Recognition: unknown
Offline Reinforcement Learning for Rotation Profile Control in Tokamaks
Pith reviewed 2026-05-08 14:44 UTC · model grok-4.3
The pith
Offline reinforcement learning policies trained on historical tokamak data can control plasma rotation profiles when deployed on a real device.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Offline model-based RL that fits probabilistic models of plasma dynamics to historical DIII-D data can generate rollouts sufficient to train a policy that, when deployed on the real tokamak, achieves useful rotation-profile control without ever interacting online during training.
What carries the argument
Probabilistic models of plasma dynamics that generate synthetic rollouts for offline RL training.
If this is right
- Control policies for tokamak rotation profiles can be learned without an accurate physics simulator or live interaction.
- Probabilistic models fitted to past shots supply enough variation to train a multi-input multi-output policy.
- Real-device deployment is feasible after training only on archival data.
- The same offline approach may extend to other profile-control tasks inside the same machine.
Where Pith is reading between the lines
- If the probabilistic models remain accurate across wider operating regimes, offline RL could reduce the need for expensive simulator development in fusion control.
- Successful deployment raises the question of how to certify safety when the policy encounters conditions outside the training distribution.
- The method could be tested on other tokamaks or on different control objectives such as current or pressure profiles.
Load-bearing premise
Historical data from earlier plasma conditions are representative enough that the learned models do not produce dangerous extrapolations when the policy is deployed on new operating points.
What would settle it
A deployment run in which the learned policy drives the plasma to instability or fails to reach the commanded rotation profile on DIII-D.
Figures
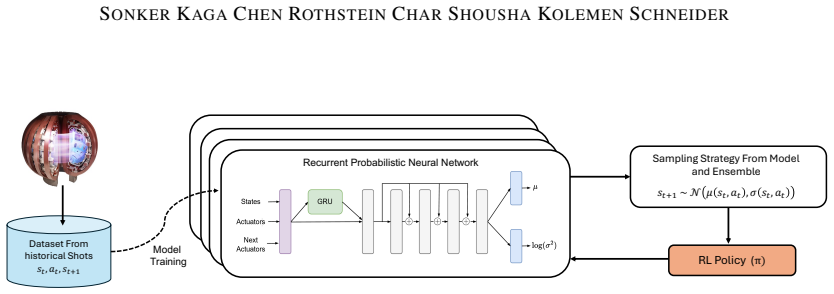



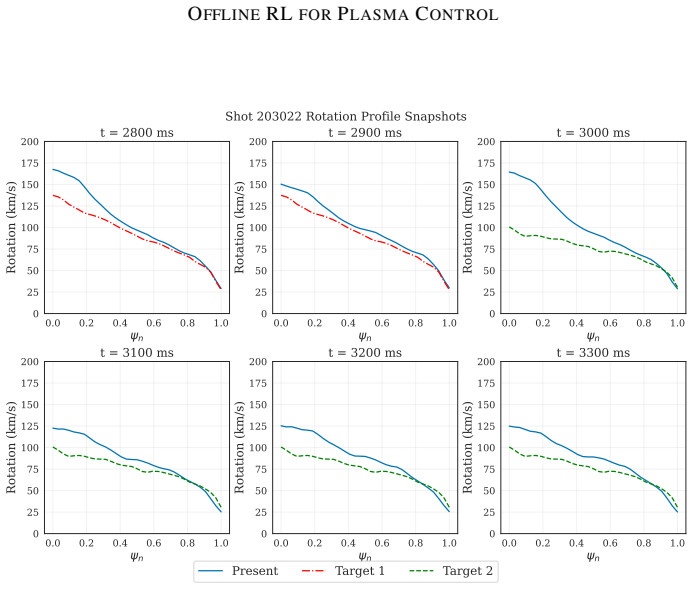


read the original abstract
Tokamaks remain leading candidates for achieving practical fusion energy, yet many important control problems inside these devices are still difficult or unsolved. One such challenge is controlling the plasma rotation profile, which strongly influences stability, confinement, and transport. While the average rotation can be controlled, controlling the full profile is challenging due to high dimensionality, response to multiple actuators and dependence on plasma condition. Learning-based control methods, such as reinforcement learning (RL), provide a potential solution to this challenging problem with ability to model complex interactions leading to effective multi-input multi-output control. However, learning such policies is challenging due to the lack of accurate simulators that can model the rotation profile dynamics. In this work, we investigate the use of offline RL and offline model-based RL algorithms for rotation profile control, training them solely on historical data from the DIII-D tokamak. Our final method uses probabilistic models of plasma dynamics to generate rollouts for RL training. We deploy this policy on the DIII-D Tokamak and observe promising real-world results. We conclude by highlighting key challenges and insights from training and deploying an RL policy on a complex physical device while using only limited past data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that offline RL and offline model-based RL algorithms, trained solely on historical DIII-D tokamak data, can learn policies for controlling the high-dimensional plasma rotation profile. The final method uses probabilistic models of plasma dynamics to generate rollouts for RL training, and the resulting policy is deployed on the real DIII-D device with promising results. The work also discusses challenges and insights from this real-world application with limited data.
Significance. If the deployment results hold with proper quantitative validation, this would be a notable contribution to applying data-driven control to fusion devices. It addresses a difficult multi-actuator, condition-dependent control problem where accurate simulators are unavailable, and demonstrates offline model-based RL as a viable path for safety-critical physical systems using only historical data.
major comments (2)
- [Abstract] Abstract: The central claim that the policy was deployed on DIII-D 'and observe promising real-world results' provides no quantitative metrics, baselines, safety checks, or details on success measurement. This is load-bearing for evaluating whether the offline RL approach yields a deployable policy.
- [Methods] Methods (probabilistic models and rollout generation): No analysis, calibration metrics, or error bounds are given for the probabilistic dynamics models under distribution shift from historical data to new operating points. This directly impacts the reliability of the generated rollouts and the safety of the learned policy.
minor comments (1)
- [Abstract] The abstract and conclusion could more explicitly state the limitations of using only historical data for generalization to new plasma conditions.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive comments on our work applying offline RL to tokamak rotation profile control. We address each major comment below and will revise the manuscript to strengthen the quantitative presentation and model analysis as appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the policy was deployed on DIII-D 'and observe promising real-world results' provides no quantitative metrics, baselines, safety checks, or details on success measurement. This is load-bearing for evaluating whether the offline RL approach yields a deployable policy.
Authors: We agree that the abstract would be improved by including concrete quantitative indicators of the deployment outcomes. The full manuscript reports specific metrics on profile tracking performance, comparisons against prior controllers, and observations regarding operational safety limits during the real-world tests. In the revised version we will update the abstract to briefly state key results (e.g., achieved error reduction and success criteria) while directing readers to the results section for full baselines, safety checks, and measurement details. revision: yes
-
Referee: [Methods] Methods (probabilistic models and rollout generation): No analysis, calibration metrics, or error bounds are given for the probabilistic dynamics models under distribution shift from historical data to new operating points. This directly impacts the reliability of the generated rollouts and the safety of the learned policy.
Authors: We acknowledge the value of explicit robustness analysis for the dynamics models. The models were trained on historical DIII-D data and assessed via cross-validation on held-out shots, but the original manuscript does not provide dedicated calibration metrics or error bounds specifically for distribution shift to new operating regimes. We will revise the methods section to add this analysis, including calibration diagnostics and uncertainty-derived bounds where supported by the existing dataset, and will discuss implications for rollout quality and policy safety. revision: yes
Circularity Check
No significant circularity; derivation self-contained via real-device validation
full rationale
The paper trains probabilistic dynamics models and offline RL policies exclusively on historical DIII-D data, then deploys the resulting policy on the physical tokamak. No equations, fitting procedures, or self-citations are described that reduce performance claims to self-referential definitions, fitted inputs renamed as predictions, or load-bearing author citations. The central result is grounded in external empirical deployment rather than any internal tautology or ansatz smuggling, making the chain self-contained against the provided benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , volume=
End-to-end training of deep visuomotor policies , author=. Journal of Machine Learning Research , volume=
-
[2]
Science robotics , volume=
Learning quadrupedal locomotion over challenging terrain , author=. Science robotics , volume=. 2020 , publisher=
2020
-
[3]
Proceedings of the IEEE , year=
A review of safe reinforcement learning methods for modern power systems , author=. Proceedings of the IEEE , year=
-
[4]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[5]
Soft Actor-Critic Algorithms and Applications
Soft actor-critic algorithms and applications , author=. arXiv preprint arXiv:1812.05905 , year=
work page internal anchor Pith review arXiv
-
[6]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review arXiv
-
[7]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[8]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review arXiv 2005
-
[9]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[10]
International conference on machine learning , pages=
Off-policy deep reinforcement learning without exploration , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[11]
Advances in neural information processing systems , volume=
Deep reinforcement learning in a handful of trials using probabilistic dynamics models , author=. Advances in neural information processing systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Mopo: Model-based offline policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in neural information processing systems , volume=
When to trust your model: Model-based policy optimization , author=. Advances in neural information processing systems , volume=
-
[14]
Advances in neural information processing systems , volume=
Morel: Model-based offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[15]
and Boots, Byron and Theodorou, Evangelos A
Williams, Grady and Wagener, Nolan and Goldfain, Brian and Drews, Paul and Rehg, James M. and Boots, Byron and Theodorou, Evangelos A. , booktitle=. Information theoretic MPC for model-based reinforcement learning , year=
-
[16]
Handbook of statistics , volume=
The cross-entropy method for optimization , author=. Handbook of statistics , volume=. 2013 , publisher=
2013
-
[17]
Advances in neural information processing systems , volume=
Differentiable mpc for end-to-end planning and control , author=. Advances in neural information processing systems , volume=
-
[18]
doi:10.1088/1741-4326/ad22f5 , year =
Mehta, Viraj and Barr, Jayson and Abbate, Joseph and Boyer, Mark D and Char, Ian and Neiswanger, Willie and Kolemen, Egemen and Schneider, Jeff , title =. doi:10.1088/1741-4326/ad22f5 , year =
-
[19]
Forty-second International Conference on Machine Learning , year =
Multi-Timescale Dynamics Model Bayesian Optimization for Plasma Stabilization in Tokamaks , author=. Forty-second International Conference on Machine Learning , year =
-
[20]
Nature , volume=
Magnetic control of tokamak plasmas through deep reinforcement learning , author=. Nature , volume=. 2022 , publisher=
2022
-
[21]
Nature , volume=
Avoiding fusion plasma tearing instability with deep reinforcement learning , author=. Nature , volume=. 2024 , publisher=
2024
-
[22]
Nuclear Fusion , volume=
Simultaneous control of safety factor profile and normalized beta for JT-60SA using reinforcement learning , author=. Nuclear Fusion , volume=. 2023 , publisher=
2023
-
[23]
Learning for Dynamics and Control Conference , pages=
Offline model-based reinforcement learning for tokamak control , author=. Learning for Dynamics and Control Conference , pages=. 2023 , organization=
2023
-
[24]
Communications Physics , volume=
High-fidelity data-driven dynamics model for reinforcement learning-based control in HL-3 tokamak , author=. Communications Physics , volume=. 2025 , publisher=
2025
-
[25]
Towards practical reinforcement learning for tokamak magnetic control , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.fusengdes.2024.114161 , author =
-
[26]
and Nouailletas, R
Kerboua-Benlarbi, S. and Nouailletas, R. and Faugeras, B. and Nardon, E. and Moreau, P. , journal=. Magnetic Control of WEST Plasmas Through Deep Reinforcement Learning , year=
-
[27]
2020 American Control Conference (ACC) , pages=
Introduction to tokamak plasma control , author=. 2020 American Control Conference (ACC) , pages=. 2020 , organization=
2020
-
[28]
Multivariable shape control development on the
Walker, ML and Humphreys, DA and Ferron, JR , booktitle=. Multivariable shape control development on the. 1997 , organization=
1997
-
[29]
Data-driven profile prediction for
Abbate, Joseph and Conlin, Rory and Kolemen, Egemen , journal=. Data-driven profile prediction for. 2021 , publisher=
2021
-
[30]
Full shot predictions for the
Char, Ian and Chung, Youngseog and Abbate, Joseph and Kolemen, Egemen and Schneider, Jeff , journal=. Full shot predictions for the
-
[31]
Nuclear Fusion , volume=
Use of differential plasma rotation to prevent disruptive tearing mode onset from 3-wave coupling , author=. Nuclear Fusion , volume=. 2024 , publisher=
2024
-
[32]
International Conference on Machine Learning , volume =
Yihao Sun and Jiaji Zhang and Chengxing Jia and Haoxin Lin and Junyin Ye and Yang Yu , title =. International Conference on Machine Learning , volume =
-
[33]
2025 , publisher =
Jiayu Chen and Yang Fu and Haomin Bao , title =. 2025 , publisher =
2025
-
[34]
CoRR , volume =
Jiayu Chen and Wentse Chen and Jeff Schneider , title =. CoRR , volume =
-
[35]
CoRR , volume =
Jiayu Chen and Aravind Venugopal and Jeff Schneider , title =. CoRR , volume =
-
[36]
Energies , VOLUME =
Chang, Horng Jinh and Wang, Shih Wei , TITLE =. Energies , VOLUME =. 2025 , NUMBER =
2025
-
[37]
and Albanese, R
Ambrosino, G. and Albanese, R. , journal=. Magnetic control of plasma current, position, and shape in Tokamaks: a survey on modeling and control approaches , year=
-
[38]
Toroidal rotation profile control for the
Wehner, William and Barton, Justin and Schuster, Eugenio , booktitle=. Toroidal rotation profile control for the. 2015 , organization=
2015
-
[39]
Combined rotation profile and plasma stored energy control for the
Wehner, William and Barton, Justin and Schuster, Eugenio , booktitle=. Combined rotation profile and plasma stored energy control for the. 2017 , organization=
2017
-
[40]
Physics of Plasmas , volume=
Large-database cross-verification and validation of tokamak transport models using baselines for comparison , author=. Physics of Plasmas , volume=. 2024 , publisher=
2024
-
[41]
Learning plasma dynamics and robust rampdown trajectories with predict-first experiments at
Wang, Allen M and Pau, Alessandro and Rea, Cristina and So, Oswin and Dawson, Charles and Sauter, Olivier and Boyer, Mark D and Vu, Anna and Galperti, Cristian and Fan, Chuchu and others , journal=. Learning plasma dynamics and robust rampdown trajectories with predict-first experiments at. 2025 , publisher=
2025
-
[42]
Nuclear Fusion , volume=
Reconstruction and interpretation of ionization asymmetry in magnetic confinement via synthetic diagnostics , author=. Nuclear Fusion , volume=. 2024 , publisher=
2024
-
[43]
APS Division of Plasma Physics Meeting Abstracts , volume=
The Influence of Rotation and SOL Drifts on Poloidal Asymmetries of Pedestal Fueling , author=. APS Division of Plasma Physics Meeting Abstracts , volume=
-
[44]
Machine learning-based real-time kinetic profile reconstruction in
Shousha, Ricardo and Seo, Jaemin and Erickson, Keith and Xing, Zichuan and Kim, SangKyeun and Abbate, Joseph and Kolemen, Egemen , journal=. Machine learning-based real-time kinetic profile reconstruction in. 2023 , publisher=
2023
-
[45]
arXiv preprint arXiv:2206.14697 , year=
Hidden parameter recurrent state space models for changing dynamics scenarios , author=. arXiv preprint arXiv:2206.14697 , year=
-
[46]
Rma: Rapid motor adaptation for legged robots,
Rma: Rapid motor adaptation for legged robots , author=. arXiv preprint arXiv:2107.04034 , year=
-
[47]
Fusion Science and Technology , volume=
OMFIT tokamak profile data fitting and physics analysis , author=. Fusion Science and Technology , volume=. 2018 , publisher=
2018
-
[48]
Advances in neural information processing systems , volume=
Randomized prior functions for deep reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[49]
Self-supervised policy adaptation during deployment
Self-supervised policy adaptation during deployment , author=. arXiv preprint arXiv:2007.04309 , year=
-
[50]
2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Learn-to-recover: Retrofitting uavs with reinforcement learning-assisted flight control under cyber-physical attacks , author=. 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2020 , organization=
2020
-
[51]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[52]
Advances in neural information processing systems , volume=
Combo: Conservative offline model-based policy optimization , author=. Advances in neural information processing systems , volume=
-
[53]
Advances in neural information processing systems , volume=
Rambo-rl: Robust adversarial model-based offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[54]
Advances in neural information processing systems , volume=
Goal-conditioned imitation learning , author=. Advances in neural information processing systems , volume=
-
[55]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
work page internal anchor Pith review arXiv
-
[56]
Advances in neural information processing systems , volume=
Uncertainty-based offline reinforcement learning with diversified q-ensemble , author=. Advances in neural information processing systems , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
Mildly conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
International Conference on Machine Learning , pages=
Model-Bellman inconsistency for model-based offline reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[59]
Fusion Engineering and Design , volume=
CAKE: consistent automatic kinetic equilibrium reconstruction , author=. Fusion Engineering and Design , volume=. 2021 , publisher=
2021
-
[60]
Feedback control of stored energy and rotation with variable beam energy and perveance on. Nuclear Fusion , author =. 2019 , pages =. doi:10.1088/1741-4326/ab17f5 , language =
-
[61]
Fusion Engineering and Design , author =
Overview of the. Fusion Engineering and Design , author =. 2024 , pages =
2024
-
[62]
Fusion Engineering and Design , author =
Next-generation plasma control in the. Fusion Engineering and Design , author =. 2003 , pages =. doi:10.1016/S0920-3796(03)00295-3 , language =
-
[63]
Plasma Physics and Controlled Fusion , author =
Design and implementation of a model-based hierarchical architecture for plasma shape control in the. Plasma Physics and Controlled Fusion , author =. 2025 , pages =. doi:10.1088/1361-6587/addeee , language =
-
[64]
Nuclear Fusion , volume=
Heating and current drive in STEP: why neutral beam injection is not desirable , author=. Nuclear Fusion , volume=. 2025 , publisher=
2025
-
[65]
Engineering Applications of Artificial Intelligence , volume=
Keras2c: A library for converting Keras neural networks to real-time compatible C , author=. Engineering Applications of Artificial Intelligence , volume=. 2021 , publisher=
2021
-
[66]
Plasma rotation and rf heating in
DeGrassie, JS and Baker, DR and Burrell, KH and Greenfield, CM and Lin-Liu, YR and Luce, TC and Petty, CC and Prater, R and Heidbrink, WW and Rice, BW , booktitle=. Plasma rotation and rf heating in. 1999 , organization=
1999
-
[67]
Tearing stable stationary ITER baseline operation in
Bardoczi, Laszlo and Dudkovskaia, Alexandra and Logan, NC and Richner, Nathan Jordan and Brown, Ashton Clair and Callen, James D and La Haye, Robert John and Strait, EJ , journal=. Tearing stable stationary ITER baseline operation in. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.