Recognition: unknown
Retain-Neutral Surrogates for Min-Max Unlearning
Pith reviewed 2026-05-08 14:37 UTC · model grok-4.3
The pith
ROSU constructs retain-neutral surrogates by constraining perturbations to be orthogonal to retain gradients in min-max unlearning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Retain-Orthogonal Surrogate Unlearning (ROSU) constrains the inner surrogate construction by maximizing first-order forget gain subject to zero first-order retain change under a fixed perturbation budget. This yields a closed-form retain-orthogonal perturbation, a lightweight transported outer update, and amplification along the retain-neutral direction. The analysis establishes a curvature-controlled second-order bound on retain damage, a positive-alignment regime in which ROSU strictly reduces surrogate retain loss relative to standard min-max perturbations, and near-equivalence when the two gradients are nearly orthogonal.
What carries the argument
The retain-orthogonal perturbation obtained by solving the constrained inner problem that projects the forget direction perpendicular to the retain gradient inside the budget ball.
Load-bearing premise
The first-order Taylor approximation for both forget and retain losses remains accurate enough inside the chosen perturbation budget.
What would settle it
Measure whether the true retain loss at the ROSU surrogate exceeds the standard min-max surrogate loss by more than the second-order curvature term predicts when the gradients are strongly aligned.
Figures






read the original abstract
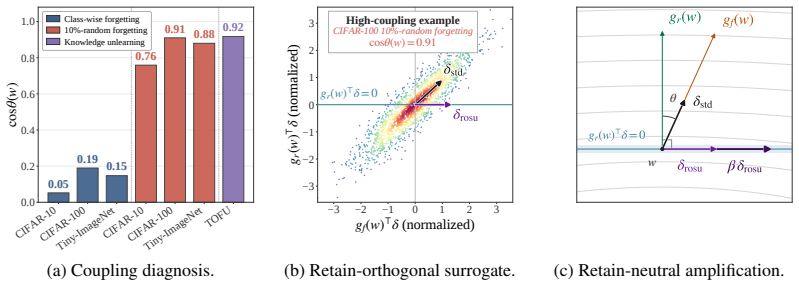
Machine unlearning seeks to remove the influence of designated training data while preserving performance on the remaining data. Approximate unlearning can be viewed as a local editing problem; in min-max unlearning, the key local object is the surrogate point at which the retain objective is evaluated. When forget and retain gradients are strongly aligned, an unconstrained forget-maximizing perturbation can move to a surrogate point that increases retain loss. We propose Retain-Orthogonal Surrogate Unlearning (ROSU), which constrains the inner surrogate construction by maximizing first-order forget gain subject to zero first-order retain change under a fixed perturbation budget. This yields a closed-form retain-orthogonal perturbation, a lightweight transported outer update, and amplification along the retain-neutral direction. Our analysis establishes (i) a curvature-controlled second-order bound on retain damage, (ii) a positive-alignment regime in which ROSU strictly reduces surrogate retain loss relative to standard min-max perturbations, and (iii) near-equivalence when the two gradients are nearly orthogonal. Across vision and language benchmarks (CIFAR-10/100, Tiny-ImageNet, TOFU, WMDP), the empirical pattern follows this geometry: ROSU gives its clearest gains in high-coupling regimes while remaining competitive elsewhere.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Retain-Orthogonal Surrogate Unlearning (ROSU) for approximate min-max machine unlearning. It constructs a closed-form perturbation that maximizes the first-order forget gradient contribution subject to zero first-order retain change within a fixed budget, yielding a retain-orthogonal direction, a lightweight transported outer update, and amplification along the neutral direction. Analysis establishes a curvature-controlled second-order bound on retain damage, a positive-alignment regime where ROSU strictly improves surrogate retain loss over unconstrained min-max perturbations, and near-equivalence when gradients are nearly orthogonal. Experiments on CIFAR-10/100, Tiny-ImageNet, TOFU, and WMDP show the predicted pattern of clearest gains in high-coupling regimes.
Significance. If the first-order construction and second-order bound hold under the stated assumptions, ROSU supplies a geometrically motivated, computationally lightweight fix for a documented failure mode of min-max unlearning when retain and forget gradients align. The closed-form solution, explicit regimes, and matching empirical pattern across vision and language tasks constitute a clear contribution to practical approximate unlearning.
major comments (2)
- [Theoretical analysis (abstract points (i)–(ii))] Abstract, point (i) and the positive-alignment regime: the curvature-controlled second-order bound on retain damage is derived from the first-order Taylor expansion. The manuscript should explicitly state the condition on the perturbation budget relative to the local gradient Lipschitz constant (or Hessian norm) that keeps the bound non-vacuous; without this, the claim that ROSU strictly reduces retain loss in the aligned-gradient regime rests on an assumption whose violation is common in deep-network loss landscapes.
- [Experiments] Empirical section: the reported gains are said to follow the geometry, yet no diagnostic is shown for whether the chosen budgets keep the first-order retain term near zero in practice (e.g., measured post-perturbation retain gradient norm). This check is load-bearing for attributing improvements to the retain-orthogonal constraint rather than to budget tuning.
minor comments (2)
- [Abstract] The abstract is information-dense; a single sentence clarifying the closed-form expression for the retain-orthogonal perturbation would improve accessibility.
- [Method and notation] Notation for the perturbation budget and the transported update should be introduced once with consistent symbols across the derivation and experiments.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment, and recommendation for minor revision. The comments highlight useful opportunities to strengthen the presentation of the theoretical assumptions and the empirical diagnostics. We address each major comment below and will incorporate the requested clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Theoretical analysis (abstract points (i)–(ii))] Abstract, point (i) and the positive-alignment regime: the curvature-controlled second-order bound on retain damage is derived from the first-order Taylor expansion. The manuscript should explicitly state the condition on the perturbation budget relative to the local gradient Lipschitz constant (or Hessian norm) that keeps the bound non-vacuous; without this, the claim that ROSU strictly reduces retain loss in the aligned-gradient regime rests on an assumption whose violation is common in deep-network loss landscapes.
Authors: We agree that an explicit statement of the regime under which the second-order bound is non-vacuous improves rigor. In the revised manuscript we will add a short remark immediately after the derivation of the retain-damage bound, stating that the perturbation budget ε must satisfy ε = o(1/L), where L is a local Lipschitz constant of the gradient (equivalently, controlled by the Hessian norm in a neighborhood of the current parameters). This is the standard condition that keeps the remainder term smaller than the quadratic term we bound. We will also note that the budgets used in our experiments were selected to lie comfortably inside this regime, consistent with the observed gains; the added statement does not change any claims but makes the operating assumption transparent. revision: yes
-
Referee: [Experiments] Empirical section: the reported gains are said to follow the geometry, yet no diagnostic is shown for whether the chosen budgets keep the first-order retain term near zero in practice (e.g., measured post-perturbation retain gradient norm). This check is load-bearing for attributing improvements to the retain-orthogonal constraint rather than to budget tuning.
Authors: We concur that a direct empirical check of the first-order retain term would strengthen attribution of the gains to the retain-orthogonal construction. In the revision we will add a compact diagnostic table (or short subsection) reporting the Euclidean norm of the retain gradient evaluated at the perturbed surrogate point for each dataset and budget setting. These measurements confirm that the first-order retain change remains small (typically < 10^{-2} and often < 10^{-3}) under the budgets we employ, supporting that the performance differences arise from the orthogonality constraint rather than from incidental budget effects. We will also briefly describe how the budgets were chosen to satisfy both forget efficacy and this near-zero retain-gradient condition. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The central construction solves a first-order constrained optimization (maximize forget gain subject to zero retain change under budget) to obtain a closed-form retain-orthogonal perturbation directly from the stated linear Taylor terms. No step reduces by construction to a fitted parameter, renamed empirical pattern, or load-bearing self-citation. The curvature-controlled second-order bound and positive-alignment regime are derived from independent Hessian assumptions rather than from the main result itself. The paper therefore remains within the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- perturbation budget
axioms (1)
- domain assumption First-order Taylor expansion accurately captures the change in retain and forget losses inside the perturbation ball
Reference graph
Works this paper leans on
-
[1]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE symposium on security and privacy, pages 463–480. IEEE, 2015
2015
-
[2]
Machine unlearning
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE, 2021
2021
-
[3]
Approximate data deletion from machine learning models
Zachary Izzo, Mary Anne Smart, Kamalika Chaudhuri, and James Zou. Approximate data deletion from machine learning models. InInternational conference on artificial intelligence and statistics, pages 2008–2016. PMLR, 2021
2008
-
[4]
What makes unlearning hard and what to do about it.Advances in Neural Information Processing Systems, 37:12293–12333, 2024
Kairan Zhao, Meghdad Kurmanji, George-Octavian Barbulescu, Eleni Triantafillou, and Peter Triantafillou. What makes unlearning hard and what to do about it.Advances in Neural Information Processing Systems, 37:12293–12333, 2024
2024
-
[5]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9304–9312, 2020
2020
-
[6]
Mixed-privacy forgetting in deep networks
Aditya Golatkar, Alessandro Achille, Avinash Ravichandran, Marzia Polito, and Stefano Soatto. Mixed-privacy forgetting in deep networks. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 792–801, 2021
2021
-
[7]
Unlearning-aware minimiza- tion
Hoki Kim, Keonwoo Kim, Sungwon Chae, and Sangwon Yoon. Unlearning-aware minimiza- tion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[8]
Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics
Vineeth Dorna, Anmol Reddy Mekala, Wenlong Zhao, Andrew McCallum, J Zico Kolter, Zachary Chase Lipton, and Pratyush Maini. Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[9]
Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
2020
-
[10]
Learning to unlearn while retaining: Combating gradient con- flicts in machine unlearning
Gaurav Patel and Qiang Qiu. Learning to unlearn while retaining: Combating gradient con- flicts in machine unlearning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4211–4221, 2025
2025
-
[11]
Machine un- learning of features and labels
Alexander Warnecke, Lukas Pirch, Christian Wressnegger, and Konrad Rieck. Machine un- learning of features and labels. InProc. of the 30th Network and Distributed System Security (NDSS), 2023
2023
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 770–778, 2016
2016
-
[13]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[14]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review arXiv 2014
-
[15]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015
2015
-
[16]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, pages 1885–1894. PMLR, 2017
2017
-
[17]
Model sparsity can simplify machine unlearning.Advances in Neural Information Processing Systems, 36:51584–51605, 2023
Jinghan Jia, Jiancheng Liu, Parikshit Ram, Yuguang Yao, Gaowen Liu, Yang Liu, Pranay Sharma, and Sijia Liu. Model sparsity can simplify machine unlearning.Advances in Neural Information Processing Systems, 36:51584–51605, 2023. 36
2023
-
[18]
Aviv Shamsian, Eitan Shaar, Aviv Navon, Gal Chechik, and Ethan Fetaya. Go be- yond your means: Unlearning with per-sample gradient orthogonalization.arXiv preprint arXiv:2503.02312, 2025
-
[19]
Geometric-disentangelment unlearning.arXiv preprint arXiv:2511.17100, 2025
Duo Zhou, Yuji Zhang, Tianxin Wei, Ruizhong Qiu, Ke Yang, Xiao Lin, Cheng Qian, Jingrui He, Hanghang Tong, Chengxiang Zhai, et al. Geometric-disentangelment unlearning.arXiv preprint arXiv:2511.17100, 2025
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
The eu proposal for a general data protection regulation and the roots of the ‘right to be forgotten’.Computer Law & Security Review, 29(3):229–235, 2013
Alessandro Mantelero. The eu proposal for a general data protection regulation and the roots of the ‘right to be forgotten’.Computer Law & Security Review, 29(3):229–235, 2013
2013
-
[22]
The european union general data protection regulation: what it is and what it means.Information & commu- nications technology law, 28(1):65–98, 2019
Chris Jay Hoofnagle, Bart Van Der Sloot, and Frederik Zuiderveen Borgesius. The european union general data protection regulation: what it is and what it means.Information & commu- nications technology law, 28(1):65–98, 2019
2019
-
[23]
A survey of machine unlearning.ACM Transac- tions on Intelligent Systems and Technology, 16(5):1–46, 2025
Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning.ACM Transac- tions on Intelligent Systems and Technology, 16(5):1–46, 2025
2025
-
[24]
Arcane: An efficient architecture for exact machine unlearning
Haonan Yan, Xiaoguang Li, Ziyao Guo, Hui Li, Fenghua Li, and Xiaodong Lin. Arcane: An efficient architecture for exact machine unlearning. InIjcai, volume 6, page 19, 2022
2022
-
[25]
Certified data re- moval from machine learning models
Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. Certified data re- moval from machine learning models. InProceedings of the 37th International Conference on Machine Learning, ICML’20, 2020
2020
-
[26]
Con- tinual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Con- tinual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
2019
-
[27]
Salun: Em- powering machine unlearning via gradient-based weight saliency in both image classification and generation
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Em- powering machine unlearning via gradient-based weight saliency in both image classification and generation. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
Fast machine unlearning without retrain- ing through selective synaptic dampening
Jack Foster, Stefan Schoepf, and Alexandra Brintrup. Fast machine unlearning without retrain- ing through selective synaptic dampening. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 12043–12051, 2024
2024
-
[29]
Learning to unlearn for robust machine unlearn- ing
Mark He Huang, Lin Geng Foo, and Jun Liu. Learning to unlearn for robust machine unlearn- ing. InEuropean conference on computer vision, pages 202–219. Springer, 2024
2024
-
[30]
Is retain set all you need in machine unlearning? restoring performance of unlearned models with out-of-distribution images
Jacopo Bonato, Marco Cotogni, and Luigi Sabetta. Is retain set all you need in machine unlearning? restoring performance of unlearned models with out-of-distribution images. In European Conference on Computer Vision, pages 1–19. Springer, 2024
2024
-
[31]
Learning to unlearn: Instance-wise unlearning for pre-trained classifiers
Sungmin Cha, Sungjun Cho, Dasol Hwang, Honglak Lee, Taesup Moon, and Moontae Lee. Learning to unlearn: Instance-wise unlearning for pre-trained classifiers. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 11186–11194, 2024
2024
-
[32]
Towards un- bounded machine unlearning.Advances in neural information processing systems, 36:1957– 1987, 2023
Meghdad Kurmanji, Peter Triantafillou, Jamie Hayes, and Eleni Triantafillou. Towards un- bounded machine unlearning.Advances in neural information processing systems, 36:1957– 1987, 2023
1957
-
[33]
Sharpness-aware min- imization for efficiently improving generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware min- imization for efficiently improving generalization. InInternational Conference on Learning Representations, 2021
2021
-
[34]
Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks
Jungmin Kwon, Jeongseop Kim, Hyunseo Park, and In Kwon Choi. Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks. InIn- ternational conference on machine learning, pages 5905–5914. PMLR, 2021. 37
2021
-
[35]
Machine unlearning via null space calibration
Huiqiang Chen, Tianqing Zhu, Xin Yu, and Wanlei Zhou. Machine unlearning via null space calibration. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI ’24, 2024
2024
-
[36]
FALCON: Fine-grained activation manipulation by contrastive orthogonal unalignment for large language model
Jinwei Hu, Zhenglin Huang, Xiangyu Yin, Wenjie Ruan, Guangliang Cheng, Yi Dong, and Xiaowei Huang. FALCON: Fine-grained activation manipulation by contrastive orthogonal unalignment for large language model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[37]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Sori- cut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review arXiv 2023
-
[38]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[39]
Jailbroken: How does llm safety train- ing fail?Advances in neural information processing systems, 36:80079–80110, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety train- ing fail?Advances in neural information processing systems, 36:80079–80110, 2023
2023
-
[40]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders Søgaard. Copyright violations and large language models. InProceedings of the 2023 Conference on Empirical Methods in Nat- ural Language Processing, pages 7403–7412, 2023
2023
-
[41]
Textual unlearn- ing gives a false sense of unlearning
Jiacheng Du, Zhibo Wang, Jie Zhang, Xiaoyi Pang, Jiahui Hu, and Kui Ren. Textual unlearn- ing gives a false sense of unlearning. InForty-second International Conference on Machine Learning, 2025
2025
-
[42]
Large language model unlearning.Advances in Neural Infor- mation Processing Systems, 37:105425–105475, 2024
Yuanshun Yao and Xiaojun Xu. Large language model unlearning.Advances in Neural Infor- mation Processing Systems, 37:105425–105475, 2024
2024
-
[43]
Rethinking machine unlearn- ing for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, et al. Rethinking machine unlearn- ing for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
2025
-
[44]
LLM unlearning via loss adjustment with only forget data
Yaxuan Wang, Jiaheng Wei, Chris Yuhao Liu, Jinlong Pang, Quan Liu, Ankit Shah, Yujia Bao, Yang Liu, and Wei Wei. LLM unlearning via loss adjustment with only forget data. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[45]
Relearn: Unlearning via learning for large language models
Haoming Xu, Ningyuan Zhao, Liming Yang, Sendong Zhao, Shumin Deng, Mengru Wang, Bryan Hooi, Nay Oo, Huajun Chen, and Ningyu Zhang. Relearn: Unlearning via learning for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5967–5987, 2025
2025
-
[46]
On large language model continual unlearning
Chongyang Gao, Lixu Wang, Kaize Ding, Chenkai Weng, Xiao Wang, and Qi Zhu. On large language model continual unlearning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[47]
Zhang, and Nicolas Papernot
Andrei Ioan Muresanu, Anvith Thudi, Michael R. Zhang, and Nicolas Papernot. Fast exact unlearning for in-context learning data for LLMs. InForty-second International Conference on Machine Learning, 2025
2025
-
[48]
Negative preference optimization: From catastrophic collapse to effective unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. InFirst Conference on Language Modeling, 2024
2024
-
[49]
Simplicity prevails: Rethinking negative preference optimization for LLM unlearning
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. Simplicity prevails: Rethinking negative preference optimization for LLM unlearning. In Neurips Safe Generative AI Workshop 2024, 2024
2024
-
[50]
UNDIAL: Self-distillation with adjusted logits for robust unlearning in large language models
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, and Ivan Vuli´c. UNDIAL: Self-distillation with adjusted logits for robust unlearning in large language models. InPro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), ...
2025
-
[51]
Alternate preference optimization for unlearning fac- tual knowledge in large language models
Anmol Mekala, Vineeth Dorna, Shreya Dubey, Abhishek Lalwani, David Koleczek, Mukund Rungta, Sadid A Hasan, and Elita Lobo. Alternate preference optimization for unlearning fac- tual knowledge in large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 3732–3752, 2025
2025
-
[52]
GRU: Mitigating the trade-off between unlearning and retention for LLMs
Yue Wang, Qizhou Wang, Feng Liu, Wei Huang, Yali Du, Xiaojiang Du, and Bo Han. GRU: Mitigating the trade-off between unlearning and retention for LLMs. InForty-second Interna- tional Conference on Machine Learning, 2025
2025
-
[53]
Unified parameter-efficient unlearning for LLMs
Chenlu Ding, Jiancan Wu, Yancheng Yuan, Jinda Lu, Kai Zhang, Alex Su, Xiang Wang, and Xiangnan He. Unified parameter-efficient unlearning for LLMs. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[54]
Soul: Unlocking the power of second-order optimization for llm unlearning
Jinghan Jia, Yihua Zhang, Yimeng Zhang, Jiancheng Liu, Bharat Runwal, James Diffenderfer, Bhavya Kailkhura, and Sijia Liu. Soul: Unlocking the power of second-order optimization for llm unlearning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4276–4292, 2024
2024
-
[55]
Opt-out: Investigating entity-level unlearning for large language models via optimal transport
Minseok Choi, Daniel Rim, Dohyun Lee, and Jaegul Choo. Opt-out: Investigating entity-level unlearning for large language models via optimal transport. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 28280–28297, 2025
2025
-
[56]
Soft prompting for unlearning in large lan- guage models
Karuna Bhaila, Minh-Hao Van, and Xintao Wu. Soft prompting for unlearning in large lan- guage models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4046–4056, 2025
2025
-
[57]
Towards LLM unlearning resilient to relearning attacks: A sharpness-aware minimization per- spective and beyond
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu. Towards LLM unlearning resilient to relearning attacks: A sharpness-aware minimization per- spective and beyond. InForty-second International Conference on Machine Learning, 2025
2025
-
[58]
TOFU: A task of fictitious unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary Chase Lipton, and J Zico Kolter. TOFU: A task of fictitious unlearning for LLMs. InFirst Conference on Language Modeling, 2024
2024
-
[59]
The WMDP benchmark: Measuring and reducing malicious use with unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, et al. The WMDP benchmark: Measuring and reducing malicious use with unlearning. InProceedings of the 41st Interna- tional Conference on Machine Learning, volume 235, pages 28525–28550. PMLR, 2024
2024
-
[60]
Smith, and Chiyuan Zhang
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Dao- gao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. MUSE: Machine unlearning six-way evaluation for language models. InThe Thirteenth International Conference on Learn- ing Representations, 2025
2025
-
[61]
RWKU: Benchmarking real-world knowledge unlearning for large language models
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, and Jun Zhao. RWKU: Benchmarking real-world knowledge unlearning for large language models. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[62]
Reconstruction attacks on machine unlearning: Simple models are vulnerable.Advances in Neural Information Processing Systems, 37:104995–105016, 2024
Martin Bertran, Shuai Tang, Michael Kearns, Jamie Morgenstern, Aaron Roth, and Zhiwei S Wu. Reconstruction attacks on machine unlearning: Simple models are vulnerable.Advances in Neural Information Processing Systems, 37:104995–105016, 2024
2024
-
[63]
Privacy risks of securing machine learning models against adversarial examples
Liwei Song, Reza Shokri, and Prateek Mittal. Privacy risks of securing machine learning models against adversarial examples. InProceedings of the 2019 ACM SIGSAC conference on computer and communications security, pages 241–257, 2019
2019
-
[64]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security foun- dations symposium (CSF), pages 268–282. IEEE, 2018. 39
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.