in machine learning,
T. G. Dietterich, “Ensemble methods in machine learning,” inProc. Int. Workshop Multiple Classifier Syst., Dec. 2000, pp. 1–15
2000
-
[12]
Communication-Efficient Learning of Deep Networks from Decentralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” inProc. 20th Int. Conf. Artif. Intell. Statist., Apr. 2017, pp. 1273–1282
2017
-
[13]
Federated machine learning: Concept and applications,
Q. Yang, Y . Liu, T. Chen, and Y . Tong, “Federated machine learning: Concept and applications,”ACM Trans. Intell. Sys. Technol., vol. 10, no. 2, pp. 1–19, 2019
2019
-
[14]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProc. Mach. Learn. Syst., vol. 2, 2020, pp. 429–450
2020
-
[15]
Model-contrastive federated learning,
Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2021, pp. 10 713–10 722
2021
-
[16]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv:1503.02531, 2015
work page internal anchor Pith review arXiv 2015
-
[17]
arXiv preprint arXiv:1804.03235 , year=
R. Anil, G. Pereyra, A. Passos, R. Ormandi, G. E. Dahl, and G. E. Hinton, “Large scale distributed neural network training through online distillation,”arXiv:1804.03235, 2018
-
[18]
Communication-efficient federated learning via knowledge distillation,
C. Wu, F. Wu, L. Lyu, Y . Huang, and X. Xie, “Communication-efficient federated learning via knowledge distillation,”Nature Commun., vol. 13, no. 1, p. 2032, Apr. 2022
2032
-
[19]
Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-iid private data,
S. Itahara, T. Nishio, Y . Koda, M. Morikura, and K. Ya- mamoto, “Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-iid private data,” IEEE Trans. Mobile Comput., vol. 22, no. 1, pp. 191–205, Jan. 2023
2023
-
[20]
A survey on transfer learning,
S. J. Pan and Q. Yang, “A survey on transfer learning,”IEEE Trans. Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, Oct. 2010
2010
-
[21]
Cnn features off-the-shelf: an astounding baseline for recognition,
A. Sharif Razavian, H. Azizpour, J. Sullivan, and S. Carlsson, “Cnn features off-the-shelf: an astounding baseline for recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops, Jun. 2014, pp. 806–813
2014
-
[22]
N. Guha, A. Talwalkar, and V . Smith, “One-shot federated learning,” arXiv:1902.11175, 2019
-
[23]
Towards one-shot federated learning: Advances, chal- lenges, and future directions,
F. Amato, L. Qiu, M. Tanveer, S. Cuomo, D. Annunziata, F. Giampaolo, and F. Piccialli, “Towards one-shot federated learning: Advances, chal- lenges, and future directions,”Neurocomputing, vol. 664, p. 132088, Feb. 2026
2026
-
[24]
An image is worth 16x16 words: Transformers for image recognition at scale,
D. Alexey, B. Lucas, K. Alexander, W. Dirk, Z. Xiaohua, U. Thomas, D. Mostafa, M. Matthias, H. Georg, G. Sylvain, U. Jakob, and H. Neil, “An image is worth 16x16 words: Transformers for image recognition at scale,” inProc. Int. Conf. Learn. Represent., Jan. 2021
2021
-
[25]
Distributed learning of deep neural network over multiple agents,
O. Gupta and R. Raskar, “Distributed learning of deep neural network over multiple agents,”J. Netw. Comput. Appl., vol. 116, pp. 1–8, Aug. 2018
2018
-
[26]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,”ACM SIGARCH Comput. Archit. News, pp. 615–629, Apr. 2017
2017
-
[27]
Hybrid ensemble of classifiers using voting,
I. Gandhi and M. Pandey, “Hybrid ensemble of classifiers using voting,” inProc. Int. Conf. Green Comput. Internet Things, 2015, pp. 399–404
2015
-
[28]
S. W. A. Sherazi, J.-W. Bae, and J. Y . Lee, “A soft voting ensemble classifier for early prediction and diagnosis of occurrences of major adverse cardiovascular events for stemi and nstemi during 2-year follow- up in patients with acute coronary syndrome,”PLOS ONE, vol. 16, no. 6, pp. 1–20, Jun. 2021
2021
-
[29]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inProc. 37th Int. Conf. Mach. Learn., Jul. 2020, pp. 1597–1607
2020
-
[30]
Energy-based out-of-distribution detection,
W. Liu, X. Wang, J. Owens, and Y . Li, “Energy-based out-of-distribution detection,” inProc. 34th Int. Conf. Neural Inf. Process. Syst., 2020, pp. 21 464–21 475
2020
-
[31]
Learning word vectors for sentiment analysis,
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y . Ng, and C. Potts, “Learning word vectors for sentiment analysis,” inProc. 49th Annu. Meeting Assoc. Comput. Linguistics: Hum. Lang. Technol., Jun. 2011, pp. 142–150
2011
-
[32]
Genre classification dataset (imdb),
hijest, “Genre classification dataset (imdb),” Kaggle, 2020, accessed: Feb. 10, 2026. [Online]. Available: https://www.kaggle.com/datasets/ hijest/genre-classification-dataset-imdb
2020
-
[33]
ImageNet Large Scale Visual Recognition Challenge,
R. Olga, D. Jia, S. Hao, K. Jonathan, S. Sanjeev, M. Sean, H. Zhiheng, K. Andrej, K. Aditya, B. Michael, C. B. Alexander, and F.-F. Li, “ImageNet Large Scale Visual Recognition Challenge,”Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Apr. 2015
2015
-
[34]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProc. 38th Int. Conf. Mach. Learn., vol. 139, Jul. 2021, pp. 8748–8763
2021
-
[35]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haz- iza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski, “Dinov3,”arXiv:2508.10104, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., Dec. 2016, pp. 770–778
2016
-
[37]
Convnext v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoencoders,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 16 133–16 142
2023
-
[38]
Simple CLIP,
M. M. Shariatnia, “Simple CLIP,” gitHub repository, 2021, Accessed: Jul. 31, 2025. [Online]. Available: https://github.com/moein-shariatnia/ OpenAI-CLIP
2021
-
[39]
Visualizing data using t-sne,
L. van der Maaten and G. Hinton, “Visualizing data using t-sne,”J. Mach. Learn. Res., vol. 9, no. 86, pp. 2579–2605, Nov. 2008
2008
-
[40]
Unsplit: Data-oblivious model inversion, model stealing, and label inference attacks against split learning,
E. Erdo ˘gan, A. K ¨upc ¸¨u, and A. E. C ¸ ic ¸ek, “Unsplit: Data-oblivious model inversion, model stealing, and label inference attacks against split learning,” inProc. 21st ACM Workshop Privacy Electron. Soc., 2022, pp. 115–124
2022
-
[41]
Unleashing the tiger: Inference attacks on split learning,
D. Pasquini, G. Ateniese, and M. Bernaschi, “Unleashing the tiger: Inference attacks on split learning,” inProc. ACM SIGSAC Conf. Comput. Commun. Sec., 2021, pp. 2113–2129
2021
-
[42]
A stealthy wrongdoer: Feature-oriented reconstruction attack against split learning,
X. Xu, M. Yang, W. Yi, Z. Li, J. Wang, H. Hu, Y . Zhuang, and Y . Liu, “A stealthy wrongdoer: Feature-oriented reconstruction attack against split learning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 12 130–12 139
2024
-
[43]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv:1511.06434, 2015
work page internal anchor Pith review arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.