Recognition: unknown
On Fixing Insecure AI-Generated Code through Model Fine-Tuning and Prompting Strategies
Pith reviewed 2026-05-08 09:06 UTC · model grok-4.3
The pith
No fine-tuning or prompting strategy consistently eliminates security weaknesses in AI-generated code across models and languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Security improvements achieved through fine-tuning and prompting strategies are highly strategy- and model-dependent. Some approaches reduce specific classes of weaknesses yet frequently introduce new weaknesses as side effects of the remediation. No strategy consistently eliminates weaknesses across all models and scenarios, demonstrating the absence of a universally effective solution for secure AI-generated code.
What carries the argument
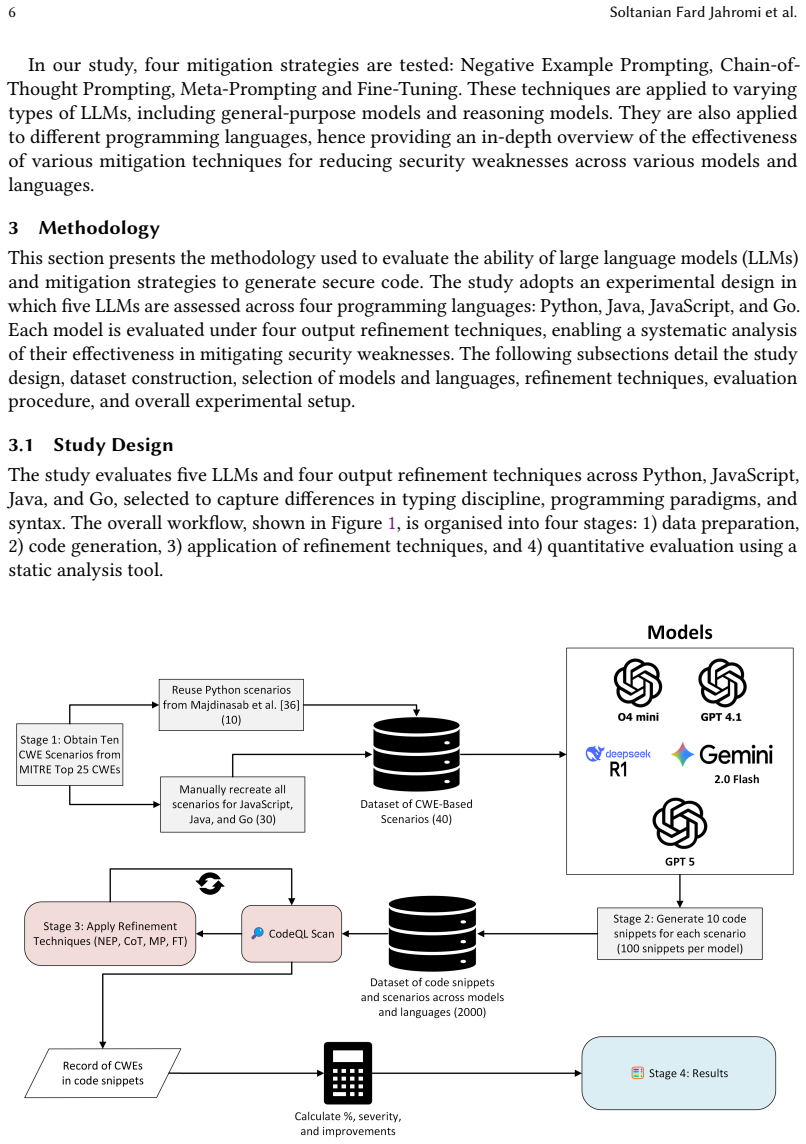
Comparative evaluation of fine-tuning and prompting refinement methods on code generation models, quantified by shifts in CWE prevalence, severity, and co-occurrence detected through static analysis.
If this is right
- Fixing one class of weakness in AI-generated code often creates new weaknesses in other parts of the same program.
- The success of any remediation method depends on both the underlying model and the target programming language.
- Developers cannot assume that applying one tested strategy will produce secure code in all deployment contexts.
- Combined or adaptive approaches may be required because single-strategy fixes leave residual risks.
Where Pith is reading between the lines
- If static analysis misses context-dependent flaws, the reported side effects of fixes could be understated.
- Model-specific tuning might encourage fragmented security practices rather than portable solutions.
- Future pipelines could incorporate iterative verification steps that re-scan code after each attempted fix.
Load-bearing premise
Static analysis tools provide a complete and unbiased detection of security weaknesses without missing important vulnerabilities or producing false positives that would change the relative performance of the tested strategies.
What would settle it
Re-running the full set of generated code samples through independent manual security audits by multiple experts and comparing the resulting weakness counts and types against the static analysis results before and after each strategy.
Figures












read the original abstract
The security of AI-generated code remains a major obstacle to its widespread adoption. Although code generation models achieve strong performance on functional benchmarks, their outputs frequently contain bugs and security weaknesses that undermine their trustworthiness. Prior work has explored a range of approaches to mitigate security issues in AI-generated code, e.g., using static analysis-guided generation and prompt engineering. However, their effectiveness varies widely across models and settings. This paper presents a systematic investigation of strategies for hardening model-generated code against a list of Common Weakness Enumeration (CWE). We assess the extent to which these strategies improve security across models and programming languages, using fine-tuning and prompting approaches for model output refinement. Beyond the prevalence of security weaknesses, we analyse the severity of identified CWEs, their co-occurrence, and the unintended consequences of remediation (i.e., whether fixing certain weaknesses introduces new weaknesses elsewhere in the same code). Our results show that security improvements are highly strategy- and model-dependent. Although some approaches reduce specific classes of weaknesses, they often introduce new weaknesses as side effects of the fixes. Moreover, no strategy consistently eliminates weaknesses across all models and scenarios, highlighting the absence of a universally effective "bulletproof" solution for secure AI-generated code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic empirical evaluation of fine-tuning and prompting strategies aimed at mitigating Common Weakness Enumerations (CWEs) in code generated by large language models. It assesses these strategies across multiple models and programming languages, measuring not only reductions in specific weaknesses but also their severity, co-occurrence patterns, and unintended side effects where remediation efforts introduce new CWEs. The core claim is that security improvements are highly strategy- and model-dependent, with fixes often creating new vulnerabilities and no approach proving universally effective across all scenarios.
Significance. If the empirical measurements hold after addressing validation concerns, the work is significant for demonstrating the trade-offs and lack of a 'bulletproof' solution in securing AI-generated code. The analysis of side effects and co-occurrences provides concrete evidence that remediation is not straightforward, which can guide future research toward more holistic or model-specific techniques. The multi-model, multi-language design adds practical value to the software engineering and AI security literature.
major comments (2)
- [§3 (Experimental Setup / CWE Detection)] §3 (Experimental Setup / CWE Detection): The central claims—that certain strategies reduce specific CWEs but introduce new ones as side effects, and that no strategy is universally effective—rest entirely on outputs from static analysis tools. No validation of these tools is reported (e.g., precision/recall against manual inspection of a sample, false-positive rates, or coverage for semantic vulnerabilities). Static analyzers are known to have incomplete coverage and language/model biases; without a concrete validation step (such as auditing 100 random samples per strategy), the side-effect findings risk being tool artifacts rather than genuine code changes. This directly affects the load-bearing conclusion about strategy dependence.
- [§4 (Results and Analysis)] §4 (Results and Analysis): The manuscript reports that improvements are 'highly strategy- and model-dependent' and that fixes 'often introduce new weaknesses,' but provides insufficient detail on sample sizes per model/strategy, number of generations evaluated, data exclusion criteria, and any statistical tests (e.g., significance of differences in CWE counts). These omissions make it impossible to assess whether the observed side effects and lack of universal effectiveness are robust or sensitive to post-hoc choices, as noted in the low soundness assessment.
minor comments (2)
- [Abstract] The abstract refers to 'a list of Common Weakness Enumeration (CWE)' without naming the specific CWEs or their selection criteria; moving this detail to the abstract or §2 would improve immediate clarity for readers.
- [Results figures/tables] Figure or table captions describing CWE co-occurrence or severity distributions could explicitly state the total number of code samples underlying each bar or cell to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We are pleased that the referee recognizes the significance of our empirical evaluation of fine-tuning and prompting strategies for securing AI-generated code. We address each major comment below and outline the revisions we plan to make to improve transparency and validation.
read point-by-point responses
-
Referee: [§3 (Experimental Setup / CWE Detection)] §3 (Experimental Setup / CWE Detection): The central claims—that certain strategies reduce specific CWEs but introduce new ones as side effects, and that no strategy is universally effective—rest entirely on outputs from static analysis tools. No validation of these tools is reported (e.g., precision/recall against manual inspection of a sample, false-positive rates, or coverage for semantic vulnerabilities). Static analyzers are known to have incomplete coverage and language/model biases; without a concrete validation step (such as auditing 100 random samples per strategy), the side-effect findings risk being tool artifacts rather than genuine code changes. This directly affects the load-bearing conclusion about strategy dependence.
Authors: We agree that validating the static analysis tools is essential to substantiate our claims about side effects and strategy dependence. The original manuscript relied on established static analyzers (CodeQL for C/C++ and Java, Bandit for Python) without a reported manual validation step. We will add a new subsection to §3 describing a manual audit of 100 randomly selected code samples per strategy-model-language combination. This audit will compute precision, recall, and false-positive rates for CWE detections and note any semantic issues missed by the tools. The results and their implications for the side-effect findings will be discussed, directly addressing the concern that observations may be tool artifacts. revision: yes
-
Referee: [§4 (Results and Analysis)] §4 (Results and Analysis): The manuscript reports that improvements are 'highly strategy- and model-dependent' and that fixes 'often introduce new weaknesses,' but provides insufficient detail on sample sizes per model/strategy, number of generations evaluated, data exclusion criteria, and any statistical tests (e.g., significance of differences in CWE counts). These omissions make it impossible to assess whether the observed side effects and lack of universal effectiveness are robust or sensitive to post-hoc choices, as noted in the low soundness assessment.
Authors: We acknowledge that additional experimental details are required for reproducibility and to evaluate the robustness of our conclusions. The original submission summarized generation counts at a high level but omitted granular breakdowns and statistical analysis. In the revised manuscript, we will expand §4 with a dedicated 'Experimental Details' subsection reporting: exact sample sizes (e.g., 500 generations per model-strategy-language configuration), data exclusion criteria (non-parsable or non-compilable outputs), and statistical tests including p-values from McNemar's test for paired CWE presence and effect sizes for count differences. Updated tables and confidence intervals will be included to allow assessment of whether side effects and strategy dependence are sensitive to analysis choices. revision: yes
Circularity Check
Minor self-citation present but not load-bearing for empirical claims
full rationale
This is an empirical measurement study whose central claims (strategy- and model-dependent security improvements, introduction of new weaknesses as side effects, and absence of a universal solution) rest on experimental outcomes from applying fine-tuning/prompting strategies and detecting CWEs via static analysis. No derivation chain, equations, or fitted parameters reduce to inputs by construction. A minor self-citation to prior prompting work exists but is not load-bearing for the new side-effect findings, which have independent experimental content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static analysis tools reliably identify the listed CWEs without systematic false positives or negatives that would bias strategy comparisons.
Reference graph
Works this paper leans on
-
[1]
Anisuzzaman, Jeffrey G
D.M. Anisuzzaman, Jeffrey G. Malins, Paul A. Friedman, and Zachi I. Attia. 2025. Fine-Tuning Large Language Models for Specialized Use Cases.Mayo Clinic Proceedings: Digital Health3, 1 (2025), 100184
2025
-
[2]
Anthropic. 2026. Claude Code. https://claude.com/product/claude-code Accessed: 2026-03-01
2026
-
[3]
Anysphere Inc. 2025. The AI Code Editor. https://cursor.com/en. Accessed: 2025-08-01
2025
- [4]
-
[5]
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John Patrick Cunningham. 2024. LoRA Learns Less and Forgets Less.Transactions on Machine Learning Research(2024), 1–39
2024
-
[6]
Marc Bruni, Fabio Gabrielli, Mohammad Ghafari, and Martin Kropp. 2025. Benchmarking prompt engineering techniques for secure code generation with gpt models. InProceedings of the 2nd ACM International Conference on AI Foundation Models and Software Engineering (FORGE). IEEE, 93–103
2025
-
[7]
Cloudsmith. 2025. 2025 Artifact Management Report. https://cloudsmith.com/campaigns/2025-artifact-management- report. Accessed: 2026-01-07
2025
-
[8]
The MITRE Corporation. 2025. CWE Top 25 Most Dangerous Software Weaknesses. https://cwe.mitre.org/top25/. Accessed: 2025-08-16
2025
-
[9]
Roddy Correa, Juan-Ramón Higuera, Javier Bermejo, Juan Antonio Montalvo, Manuel Sanchez, and Ángel Magreñán
-
[10]
Hybrid Security Assessment Methodology for Web Applications.Computer Modeling in Engineering & Sciences 126 (2020), 89–124
2020
-
[11]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2025
-
[12]
Greta Dolcetti and Eleonora Iotti. 2025. A Dual Perspective Review on Large Language Models and Code Verification. Frontiers in Computer Science7 (2025), 1655469
2025
-
[13]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineering: Survey and open problems. InProceedings of the IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[14]
Ahmed Fawzy, Amjed Tahir, and Kelly Blincoe. 2026. Vibe Coding in Practice: Motivations, Challenges, and a Future Outlook–a Grey Literature Review. InProceedings of the IEEE International Conference on Software Engineering - Software Engineering in Practice (SEIP). IEEE
2026
-
[15]
Forum of Incident Response and Security Teams, Inc. (FIRST). 2019. Common Vulnerability Scoring System v3.1: Specification Document. https://www.first.org/cvss/v3-1/specification-document. Accessed: 2025-08-24
2019
-
[16]
OpenJS Foundation. 2025. Express - Fast, unopinionated, minimalist web framework for Node.js. https://expressjs.com/. Accessed: 2025-11-30. On Fixing Insecure AI-Generated Code Suggestions 41
2025
-
[17]
Yujia Fu, Peng Liang, Amjed Tahir, Zengyang Li, Mojtaba Shahin, Jiaxin Yu, and Jinfu Chen. 2025. Security weaknesses of copilot-generated code in github projects: An empirical study.ACM Transactions on Software Engineering and Methodology34, 8 (2025), 1–34
2025
-
[18]
Vrunda Gadesha, Eda Kavlakoglu, and Vanna Winland. 2025. What is chain of thought (CoT) prompting? IBM Think website. https://www.ibm.com/think/topics/chain-of-thoughts
2025
-
[19]
GitHub. 2021. CodeQL. https://codeql.github.com/ Accessed: 2025-08-19
2021
-
[20]
GitHub. 2021. CodeQL code scanning: new severity levels for security alerts. https://github.blog/changelog/2021-07- 19-codeql-code-scanning-new-severity-levels-for-security-alerts/. Accessed: 2025-08-24
2021
-
[21]
GitHub. 2025. AI that builds with you. https://github.com/features/copilot. Accessed: 2025-08-01
2025
-
[22]
GitHub. 2025. Octoverse: A new developer joins GitHub every second as AI leads TypeScript to #1. https://github.blog/ news-insights/octoverse/octoverse-a-new-developer-joins-github-every-second-as-ai-leads-typescript-to-1/. Ac- cessed: 2026-05-04
2025
-
[23]
GitHub. 2025. Survey reveals AI’s impact on the developer experience. https://github.blog/news-insights/research/ survey-reveals-ais-impact-on-the-developer-experience/. Accessed: 2025-08-01
2025
-
[24]
Google Developers. 2025. Gemini 2.0: Flash, Flash-Lite and Pro. Google Developers Blog. https://developers.googleblog. com/en/gemini-2-family-expands/ Accessed on August 16, 2025
2025
-
[25]
Hossein Hajipour, Keno Hassler, Thorsten Holz, Lea Schönherr, and Mario Fritz. 2024. Codelmsec benchmark: Systematically evaluating and finding security vulnerabilities in black-box code language models. InProceedings of the 2nd IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 684–709
2024
-
[26]
Jingxuan He, Mark Vero, Gabriela Krasnopolska, and Martin Vechev. 2024. Instruction tuning for secure code generation. InProceedings of the 41st International Conference on Machine Learning (ICML). IEEE, 18043–18062
2024
-
[27]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[28]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[29]
InProceedings of the 10th International Conference on Learning Representations (ICLR)
LoRA: Low-Rank Adaptation of Large Language Models. InProceedings of the 10th International Conference on Learning Representations (ICLR). OpenReview.net, 1–13
-
[30]
IBM. [n. d.]. What is DevSecOps? https://www.ibm.com/think/topics/devsecops Accessed: 2026-04-05
2026
-
[31]
Mahmoud Jahanshahi and Audris Mockus. 2025. Cracks in the stack: Hidden vulnerabilities and licensing risks in llm pre-training datasets. InProceedings of the 2nd IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 104–111
2025
-
[32]
Arvinder Kaur and Ruchikaa Nayyar. 2020. A Comparative Study of Static Code Analysis tools for Vulnerability Detection in C/C++ and JAVA Source Code.Procedia Computer Science171 (2020), 2023–2029
2020
- [33]
-
[34]
Jan H. Klemmer, Stefan Albert Horstmann, Nikhil Patnaik, Cordelia Ludden, Cordell Burton Jr., Carson Powers, Fabio Massacci, Akond Rahman, Daniel Votipka, Heather Richter Lipford, Awais Rashid, Alena Naiakshina, and Sascha Fahl. 2024. Using AI Assistants in Software Development: A Qualitative Study on Security Practices and Concerns. In Proceedings of the...
2024
- [35]
- [36]
-
[37]
Junjie Li, Aseem Sangalay, Cheng Cheng, Yuan Tian, and Jinqiu Yang. 2024. Fine tuning large language model for secure code generation. InProceedings of the 1st Special Event of AI Foundation Models and Software Engineering (FORGE). ACM, 86–90
2024
- [38]
-
[39]
Nikolaos Lykousas and Constantinos Patsakis. 2023. Tales from the Git: Automating the detection of secrets on code and assessing developers’ passwords choices. InProceedings of the 8th IEEE European Symposium on Security and Privacy Workshops (EuroS&PW). IEEE, 68–75
2023
-
[40]
Vahid Majdinasab, Michael Joshua Bishop, Shawn Rasheed, Arghavan Moradidakhel, Amjed Tahir, and Foutse Khomh
-
[41]
InProceedings of the 31st IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER)
Assessing the Security of GitHub Copilot Generated Code – A Targeted Replication Study. InProceedings of the 31st IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 435–444. 42 Soltanian Fard Jahromi et al
-
[42]
MITRE Corporation. 2025. CWE-79: Improper Neutralization of Input During Web Page Generation (Cross -site Scripting). https://cwe.mitre.org/data/definitions/79.html. Accessed: 2025-08-01
2025
-
[43]
MITRE Corporation. 2025. CWE-89: Improper Neutralization of Special Elements used in an SQL Command (’SQL Injection’). https://cwe.mitre.org/data/definitions/89.html. Accessed: 2025-08-01
2025
-
[44]
MITRE Corporation. 2025. New to CWE. https://cwe.mitre.org/about/new_to_cwe.html. Accessed: 2025-08-01
2025
-
[45]
Hassan Onsori Delicheh, Alexandre Decan, and Tom Mens. 2024. Quantifying security issues in reusable JavaScript actions in GitHub workflows. InProceedings of the 21st International Conference on Mining Software Repositories (MSR). ACM, 692–703
2024
-
[46]
OpenAI. 2025. Introducing GPT-5. OpenAI website. https://openai.com/index/introducing-gpt-5/ Accessed on November 25, 2025
2025
-
[47]
OpenAI. 2025. Introducing GPT -4.1 in the API. OpenAI website. https://openai.com/index/gpt-4-1/ Accessed on August 16, 2025
2025
-
[48]
OpenAI. 2025. Introducing OpenAI o3 and o4-mini. OpenAI website. https://openai.com/index/introducing-o3-and- o4-mini/ Accessed on August 16, 2025
2025
-
[49]
Oracle. 2025. Java EE at a Glance. https://www.oracle.com/nz/java/technologies/java-ee-glance.html. Accessed: 2025-11-30
2025
-
[50]
Stack Overflow. 2025. 2025 Stack Overflow Developer Survey - AI. https://survey.stackoverflow.co/2025/ai Accessed: 2025-10-29
2025
-
[51]
2025.Flask Documentation
Pallets Projects. 2025.Flask Documentation. Pallets Projects. https://flask.palletsprojects.com/en/stable/ Version 3.1.2
2025
-
[52]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions. InProceedings of the 43rd IEEE Symposium on Security and Privacy (SP). IEEE, 754–768
2022
-
[53]
The Go Project. 2025. Package net/http - HTTP client and server implementations in Go. https://pkg.go.dev/net/http. Accessed: 2025-11-30
2025
-
[54]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis.arXiv preprint arXiv:2009.10297 (2020)
work page internal anchor Pith review arXiv 2020
-
[55]
Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, and Vijay Gadepally. 2023. From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference. InProceedings of the 12th IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 1–9
2023
-
[56]
Andreas Schaad, Stefan Götz, and Dominik Binder. 2025. You Still have to Study On the Security of LLM Generated Code. InICT Systems Security and Privacy Protection, Lili Nemec Zlatolas, Kai Rannenberg, Tatjana Welzer, and Joaquin Garcia-Alfaro (Eds.). Springer, 111–124
2025
-
[57]
Tabnine. 2025. Tabnine. https://www.tabnine.com/. Accessed: 2025-08-01
2025
-
[58]
Cordeiro
Norbert Tihanyi, Tamas Bisztray, Mohamed Amine Ferrag, Ridhi Jain, and Lucas C. Cordeiro. 2024. How secure is AI-generated code: a large-scale comparison of large language models.Empirical Software Engineering30, 47 (2024), 1–47
2024
-
[59]
Catherine Tony, Markus Mutas, Nicolás Díaz Ferreyra, and Riccardo Scandariato. 2023. LLMSecEval: A Dataset of Natural Language Prompts for Security Evaluations. InProceedings of the 20th International Conference on Mining Software Repositories (MSR). IEEE, 588–592
2023
-
[60]
Lukas Twist, Jie M Zhang, Mark Harman, Don Syme, Joost Noppen, and Detlef Nauck. 2025. LLMs Love Python: A Study of LLMs’ Bias for Programming Languages and Libraries.arXiv e-prints(2025), arXiv–2503
2025
-
[61]
Darko Ðurđev. 2024. Popularity of programming languages.AIDASCO Reviews2, 2 (2024), 24–29
2024
-
[62]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in Neural Information Processing Systems30 (2017), 1–11
2017
-
[63]
Luping Wang, Sheng Chen, Linnan Jiang, Shu Pan, Runze Cai, Sen Yang, and Fei Yang. 2025. Parameter-efficient fine-tuning in large language models: a survey of methodologies.Artificial Intelligence Review58, 8 (2025), Article No.: 227
2025
-
[64]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems35 (2022), 24824–24837
2022
- [65]
- [66]
- [67]
-
[68]
Jianguo Zhao, Yuqiang Sun, Cheng Huang, Chengwei Liu, YaoHui Guan, Yutong Zeng, and Yang Liu. 2025. Towards secure code generation with LLMs: A study on common weakness enumeration.IEEE Transactions on Software Engineering51, 12 (2025), 3507–3523
2025
-
[69]
Dewu Zheng, Yanlin Wang, Ensheng Shi, Xilin Liu, Yuchi Ma, Hongyu Zhang, and Zibin Zheng. 2024. Top general performance= top domain performance? domaincodebench: A multi-domain code generation benchmark.arXiv preprint arXiv:2412.18573(2024). A Network Graph of CWEs Introduced By Model Refinement Techniques 44 Soltanian Fard Jahromi et al. Fig. 13. Network...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.